准备工作
- 需要用到的库
import requests
from bs4 import BeautifulSoup
import re
from fontTools.ttLib import TTFont
step1
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36"}
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
print("页面状态码:{0}".format(response.status_code))
通过requests的get方法来访问url, 并指定解码方式为"utf-8". 可以看到标题被存放在hl、div标签, 类型被存放在a标签中等.
soup = BeautifulSoup(response.text, "html.parser")
#print(soup)
div = soup.find_all("div", {"class": "movie-brief-container"})[0]
CN_title = div.h1.text
EN_title = div.div.text
MoveType = []for i in range(len(div.find_all("li")[0].find_all("a"))):move_type = div.find_all("li")[0].find_all("a")[i].textMoveType.append(move_type)land = div.find_all("li")[1].text
Land = land.replace("\n", "").lstrip().rstrip().replace(" ", "").split("/")
接下来我们用BeautifulSoup库来格式化response对象的内容, 使其更易读.
step2(难点)
接下来用户rating的内容, 与step1不同的是, 数字内容被加密了(我们看到的内容是.).
可以看到这个字体的class为"stonefont", 这是一种自定义字体, 起初是为了解决浏览器字体不适配的问题.
- 参考解决办法
首先右击页面, 查看源代码

实际上这种字体的编码通过一个woff文件来控制, 我们只需要ctrl + F后搜索stonefont

就可以找到这个文件, 那么我们就可以通过下载这个文件来查看被加密的数字是通过何种方式来编码的
fontUrl = "http://vfile.meituan.net/colorstone/0e34b53354e3b3af841216ade738e4312268.woff"
r = requests.get(fontUrl)
with open("D://Desktop//stonefont.woff", "wb") as code:code.write(r.content)
我们可以通过这个网站查看woff字体文件(Iconfot)

显然这是一种unicode编码方式, 我们再回到网页源代码上
html = response.content.decode("utf-8")
html

注意到html里的内容很乱, 这是因为我们没有通过beautifulsoup解决, 原因是beautifulsoup库会自动解析Unicode编码, 导致我们看不到加密数字的真实情况(尽管内容很乱, 我们依然可以通过ctrl + F: koubei来找到标签的位置).
可以看到包含了(rating)的标签内数字部分都现显示出了其Unicode编码. 也就是说每个Unicode代表了一个数字, 我们只需找到每个数字的具体Unicode就可以将其替换为真实的数字(实际上工作量并不太大, 因为数字只包括了0-9)
利用刚才提到的网站解析woff文件.

xe48e和xe84e分别指向了9和6, 这与页面上9.6的评分一致. 现在我们需要建立起Unicode与数字的对应关系
fontPath = "D://Desktop//0e34b53354e3b3af841216ade738e4312268.woff"
font = TTFont(fontPath)
fontNumber = [8, 4, 1, 2, 7, 9, 5, 6, 3, 0]
TTFont方法能够直接读取woff文件并给出其Unicode形式, 你也应该能够发现fontNumber列表里的内容正是和woff文件的数字相对应. 幸运的是python中的字典dict正好匹配了这种形式, 所以我们将这种对应关系建立为字典.
numDict = {}
for i in range(len(newList)):numDict[newList[i]] = fontNumber[i]
既然对应关系已经找到, 我们就可以去寻找这些Unicode所在的位置
html = response.content.decode("utf-8")
star = re.findall(r'<span class="index-left info-num ">\s+<span class="stonefont">(.*?)</span>\s+</span>', html)
starNumber = str()
for i in range(len(star[0].split("."))):if star[0].split(".")[i] in numDict:starNumber = starNumber + "." + str(numDict[star[0].split(".")[i]])#print(numDict[star[0].split(".")[i]], end=".") #这里的print方法是为了调试, 当代码运行正常时我们就可以将其注释.
注意: 这里我们使用了正则表达式的方式来匹配标签, 因为我们并没有通过BeautifulSoup方法去解析response对象, 那么r.find_all()方法就是不可用的, 因为这是针对soup对象的方法.
运行结果:

结果为9.6, 与预期一致.
boxOffice = re.findall(r'<div class="movie-index-content box">\s+<span class="stonefont">(.*?)</span>', html)
boxnumber = str()
for i in range(len(boxOffice[0].split("."))):for j in range(len(boxOffice[0].split(".")[i].split(";")) - 1):boxnumber = boxnumber + str(numDict[boxOffice[0].split(".")[i].split(";")[j] + ";"])#print(numDict[boxOffice[0].split(".")[i].split(";")[j] + ";"])boxnumber = boxnumber + "."
print(boxnumber[0:-1])
运行结果:
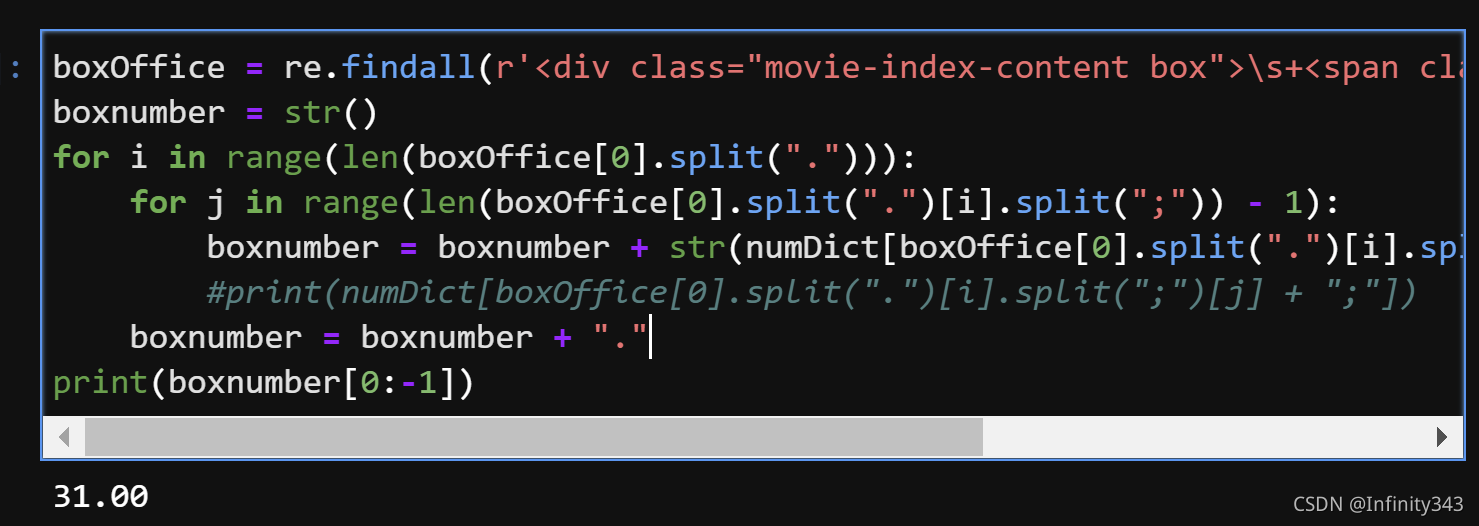
与预期保持一致(注意: 这里我们只考虑了这一个样本, 也就是说box office数字的排列方式是固定的, 当获取不同的样本时, 数位可能会有所不同, 需要结合实际情况做出调整)
step3
将全部代码组合
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import re
from fontTools.ttLib import TTFontproxies = {'https': '203.86.26.9:3128'
} #设置代理
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36"} #设置头部
#response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
print("页面状态码:{0}".format(response.status_code))
soup = BeautifulSoup(response.text, "html.parser")
#print(soup)
div = soup.find_all("div", {"class": "movie-brief-container"})[0]
CN_title = div.h1.text
EN_title = div.div.text
MoveType = []for i in range(len(div.find_all("li")[0].find_all("a"))):move_type = div.find_all("li")[0].find_all("a")[i].textMoveType.append(move_type)land = div.find_all("li")[1].text
Land = land.replace("\n", "").lstrip().rstrip().replace(" ", "").split("/") fontUrl = "http://vfile.meituan.net/colorstone/0e34b53354e3b3af841216ade738e4312268.woff"
r = requests.get(fontUrl)
with open("D://Desktop//stonefont.woff", "wb") as code:code.write(r.content)
fontPath = "D://Desktop//0e34b53354e3b3af841216ade738e4312268.woff"
font = TTFont(fontPath)
fontNumber = [8, 4, 1, 2, 7, 9, 5, 6, 3, 0]
#print(font.getGlyphOrder()[2::])numDict = {}
for i in range(len(newList)):numDict[newList[i]] = fontNumber[i]#print(newList[i],fontNumber[i])html = response.content.decode("utf-8")
star = re.findall(r'<span class="index-left info-num ">\s+<span class="stonefont">(.*?)</span>\s+</span>', html)
starNumber = str()
for i in range(len(star[0].split("."))):if star[0].split(".")[i] in numDict:starNumber = starNumber + "." + str(numDict[star[0].split(".")[i]])#print(numDict[star[0].split(".")[i]], end=".")boxOffice = re.findall(r'<div class="movie-index-content box">\s+<span class="stonefont">(.*?)</span>', html)
boxnumber = str()
for i in range(len(boxOffice[0].split("."))):for j in range(len(boxOffice[0].split(".")[i].split(";")) - 1):boxnumber = boxnumber + str(numDict[boxOffice[0].split(".")[i].split(";")[j] + ";"])#print(numDict[boxOffice[0].split(".")[i].split(";")[j] + ";"])boxnumber = boxnumber + "."abstract = soup.find_all("span", {"class": "dra"})[0].textprint("name_CN:{0}, name_EN:{1}".format(CN_title,EN_title))
print("type:{0}".format(MoveType))
print("location:{0}, time:{1}".format(Land[0],Land[1]))
print("rationg:{0}".format(starNumber[1::]))
print("box office:{0}".format(boxnumber[0:-1]))
print("abstract:{0}".format(abstract))
至此, 我们需要的内容就获取完毕了.





![apache主机头设置-一台服务器支持多个网站,多个域名 ... [复制链接]](http://img0.ph.126.net/j4SWXfhStY3zjwF9rzzxfA==/3143231065028127957.jpg)