最近学习了一段时间的Python基础语法后,写了一个爬取世界港口数据的爬虫,并且保存到SQL Server 数据库。
前提
公司之前有个需求是想监控集装箱如果进出某个港口的时候能给出信息提示,并且与海运数据进行对接,达到集装箱从陆运—海运—陆运,整个过程动态监控的目的。
其中有个小的需求是集装箱经过某个港口的时候需要给出消息提醒,以通知先关箱主(货主)。这样就需要知道全世界所有的港口信息有哪些,区域定位信息等。这样利用我们集装箱定位设备+GIS空间地理信息分析就可以实现集装箱进出港口的分析。
爬取网站
http://gangkou.00cha.net

我这里选择的是按国家查询,这个是网站的第一层,选择某个国家后,我们进入第二层

这样就可以得到某个国家所有港口的列表,我们还需要进入第三层得到每个港口详细信息。

所以我们写爬虫的时候需要用三个循环才能得到具体的港口信息。
实现
第一步:我们获取第一层网页数据
#定义一个变量url,为需要爬取数据我网页网址
url = 'http://gangkou.00cha.net/'#获取这个网页的源代码,存放在req中,{}中为不同浏览器的不同User-Agent属性,针对不同浏览器可以自行百度
req = requests.get(url,{'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'})
req.encoding = 'gb2312'
#生成一个Beautifulsoup对象,用以后边的查找工作
soup = BeautifulSoup(req.text,'lxml')#找到所有a标签中的内容并存放在xml这样一个类似于数组队列的对象中
xml = soup.find_all('a')
gj=[]
#查找国家港口的URL
for k in xml:if 'gj_' in k['href']:gj.append(k['href'])我们将国家信息及每个国家港口后面对应的URL进行存储。
第二步:获取每个国家的港口列表
urlgj='http://gangkou.00cha.net/'+l#获取这个网页的源代码,存放在req中,{}中为不同浏览器的不同User-Agent属性,针对不同浏览器可以自行百度reqgj = requests.get(urlgj,{'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'})reqgj.encoding = 'gb2312'#生成一个Beautifulsoup对象,用以后边的查找工作soupgj = BeautifulSoup(reqgj.text,'lxml')#找到所有a标签中的内容并存放在xml这样一个类似于数组队列的对象中xmlgj = soupgj.find_all('a')第三步:遍历这个国家的港口列表,获取每个港口的详细数据
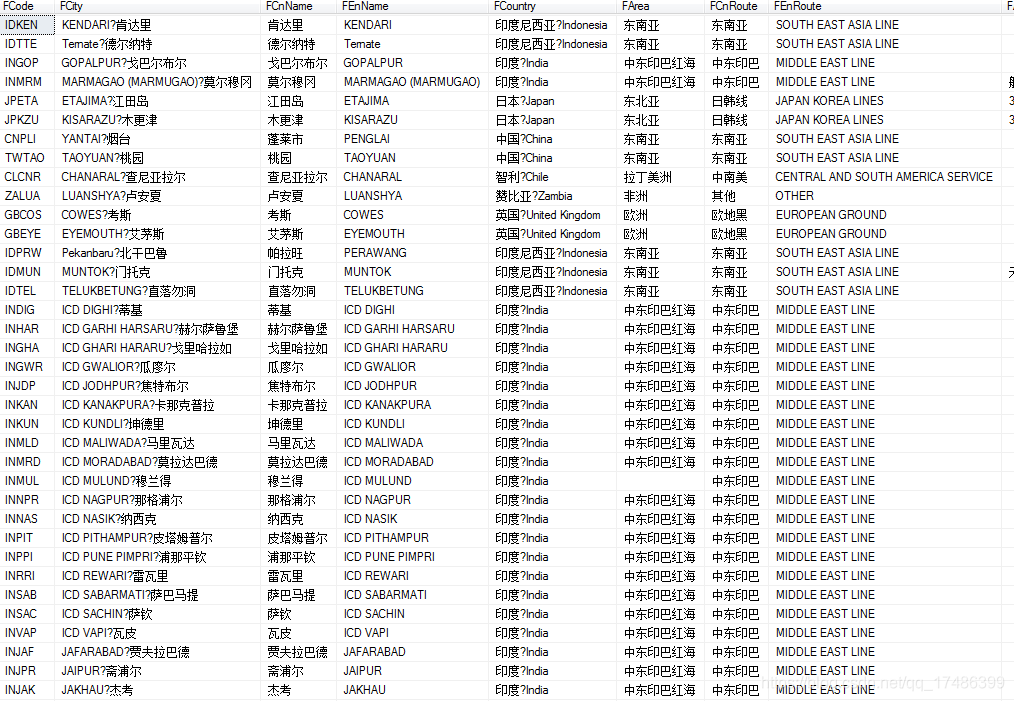
#查找国家港口的URLfor kgj in xmlgj:if 'gk_' in kgj['href']:urlgk='http://gangkou.00cha.net/'+kgj['href']reqgk = requests.get(urlgk,{'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'})reqgk.encoding = 'gb2312'soupgk = BeautifulSoup(reqgk.text,'lxml')#keylatlon1=soupgk.find(key1)trarry=[]for tr in soupgk.find_all('tr'):tdarry=[]for td in tr.find_all('td'):text = td.text.replace('\u3000','').replace(' ',' ')tdarry.append(text)trarry.append(tdarry)keylonlat1='LatLng'#设置经纬度关键字1keylonlat2=");"#设置经纬度关键字2plonlata=reqgk.text.find(keylonlat1)#找出关键字1的位置plonlatt=reqgk.text.find(keylonlat2,plonlata)#找出关键字2的位置(从字1后面开始查找)lonlat=reqgk.text[plonlata:plonlatt+1]#得到关键字1与关键字2之间的内容(即想要的数据)lonlat= re.findall(r'[(](.*?)[)]', lonlat)introarry=[]for introduce in soupgk.find_all('div', class_='bei lh'):if '港口介绍' in introduce.text:introarry.append([introduce.text.replace( '\ufffd','').replace( '\xe6','').replace(' ',' ')])最后导入pymssql库,进行数据保存到SQL Server里面
![[web] 网站压力测试工具-ab工具](http://upload-images.jianshu.io/upload_images/539132-b98dc6d06438b95d.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/494/format/webp)