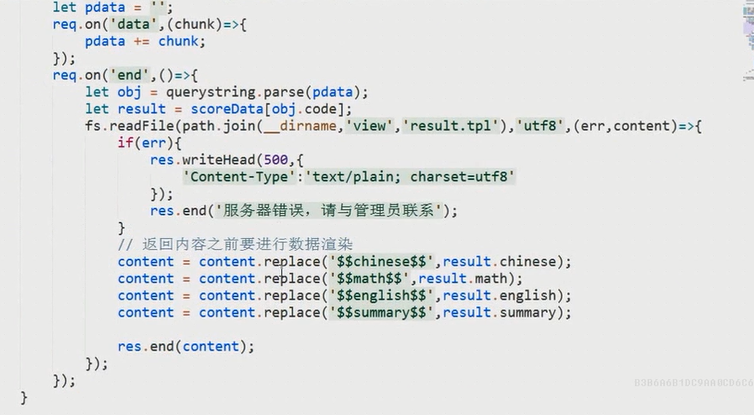
程序已经完成,源码下载:
 Yangtze.zip (2 MB, 下载次数: 5337)
Yangtze.zip (2 MB, 下载次数: 5337)
登陆是需要账号的,账号可能还要留着后续开发.而 我已经毕业了, 要是被改了我还真没法改回来了...所以就不提供了.如果有人特别想要登陆看看的,可以在QQ上M我...
开发Android网站客户端通常有两种方法:
第一种,通过服务端的开放平台,调用提供的API接口来开发,比如说淘宝开放平台,新浪微博之类的;
第二种,服务端没有提供任何接口,你也没有服务端任何数据库访问权限,就是一个纯纯粹粹的网站,要你做客户端。今天,我要和大家分享的正是第二种情况。
首先需要准备一个工具:httpWatch.这是一个网页数据分析工具.可以查看到你发送/接受的数据.特别是post提交的数据,在某些需要登录的网页中尤为重要.
附件下载
HttpWatchPro-ha-crack.zip (15.08 MB, 下载次数: 4868)
这个软件是以插件的形式存在于IE中的,支持IE6-9,使用的时候像这样就可以了.

点击录制,然后在浏览器输入地址打开.就可以看到数据哦.以百度为例

可以看到百度的首页其实包含了很多链接.有图片的,有css样式的,当然我们最关心的还是那个目标地址为 www.baidu.com的get请求.
在这个请求的"内容"标签里面可以看到网页返回的html数据.里面包含了各个链接的地址.如何解析出来呢?
当然你可以用xml的解析方法.但是这个html的标签实在太多了...不管用xml的哪种解析方式都是折腾人.还好我们有一个专门解析html的工具jsoup.
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据.android使用的时候,导入这个jar包就可以了.
附件下载 jsoup-1.7.1.jar (271.75 KB, 下载次数: 1870)
jsoup-1.7.1.jar (271.75 KB, 下载次数: 1870)
下面来一个解析示例,是我代码里面的一部分.
Elements hidden_inputs = doc.select("input[type=hidden]"); 这是关键的一句,是从这个html字符串转化来的doc文件中,查找所有type属性等于hidden的input标签.
doc.select后面放的是css选择器.我也不会用,不过用着用着就熟练了~~~比如查找所有的超链接就是.select("a[href]");
至于找到以后的Elements相关方法更是丰富,具体可以看看这个API: http://jsoup.org/apidocs/org/jsoup/nodes/Element.html
找到了之后就简单了对吧,点击按钮,发送请求,然后解析数据,获得下一批链接地址.
关于cookie的应用:(可能是我第一次用这个,又或者是我试验的网站比较简单,所以可能有不完善的地方)
cookie可以理解为一些信息,你每次请求数据的时候都会用,但是当你做登陆之类的操作时,如果你登陆成功了,服务器会保存记录你登陆成功时用的cookie.下次你访问的时候就可以选择了.如果在请求的header里面附上这个cookie,服务器就认为你登陆了.那么你请求一些需要登陆才能查看的信息时,就不会提示你登陆了.
获取cookie的代码:
Yangtze.zip (2 MB, 下载次数: 5337)
登陆是需要账号的,账号可能还要留着后续开发.而 我已经毕业了, 要是被改了我还真没法改回来了...所以就不提供了.如果有人特别想要登陆看看的,可以在QQ上M我...
开发Android网站客户端通常有两种方法:
第一种,通过服务端的开放平台,调用提供的API接口来开发,比如说淘宝开放平台,新浪微博之类的;
第二种,服务端没有提供任何接口,你也没有服务端任何数据库访问权限,就是一个纯纯粹粹的网站,要你做客户端。今天,我要和大家分享的正是第二种情况。
首先需要准备一个工具:httpWatch.这是一个网页数据分析工具.可以查看到你发送/接受的数据.特别是post提交的数据,在某些需要登录的网页中尤为重要.
附件下载
HttpWatchPro-ha-crack.zip (15.08 MB, 下载次数: 4868)
这个软件是以插件的形式存在于IE中的,支持IE6-9,使用的时候像这样就可以了.
点击录制,然后在浏览器输入地址打开.就可以看到数据哦.以百度为例
可以看到百度的首页其实包含了很多链接.有图片的,有css样式的,当然我们最关心的还是那个目标地址为 www.baidu.com的get请求.
在这个请求的"内容"标签里面可以看到网页返回的html数据.里面包含了各个链接的地址.如何解析出来呢?
当然你可以用xml的解析方法.但是这个html的标签实在太多了...不管用xml的哪种解析方式都是折腾人.还好我们有一个专门解析html的工具jsoup.
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据.android使用的时候,导入这个jar包就可以了.
附件下载
jsoup-1.7.1.jar (271.75 KB, 下载次数: 1870)
下面来一个解析示例,是我代码里面的一部分.
[Java] 纯文本查看 复制代码
| 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 | public void handResponse(MyHttpResponse myHttpResponse) { Document doc; if (myHttpResponse.getPipIndex() == NetConstant.HOMEPAGE) { doc = myHttpResponse.getData(); Elements hidden_inputs = doc.select("input[type=hidden]"); for (Element ele : hidden_inputs) { String[] arr = new String[] { ele.attr("name"), ele.attr("value") }; Globe.sHideParams.add(arr); } hidden_inputs = doc.select("input[type=submit]"); Globe.sHideParams.add(new String[] { hidden_inputs.get(0).attr("name"), hidden_inputs.get(0).attr("value") }); System.out.println("获取首页信息成功"); // System.out.println(doc); } } |
Elements hidden_inputs = doc.select("input[type=hidden]"); 这是关键的一句,是从这个html字符串转化来的doc文件中,查找所有type属性等于hidden的input标签.
doc.select后面放的是css选择器.我也不会用,不过用着用着就熟练了~~~比如查找所有的超链接就是.select("a[href]");
至于找到以后的Elements相关方法更是丰富,具体可以看看这个API: http://jsoup.org/apidocs/org/jsoup/nodes/Element.html
找到了之后就简单了对吧,点击按钮,发送请求,然后解析数据,获得下一批链接地址.
关于cookie的应用:(可能是我第一次用这个,又或者是我试验的网站比较简单,所以可能有不完善的地方)
cookie可以理解为一些信息,你每次请求数据的时候都会用,但是当你做登陆之类的操作时,如果你登陆成功了,服务器会保存记录你登陆成功时用的cookie.下次你访问的时候就可以选择了.如果在请求的header里面附上这个cookie,服务器就认为你登陆了.那么你请求一些需要登陆才能查看的信息时,就不会提示你登陆了.
获取cookie的代码:
[Java] 纯文本查看 复制代码
| 01 02 03 04 05 06 07 08 09 10 | if (req.getPipIndex() == NetConstant.LOGIN) { CookieStore store = client.getCookieStore(); List<Cookie> cookies = store.getCookies(); if (cookies.isEmpty()) { } else { mCookie = cookies.get(0); mCookieString = mCookie.getName() + "=" + mCookie.getValue(); } } |
将这个cookie保存起来待用.
附加cookie的代码:
post.setHeader("Cookie", Globe.sCookieString);
最新比较闲,于是就想着给学校的教务处网站做一个客户端,免得像以前读书时,查个课表,分数还要去电脑上弄.
虽然还没做完,但是技术上的问题都OK了.就把一些实现思路和注意的地方发上来.大家有什么中意的网站都可以做一个试试的.
转自:http://www.apkbus.com/forum.php?mod=viewthread&tid=73305&extra=page%3D1