原标题:PYTHON模拟登陆网页方法总结
由于工作中涉及到模拟登陆网页任务,查阅相关资料后总结得出,目前Python中常用的模拟登陆网页方法共有4种:
1、直接使用已知的cookie访问;
2、模拟登录后再携带得到的cookie访问;
3、模拟登录后用session保持登录状态;
4、使用无头浏览器访问。

方法1 直接使用已知的cookie访问
0
1
原理
http是一种无状态的连接,当服务器一下子收到好几个请求时,是无法判断出哪些请求是同一个客户端发起的。于是就需要cookie来标识客户端的身份,以存储它的信息(如登录状态)。这也意味着,只要得到了别的客户端的cookie,我们就可以假冒成它来和服务器对话。
0
2
具体步骤
用浏览器登录,在开发者工具中获取浏览器里的cookie字符串。
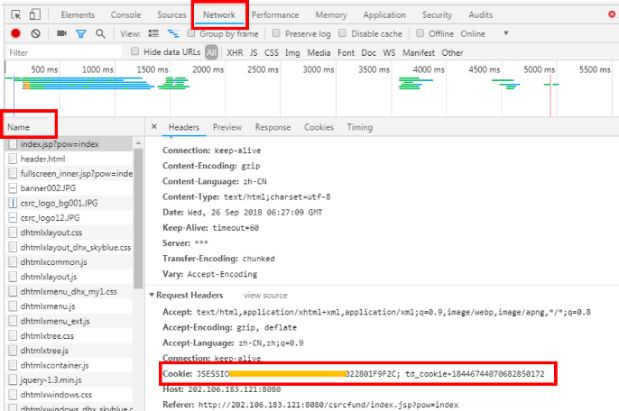
0
3
具体代码(request库版) 。
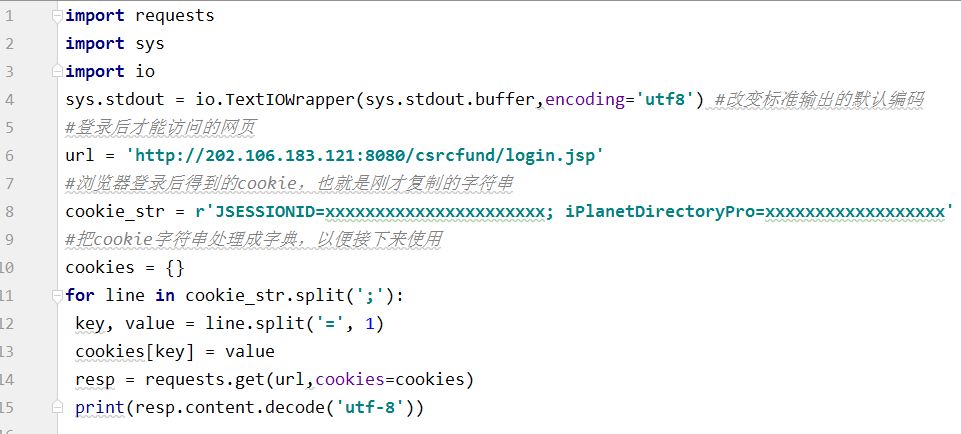
方法2 模拟登录后再携带得到的cookie访问
0
1
原理
先向网页发起登录请求,从响应中得到cookie,利用此cookie进行网页访问能够得到登录后才能看到的页面。
0
2
具体步骤
1.在开发者工具network选项卡中找出表单提交到的页面(注意勾选Preserve Log)
2.从Form Data里找出要提交的数据
0
3
具体代码(request库版)

方法3 模拟登陆后用session保持登陆状态
0
1
原理
把每一个客户端和服务器的互动当作一个“会话”,session作为会话的标记可以让服务器认可客户端。
0
2
具体步骤
1.找出表单提交到的页面
2.找出要提交的数据
0
3
具体代码(request库版)。
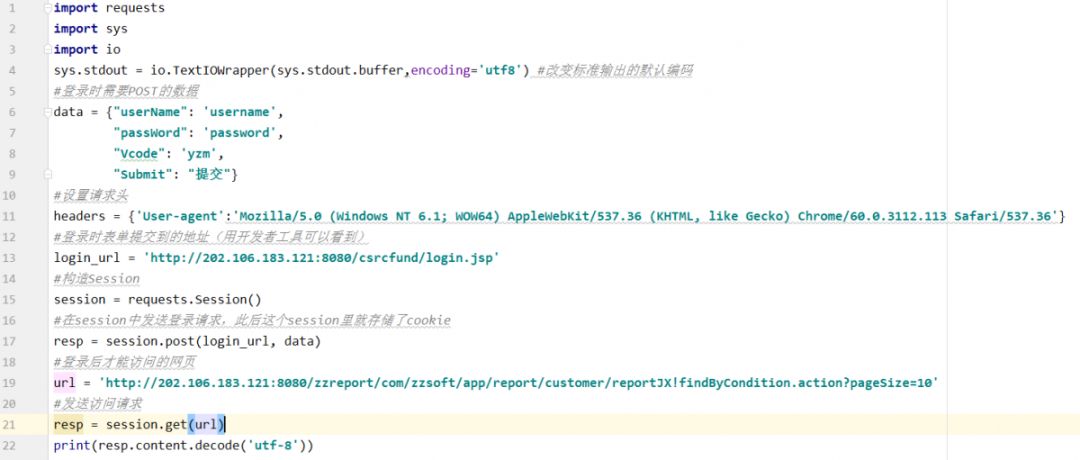
方法4 使用无头浏览器访问
0
1
原理
使用Selenium库调用浏览器来访问网页,把网页操作(如打开网页、输入文本、点击等)写入代码中,浏览器就能忠实地执行操作。
0
2
具体步骤
1.安装selenium库、Chrome浏览器
2.在源代码中找到登录时的输入文本框、按钮这些元素
3.通过Selenium库提供了find_element(s)_by_xxx的方法定位网页元素并执行。

0
3
具体代码 。
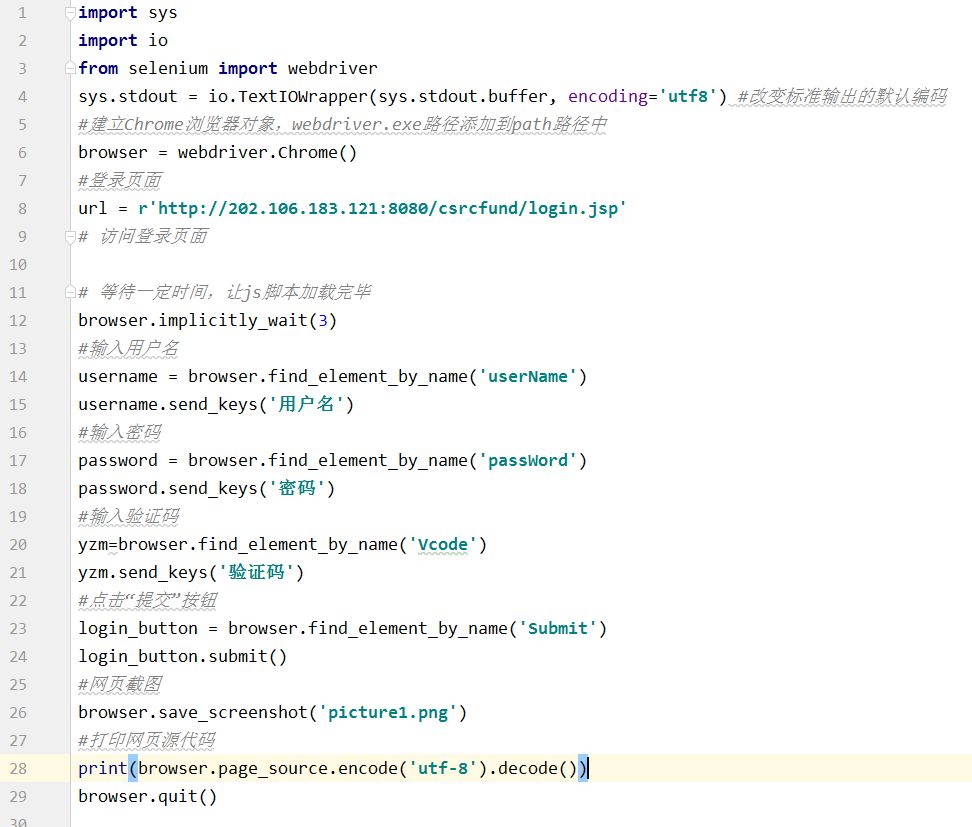
总结
前三种方法在编程过程中需要通过开发者工具获取网页信息以及浏览器信息,并且需要考虑反爬虫机制,但运行效率相对较高;使用无头浏览器访问功能强大,几乎可以对付任何网页,但会导致代码效率低。

责任编辑:



![C++] WAP GPRS 向WWW网站 提交POST GET 数据 实例](https://images.cnblogs.com/OutliningIndicators/ExpandedBlockStart.gif)