小说网站爬虫第一天
从今天开始,学习一下爬虫的知识,爬取小说网站。
第一天:
网站:http://www.bxwx9.org
小说:大主宰

语言:IDEA+java
jar包:maven工程,所以放上dependencies,每一个jar包的作用大家去研究一下
项目结构:

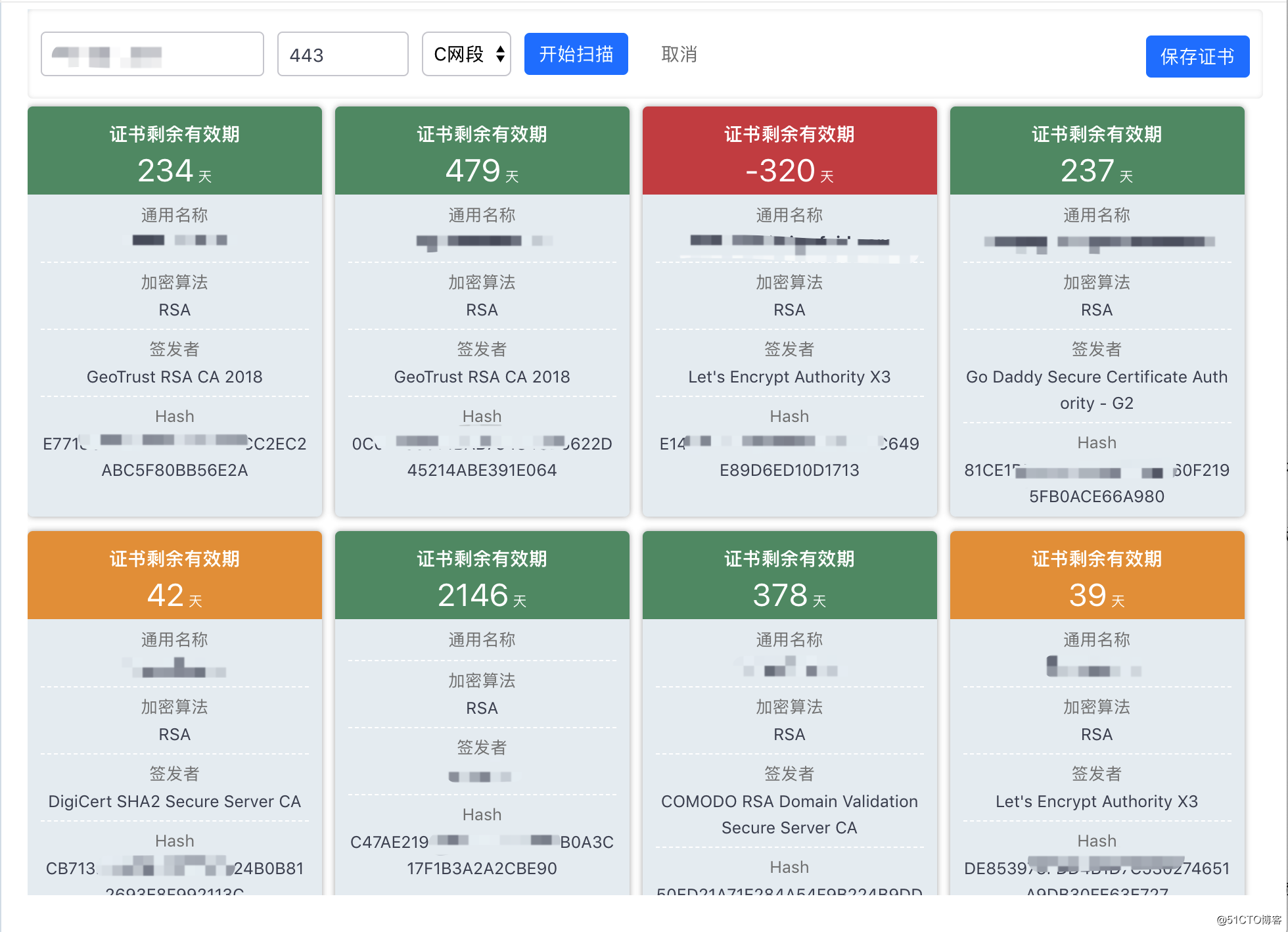
需求:获取小说的章节列表中的标题和URL
原理:
- 用谷歌浏览器F12查看网页的内容,找到章节列表所在的元素

- 使用标签选择器来选择需要的内容

代码如下操作:

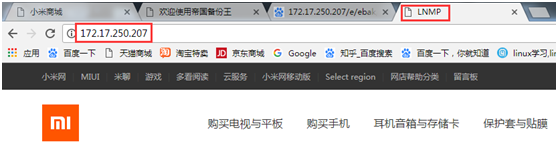
中文乱码的解决:

运行的效果图:
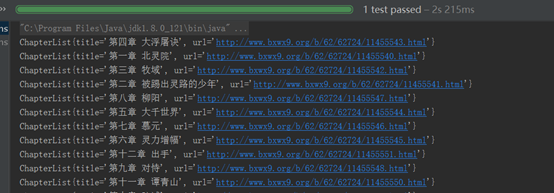
明天继续!!!!
转载于:https://blog.51cto.com/lgzkd/1904394