接下来就是
学习 python 的正确姿势

有人说了
不就是把字体通过 unicode 编码吗?
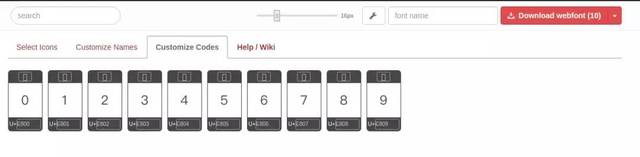
那就简单了啊
把每个字的编码找到
然后使用字典把编码和对应的字对应起来
抓取分析的时候
直接替换不就得了

有道理是有道理
但是
如果我每次返回给你的编码都不一样呢?
你说死不死

好了好了,先别哭得那么舒服
我们来看看天猫电影票房榜单的页面
https://maoyan.com/board/1
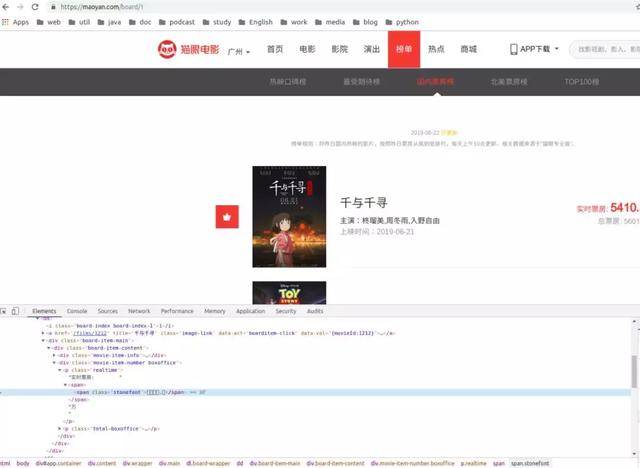

正如你所看到的那样
这里也使用了字体加密
通过源代码我们可以看到
font-face这里制定了字体文件路径

还是熟悉的配方
熟悉的味道~

不过小老弟
还是不要开心太早
刷新几次你就会发现
(盯着下图 2 秒钟)
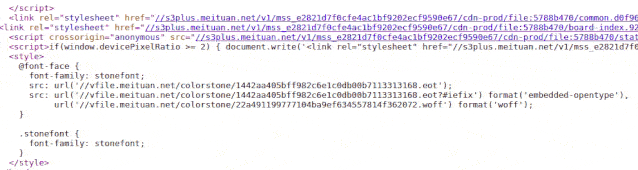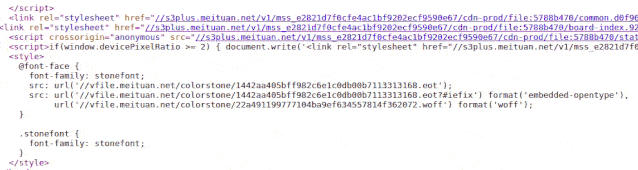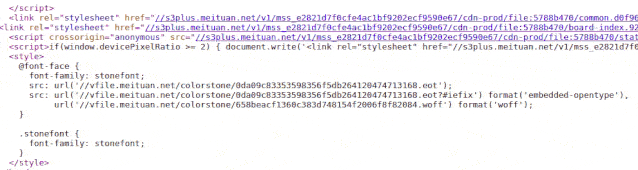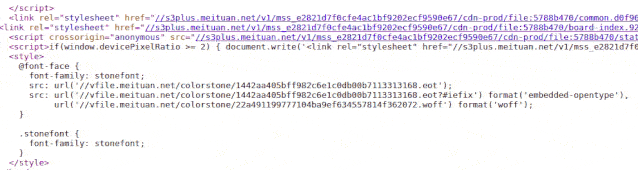
看到没有
字体文件一直在变
woc!
玩呢?


我们先把字体文件下载下来
# 把整个页面搞下来
url = 'https://maoyan.com/board/1'
html = download_html(url).decode('utf-8')
用正则把字体文件名拿一下
font_file_name = re.findall(r'//vfile.meituan.net/colorstone/(w+.woff)', html)[0]
拿到了文件名之后就构建一下url
然后把字体文件下载下来
url = 'http://vfile.meituan.net/colorstone/' + font_file_name
font_file = download_html(url)
接着把字体文件写到本地文件中
with open('fonts/' + font_file, 'wb') as f:
f.write(new_file)
使用 fontTools 来获取字体
如果你之前没安装的话要安装才能用
接着我们把字体文件保存为 xml
font = TTFont('fonts/' + font_file)
font.saveXML('./'+font_file+'.xml')

快打开打开看看
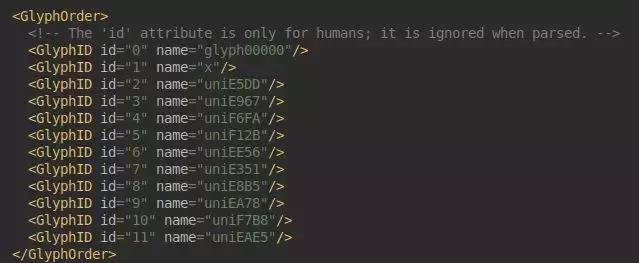
哇,这些玩意
有点眼熟啊
这不就是加密的 unicode 码么
左边的 id 难道就是对应的数字?

恩没那么简单
就能找到聊得来的伴
尤其是在看过了那么多背叛
总是....

不好意思
走错片场了
回到我们刚刚的 xml 文件
往下拉一下
可以看到这个
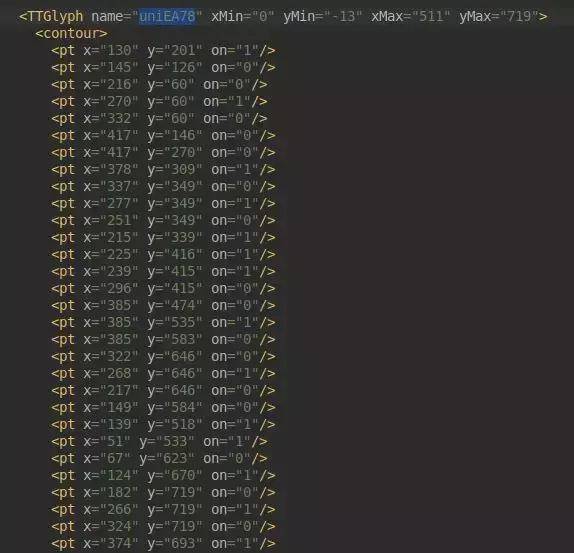
这里每一个编码都对应一个 TTGlyph 对象
从各种 x y 坐标可以猜测
它应该是用来绘制一个字的
我们把任意一个对象复制一下
然后用 matplotlib 根据坐标画个图试试看
import matplotlib.pyplot as plt
import re
str = """"
.....此处省略一点代码
"""
x = [int(i) for i in re.findall(r'