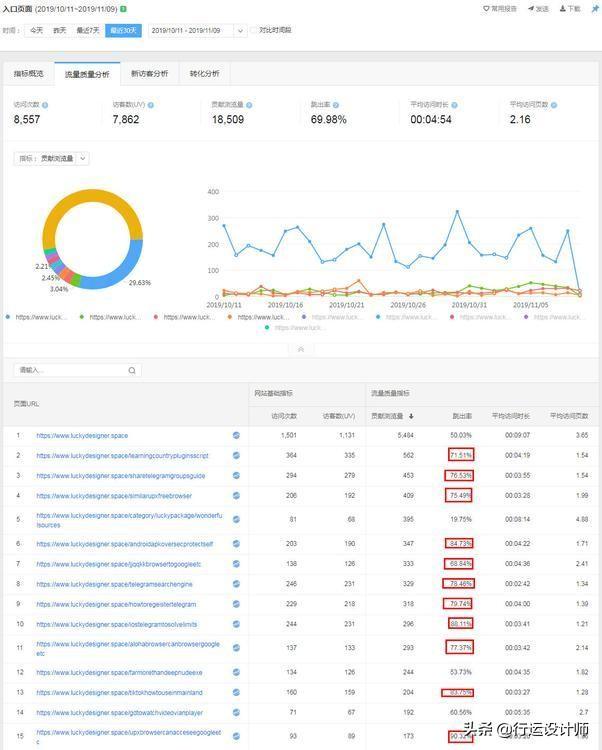
优书网是一个老白常用的第三方小说点评网站
首先爬取优书网–>书库
通过书库翻页来获得书籍相关信息
def get_url():url = "http://www.yousuu.com/bookstore/?channel&classId&tag&countWord&status&update&sort&page="headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3534.4 Safari/537.36'}html = requests.get(url+"1",headers=headers)html.encoding = "UTF-8"js_info = xpathnode(html)js_info = js_info.get('Bookstore')account_info = js_info.get('total')pages = math.ceil(float(account_info/20)) #get the upper integerurl = [url+str(i+1) for i in range(pages)] #this is the array of waited crawl url ,just return to another blockreturn pages,urldef xpathnode(html): #return the structure of json datatree = etree.HTML(html.text)node = tree.xpath('//script/text()') #get the account of booksinfo = node[0][25:-122]js_info = json.loads(info)return js_infodef crawl(): #the corepages,url_combine = get_url()conn = conn_sql()create_tab(conn)cursor = conn.cursor()flag = 0for url in url_combine: #page turningflag = flag+1headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3534.4 Safari/537.36'}html = requests.get(url,headers=headers)html.encoding = "UTF-8"book_js_info = xpathnode(html)book_js_info = book_js_info.get('Bookstore')book_js_info = book_js_info.get('books')print('rate of progress:'+str(round(flag*100/pages,2))+'%') #rate of progressfor i in range(20): #scanning the pagetry:book = book_js_info[i]dt = {'bookId':book.get('bookId'),'title':book.get('title'),'score':book.get('score'),'scorerCount':book.get('scorerCount'),'author':book.get('author'),'countWord':str(round(book.get('countWord')/10000,2)),\'tags':str(book.get('tags')).translate(str.maketrans('', '', '\'')),\'updateAt':book.get('updateAt')[:10]}store_to_sql(dt,conn,cursor)except:print('erro')cursor.close()conn.close()
存入SQL server数据库:(使用时可更改自己数据库参数的设置)
def store_to_sql(dt,connect,cursor): #insert or just change the informationtbname = '['+record+']'ls = [(k,v) for k,v in dt.items() if k is not None]sentence = 'IF NOT EXISTS ( SELECT * FROM '+tbname+' WHERE bookId = '+str(ls[0][1])+') \INSERT INTO %s (' % tbname +','.join([i[0] for i in ls]) +') VALUES (' + ','.join(repr(i[1]) for i in ls) + ');'cursor.execute((sentence))connect.commit()return ""def create_tab(conn): #create table(if not exists)cursor = conn.cursor()sentence = 'if not exists (select * from sysobjects where id = object_id('+record+')and OBJECTPROPERTY(id, \'IsUserTable\') = 1) \CREATE TABLE\"'+record+'\"\(NUM int IDENTITY(1,1),\bookId INT NOT NULL,\title VARCHAR(100),\score VARCHAR(100),\scorerCount float,\author VARCHAR(50),\countWord float ,\tags VARCHAR(100),\updateAt date) 'cursor.execute(sentence)conn.commit()cursor.close()def conn_sql():server = "127.0.0.1"user = "sa"password = "123456"conn = pymssql.connect(server, user, password, "novel")return conn
爬取结果:
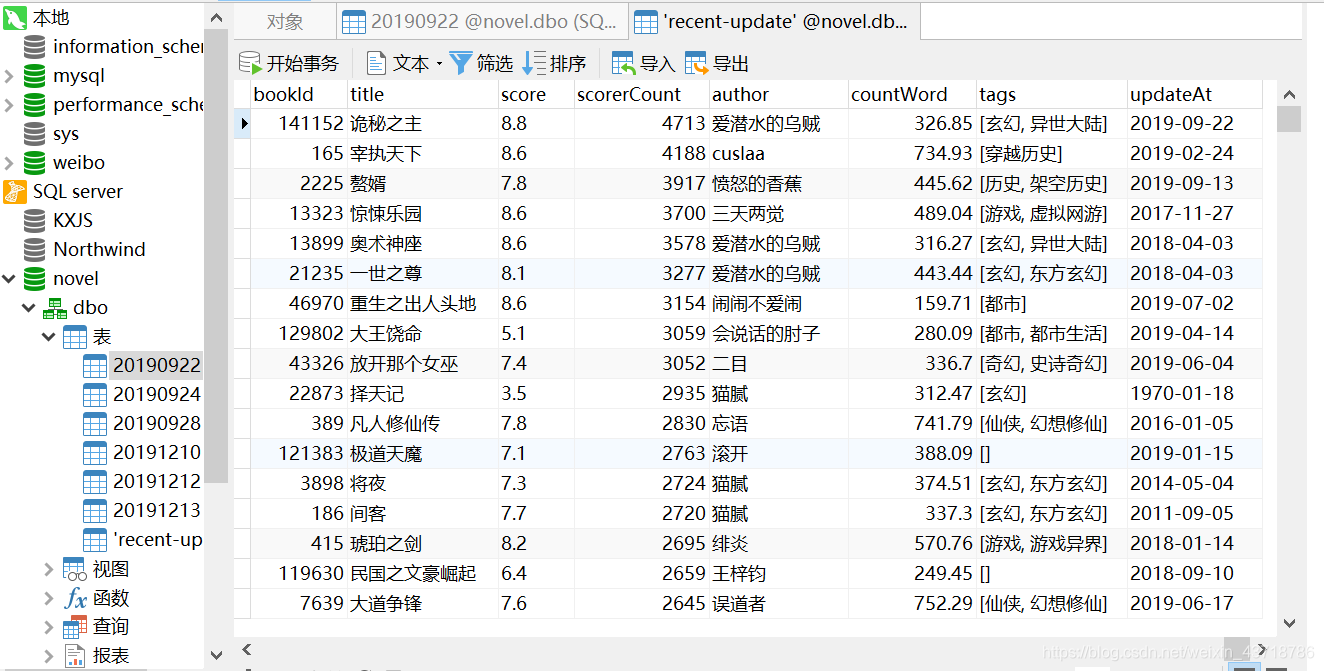
注意,优书网更新后限制了爬虫,需要增加一个sleep()人为每次爬取的增加时间间隔。
全部代码:
# -- coding: gbk --
import json
import requests
import csv
import numpy
import json
import math
from lxml import etree
import pymssql
import datetime#爬取数据并存入sql数据库
record = str(datetime.date.today()).translate(str.maketrans('','','-')) #date of today
def get_url():url = "http://www.yousuu.com/bookstore/?channel&classId&tag&countWord&status&update&sort&page="headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3534.4 Safari/537.36'}html = requests.get(url+"1",headers=headers)html.encoding = "UTF-8"js_info = xpathnode(html)js_info = js_info.get('Bookstore')account_info = js_info.get('total')pages = math.ceil(float(account_info/20)) #get the upper integerurl = [url+str(i+1) for i in range(pages)] #this is the array of waited crawl url ,just return to another blockreturn pages,urldef xpathnode(html): #return the structure of json datatree = etree.HTML(html.text)node = tree.xpath('//script/text()') #get the account of booksinfo = node[0][25:-122]js_info = json.loads(info)return js_infodef crawl(): #the corepages,url_combine = get_url()conn = conn_sql()create_tab(conn)cursor = conn.cursor()flag = 0for url in url_combine: #page turningflag = flag+1headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3534.4 Safari/537.36'}html = requests.get(url,headers=headers)html.encoding = "UTF-8"book_js_info = xpathnode(html)book_js_info = book_js_info.get('Bookstore')book_js_info = book_js_info.get('books')print('rate of progress:'+str(round(flag*100/pages,2))+'%') #rate of progressfor i in range(20): #scanning the pagetry:book = book_js_info[i]dt = {'bookId':book.get('bookId'),'title':book.get('title'),'score':book.get('score'),'scorerCount':book.get('scorerCount'),'author':book.get('author'),'countWord':str(round(book.get('countWord')/10000,2)),\'tags':str(book.get('tags')).translate(str.maketrans('', '', '\'')),\'updateAt':book.get('updateAt')[:10]}store_to_sql(dt,conn,cursor)except:print('erro')cursor.close()conn.close()def store_to_sql(dt,connect,cursor): #insert or just change the informationtbname = '['+record+']'ls = [(k,v) for k,v in dt.items() if k is not None]sentence = 'IF NOT EXISTS ( SELECT * FROM '+tbname+' WHERE bookId = '+str(ls[0][1])+') \INSERT INTO %s (' % tbname +','.join([i[0] for i in ls]) +') VALUES (' + ','.join(repr(i[1]) for i in ls) + ');'cursor.execute((sentence))connect.commit()return ""def create_tab(conn): #create table(if not exists)cursor = conn.cursor()sentence = 'if not exists (select * from sysobjects where id = object_id('+record+')and OBJECTPROPERTY(id, \'IsUserTable\') = 1) \CREATE TABLE\"'+record+'\"\(NUM int IDENTITY(1,1),\bookId INT NOT NULL,\title VARCHAR(100),\score VARCHAR(100),\scorerCount float,\author VARCHAR(50),\countWord float ,\tags VARCHAR(100),\updateAt date) 'cursor.execute(sentence)conn.commit()cursor.close()def conn_sql():server = "127.0.0.1"user = "sa"password = "123456"conn = pymssql.connect(server, user, password, "novel")return connif __name__ == '__main__':crawl()