24.网站更新数据监控-1
一.scrapy 对网站是否更新做监控
1.spider.py
# -*- coding: utf-8 -*- import scrapy import time import re from WEB.conmon.md5_tool import md5_encodefrom WEB.items import WebItemclass CompanyInfoSpider(scrapy.Spider):name = 'wenzhou'allowed_domains = ['wzszjw.wenzhou.gov.cn']start_urls = ['http://wzszjw.wenzhou.gov.cn/col/col1357901/index.html']custom_settings = {"DOWNLOAD_DELAY": 0.5,"ITEM_PIPELINES":{'WEB.pipelines.MysqlPipeline': 320},"DOWNLOADER_MIDDLEWARES": {'WEB.middlewares.RandomUaseragentMiddleware': 500,},}def parse(self, response):#gbk解码_response=response.text.encode('utf-8')# print(_response)# 转码_response=_response.decode('utf-8')texts=re.findall("<span>.*?</span><b>·</b><a href=\'.*?\'",_response)str = ""for text in texts:str = str + "".join(text)# print(str)text_md5 = md5_encode(str)item = WebItem()item["website_name"] = "温州市建设工程造价管理处"item["website_url"] = response.urlitem["content_md5"] = text_md5item["date_time"] = time.time()print(item)yield item
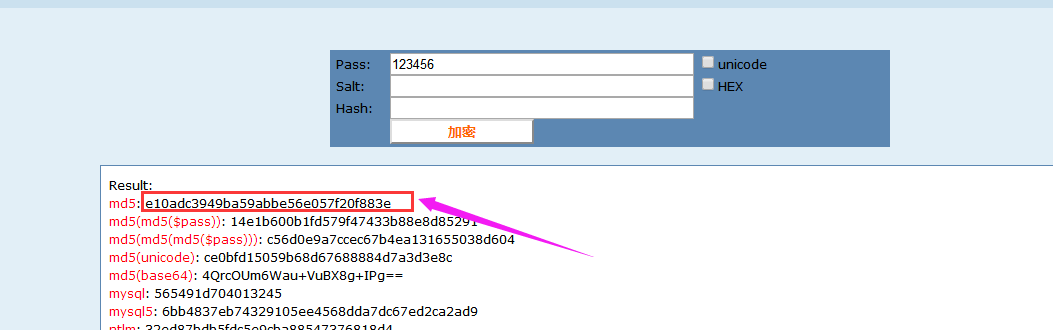
2.spider引用 md5_tool.py 对获取标签内容加密确保入库的唯一性(后期对网站监控比对的字段对象 MD5的值)
# -*- coding:utf-8 -*- import hashlib# md5 加密 def md5_encode(md5):md5 = md5hash = hashlib.md5()hash.update(bytes(md5, encoding='utf-8')) # 要对哪个字符串进行加密,就放这里return hash.hexdigest() # 拿到加密字符串
3.通用的piplines.py 链接数据库
# -*- coding: utf-8 -*- from scrapy.conf import settings import pymysqlclass WebPipeline(object):def process_item(self, item, spider):return item# 数据保存mysql class MysqlPipeline(object):def open_spider(self, spider):self.host = settings.get('MYSQL_HOST')self.port = settings.get('MYSQL_PORT')self.user = settings.get('MYSQL_USER')self.password = settings.get('MYSQL_PASSWORD')self.db = settings.get(('MYSQL_DB'))self.table = settings.get('TABLE')self.client = pymysql.connect(host=self.host, user=self.user, password=self.password, port=self.port, db=self.db, charset='utf8')def process_item(self, item, spider):item_dict = dict(item)cursor = self.client.cursor()values = ','.join(['%s'] * len(item_dict))keys = ','.join(item_dict.keys())sql = 'INSERT INTO {table}({keys}) VALUES ({values})'.format(table=self.table, keys=keys, values=values)try:if cursor.execute(sql, tuple(item_dict.values())): # 第一个值为sql语句第二个为 值 为一个元组print('成功')self.client.commit()except Exception as e:print(e)print('失败')self.client.rollback()return itemdef close_spider(self, spider):self.client.close()
4.setting.py 配置
# -*- coding: utf-8 -*-# Scrapy settings for WEB project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # https://doc.scrapy.org/en/latest/topics/settings.html # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html # https://doc.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'WEB'SPIDER_MODULES = ['WEB.spiders'] NEWSPIDER_MODULE = 'WEB.spiders'# mysql配置参数 MYSQL_HOST = "172.16.0.55" MYSQL_PORT = 3306 MYSQL_USER = "root" MYSQL_PASSWORD = "concom603" MYSQL_DB = 'web_page' TABLE = "web_page_update"# Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = 'WEB (+http://www.yourdomain.com)'# Obey robots.txt rules ROBOTSTXT_OBEY = False# Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32# Configure a delay for requests for the same website (default: 0) # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs #DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16# Disable cookies (enabled by default) #COOKIES_ENABLED = False# Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False# Override the default request headers: #DEFAULT_REQUEST_HEADERS = { # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', # 'Accept-Language': 'en', #}# Enable or disable spider middlewares # See https://doc.scrapy.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # 'WEB.middlewares.WebSpiderMiddleware': 543, #}# Enable or disable downloader middlewares # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html #DOWNLOADER_MIDDLEWARES = { # 'WEB.middlewares.WebDownloaderMiddleware': 543, #}# Enable or disable extensions # See https://doc.scrapy.org/en/latest/topics/extensions.html #EXTENSIONS = { # 'scrapy.extensions.telnet.TelnetConsole': None, #}# Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html #ITEM_PIPELINES = { # 'WEB.pipelines.WebPipeline': 300, #}# Enable and configure the AutoThrottle extension (disabled by default) # See https://doc.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False# Enable and configure HTTP caching (disabled by default) # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = 'httpcache' #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
5.items.py 字段属性
# -*- coding: utf-8 -*-# Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.htmlimport scrapyclass WebItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()content_md5 = scrapy.Field() # 监控文本website_url = scrapy.Field() # 采集页面urlwebsite_name = scrapy.Field() # 网站名称date_time = scrapy.Field() # 当前时间戳
6.数据库建表
CREATE TABLE `web_page_update` (`id` int(22) NOT NULL AUTO_INCREMENT,`website_url` varchar(255) DEFAULT NULL COMMENT '网站url',`website_name` varchar(255) DEFAULT NULL COMMENT '采集网站名',`content_md5` varchar(255) DEFAULT NULL COMMENT '页面内容',`date_time` decimal(65,7) DEFAULT NULL COMMENT '时间戳',PRIMARY KEY (`id`),UNIQUE KEY `content_md5` (`content_md5`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=230 DEFAULT CHARSET=utf8;
7.执行爬虫文件
scrapy crawl wenzhou
E:\Spider\work_code\9-15\WEB(1)\WEB>scrapy crawl wenzhou 2018-09-17 10:48:14 [scrapy.utils.log] INFO: Scrapy 1.5.1 started (bot: WEB) 2018-09-17 10:48:14 [scrapy.utils.log] INFO: Versions: lxml 4.2.3.0, libxml2 2.9.5, cssselect 1.0.3, parsel 1.5.0, w3lib 1.19.0, Twisted 18.7.0, Python 3.5.3 (v3.5.3:1880cb95a742, Jan16 2017, 16:02:32) [MSC v.1900 64 bit (AMD64)], pyOpenSSL 18.0.0 (OpenSSL 1.1.0h 27 Mar 2018), cryptography 2.3, Platform Windows-7-6.1.7601-SP1 2018-09-17 10:48:14 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'WEB', 'SPIDER_MODULES': ['WEB.spiders'], 'DOWNLOAD_DELAY': 0.5, 'NEWSPIDER_MODULE': 'WEB.spiders'} 2018-09-17 10:48:14 [scrapy.middleware] INFO: Enabled extensions: ['scrapy.extensions.corestats.CoreStats','scrapy.extensions.telnet.TelnetConsole','scrapy.extensions.logstats.LogStats'] 2018-09-17 10:48:14 [scrapy.middleware] INFO: Enabled downloader middlewares: ['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware','scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware','scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware','WEB.middlewares.RandomUaseragentMiddleware','scrapy.downloadermiddlewares.useragent.UserAgentMiddleware','scrapy.downloadermiddlewares.retry.RetryMiddleware','scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware','scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware','scrapy.downloadermiddlewares.redirect.RedirectMiddleware','scrapy.downloadermiddlewares.cookies.CookiesMiddleware','scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware','scrapy.downloadermiddlewares.stats.DownloaderStats'] 2018-09-17 10:48:14 [scrapy.middleware] INFO: Enabled spider middlewares: ['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware','scrapy.spidermiddlewares.offsite.OffsiteMiddleware','scrapy.spidermiddlewares.referer.RefererMiddleware','scrapy.spidermiddlewares.urllength.UrlLengthMiddleware','scrapy.spidermiddlewares.depth.DepthMiddleware'] 2018-09-17 10:48:14 [scrapy.middleware] INFO: Enabled item pipelines: ['WEB.pipelines.MysqlPipeline'] 2018-09-17 10:48:14 [scrapy.core.engine] INFO: Spider opened 2018-09-17 10:48:14 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min) 2018-09-17 10:48:14 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023 2018-09-17 10:48:14 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://wzszjw.wenzhou.gov.cn/col/col1357901/index.html> (referer: None) {'content_md5': 'd0ecfb7ce1f4871e4cd091fc53982755','date_time': 1537152494.7628245,'website_name': '温州市建设工程造价管理处','website_url': 'http://wzszjw.wenzhou.gov.cn/col/col1357901/index.html'} (1062, "Duplicate entry 'd0ecfb7ce1f4871e4cd091fc53982755' for key 'content_md5'") 失败 2018-09-17 10:48:14 [scrapy.core.scraper] DEBUG: Scraped from <200 http://wzszjw.wenzhou.gov.cn/col/col1357901/index.html> {'content_md5': 'd0ecfb7ce1f4871e4cd091fc53982755','date_time': 1537152494.7628245,'website_name': '温州市建设工程造价管理处','website_url': 'http://wzszjw.wenzhou.gov.cn/col/col1357901/index.html'} 2018-09-17 10:48:14 [scrapy.core.engine] INFO: Closing spider (finished) 2018-09-17 10:48:14 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 296,'downloader/request_count': 1,'downloader/request_method_count/GET': 1,'downloader/response_bytes': 2855,'downloader/response_count': 1,'downloader/response_status_count/200': 1,'finish_reason': 'finished','finish_time': datetime.datetime(2018, 9, 17, 2, 48, 14, 767824),'item_scraped_count': 1,'log_count/DEBUG': 3,'log_count/INFO': 7,'response_received_count': 1,'scheduler/dequeued': 1,'scheduler/dequeued/memory': 1,'scheduler/enqueued': 1,'scheduler/enqueued/memory': 1,'start_time': datetime.datetime(2018, 9, 17, 2, 48, 14, 492809)} 2018-09-17 10:48:14 [scrapy.core.engine] INFO: Spider closed (finished)E:\Spider\work_code\9-15\WEB(1)\WEB>
由于我之前已经测试如过库,数据库已经存过相同的数据,所以报了失败,只有网站更新出现新数据,才会提示成功。

posted on 2018-09-14 19:07 五杀摇滚小拉夫 阅读(...) 评论(...) 编辑 收藏