大家好,我是小张~
之前写过一篇博文介绍了一款OCR 识别库,识别精度能达到商用级别,并且支持多语言识别,使用详情请参考文章:文本OCR,这个Python库识别效果不输于商用!,
除了PaddleOCR之外,之前还介绍过一些其它好玩的开源项目,例如老照片修复 Bringing-Old-Photos-Back-to-Life 、黑白照片上色DeOldify 。因此,最近准备启动一个项目,做一个在线网站,将之前一些好玩的功能都陆续集成在这个网站中
本篇文章将介绍网站第一个功能模块:图片OCR识别,识别功能借助于PaddleOCR,后端使用Django框架,前端主要借助Element-PLus + Vue 实现,这个模块虽然没有用到数据库存储功能,但由于是 Django框架需要借助MySQL 实现项目初始化。
OCR识别整体流程:网站提供一个图片上传入口,用户将识别后的图片上传后,网站后台在1~2秒后返回图片的识别结果,效果如下:
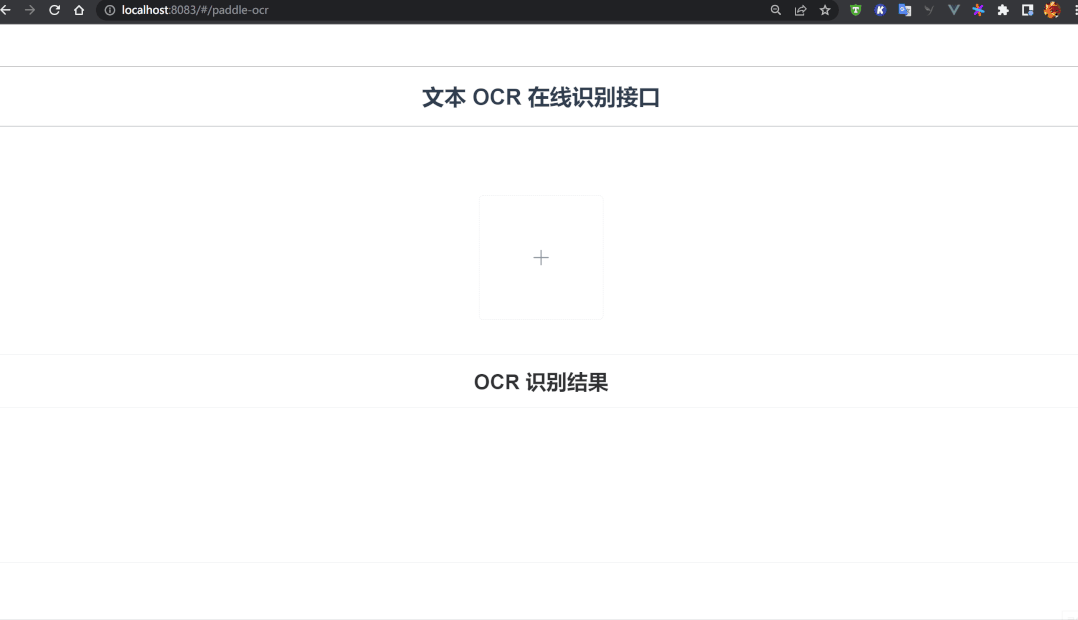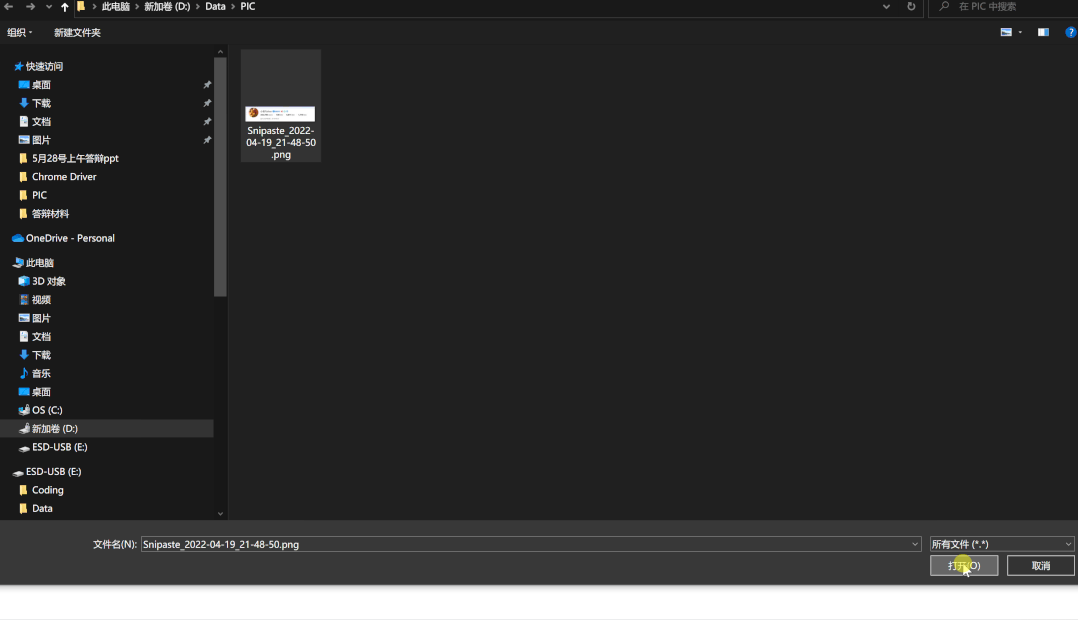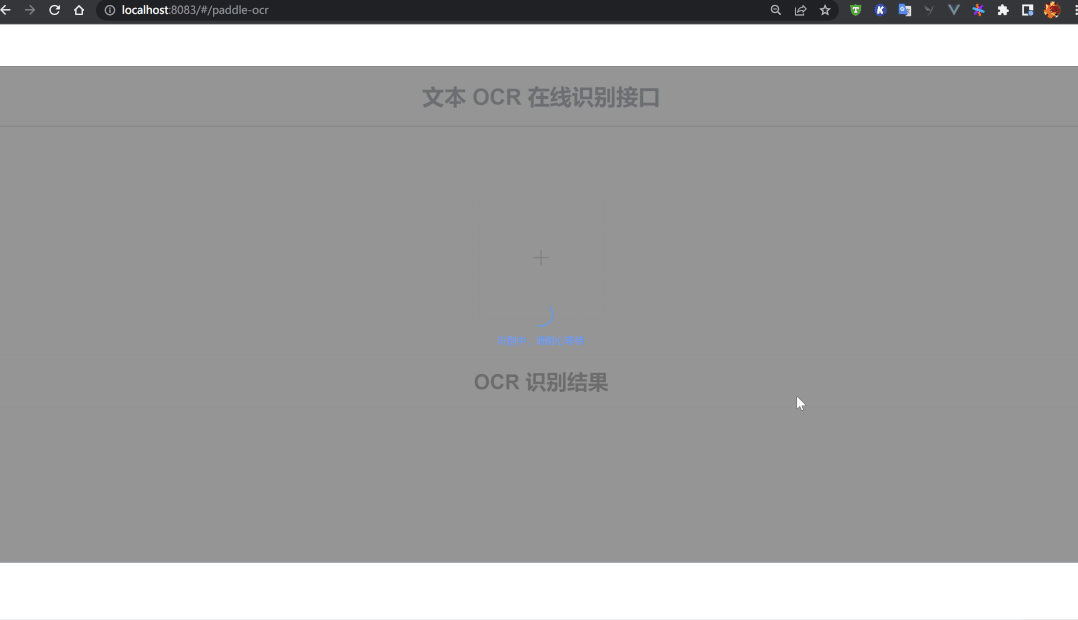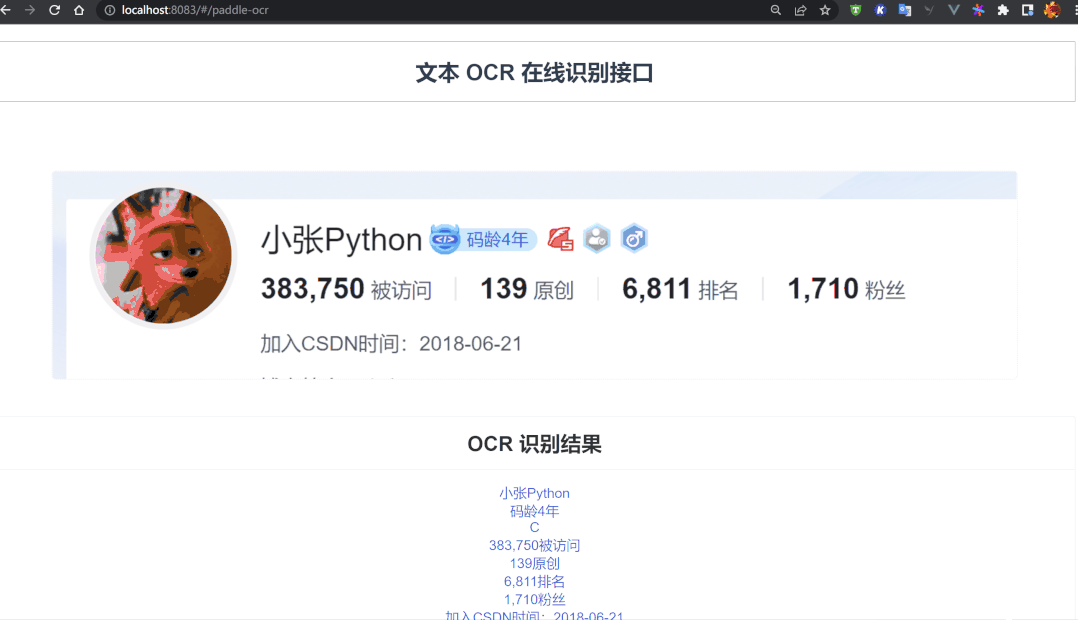
页面整体布局
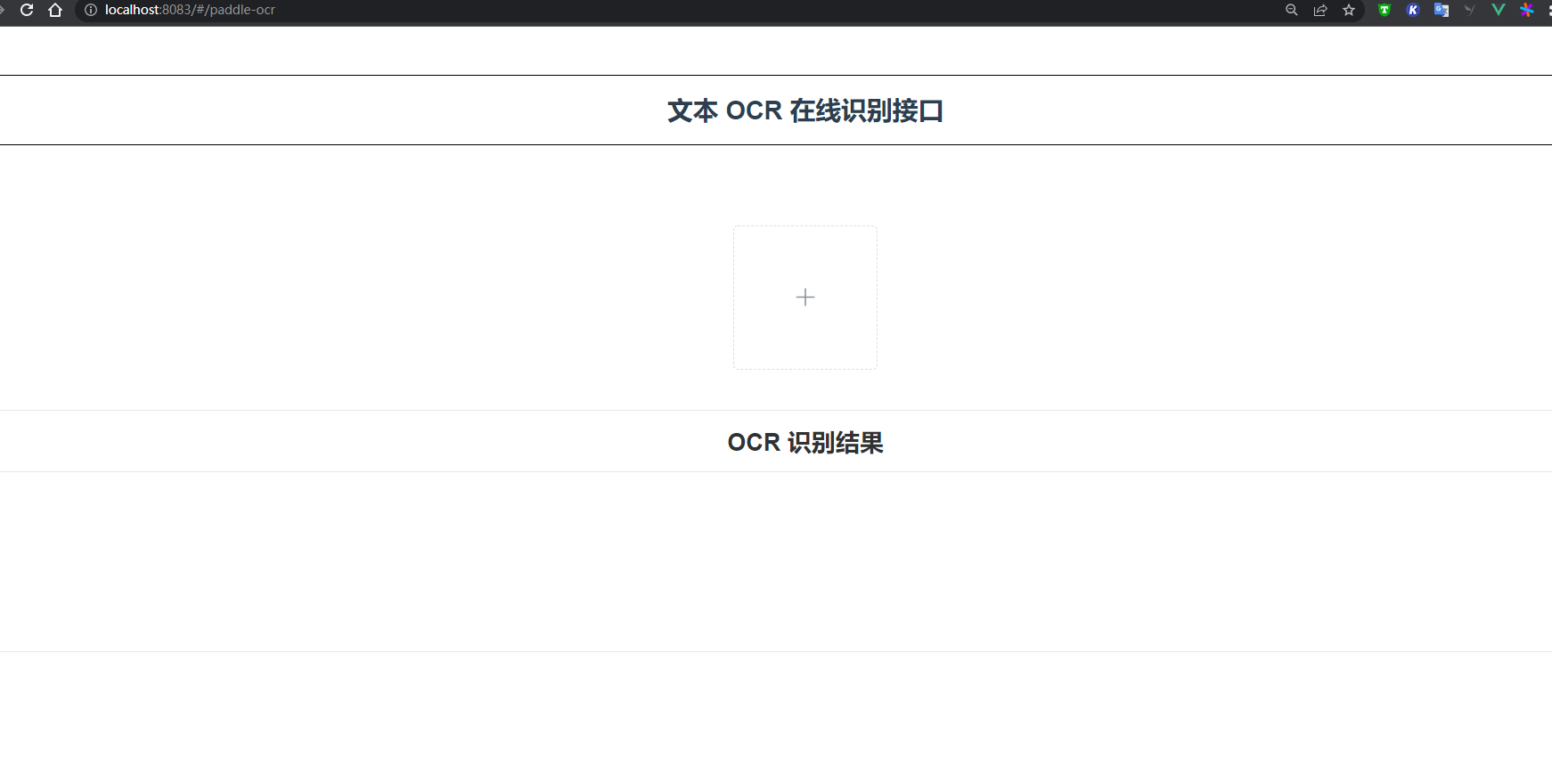
文字识别中页面:
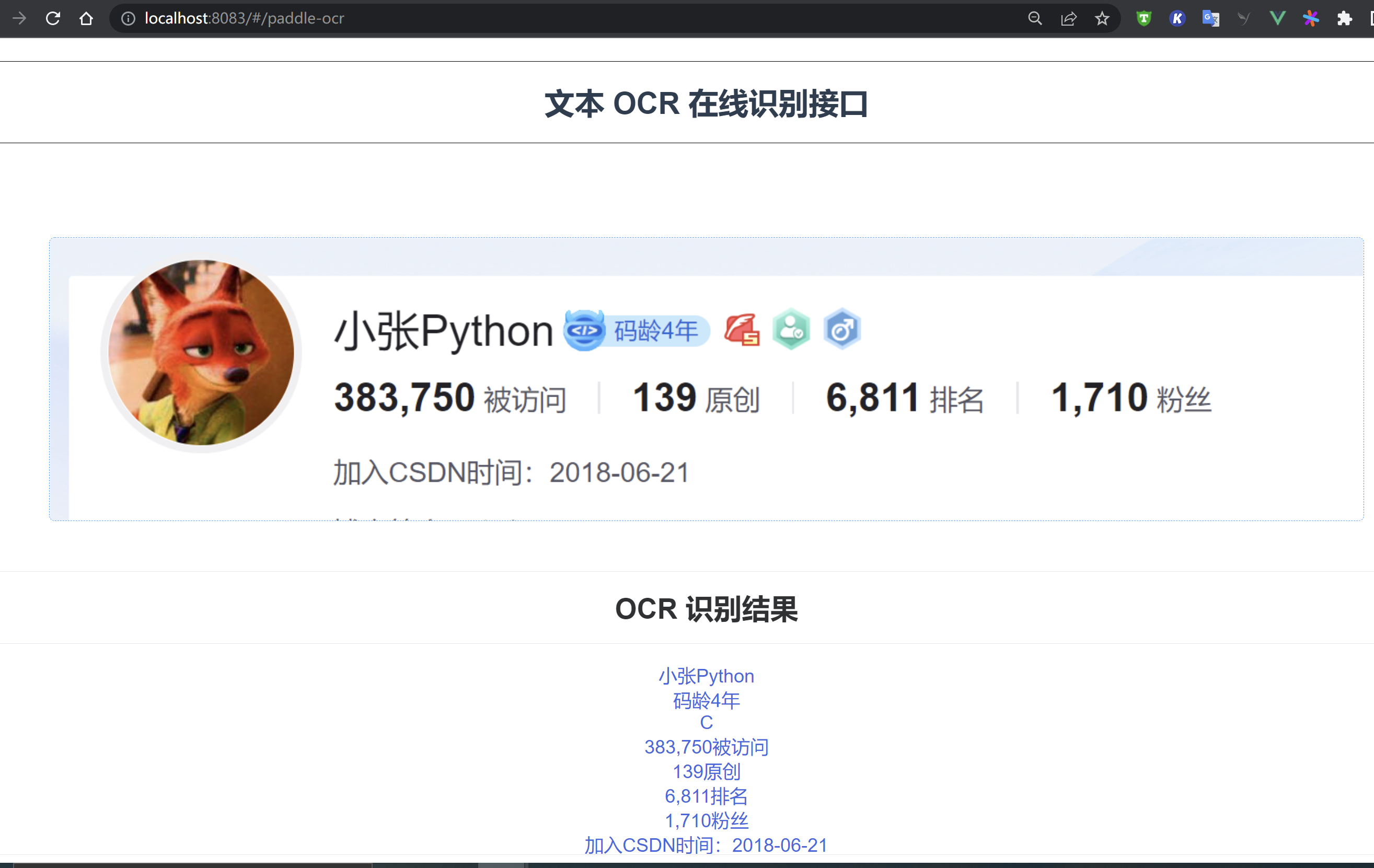
OCR识别完成:
一,Django项目初始化
- 1.1,检查 Django 环境
python -m django --version
若终端显示版本号,未出现 No module named django,即可证明已安装成功~,Django安装方法参考以下连接
https://docs.djangoproject.com/zh-hans/4.0/

- 1.2 创建 Django 项目
在 Django 框架中,项目中每个模块叫 app,每个 app 负责一个模块功能,例如博客中的评论模块;所有 app 组合在一起形成整个项目 project,因此首先,创建一个项目 dlIntegrated(命名随意)
django-admin startproject dlIntegrated
- 创建后目录树形结构如下
dlIntegrated│ manage.py│└─dlIntegratedasgi.pysettings.pyurls.pywsgi.py__init__.py
cd 到 manage.py 同级的目录下,终端运行
python manage.py runserver
终端无报错,浏览器输入 http:\localhost:8080,进入 django 初始化页面,即可代表 django 启动成功
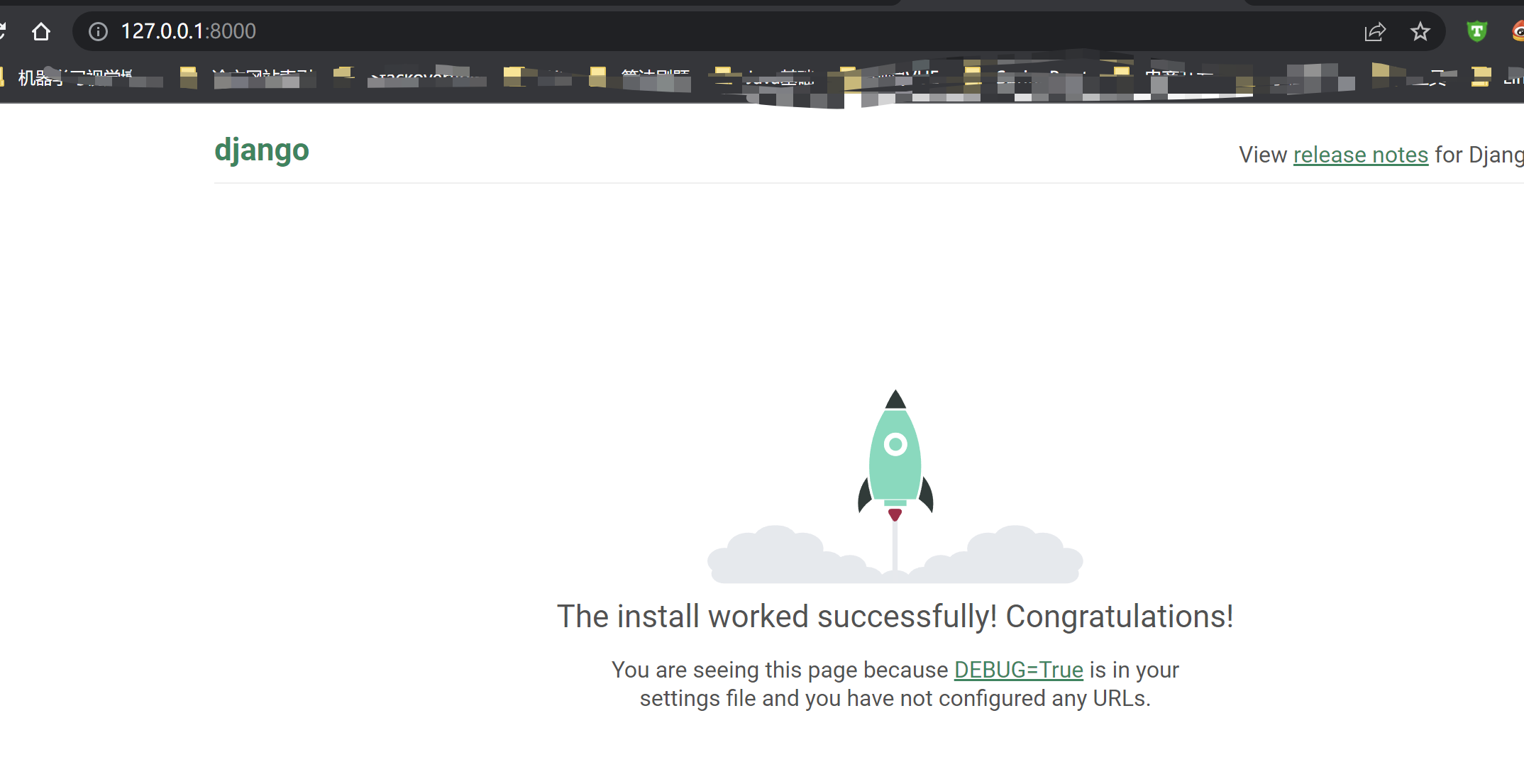
- 1.3,创建 app
cd 到与 manage.py 同级的目录下,输入以下命令:
python manage.py startapp paddleApp
运行成功后,目录树结构如下:
│ manage.py
│
├─dlIntegrated
│ │ asgi.py
│ │ settings.py
│ │ urls.py
│ │ wsgi.py
│ │ __init__.py
│ │
│ └─__pycache__
│ settings.cpython-37.pyc
│ __init__.cpython-37.pyc
│
└─paddleApp│ admin.py│ apps.py│ models.py│ tests.py│ views.py│ __init__.py│└─migrations__init__.py
- 1.4,配置
dlIntegrated/setting.py配置项,连接数据库,连接App等
找到 DATABASES
DATABASES = {'default': {'ENGINE': 'django.db.backends.mysql','USER':'root','HOST':'localhost','NAME':'dl_intergate','PASSWORD':'root','TIME_ZONE':'Asia/Shanghai'}
}
找到 INSTALLED_APPS,加入app选项paddleApp.apps.PaddleappConfig(根据自己项目调整)
INSTALLED_APPS = ['paddleApp.apps.PaddleappConfig','django.contrib.admin','django.contrib.auth','django.contrib.contenttypes','django.contrib.sessions','django.contrib.messages','django.contrib.staticfiles',
]
二,安装 PaddleOCR
之前介绍 PaddleOCR 时,需要经过Github 代码仓库拉项目、配环境、写demo一系列步骤,然后才能正常使用;PaddleOCR 项目源于百度,经过多次迭代后目前已经被封装为一个Python库,安装时借助 pip 工具即可
- 2.1,pip 安装 PaddleOCR:
# GPU版本
python3 -m pip install paddlepaddle-gpu# CPU版本
python3 -m pip install paddlepaddle
需要注意的是,如果项目用GPU版本时,需要保证 GPU 环境配置好,例如 CUDA、Cudnn等
- 2.2,安装 PaddleOCR Whl 包
pip install "paddleocr>=2.0.1" # Recommend to use version 2.0.1+
安装 paddleocr 时可能会报错,这里我记录了我配置时遇到的一些错误(Windows 环境),有遇到相同错误的可以参考下:“basetsd.h”: No such file or directory,LINK : fatal error LNK1158: 无法运行“rc.exe”报错
三,Django完善视图,url模块
- 3.1,views 视图中实现识别核心模块:
def ocr_detect(filePath:str):'''orc识别'''print("filePath is ",filePath)ocr = PaddleOCR(use_angle_cls=True, lang='ch') # need to run only once to download and load model into memoryresult = ocr.ocr(filePath, cls=True)result_list = result(path,fileName) = os.path.split(filePath)image = Image.open(filePath).convert('RGB')boxes = [line[0] for line in result]txts = [line[1][0] for line in result]scores = [line[1][1] for line in result]im_show = draw_ocr(image, boxes, txts, scores, font_path='./template/fonts/Deng.ttf')im_show = Image.fromarray(im_show)im_show.save(os.path.join(path,"draw-"+fileName))- 3.2,在app 中的 urls.py 中定义 url 接口
# ProjectName/App/urls.pyfrom django.urls import pathfrom . import viewsurlpatterns = [path('upload-image',views.paddle_image_upload)]
- 3.3 将app 中 API接口与项目链接
# ProjectName/urls.pyurlpatterns = [path('admin/', admin.site.urls),path('paddleApp/',include('paddleApp.urls'))
]
四,借助Vue对前端项目初始化
- 4.1,这里借助的是 Vue 脚手架,为了提交开发效率借助 Element-Plus 组件库,项目的结构树如下:
│ .gitignore
│ babel.config.js
│ jsconfig.json
│ list.txt
│ package-lock.json
│ package.json
│ README.md
│ tsconfig.json
│ vue.config.js
├─public
│ favicon.ico
│ index.html
│
└─src│ App.vue│ main.ts│ router.ts│ shims-vue.d.ts│ ├─assets│ logo.png│ ├─components│ HelloWorld.vue│ └─page└─paddletextOcrPage.vue
- 4.2,router.ts 定义前端路由
import {createRouter,createWebHashHistory} from 'vue-router'const routes = [{path: '/paddle-ocr',component:()=> import('@/page/paddle/textOcrPage.vue')}
]const router = createRouter({history:createWebHashHistory(),routes
})export default router;
- 4.3,在配置文件
vue.conf.js中定义方向代理,解决跨域问题
module.exports = defineConfig({transpileDependencies: true,devServer: {proxy:{'/api':{target: 'http://localhost:8089',pathRewrite: {'^/api':'',changeOrigin: true}}},port: 8083},// chainWebpack: config => {// // 处理ts文件 (新增loader)// config.module.rule('ts').use('te-loader').end()// }
})
- 4.4,在vue脚本实现页面布局,上传组件实现,上传逻辑编写(以下为部分代码)
<div v-loading="loading" :element-loading-text="loadingText" element-loading-background="rgba(122, 122, 122, 0.8)"><div style="border:1px solid black"><h1>文本 OCR 在线识别接口</h1></div><div style="margin-top:100px"><el-uploadclass="avatar-uploader"action="/api/paddleApp/upload-image":show-file-list="false":on-success="handleAvatarSuccess":before-upload="beforeAvatarUpload"><img v-if="imageUrl" :src="imageUrl" class="avatar" /><el-icon v-else class="avatar-uploader-icon"><Plus></Plus></el-icon></el-upload><el-card shadow="never"><template #header><div class="card-header"><span>OCR 识别结果</span></div></template><div style="text-align: center;font-size: 20px;color:royalblue" v-for="o in resultText" :key="o" class="text item">{{o[1][0] ?o[1][0]:'' }}</div></el-card></div>
</div>
</template><script lang="ts" setup>
import { ref } from 'vue'
import { ElMessage } from 'element-plus'
import { Plus } from '@element-plus/icons-vue'
import type { UploadProps } from 'element-plus'const imageUrl = ref('')
const resultText = ref('')
const loading = ref(false)
const loadingText = ref('识别中,请耐心等待')const handleAvatarSuccess: UploadProps['onSuccess'] = (response,uploadFile
) => {const resultData = response.dataresultText.value = resultData.resultimageUrl.value = URL.createObjectURL(uploadFile.raw!)loading.value =false}
const beforeAvatarUpload: UploadProps['beforeUpload'] = (rawFile) => {if (!(rawFile.type === 'image/jpeg' || rawFile.type === 'image/png')) {ElMessage.error('Avatar picture must be JPG format!')return false} else if (rawFile.size / 1024 / 1024 > 2) {ElMessage.error('Avatar picture size can not exceed 2MB!')return false}loading.value = truereturn true
}
</script>五,小结
好了,以上就是本篇文章的全部内容了,本文涉及的内容知识较多,适合收藏下来慢慢吸收:😛,由于 Python 语言也有自身的局限性,因此在项目中引入 Vue、JS等作为前端界面实现,搭建一个前后端分离网站
这里在项目中引入了 OCR图片 识别功能,后面将会计划把一些其它功能加进来,例如Excel上传,读写;图像分割,经纬度转换等,带大家一起来完善这个项目
最后,项目源码获取方式,关注微信公号:小张Python 后台回复关键字:dl_interated 即可






![[Python爬虫]模拟登陆**查网站](https://img-blog.csdn.net/20180921171042868?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FzaGVyMTE3/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)