简单来说,爬取工作前期任务是了解目标网站的体系结构和“反爬策略”,然后是根据现有软硬件资源环境条件设计代码,反复迭代测试,最终实施部署。
之前,写过爬取图片网站的PHP和Python代码spi之类,通过读取HTML文本内容,模糊检索HTML img标签获取资源。批量爬取效率较高,但是只能应对“宽松”的爬虫应对策略,须应对各种不同文本编码和网站管理员的“疏忽”造成的编码混乱问题,且受网路网络实时状况影响较大,出现不稳定的现象。今昨心血来潮,改进原来的思路,采用Python + Selenium + 自定义HTML DOM解释器1(正则表达式RE)来实现。效率不如检索纯HTML文本高,但是准确率、稳定性较高。
先开展前期准备工作,深入了解目标体系结构。
任意点开一个目标图集网页:

可以看到图集的标题、更新时间、栏目以及翻页方式等等详细信息。由于需要自动翻页,获取图片页数的边界很重要。刚好,图集的页数总量在标题中。这样,只需获取该HTML节点的HTML文本(innerHTML),加以正则表达式就可以识别。完美解决翻页次数的问题。而翻页,如“温馨提示”所说 – “点击图片”即可。Selenium具有鼠标点击HTML节点操作的事件。
# 标题内容包含页码信息
pagePattern='([0-9]+[/][0-9]+)'
# 匹配标题HTML的页码
matches=re.findall(pagePattern, html)
# 目标只有一个
counts=matches[0]
现在通过浏览器来查看目标的HTML结构。博主使用的是Chrome浏览器(Firefox/Internet等Selenium支持的都可以)。右击目标图片检查:

从图片看出,目标图片被包含在一个超链接,超链接被包含在一个div标签。目标的体系结构相对较简单。在网页加载进来,目标标签渲染完成后,定位该标签节点,获取其HTML文本内容,加以分析得出目标图片的地址。保存目标后,操作点击事件实现自动翻页,进行下一次处理分析,直到到达上述翻页界限。自动翻页结束后,开始下载上述步骤获取的目标图片集。
实现过程明确,开始实现设计代码。
# -*- coding: utf-8 -*-
#!/usr/bin/env python"""
@author: WowlNAN@github: https://github.com/WowlNAN@blog: https://blog.csdn.net/qq_21264377"""
"""
Get target pictures of specific website
"""import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECS
from htmldom import *
import re
import sys
from schedule import *class Solution:def __init__(self):self.url=''self.driver=webdriver.Chrome()self.images={}self.path=Nonedef __delete__(self):self.url=Noneself.images=Noneself.path=''if self.driver:self.driver.close()self.driver=Nonedef reset(self):self.url=''self.images={}self.path=Nonedef dictimage(self, index: int, url: str):if self.images.get(index, '')=='':self.images[index]=urldef pickimage(self, index: int, html: str):imagehtmls=match('//a//img', html)image=re.findall('src="([^<>"]*)"', imagehtmls[0])[0]self.dictimage(index, image)return imagedef getimages(self, url: str):if not url:return Noneelif not url.strip():return Noneelif not url.startswith('http://') and not url.startswith('https://'):return Noneself.path=url.split('/')[-1].split('.')[0]# 加载目标图集网页self.driver.get(url)# 设置等待事件wait=WebDriverWait(self.driver, 5)time.sleep(1) # 指定等待事件内容:直到目标class元素出现 targetelement=wait.until(ECS.presence_of_element_located((By.CLASS_NAME, 'center')))#print('wait ', url, end='')if not targetelement or targetelement==[]:return None# 获取根节点 -- 目标所在标签节点的HTML文本内容html=targetelement.get_attribute('innerHTML')if not html:return# 从根节点获取标题节点HTMLtitlehtml=match('//h1:class=center', html)if not titlehtml:return# 正则匹配页码信息counterhtml=re.findall('([0-9]+[/][0-9]+)', titlehtml[0])if not counterhtml:return counts=counterhtml[0].split('/')# 起止页码current=int(counts[0])end=int(counts[1])# 分析HTML获取目标图片self.pickimage(current, html)print('loading...', str(current)+'/'+str(end)+' ', end='')time.sleep(1)i=current+1while i<end+1:try:# 操作点击目标节点事件targetelement.click()time.sleep(.5)# 指定等待事件内容:直到目标class元素出现 targetelement=wait.until(ECS.presence_of_element_located((By.CLASS_NAME, 'center'))) print('\rloading...', str(i)+'/'+str(end)+' ', end='')if not targetelement or targetelement==[]:i+=1continue# 从根节点获取标题节点HTMLhtml=targetelement.get_attribute('innerHTML')# 分析HTML获取目标图片image=self.pickimage(i, html)i+=1except:i+=1# 开始下载目标图片集合# start downloadstime.sleep(1)codes={'hit':0, 'done':0, 'failed':0}i=1for key in self.images.keys():print('\rcaching...', str(i)+'/'+str(end)+' ', end='')# 下载图片act=schedule.schedule(self.images.get(key), path=self.path)# 根据反馈信息,统计下载情况codes[act]=codes[act]+1i+=1time.sleep(.1)# 生成下载统计表格keys='|'actions='|'l=len(codes.keys())i=0for key in codes.keys():kl=16-len(key)keys+=' '*(kl//2)+key+' '*(kl-kl//2)al=16-len(str(codes[key]))actions+=' '*(al//2)+str(codes[key])+' '*(al-al//2)i+=1if i>0:keys+='|'actions+='|'print('\r|'+('-'*16+'|')*l, end='\n')print(keys)print('|'+('-'*16+'|')*l)print(actions)print('|'+('-'*16+'|')*l)print("ENTER:[eg, http://a.com/b/c.html]")
url=' '
while url:if url:s.getimages(url)time.sleep(.2)s.reset()# 命令行输入目标图集首页地址(可跳页)url=input(">>")
schedule.py
# -*- coding: utf-8 -*-
#!/usr/bin/env python"""
@author: WowlNAN@github: https://github.com/WowlNAN@blog: https://blog.csdn.net/qq_21264377"""import requests
import ssl
import socket
from fio import fio
import os
import time
import datetimeclass Schedule:def __init__(self):passdef schedule(self, url, path=None, delay=.1): if url==None or url.strip()=='':return 'failed'else:# wait until delay is overtime.sleep(delay)count=1completed=Falsewhile count<=3 and not completed: try:# http headersheaders={'User-Agent':'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:64.0) Gecko/201001003 Firefox/64.0','Referer':url,'authority':'www.ttbcdn.com','method':'GET','scheme':'https','accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8','accept-encoding':'gzip, deflate, br','accept-language':'zh-CN,zh;q=0.8','cache-control':'max-age=0','upgrade-insecure-requests':'1'}# create directories according to date and the relative pathcurrenttime=datetime.datetime.now() tmpdir=fio.getTempDir()+'/'+currenttime.strftime("%Y")+'/'+currenttime.strftime("%m")+'/'+currenttime.strftime("%d");paths=url.split('/')# check if the specific storage path is setif not path: tmpdir+='/'+paths[-2]else:tmpdir+='/'+pathfio.mkdirs(tmpdir)tmpfilename=tmpdir+'/'+paths[-1]if os.path.exists(tmpfilename):# repeat downloadreturn 'hit'else:# download is readyssl._create_default_https_context=ssl._create_default_https_context=ssl._create_unverified_contextsocket.setdefaulttimeout(5)#req = request.Request(url, headers=headers)#response = request.urlopen(req)'''opener=request.build_opener()opener.addheaders=[('User-Agent', 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:65.0) Gecko/20100101 Firefox/65.0'), ('Referer', task.getreferer())]response=request.urlretrieve(url, tmpfilename, self.joblistener)'''#The following step with referer:response=requests.get(url, headers=headers, timeout=5)#if response.getcode()==200:#con = response.read()if response.status_code==200:f=open(tmpfilename, 'wb')for con in response.iter_content(chunk_size=512):if con:f.write(con)f.close()completed=True#print('\rdone ', url, end='')return 'done'else:# retry after problemscount+=1 except :#Exception as err:# retry after exceptioncount+=1if not completed:# download failedreturn 'failed'# Run under process instead of thread schedule=Schedule()
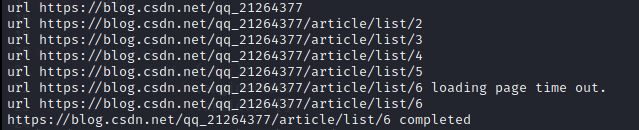
首次下载效果图:

重复下载效果图:

首次下载得到8张图片 – “done”。重复下载后,提示包含8个重复目标 – “hit”。(下载失败 – “failed” 略)


2020-08-22 01:21PM Sat.
关于PhantomJS:
PhantomJS满天飞而Chrome之流还没有headless的时候,尝试PhantomJS 基于webkit的headless浏览器,结果发现一些“严格”反爬虫机制的网站反馈“浏览器版本过低”。看到Selenium.dev介绍,PhantomJS基于比较旧、远低于Chrome和safari浏览器的webkit版本,该项目已自2017年8月5日停止维护。而在此之前Chrome维护方Google宣布推出开发者headless版本。

2020/10/27 Tues.
以上可以描述为“逻辑计数器”方式(Logical Counter)。另一种简单的翻页方式:自然语言特征(Natural Language Feature)。也就是说,通过自然语言来描述翻页方式,指定翻页的途径。比如说,中文的“下一页”,英文的“Next”等等。这种方式比较直观清晰。一般情况下,其目标很轻松就能在简洁的代码中得以实现。
很多时候,此类网站的HTML代码类似于:<a href="a.com/b?page=2">下一页</a>或者<a href="a.com/b?page=2">Next</a>。据此,可以通过查找包含类似自然语言特征码的a超链接标签,得知下一页的位置是否存在以及内容。使用Python + Selenium可以使用以下代码:
import traceback
from selenium import webdriver
from selenium.webdriver.common import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECS
...
try:clickelement=wait.until(ECS.presence_of_element_located((By.PARTIAL_LINK_TEXT, 'Next')))
except:try:clickelement=wait.until(ECS.presence_of_element_located((By.PARTIAL_LINK_TEXT, '下一页')))if clickelement:# Chinese中文语言特征,按照目标区域语言调整。chn=Trueexcept:traceback.print_exc()
...
pageend=True
if clickelement:# 判定页面集合的终点,这里以超链接地址为“#”或以“#”号结尾的地址pageend=clickelement.get_attribute('href')=='#' or clickelement.get_attribute('href').endswith('#')while clickelement and not pageend:# Do somethingtry:...finally:try:# Chinese中文语言特征码if chn:clickelement=wait.until(ECS.presence_of_element_located((By.PARTIAL_LINK_TEXT, '下一页')))else:# English英文语言特征码clickelement=wait.until(ECS.presence_of_element_located((By.PARTIAL_LINK_TEXT, 'Next')))# 重新判定页面集合的终点if clickelement:pageend=clickelement.get_attribute('href')=='#' or clickelement.get_attribute('href').endswith('#')except:# 出现错误判定翻页动作结束pageend=Truetraceback.print_exc()
自然语言特征码和逻辑计数器两种方式,各有优缺点。自然语言特征码直观简洁,通用性广;逻辑计数器针对性强,效率表现良好。凡事具有两面性,不能一概而论。互联网环境因人而异,网络生态环境复杂多变(Complex)。因此,需要灵活多变的应对策略。
自定义HTML DOM解析器,来源于之前写的HTML标签选择器的系列文章。 ↩︎

![[转载]使用IntelliJ IDEA开发SpringMVC网站(一)开发环境](https://image-static.segmentfault.com/304/403/3044038503-5c666c973c254_articlex)