单页面应用(SPA)对于SEO不友好的问题可以通过预渲染(Prerender)和服务端渲染(SSR)技术解决
本文主要记录预渲染技术在vue cli构建的项目中的使用
用到插件prerender-spa-plugin、vue-meta-info
内容
- 1. 引入依赖 prerender-spa-plugin
- 2. vue.config.js配置
- 3. 在main.js 添加监听方法
- 4. 配置meta参数
- 为什么SEO对单页面应用SPA不友好
- 预渲染图解过程
示例基于
vue:“^2.6.11”
vue-cli:“~4.5.0”
⚠️:router 中路由模式一定要修改为 history 才能生效,hash模式生成的页面都是一样的
1. 引入依赖 prerender-spa-plugin
npm i prerender-spa-plugin --save-dev
(prerender-spa-plugin的主要原理是启动浏览器,渲染完成后抓取HTML,然后再替换掉原有HTML)
2. vue.config.js配置
vue-cli4.x项目默认没有vue.config.js(3.x同样没有),请手动创建
配置如下:
基本不需要修改,除了routes那里的配置,要改成你自己的路由
const PrerenderSPAPlugin = require('prerender-spa-plugin');
const Renderer = PrerenderSPAPlugin.PuppeteerRenderer;
const path = require('path');
module.exports = {configureWebpack: () => {return {plugins: [new PrerenderSPAPlugin({// 输出预渲染文件的目录staticDir: path.join(__dirname, 'dist'),// 预渲染的路由,对应自己的路由文件// ⚠️:这里配不了动态路由 要传参的也不行routes: ['/home', '/project', '/develop','/develop/us','/develop/managers','/develop/activities','/develop/items'],// 要使用的渲染器的配置renderer: new Renderer({// 触发渲染的时间,用于获取数据后再保存渲染结果renderAfterTime: 5000,// 等待渲染,直到文档上调度指定的事件// 在 main.js 中 document.dispatchEvent(new Event('render-event')),两者的事件名称要对应上。renderAfterDocumentEvent: 'render-event'})}),],};}
};
更多配置访问
https://github.com/chrisvfritz/prerender-spa-plugin#about-prerender-spa-plugin
3. 在main.js 添加监听方法
此方法名要跟上面的 vue.config.js 中配置的renderAfterDocumentEvent一致
new Vue({render: h => h(App),mounted() {document.dispatchEvent(new Event('render-event'));}
}).$mount('#app')
这时候npm run build,生成的文件是每个路由都会对应一个index.html

4. 配置meta参数
要使用到插件vue-meta-info
vue-meta-info 是一个基于vue 2.0的插件,它会让你更好的管理你的 app 里面的 meta 信息。你可以直接 在组件内设置 metaInfo 便可以自动挂载到你的页面中。当然,有时候我们也可能会遇到让人头疼的SEO问题,那么使用此插件配合 prerender-spa-plugin 也是再合适不过了
安装:
npm install vue-meta-info --save
引入:
// main.js
import MetaInfo from 'vue-meta-info';
Vue.use(MetaInfo);
组件内使用:
每个组件都可以设置不同的配置项
export default {name: "Home",metaInfo: {meta: [{name: "keywords",content:"...",},{name: "description",content:"...",},],},
}
具体步骤已经结束了,下面简易记录一下
为什么SEO对单页面应用SPA不友好
- 搜索引擎蜘蛛(网络爬虫)自动抓取网页内容时,会分析页面内容,例如:从 meta 标签中读取 keywords 、 description 的内容、根据语义化的 html 的标签爬取和分析内容
- 搜索引擎蜘蛛在爬取的过程中,不会去执行js,所以隐藏在js中的跳转也不会获取到,vue通过js控制路由然后渲染出对应的页面,而搜索引擎蜘蛛是不会去执行页面的js的,导致搜索引擎蜘蛛只能收录index.html一个页面,在百度中就搜索不到相关的子页面的内容
预渲染图解过程
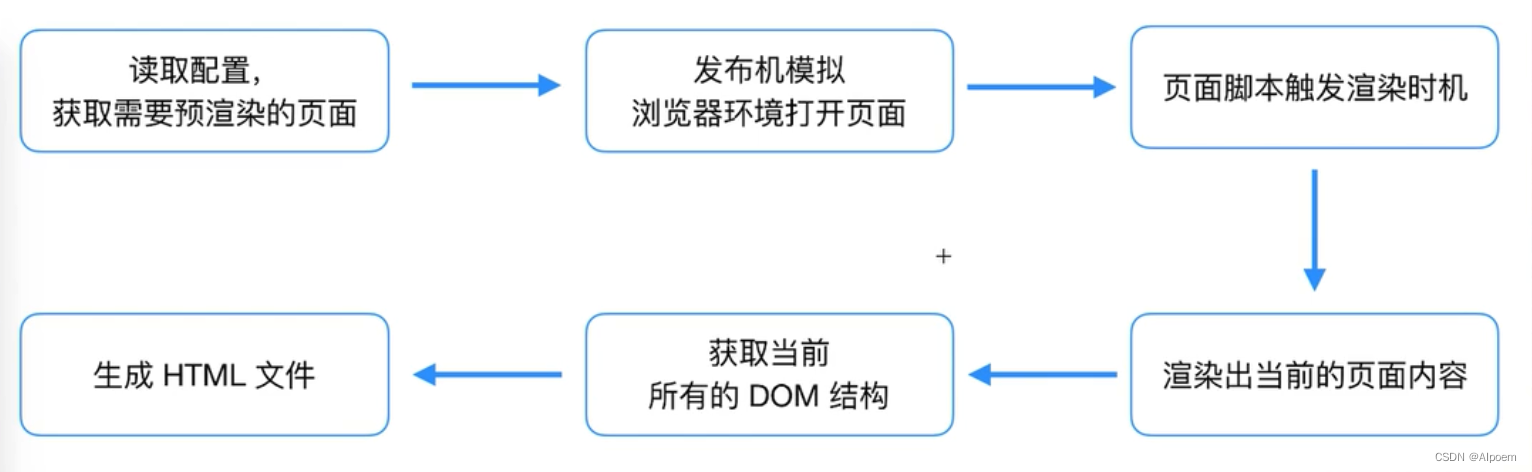
在打包结束并生成文件之后,会启动一个server模拟网站运行来访问指定的页面,得到相应的html结构并输出到指定目录里
由于是先生成内容再生成html文件,这样网络爬虫就能爬取到网站的内容
本文参考:
https://blog.csdn.net/weixin_30852391/article/details/111915355
https://blog.csdn.net/qq_40893035/article/details/111643676?utm_medium=distribute.pc_relevant.none-task-blog-2defaultbaidujs_title~default-0.no_search_link&spm=1001.2101.3001.4242.1&utm_relevant_index=3
https://blog.csdn.net/qq_37564189/article/details/106090414
https://blog.csdn.net/weixin_42899690/article/details/120556911