目录
- 1152 Analyze User Website Visit Pattern 用户网站访问行为分析
- 描述
- 思路
- 代码实现
1152 Analyze User Website Visit Pattern 用户网站访问行为分析
描述
为了评估某网站的用户转化率,我们需要对用户的访问行为进行分析,并建立用户行为模型。日志文件中已经记录了用户名、访问时间以及页面路径。
为了方便分析,日志文件中的 N 条记录已经被解析成三个长度相同且长度都为 N 的数组,分别是:用户名 username,访问时间 timestamp 和 页面路径 website。第 i 条记录意味着用户名是 username[i] 的用户在 timestamp[i] 的时候访问了路径为 website[i] 的页面。
我们需要找到用户访问网站时的 『共性行为路径』,也就是有最多的用户都 至少按某种次序访问过一次 的三个页面路径。需要注意的是,用户 可能不是连续访问 这三个路径的。
『共性行为路径』是一个 长度为 3 的页面路径列表,列表中的路径 不必不同,并且按照访问时间的先后升序排列。
如果有多个满足要求的答案,那么就请返回按字典序排列最小的那个。
(页面路径列表 X 按字典序小于 Y 的前提条件是:X[0] < Y[0] 或 X[0] == Y[0] 且 (X[1] < Y[1] 或 X[1] == Y[1] 且 X[2] < Y[2]))
题目保证一个用户会至少访问 3 个路径一致的页面,并且一个用户不会在同一时间访问两个路径不同的页面。
- 示例:
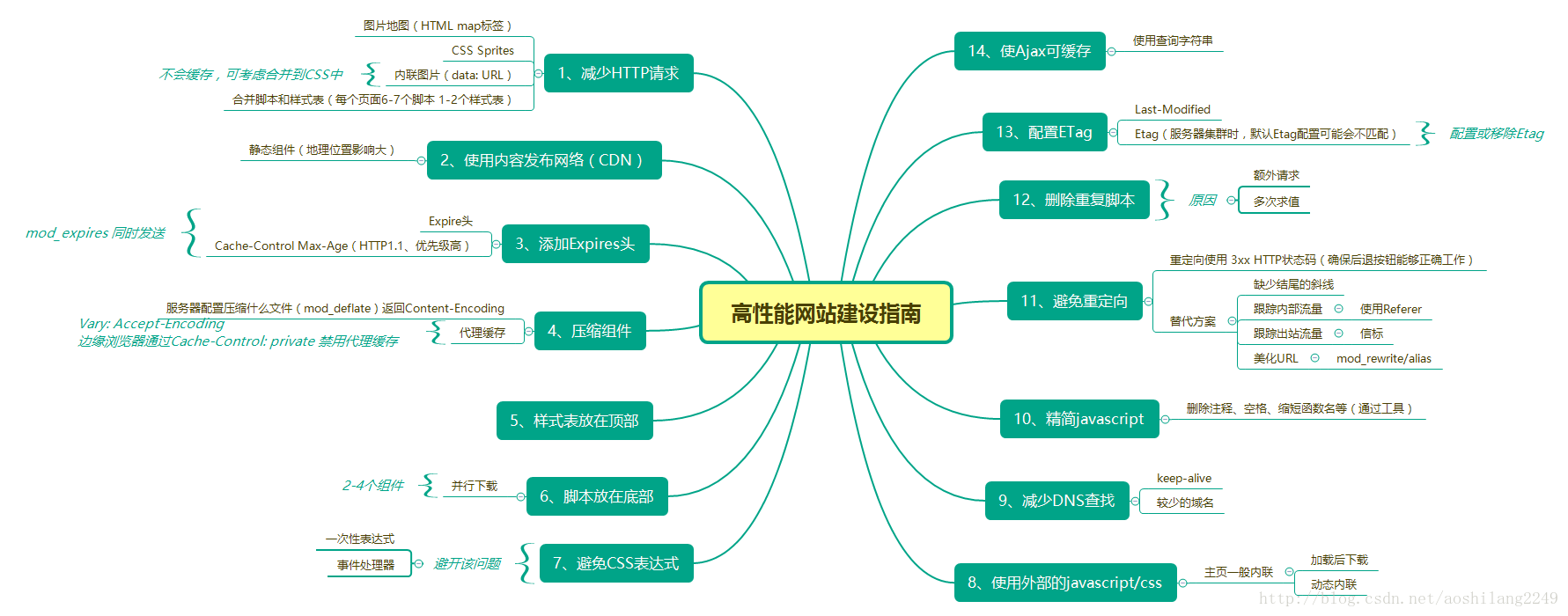
输入:username = ["joe","joe","joe","james","james","james","james","mary","mary","mary"],
timestamp = [1,2,3,4,5,6,7,8,9,10],
website = ["home","about","career","home","cart","maps","home","home","about","career"]
输出:["home","about","career"]
解释:
由示例输入得到的记录如下:
["joe", 1, "home"]
["joe", 2, "about"]
["joe", 3, "career"]
["james", 4, "home"]
["james", 5, "cart"]
["james", 6, "maps"]
["james", 7, "home"]
["mary", 8, "home"]
["mary", 9, "about"]
["mary", 10, "career"]
有 2 个用户至少访问过一次 ("home", "about", "career")。
有 1 个用户至少访问过一次 ("home", "cart", "maps")。
有 1 个用户至少访问过一次 ("home", "cart", "home")。
有 1 个用户至少访问过一次 ("home", "maps", "home")。
有 1 个用户至少访问过一次 ("cart", "maps", "home")。
- 提示:
3 <= N = username.length = timestamp.length = website.length <= 50
1 <= username[i].length <= 10
0 <= timestamp[i] <= 10^9
1 <= website[i].length <= 10
username[i] 和 website[i] 都只含小写字符
思路
暴力枚举每个用户的顺序网页访问路径(有三个页面)
选出访问路径出现最多次数的那个 或者 字典序排列最小的那个
代码实现
重要存储结构示意图如下: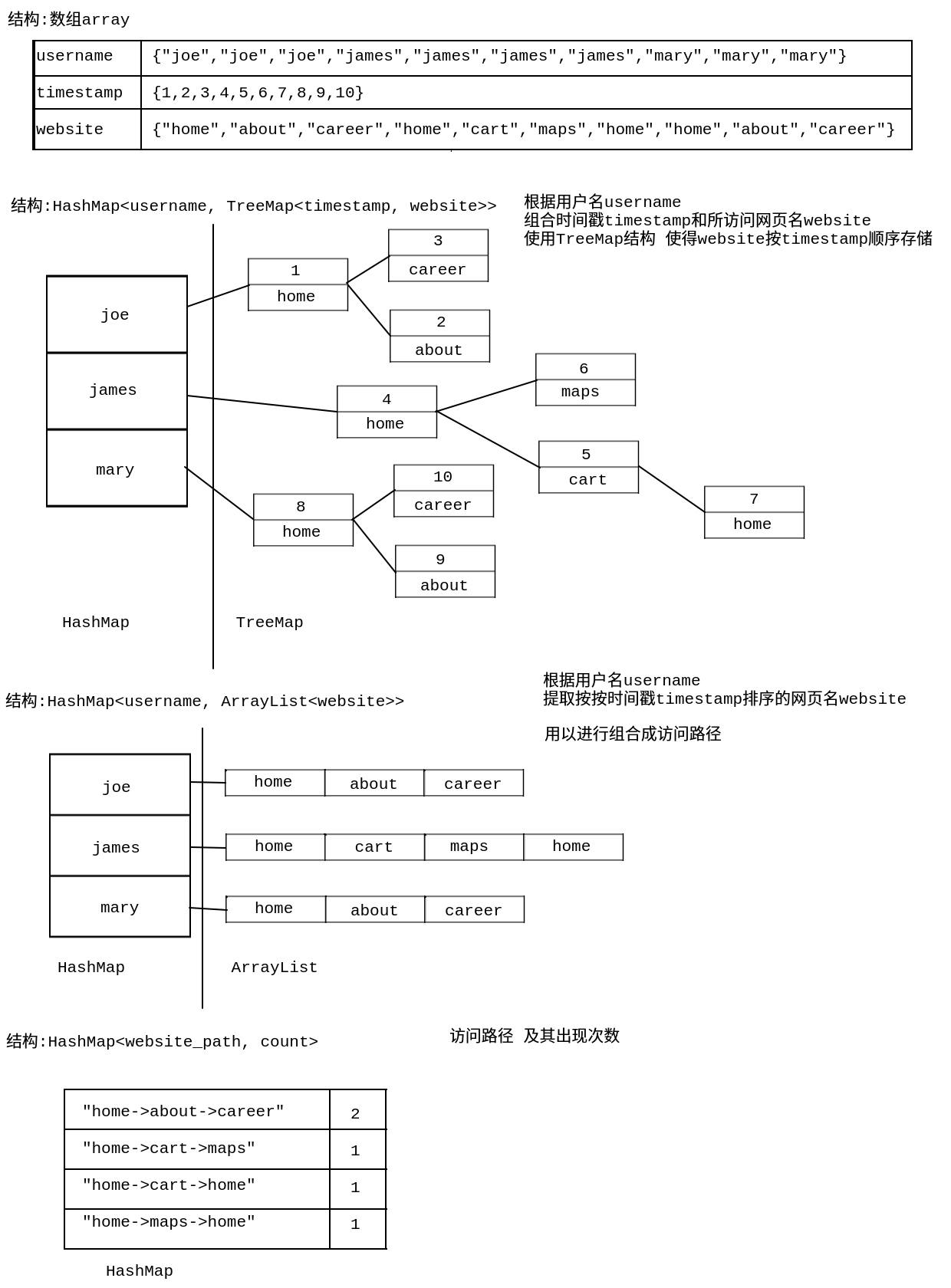
暴力枚举每一用户访问路径并投票
class Solution {public List<String> mostVisitedPattern(String[] username, int[] timestamp, String[] website) {// utwRecords 根据用户名username组合三个数组 <username, <timestamp, website>>// 注意内部使用TreeMap 是为了排序 时间戳timestamp的按顺序排列HashMap<String, TreeMap<Integer, String>> utwRecords = new HashMap<>();for (int i = 0; i < username.length; i++) {if (!utwRecords.containsKey(username[i])) {utwRecords.put(username[i], new TreeMap<Integer, String>());}utwRecords.get(username[i]).put(timestamp[i], website[i]);}// uwRecords 提取utwRecords中除时间戳timestamp的数据 // 用户名username以及对应访问的网页website(按时间戳排序)HashMap<String, ArrayList<String>> uwRecords = new HashMap<>();for (String name : utwRecords.keySet()) {uwRecords.put(name, new ArrayList<String>());for (Integer time : utwRecords.get(name).keySet()) {uwRecords.get(name).add(utwRecords.get(name).get(time));}}// cntWP 存储所枚举的每一条网页访问路径 并计录其出现的次数// <网页访问路径(3个网页名称合成1条字符串), 出现次数>HashMap<String, Integer> cntWP = new HashMap<>();// maxCnt 网页访问路径出现最多次数为int maxCnt = 0;// res 最多次数的网页访问路径(3个网页名称合成1条字符串)String res = new String();for (String name : uwRecords.keySet()) {// len 当前用户所访问的网页数int len = uwRecords.get(name).size();// single 存储当前用户所访问网页的访问路径 并去重HashSet<String> single = new HashSet<>();for (int i = 0; i < len-2; i++) {for (int j = i+1; j < len-1; j++) {for (int k = j+1; k < len; k++) {// 网页访问路径格式: A-->B-->CString cur = (new StringBuilder()).append(uwRecords.get(name).get(i)).append("->").append(uwRecords.get(name).get(j)).append("->").append(uwRecords.get(name).get(k)).toString();single.add(cur);}}}// 遍历当前用户所访问网络的路径 存储并给访问路径计数for (String str : single) {if (!cntWP.containsKey(str)) {cntWP.put(str, 0);}cntWP.put(str, cntWP.get(str)+1);int curCnt = cntWP.get(str);// 当该访问路径出现次数curCnt大于最大访问次数maxCnt // 那么结果路径res就是该路径// 或者// 当该访问路径出现次数curCnt等于最大访问次数maxCnt 且字典序小于原出现次数最多的路径res // 那么结果路径res就是该路径if (curCnt > maxCnt | (curCnt == maxCnt && str.compareTo(res) < 0)) {maxCnt = curCnt;res = str;}}}// ans 存储所求结果访问路径的3个网页// 其实也可以使用 Arrays.asList(res.split("->"))ArrayList<String> ans = new ArrayList<>();for (String str : res.split("->")) {ans.add(str);}return ans;}
}