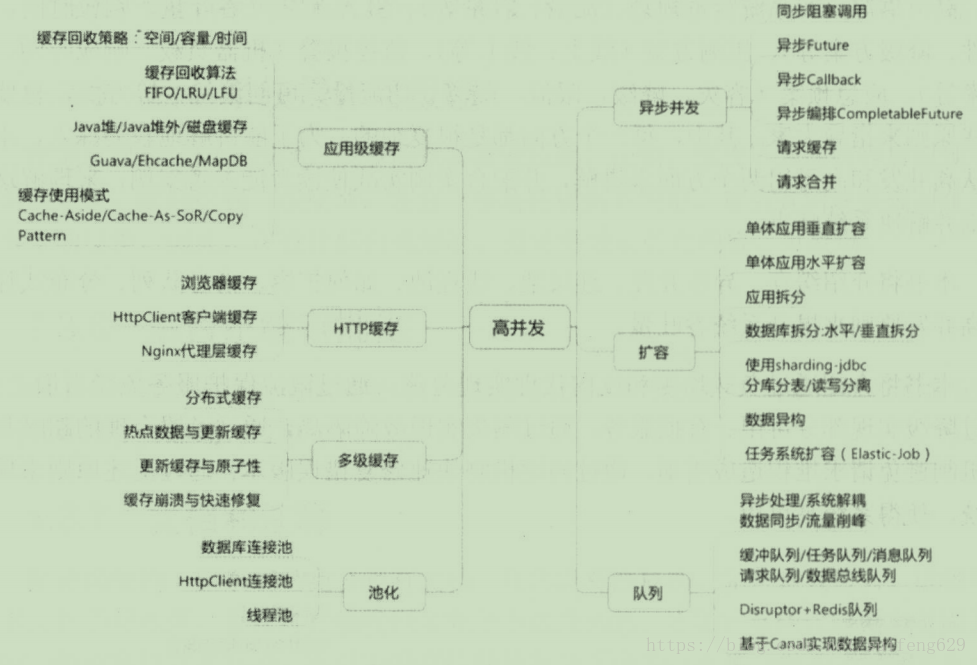
1.什么是路由?
在Web开发过程中,经常会遇到『路由』的概念。那么,到底什么是路由?简单来说,路由就是URL到函数的映射。
路由的概念最开始是由后端提出来的,在以前用模板引擎开发页面的时候,是使用路由返回不同的页面,
大致流程可以看成这样:
(1)浏览器发出请求
(2)服务器端监听到80端口或者443有请求过来,并解析url路径
(3)根据服务器的路由配置,返回相应信息(可以是html文件,json数据,也可以是图片)
(4)浏览器根据数据包的content-type来决定如何解析数据
简单来说路由就是用来跟后端服务器进行交互的一种方式,通过不同的路径来请求不同的资源,请求不同的页面是路由的其中一项功能。
2.router 和 route 的区别
route就是一条路由,它将一个URL路径和一个函数进行映射,例如:
/users -> getAllUsers()
/users/count -> getUsersCount()
这就是两条路由,当访问 /users 的时候,会执行 getAllUsers() 函数;当访问 /users/count 的时候,会执行 getUsersCount() 函数。
而 router 可以理解为一个容器,或者说一种机制,它管理了一组 route。简单来说,route 只是进行了URL和函数的映射,而在当接收到一个URL之后,去路由映射表中查找相应的函数,这个过程是由 router 来处理的。一句话概括就是 "The router routes you to a route"。
3.服务端路由
对于服务器来说,当接收到客户端发来的HTTP请求,会根据请求的URL,来找到相应的映射函数,然后执行该函数,并将函数的返回值发送给客户端。对于最简单的静态资源服务器,可以认为,所有URL的映射函数就是一个文件读取操作。对于动态资源,映射函数可能是一个数据库读取操作,也可能是进行一些数据的处理,等等。
以 Express 为例:
app.get('/', (req, res) => {
res.sendFile('index')
})
app.get('/users', (req, res) => {
db.queryAllUsers()
.then(data => res.send(data))
})
这里定义了两条路由:
当访问 / 的时候,会返回 index 页面
当访问 /users 的时候,会从数据库中取出所有用户数据并返回
不仅仅是URL 在 router 匹配 route 的过程中,不仅会根据URL来匹配,还会根据请求的方法来看是否匹配。例如上面的例子,如果通过 POST 方法来访问 /users,就会找不到正确的路由。
4.客户端路由
对于客户端(通常为浏览器)来说,路由的映射函数通常是进行一些DOM的显示和隐藏操作。这样,当访问不同的路径的时候,会显示不同的页面组件。客户端路由最常见的有以下两种实现方案:
(1)基于Hash
我们知道,URL中 # 及其后面的部分为 hash。例如:
const url = require('url')var a = url.parse('http://example.com/#/foo/bar')
console.log(a.hash)//=> #/foo/bar
hash仅仅是客户端的一个状态,也就是说,当向服务器发请求的时候,hash部分并不会发过去。
通过监听 window 对象的 hashChange 事件,可以实现简单的路由。例如:即根据哈希值的不同显示不同的内容
window.onhashchange =function() {var hash =window.location.hashvar path = hash.substring(1) //截取指定下标直接的字符,这是从下标1开始到结尾switch(path) {case '/':
showHome()break
case '/users':
showUsersList()break
default:
show404NotFound()
}
}
(2)基于History API
通过HTML5 History API可以在不刷新页面的情况下,直接改变当前URL。详细用法可以参考:
我们可以通过监听 window 对象的 popstate 事件,来实现简单的路由:
window.onpopstate =function() {var path =window.location.pathnameswitch(path) {case '/':
showHome()break
case '/users':
showUsersList()break
default:
show404NotFound()
}
}
但是这种方法只能捕获前进或后退事件,无法捕获 pushState 和 replaceState,一种最简单的解决方法是替换 pushState 方法,例如:
var pushState =history.pushState
history.pushState=function() {
pushState.apply(history, arguments)//emit a event or just run a callback
emitEventOrRunCallback()
}
不过,最好的方法还是使用实现好的 history 库。
(3)两种方法的比较
总的来说,基于Hash的路由,兼容性更好;基于History API的路由,更加直观和正式。 但是,有一点很大的区别是,基于Hash的路由不需要对服务器做改动,基于History API的路由需要对服务器做一些改造。下面来详细分析。 假设服务器只有如下文件(script.js被index.html所引用):
/-
|- index.html
|- script.js
基于Hash的路径有:
http://example.com/
http://example.com/#/foobar
基于History API的路径有:
http://example.com/
http://example.com/foobar
当直接访问 / 的时候,两者的行为是一致的,都是返回了 index.html 文件。
当从 / 跳转到 /#/foobar 或者 /foobar 的时候,也都是正常的,因为此时已经加载了页面以及脚本文件,所以路由跳转正常。
当直接访问 /#/foobar 的时候,实际上向服务器发起的请求是 /,因此会首先加载页面及脚本文件,接下来脚本执行路由跳转,一切正常。
当直接访问 /foobar 的时候,实际上向服务器发起的请求也是 /foobar,然而服务器端只能匹配 / 而无法匹配 /foobar,因此会出现404错误。
因此如果使用了基于History API的路由,需要改造服务器端,使得访问 /foobar 的时候也能返回 index.html 文件,这样当浏览器加载了页面及脚本之后,就能进行路由跳转了。
5.动态路由
上面提到的例子都是静态路由,也就是说,路径都是固定的。但是有时候我们需要在路径中传入参数,例如获取某个用户的信息,我们不可能为每个用户创建一条路由,而是在通过捕获路径中的参数(例如用户id)来实现。
例如在 Express 中:
app.get('/user/:id', (req, res, next) => {
// ... ...
})
在 Flask 中:
@app.route('/user/')
def get_user_info(user_id):
pass
6.严格路由
在很多情况下,会遇到 /foobar 和 /foobar/ 的情况,它们看起来非常类似,然而实际上有所区别,具体的行为也是视服务器设置而定。
在 Flask的文档 中,提到,末尾有斜线的路径,类比于文件系统的一个目录;末尾没有斜线的路径,类比于一个文件。因此访问 /foobar 的时候,可能会重定向到 /foobar/,而反过来则不会。
如果使用的是 Express,默认这两者是一样的,也可以通过 app.set 来设置 strict routing,来区别对待这两种情况。
什么是路由?
在Web开发过程中,经常会遇到『路由』的概念。那么,到底什么是路由?简单来说,路由就是URL到函数的映射。
访问的URL会映射到相应的函数里(这个函数是广义的,可以是前端的函数也可以是后端的函数),然后由相应的函数来决定返回给这个URL什么东西。路由就是在做一个匹配的工作。
从后端路由讲起
在web开发早期的「刀耕火种」年代里,一直是后端路由占据主导地位。不管是php,还是jsp、asp,用户能通过URL访问到的页面,大多是通过后端路由匹配之后再返回给浏览器的。经典面试题,「你从浏览器地址栏里输入www.baidu.com到你看到网页这个过程中经历了什么」其实讲的也是这个道理。

在web后端,不管是什么语言的后端框架,都会有一个专门开辟出来的路由模块或者路由区域,用来匹配用户给出的URL地址,以及一些表单提交、ajax请求的地址。通常遇到无法匹配的路由,后端将会返回一个404状态码。这也是我们常说的404 NOT FOUND的由来。
URL 与 Methods
如果你关注RESTful API,那么将会很熟悉下面四种发起请求的类型:GET,POST,PUT,DELETE。
它们分别对应四种基本操作:GET用来获取资源,POST用来新建资源(也可以用于更新资源),PUT用来更新资源,DELETE用来删除资源。——来自阮一峰《理解RESTful架构》
虽然上面说的是RESTful API,但是实际上我们在地址栏输入一个URL,并回车的时候,是以GET请求发出去的。这也体现了,URL地址和请求的method也应该是一一对应。下面给出一个例子:
router.post('/user/:id', addUser)
router.get('/user/:id', getUser) // 配置get路由
router.post('/user/:id', addUser)
后端路由与服务端渲染
前面说了,「刀耕火种」的年代里,网页通常是通过后端路由直接输出给客户端浏览器的。也就是网页的html一般是在后端服务器里通过模板引擎渲染好再交给前端的。至于一些其他的效果,是通过预先写在页面里的jQuery、Bootstrap等常见的前端框架去负责的。
如果你说有些网站已经是通过ajax去实现的页面,比如gmail,比如qq邮箱。那么你要注意到哪怕是这些页面,它们页面的「龙骨」也并非是全部通过ajax去实现的,依然还是后端直出——这也就是我们现在又老生常谈的服务端渲染。
服务端渲染的好处有很多,比如对于SEO友好,一些对安全性要求高的页面采用服务端渲染是更保险的。而在当时还没有node.js的年代,为了良好地构建前端页面,都是通过服务端语言对应的模板引擎来实现动态网页、页面结构的组织、组件的复用。比如Laravel的blade,用在Django上的jinja2,用在Struts的jsp等等。实际上到如今,一门后端语言想要能实现自己的web功能,都需要有自己对应的模板引擎。
node.js诞生之后,前端拥有自己的后端渲染的模板引擎也成为了现实。常见的比如pug、ejs、nunjucks等。这些模板引擎搭配Express、Koa等后端框架也在一开始风靡一时
不过在这个过程中,随着web应用的开发越来越复杂,单纯服务端渲染的问题开始慢慢的暴露出来了——耦合性太强了,jQuery时代的页面不好维护,页面切换白屏严重等等。耦合性问题虽然能通过良好的代码结构、规范来解决,不过jQuery时代的页面不好维护这是有目共睹的,全局变量满天飞,代码入侵性太高。后续的维护通常是在给前面的代码打补丁。而页面切换的白屏问题虽然可以通过ajax、或者iframe等来解决,但是在实现上就麻烦了——进一步增加了可维护的难度
于是,我们开始进入了前端路由的时代。
过渡到前端路由
前端路由——顾名思义,页面跳转的URL规则匹配由前端来控制。而前端路由主要是有两种显示方式:
带有hash的前端路由,优点是兼容性高。缺点是URL带有#号不好看
不带hash的前端路由,优点是URL不带#号,好看。缺点是既需要浏览器支持也需要后端服务器支持
前端路由应用最广泛的例子就是当今的SPA的web项目。不管是Vue、React还是Angular的页面工程,都离不开相应配套的router工具。前端路由带来的最明显的好处就是,地址栏URL的跳转不会白屏了——这也得益于前端渲染带来的好处。
前端路由与前端渲染
讲前端路由就不能不说前端渲染。我以Vue项目为例。如果你是用官方的vue-cli搭配webpack模板构建的项目,你有没有想过你的浏览器拿到的html是什么样的?是你页面长的那样有button有form的样子么?我想不是的。在生产模式下,你看看构建出来的index.html长什么样:
Vue通常长上面这个样子。可以看到,这个其实就是你的浏览器从服务端拿到的html。这里面空荡荡的只有一个

前端渲染把渲染的任务交给了浏览器,通过客户端的算力来解决页面的构建,这个很大程度上缓解了服务端的压力。而且配合前端路由,无缝的页面切换体验自然是对用户友好的。不过带来的坏处就是对SEO不友好,毕竟搜索引擎的爬虫只能爬到上面那样的html,对浏览器的版本也会有相应的要求。
需要明确的是,只要在浏览器地址栏输入URL再回车,是一定会去后端服务器请求一次的。而如果是在页面里通过点击按钮等操作,利用router库的api来进行的URL更新是不会去后端服务器请求的。
Hash模式
而前端的router库通过捕捉#号后面的参数、地址,来告诉前端库(比如Vue)渲染对应的页面。这样,不管是我们在浏览器的地址栏输入,或者是页面里通过router的api进行的跳转,都是一样的跳转逻辑。所以这个模式是不需要后端配置其他逻辑的,后台只要给前端返回http://localhost对应的html,剩下具体是哪个页面,就由前端路由去判断便可。
History模式
不带#号的路由,也就是我们通常能见到的URL形式。router库要实现这个功能一般都是通过HTML5提供的history这个api。比如history.pushState()可以向浏览器地址栏push一个URL,而这个URL是不会向后端发起请求的!通过这个特性,便能很方便地实现漂亮的URL。不过需要注意的是,这个api对于IE9及其以下版本浏览器是不支持的,IE10开始支持,所以对于浏览器版本是有要求的。vue-router会检测浏览器版本,当无法启用history模式的时候会自动降级为hash模式
上面说了,你在页面里的跳转,通常是通过router的api去进行的跳转,router的api调用的通常是history.pushState()这个api,所以跟后端没什么关系。但是一旦你从浏览器地址栏里输入一个地址,比如http://localhost/user/1,这个URL是会向后端发起一个get请求的。后端路由表里如果没有配置相应的路由,那么自然就会返回一个404了!这也就是很多朋友在生产模式遇到404页面的原因
那么很多人会问了,那为什么我在开发模式下没问题呢?那是因为vue-cli在开发模式下帮你启动的那个express开发服务器帮你做了这方面的配置。理论上在开发模式下本来也是需要配置服务端的,只不过vue-cli都帮你配置好了,所以你就不用手动配置了。
那么该如何配置呢?其实在生产模式下配置也很简单,参考vue-router给出的配置例子。一个原则就是,在所有后端路由规则的最后,配置一个规则,如果前面其他路由规则都不匹配的情况下,就执行这个规则——把构建好的那个index.html返回给前端。这样就解决了后端路由抛出的404的问题了,因为只要你输入了http://localhost/user/1这地址,那么由于后端其他路由都不匹配,那么就会返回给浏览器index.html。
浏览器拿到这个html之后,router库就开始工作,开始获取地址栏的URL信息,然后再告诉前端库(比如Vue)渲染对应的页面。到这一步就跟hash模式是类似的了。
当然,由于后端无法抛出404的页面错误,404的URL规则自然是交给前端路由来决定了。你可以自己在前端路由里决定什么URL都不匹配的404页面应该显示什么。设置默认路由
前端路由与服务端渲染
虽然前端渲染有诸多好处,不过SEO的问题,还是比较突出的。所以react、vue等框架在后来也在服务端渲染上做着自己的努力。基于前端库的服务端渲染跟以前基于后端语言的服务端渲染又有所不同。前端框架的服务端渲染大多依然采用的是前端路由,并且由于引入了状态统一、vnode等等概念,它们的服务端渲染对服务器的性能要求比php等语言基于的字符串填充的模板引擎渲染对于服务器的性能要求高得多。所以在这方面不仅是框架本身在不断改进算法、优化,服务端的性能也必须要有所提升。当初掘金换成SSR的时候也遇到了对应的性能问题,就是这个原因。
当然在二者之间,也出现了预渲染的概念。也即先在服务端构建出一部分静态的html文件,用于直出浏览器。然后剩下的页面再通过常用的前端渲染来实现。通常我们可以把首页采用预渲染的方式。这个的好处是明显的,兼顾了SEO和服务器的性能要求。不过它无法做到全站SEO,生产构建阶段耗时也会有所提高,这也是遗憾所在。
关于预渲染,可以考虑使用prerender-spa-plugin这个webapck的插件,它的3.x版本开始使用puppeteer来构建html文件了。
前后端分离
得益于前端路由和现代前端框架的完整的前后端渲染能力,跟页面渲染、组织、组件相关的东西,后端终于可以不用再参与了。
前后端分离的开发模式也逐渐开始普及。前端开始更加注重页面开发的工程化、自动化,而后端则更专注于api的提供和数据库的保障。代码层面上耦合度也进一步降低,分工也更加明确。我们也摆脱了当初「刀耕火种」的web开发年代。
实列:使用Vue 和 Flask中创建单页面应用去除导航栏中的#号
Vue项目去掉地址栏中的#号,最常用的方式就是在路由中使用 history 模式,存在的问题与原因如上文所述,HTML5的History-Mode在Vue-router中需要配置Web服务器的重定向,将所有路径指向index.html
以Flask创建的 web server 为例,做法很简单,将现有路由修改为以下:
@app.route('/', defaults={'path': ''})
@app.route('/')
def catch_all(path):
return render_template("index.html")
现在输入网址localhost:5000/xxxx 都将重新定向到index.html和vue-router将处理路由。
![[Erlang24]使用zotonic搭建网站记录](https://images0.cnblogs.com/blog/629822/201409/291052188785977.gif)