目的
通过实现简易的静态网站服务器,来了解HTTP服务器的基本内容,以及C++ REST SDK如何使用。
静态网站
静态网站是指内容全部是静态的,不需要动态生成,当客户端请求指定资源时,将资源回复给客户端即可,不需要有进一步的交互;服务器上只是寄存了一些HTML、CSS、JavaScript以及资源文件。
对于静态网站,我们的HTTP服务器只需要实现GET功能,根据客户端请求的资源URI返回给客户端即可,HTTP 方法:GET 对比 POST。
实现思路
使用http_listener实现对本地端口的http请求监听;
接收到请求后根据请求的相对URI获取所请求的文件
打开文件并发送内容及内容类型
MiniHTTPServer
http_listener需要指定监听的地址,当收到资源请求时,需要确定从哪个路径取文件,并提供启动和关闭接口:
#include
#include
class MiniHTTPServer
{
public:
explicit MiniHTTPServer(utility::string_t strUrl);//根据地址创建http_listener
~MiniHTTPServer(); //关闭服务器
//设定文档根目录
void setDocumentRoot(const utility::string_t& strWWW) { m_strWWW = strWWW;};
public:
pplx::task start(); //启动服务器
pplx::task stop(); //关闭服务器
//处理错误
static void handle_error(pplx::task& t);
private:
utility::string_t m_strWWW;//根路径
std::unique_ptr<:http::experimental::listener::http_listener> m_listener;
};
构造服务器:
MiniHTTPServer::MiniHTTPServer(utility::string_t strUrl)
:m_strWWW(U(".")),m_listener(new http_listener(strUrl))
{
}
启动/停止服务器:
pplx::task MiniHTTPServer::start()
{
return m_listener->open().then([](auto t){ handle_error(t); });
}
pplx::task MiniHTTPServer::stop()
{
return m_listener->close().then([](auto t){ handle_error(t); });
}
使用方法如下:
#include "MiniHTTPServer.h"
//使能宽字符输出
#include
#include
int main(int argc, char** argv)
{
_setmode(_fileno(stdout),_O_WTEXT);
if (argc != 2)
{
std::wcout <
return -1;
}
//合成服务器地址
utility::string_t strAddr = U("http://localhost:");
strAddr.append(utility::conversions::to_string_t(argv[1]));
//构造服务器并启用
MiniHTTPServer oServer(strAddr);
oServer.start().wait();
std::wcout <
std::wcout << L"按回车关闭服务器.";
std::string strVal;
std::getline(std::cin,strVal);
//关闭服务器
oServer.stop().wait();
return 0;
}
注册HTTP的GET请求处理句柄
//处理HTTP的GET请求并回复数据
void handle_get(web::http::http_request request);
//注册
MiniHTTPServer::MiniHTTPServer(utility::string_t strUrl)
:m_strWWW(U(".")),m_listener(new http_listener(strUrl))
{
//处理GET请求
m_listener->support(methods::GET,[this](auto request){
handle_get(request);
});
}
调试用:输出请求的http_headers
现在启动服务器就可以监听客户端的GET请求了,目前可以输出请求的http_header来查看客户端请求信息:
utility::string_t MiniHTTPServer::dump_http_header(web::http::http_headers oHeader)
{
stringstream_t ss;
ss<http_header\n");
for (auto const& oVal:oHeader)
{
ss<
}
ss<
return ss.str();
}
使用方法:
void MiniHTTPServer::handle_get(web::http::http_request request)
{
auto path = request.relative_uri().path();
ucout<
ucout<
......
}
根据请求URI得到资源类型
根据后缀得到资源类型:
utility::string_t MiniHTTPServer::resource_type(const utility::string_t& strSuffix)
{
std::map<:string_t> oVals;
oVals[U(".html")] = U("text/html");
oVals[U(".js")] = U("application/javascript");
oVals[U(".css")] = U("text/css");
oVals[U(".png")] = U("application/octet-stream");
oVals[U(".jpg")] = U("application/octet-stream");
auto pIt = oVals.find(strSuffix);
if (pIt != oVals.end())
return pIt->second;
return U("application/octet-stream");
}
根据URI路径得到资源文件路径和资源类型:
std::pair<:string_t utility::string_t> MiniHTTPServer::resource(const utility::string_t& strPath)
{
//如果是ROOT,寻找index
auto strVal = (strPath == U("/"))? U("/index.html"):strPath;
fs::path oPath(m_strWWW);
auto oVal = fs::absolute(oPath/strVal);
return std::make_pair(utility::string_t(oVal),resource_type(oVal.extension()));
}
添加到GET请求处理中:
auto path = request.relative_uri().path();
ucout<
ucout<
auto oVals = resource(path);
ucout<
if (!fs::exists(oVals.first))
{
request.reply(status_codes::NotFound,U("Path not found")).then([](auto t){ handle_error(t); });
return;
}
向客户端发送资源文件
使用提供的异步输入流和请求回复接口向客户端发送资源文件:
//打开异步输入流
concurrency::streams::fstream::open_istream(oVals.first,std::ios::in).then([=](concurrency::streams::istream is){
//发送异步输入流
request.reply(status_codes::OK,is,oVals.second).then([](auto t) { handle_error(t); });
}).then([=](auto& t){
try
{
t.get();
}
catch (...)
{
//打开文件失败,返回错误信息
request.reply(status_codes::InternalError).then([](auto t) { handle_error(t); });
}
});
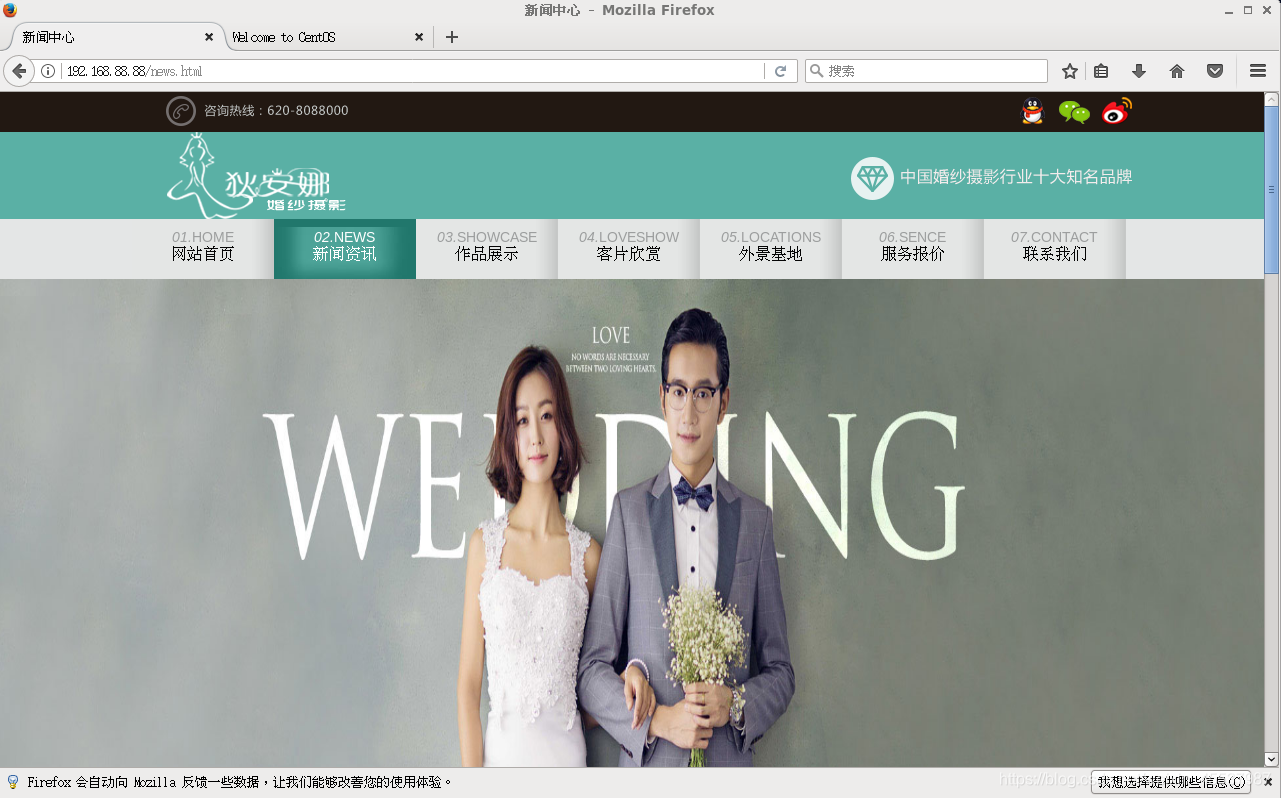
复制一些静态网站内容并运行
运行效果:
服务器输出信息
浏览器访问页面
总结
以上实现了一个非常简单的静态网站服务器,只有非常基本的功能,但是为懂得HTTP库使用的人揭开了HTTP服务器的面纱,得以一窥HTTP服务器的背后。
后续将继续了解C++ REST SDK提供的功能,为构造云端连接应用做好准备。