博客多级评论
现在我们的博客已经具有评论功能了。随着文章的评论者越来越多,有的时候评论者之间也需要交流,甚至部分评论还能合并成一个小的整体。因此最好是有某种方法可以将相关的评论聚集到一起,这时候多级评论就非常的有用了。
多级评论意味着你需要将模型重新组织为树形结构。“树根”是一级评论,而众多“树叶”则是次级评论。本教程会以第三方库django-mptt为基础,开发多级评论功能。
django-mptt模块包含了树形数据结构以及查询、修改树形数据的众多方法。
任何需要树形结构的地方,都可以用 django-mptt 来搭建。比如目录。
注意:本章新知识点较多,请读者做好心理准备,一定要耐心阅读。
重构模型
既然要建立树形结构,老的评论模型肯定是要修改了。
首先安装django-mptt:
(env) > pip install django-mptt
安装成功后,在配置中注册:
my_blog/settings.py
...
INSTALLED_APPS = [
...
'mptt',
...
]
...
这些你已经轻车熟路了。
接下来,修改评论模型:
comment/models.py
...
# django-mptt
from mptt.models import MPTTModel, TreeForeignKey
# 替换 models.Model 为 MPTTModel
class Comment(MPTTModel):
...
# 新增,mptt树形结构
parent = TreeForeignKey(
'self',
on_delete=models.CASCADE,
null=True,
blank=True,
related_name='children'
)
# 新增,记录二级评论回复给谁, str
reply_to = models.ForeignKey(
User,
null=True,
blank=True,
on_delete=models.CASCADE,
related_name='replyers'
)
# 替换 Meta 为 MPTTMeta
# class Meta:
# ordering = ('created',)
class MPTTMeta:
order_insertion_by = ['created']
...
先引入MPTT相关模块,然后改动下列几个位置:
模型不再继承内置的models.Model类,替换为MPTTModel,因此你的模型自动拥有了几个用于树形算法的新字段。(有兴趣的读者,可以在迁移好数据之后在SQLiteStudio中查看)
parent字段是必须定义的,用于存储数据之间的关系,不要去修改它。
reply_to外键用于存储被评论人。
将class Meta替换为class MPTTMeta,参数也有小的变化,这是模块的默认定义,实际功能是相同的。
这些改动大部分都是django-mptt文档的默认设置。需要说明的是这个reply_to。
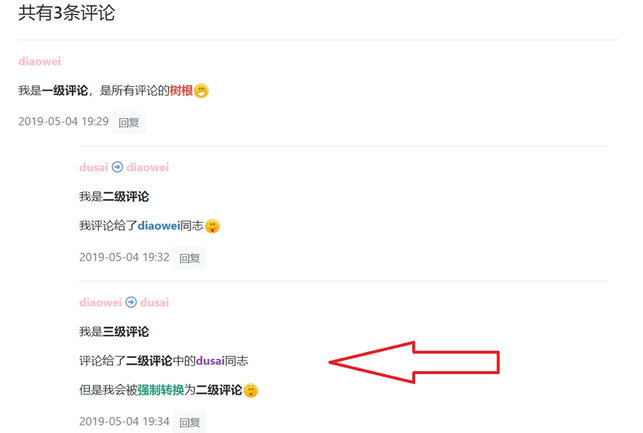
先思考一下,多级评论是否允许无限级数?无限级数听起来很美好,但是嵌套的层级如果过多,反而会导致结构混乱,并且难以排版。所以这里就限制评论最多只能两级,超过两级的评论一律重置为两级,然后再将实际的被评论人存储在reply_to字段中。
举例说明:一级评论人为 a,二级评论人为 b(parent 为 a),三级评论人为 c(parent 为 b)。因为我们不允许评论超过两级,因此将 c 的 parent 重置为 a,reply_to 记录为 b,这样就能正确追溯真正的被评论者了。
模型修改完了,添加了很多非空的字段进去,因此最好先清空所有的评论数据,再进行数据迁移。
迁移时出现下面的提示也不要慌,一律选第 1 项、填入数据 0 就可以了:
(env) > python manage.py makemigrations
You are trying to add a non-nullable field 'level' to comment without a default; we can't do that (the database needs something to populate existing rows).
Please select a fix:
1) Provide a one-off default now (will be set on all existing rows with a null value for this column)
2) Quit, and let me add a default in models.py
Select an option: 1
Please enter the default value now, as valid Python
The datetime and django.utils.timezone modules are available, so you can do e.g. timezone.now
Type 'exit' to exit this prompt
>>> 0
要还不行,就把数据库文件删了重新迁移吧。开发阶段用点笨办法也没关系。
数据迁移还是老规矩:
(env) > python manage.py makemigrations
(env) > python manage.py migrate
这就完成了。
视图
前面章节已经写过一个视图post_comment用于处理评论了,我们将复用它,以求精简代码。
改动较大,代码全贴出来,请对照改动:
comment/views.py
...
# 记得引入 Comment !
from .models import Comment
...
@login_required(login_url='/userprofile/login/')
# 新增参数 parent_comment_id
def post_comment(request, article_id, parent_comment_id=None):
article = get_object_or_404(ArticlePost, id=article_id)
# 处理 POST 请求
if request.method == 'POST':
comment_form = CommentForm(request.POST)
if comment_form.is_valid():
new_comment = comment_form.save(commit=False)
new_comment.article = article
new_comment.user = request.user
# 二级回复
if parent_comment_id:
parent_comment = Comment.objects.get(id=parent_comment_id)
# 若回复层级超过二级,则转换为二级
new_comment.parent_id = parent_comment.get_root().id
# 被回复人
new_comment.reply_to = parent_comment.user
new_comment.save()
return HttpResponse('200 OK')
new_comment.save()
return redirect(article)
else:
return HttpResponse("表单内容有误,请重新填写。")
# 处理 GET 请求
elif request.method == 'GET':
comment_form = CommentForm()
context = {
'comment_form': comment_form,
'article_id': article_id,
'parent_comment_id': parent_comment_id
}
return render(request, 'comment/reply.html', context)
# 处理其他请求
else:
return HttpResponse("仅接受GET/POST请求。")
主要变化有3个地方:
视图的参数新增了parent_comment_id=None。此参数代表父评论的id值,若为None则表示评论为一级评论,若有具体值则为多级评论。
如果视图处理的是多级评论,则用MPTT的get_root()方法将其父级重置为树形结构最底部的一级评论,然后在reply_to中保存实际的被回复人并保存。视图最终返回的是HttpResponse字符串,后面会用到。
新增处理GET请求的逻辑,用于给二级回复提供空白的表单。后面会用到。
很好,现在视图中有一个parent_comment_id参数用于区分多级评论,因此就要求有的url传入此参数,有的不传入,像下面这样:
comment/urls.py
...
urlpatterns = [
# 已有代码,处理一级回复
path('post-comment/', views.post_comment, name='post_comment'),
# 新增代码,处理二级回复
path('post-comment//', views.post_comment, name='comment_reply')
]
两个path都使用了同一个视图函数,但是传入的参数却不一样多,仔细看。第一个path没有parent_comment_id参数,因此视图就使用了缺省值None,达到了区分评论层级的目的。
前端渲染
在前端的逻辑上,我们的理想很丰满:
二级回复同样要使用富文本编辑器
回复时不能离开当前页面
多个ckeditor加载时,不能有性能问题
然而理想越丰满,代码写得就越痛苦。
首先就是detail.html的代码要大改,主要集中在显示评论部分以及相关的JavaScript。
需要改动的地方先全部贴出来:
templates/article/detail.html
...
{% load mptt_tags %}
共有{{ comments.count }}条评论
{% recursetree comments %}
{% with comment=node %}
{% endwith %}
{% endrecursetree %}
...
{% block script %}
...
// 加载 modal
function load_modal(article_id, comment_id) {
let modal_body = '#modal_body_' + comment_id;
let modal_id = '#comment_' + comment_id;
// 加载编辑器
if ($(modal_body).children().length === 0) {
let content = '
' frameborder="0" style="width: 100%; height: 100%;" id="iframe_' +
comment_id +
'">
';$(modal_body).append(content);
};
$(modal_id).modal('show');
}
{% endblock script %}
这么大段肯定把你看晕了,不要急,让我们拆开来讲解。
遍历树
第一个问题,如何遍历树形结构?
django-mptt提供了一个快捷方式:
{% load mptt_tags %}
{% recursetree objs %}
{{ node.your_field }}
{% if not node.is_leaf_node %}
{{ children }}
{% endif %}
{% endrecursetree %}
内部的实现你不用去管,当成一个黑盒子去用就好了。objs是需要遍历的数据集,node是其中的单个数据。有两个地方要注意:
{% load mptt_tags %}不要忘记写
node这个变量名太宽泛,用{% with comment=node %}给它起了个别名
Modal
Modal是Bootstrap内置的弹窗。本文相关代码如下:
class="btn btn-light btn-sm text-muted"
οnclick="load_modal({{ article.id }}, {{ comment.id }})"
>
回复
id="comment_{{ comment.id }}"
tabindex="-1"
role="dialog"
aria-labelledby="CommentModalCenter"
aria-hidden="true"
>
它几乎就是从Bootstrap官方文档抄下来的(所以读者要多浏览官网啊)。有点不同的是本文没有用原生的按钮,而是用JavaScript加载的Modal;还有就是增加了几个容器的id属性,方便后面的JavaScript查询。
和之前章节用的Layer.js相比,Bootstrap的弹窗更笨重些,也更精致些,很适合在这里使用。
加载Modal
最难理解的可能就是这段加载Modal的JavaScript代码了:
// 加载 modal
function load_modal(article_id, comment_id) {
let modal_body = '#modal_body_' + comment_id;
let modal_id = '#comment_' + comment_id;
// 加载编辑器
if ($(modal_body).children().length === 0) {
let content = '';
$(modal_body).append(content);
};
$(modal_id).modal('show');
}
实际上核心逻辑只有3步:
点击回复按钮时唤醒了load_modal()函数,并将文章id、父级评论id传递进去
$(modal_body).append(content)找到对应Modal的容器,并将一个iframe容器动态添加进去
$(modal_id).modal('show')找到对应的Modal,并将其唤醒
为什么iframe需要动态加载?这是为了避免潜在的性能问题。你确实可以在页面初始加载时把所有iframe都渲染好,但是这需要花费额外的时间,并且绝大部分的Modal用户根本不会用到,很不划算。
if语句的作用是判断Modal中如果已经加载过,就不再重复加载了。
最后,什么是iframe?这是HTML5中的新特性,可以理解成当前网页中嵌套的另一个独立的网页。既然是独立的网页,那自然也会独立的向后台请求数据。仔细看src中请求的位置,正是前面我们在urls.py中写好的第二个path。即对应了post_comment视图中的GET逻辑:
comment/views.py
def post_comment(request, article_id, parent_comment_id=None):
...
# 处理 GET 请求
elif request.method == 'GET':
...
return render(request, 'comment/reply.html', context)
...
视图返回的comment/reply.html模板还没有写,接下来就把它写好。
老实说用iframe来加载ckeditor弹窗并不是很“优雅”。单页面上多个ckeditor的动态加载、取值、传参,博主没能尝试成功。有兴趣的读者可以和我交流。
Ajax提交表单
在templates中新建comment目录,并新建reply.html,写入代码:
templates/comment/reply.html
{% load staticfiles %}
action="."
method="POST"
id="reply_form"
>
{% csrf_token %}
{{ comment_form.media }}
{{ comment_form.body }}
发送
$(function(){
$(".django-ckeditor-widget").removeAttr('style');
});
function confirm_submit(article_id, comment_id){
// 从 ckeditor 中取值
let content = CKEDITOR.instances['id_body'].getData();
// 调用 ajax 与后端交换数据
$.ajax({
url: '/comment/post-comment/' + article_id + '/' + comment_id,
type: 'POST',
data: {body: content},
// 成功回调
success: function(e){
if(e === '200 OK'){
parent.location.reload();
}
}
})
}
这个模板的作用是提供一个ckeditor的编辑器,所以没有继承base.html。让我们拆开来讲。
Ajax是什么
用Ajax技术来提交表单,与传统方法非常不同。
传统方法提交表单时向后端提交一个请求。后端处理请求后会返回一个全新的网页。这种做法浪费了很多带宽,因为前后两个页面中大部分内容往往都是相同的。与此不同,AJAX技术可以仅向服务器发送并取回必须的数据,并在客户端采用JavaScript处理来自服务器的回应。因为在服务器和浏览器之间交换的数据大量减少,服务器回应更快了。
虽然本教程只用到Ajax的一点皮毛,但是Ajax的应用非常广泛,建议读者多了解相关知识。
这里会用到Ajax,倒不是因为其效率高,而是因为Ajax可以在表单提交成功后得到反馈,以便刷新页面。
核心代码如下:
function confirm_submit(article_id, comment_id){
// 从 ckeditor 中取值
let content = CKEDITOR.instances['id_body'].getData();
// 调用 ajax 与后端交换数据
$.ajax({
url: '/comment/post-comment/' + article_id + '/' + comment_id,
type: 'POST',
data: {body: content},
// 成功回调
success: function(e){
if(e === '200 OK'){
parent.location.reload();
}
}
})
}
CKEDITOR是编辑器提供的全局变量,这里用CKEDITOR.instances['id_body'].getData()取得当前编辑器中用户输入的内容。
接下来调用了Jquery的ajax方法与视图进行数据交换。ajax中定义了视图的url、请求的方法、提交的数据。
success是ajax的回调函数。当得到视图的相应后执行内部的函数。
前面写视图的时候,二级评论提交成功后会返回200 OK,回调函数接收到这个信号后,就会调用reload()方法,刷新当前的父页面(即文章所在的页面),实现了数据的更新。
csrf问题
代码中有这么一行:
没有这一行,后端会返回403 Forbidden错误,并且表单提交失败。
还记得之前提交传统表单时的{% csrf_token %}吗?Django为了防止跨域攻击,要求表单必须提供这个token,验证提交者的身份。
问题是在Ajax中怎么解决这个问题呢?一种方法就是在页面中插入这个csrf.js模块。
在static目录中将csrf.js文件粘贴进去,并在页面中引用,就可以解决此问题了。
csrf.js文件可以在我的GitHub仓库下载。
总结
认真看完本章并实现了多级评论的同学,可以给自己点掌声了。本章应该是教程到目前为止知识点最多、最杂的章节,涵盖了MTV、Jquery、Ajax、iframe、modal等多种前后端技术。
没成功实现也不要急躁,web开发嘛,走点弯路很正常的。多观察Django和控制台的报错信息,找到问题并解决它。




















>
{{ comment.user }}
{% if comment.reply_to %}
style="color: cornflowerblue;"
>
{{ comment.reply_to }}
{% endif %}
{{ comment.created|date:"Y-m-d H:i" }}
class="btn btn-light btn-sm text-muted"
οnclick="load_modal({{ article.id }}, {{ comment.id }})"
>
回复
id="comment_{{ comment.id }}"
tabindex="-1"
role="dialog"
aria-labelledby="CommentModalCenter"
aria-hidden="true"
>
回复 {{ comment.user }}:
{% if not comment.is_leaf_node %}
{{ children }}
{% endif %}