现在网络越来越普及,带宽速度普遍也有较大提升。伴随网络的普及,同时快速增长的还有网民的数量和网络流量。网站超时响应的“通病”,仍然是无法完全避免的。尤其是在网络流量高峰期访问HTTPS网站,使用类似Selenium的浏览器内核驱动driver方案过程中,这类问题的处理是关键。下面以Selenium WebDriver和Firefox为例子,介绍如何多层次应对网站超时响应的问题。
初始化全局超时配置参数,设置WebDriver的页面加载和脚本执行超时限制。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support import expected_conditions as ECS
from selenium.webdriver.support.wait import WebDriverWait
import traceback
import timeclass WebEngine:#...def config(self):self.engine=webdriver.Firefox()#设置页面加载最大时限self.engine.set_page_load_timeout(10)#脚本执行最大时限self.engine.set_script_timeout(10)使用while循环有限次数尝试首次超时意外的重置连接。
def run(self):retry=0# 手动控制是否关闭flag=Truepageend=Falsewhile retry<3 and flag and not pageend:try:retry+=1 #...self.dosomething()except:#...在while循环内,单独捕获WebDriver控制内核驱动geckodriver加载网页超时的异常exception。
def dosomething(self):try:self.engine.get(url)#最久等待5秒 self.engine.implicitly_wait(5) except:#...self.continuetodosomething()self.pagingandrepeatabove()在while循环内,使用WebDriverWait等待指定页面元素加载。如果定位页面元素超时,则被while循环体内的try-except捕捉;若无异常exception发生,而定位的元素不符合逻辑,通过while循环重置连接。
def continuetodosomething(self):by=By.IDtarget='content'wait=WebDriverWait(self.engine, 5)targetelement=wait.until(ECS.presence_of_element_located((by, target)))if None==targetelement or []==targetelement:#置于此处仅为方便描述过程continuelasturl=self.engine.current_url通过点击元素事件的翻页过程和重复上述业务逻辑。
def pagingandrepeatabove(self):maxpages=100pager=1maxclicks=3clicks=0internaltry=0while not pageend and pager<=maxpages and internaltry<3: clicks=0clickok=True#最大点击次数 while last==self.engine.current_url and clickok and clicks<maxclicks:try:clicks+=1clickelement=self.engine.find_element(clickby, clicktarget)if clickelement==None or clickelement==[]:print('url', self.engine.current_url, 'no click element')continue#修正以下三行缩进问题,于2021/6/8 Tue.clickelement.click()time.sleep(.1)clickok=Falseexcept TimeoutException:#修正以下两行缩进问题,于2021/6/8 Tue.print('url', self.engine.current_url, 'loading page time out.')clickok=lasturl==self.engine.current_urlexcept Exception:#修正以下两行缩进问题,于2021/6/8 Tue.traceback.print_exc()print('url', self.engine.current_url, 'click exception')time.sleep(.899)if clickok or clicks>=maxclicks:print('url', self.engine.current_url, 'maxclick')#最大尝试重置连接次数internaltry+=1 continuetargetelement=wait.until(ECS.presence_of_element_located((by, target)))if None==targetelement or []==targetelement:internaltry+=1continuelasturl=self.engine.current_url以CSDN为目标进行测试:

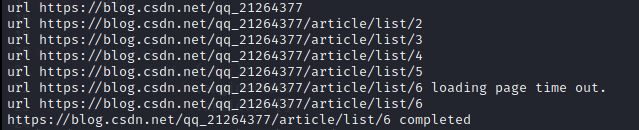
![[转载]使用IntelliJ IDEA开发SpringMVC网站(一)开发环境](https://image-static.segmentfault.com/304/403/3044038503-5c666c973c254_articlex)