之前有看过一段时间爬虫,了解了爬虫的原理,以及一些实现的方法,本项目完成于半年前,一直放在那里,现在和大家分享出来。
网络爬虫简单的原理就是把程序想象成为一个小虫子,一旦进去了一个大门,这个小虫子就像进入了新世界一样,只要符合他的口味的东西就会放在自己的袋子里,但是他还不满足,只要见到可以打开的门,他都要进去看看,里面有没有他想要的东西有就装起来,直到每个门里都看了一遍,确定没有了之后,他才肯放弃,这样下来,他的袋子已经装满了想要的东西。
上述内容表述起来就是:网络爬虫就是一个自动提取网页内容的程序,这个程序的行为像一个虫子似的,爬来爬去。一般的网络爬虫都有一个或者多个网页的url作为开始,从开始的网页上获取url,并把符合条件的内容保存下来,这样一直进行下去,直到条件不符合的时候,程序执行结束。
以下只是简单的一个爬虫,爬取一个下载网站上的迅雷下载链接,用到了两个辅助队列,一个存链接作为判断当前链接是否已经打开过,另一个是进行操作的队列,存进去的链接都会进行操作。最后获取到的下载链接存在set集合中,以保证链接不会重复。
-------------------------------以下是一个分析源码的过程,后期发现这个编码没有用上---------------------------------------------------------------------
由于在网页上显示的只是一串文字,当用户点击后,他的链接会经过url编码,编码成迅雷能够识别的链接,网站上使用的是javascript的url编码,java自带了一个url编码,和网站上的不一致,我们需要java的url编码的源码,通过分析源码其实很难简单地发现对什么字符编码,对什么不进行编码,和javascript的url编码比较之后,对其进行改造,经过比对,发现java的编码,对'@','[',']',':','/'不处理,只需要增加他们进去就行
static { dontNeedEncoding = new BitSet(256);int i;for (i = 'a'; i <= 'z'; i++) {dontNeedEncoding.set(i);}for (i = 'A'; i <= 'Z'; i++) {dontNeedEncoding.set(i);}for (i = '0'; i <= '9'; i++) {dontNeedEncoding.set(i);}dontNeedEncoding.set(' '); /* encoding a space to a + is done * in the encode() method */ dontNeedEncoding.set('-');dontNeedEncoding.set('_');dontNeedEncoding.set('.');dontNeedEncoding.set('*');dfltEncName = AccessController.doPrivileged(new GetPropertyAction("file.encoding")); }改造后的url编码类,去掉了没有用的语句,增加对对'@','[',']',':','/'特殊字符的编码
package url;import java.io.UnsupportedEncodingException; import java.io.CharArrayWriter; import java.net.URLEncoder; import java.nio.charset.Charset; import java.nio.charset.IllegalCharsetNameException; import java.nio.charset.UnsupportedCharsetException; import java.util.BitSet;public class URLEncoders {static BitSet dontNeedEncoding;static final int caseDiff = ('a' - 'A');static String dfltEncName = null;static {dontNeedEncoding = new BitSet(256);int i;for (i = 'a'; i <= 'z'; i++) {dontNeedEncoding.set(i);}for (i = 'A'; i <= 'Z'; i++) {dontNeedEncoding.set(i);}for (i = '0'; i <= '9'; i++) {dontNeedEncoding.set(i);}dontNeedEncoding.set(' '); /* * encoding a space to a + is done in the * encode() method */ dontNeedEncoding.set('-');dontNeedEncoding.set('_');dontNeedEncoding.set('.');dontNeedEncoding.set('*');dontNeedEncoding.set('@');dontNeedEncoding.set('[');dontNeedEncoding.set(']');dontNeedEncoding.set(':');dontNeedEncoding.set('/');}@Deprecated public static String encode(String s) {String str = null;try {str = encode(s, dfltEncName);} catch (UnsupportedEncodingException e) {}return str;}public static String encode(String s, String enc)throws UnsupportedEncodingException {boolean needToChange = false;StringBuffer out = new StringBuffer(s.length());Charset charset;CharArrayWriter charArrayWriter = new CharArrayWriter();if (enc == null)throw new NullPointerException("charsetName");try {charset = Charset.forName(enc);} catch (IllegalCharsetNameException e) {throw new UnsupportedEncodingException(enc);} catch (UnsupportedCharsetException e) {throw new UnsupportedEncodingException(enc);}for (int i = 0; i < s.length();) {int c = (int) s.charAt(i);if (dontNeedEncoding.get(c)) {if (c == ' ') {c = '+';needToChange = true;}out.append((char) c);i++;} else {do {charArrayWriter.write(c);if (c >= 0xD800 && c <= 0xDBFF) {if ((i + 1) < s.length()) {int d = (int) s.charAt(i + 1);if (d >= 0xDC00 && d <= 0xDFFF) {charArrayWriter.write(d);i++;}}}i++;} while (i < s.length()&& !dontNeedEncoding.get((c = (int) s.charAt(i))));charArrayWriter.flush();String str = new String(charArrayWriter.toCharArray());byte[] ba = str.getBytes(charset);for (int j = 0; j < ba.length; j++) {out.append('%');char ch = Character.forDigit((ba[j] >> 4) & 0xF, 16);if (Character.isLetter(ch)) {ch -= caseDiff;}out.append(ch);ch = Character.forDigit(ba[j] & 0xF, 16);if (Character.isLetter(ch)) {ch -= caseDiff;}out.append(ch);}charArrayWriter.reset();needToChange = true;}}return (needToChange ? out.toString() : s);} }
所以当我研究好了以上的编码之后才发现,迅雷会识别未经过编码的链接,三种链接迅雷都可以下载,如下图:

所以以上就当是提高了一下分析源码的能力……
爬虫代码并没有做任何的优化,可以说效率非常低,程序用到了递归,并且在程序运行的过程中打开的链接会形成一个环形,也就是打开一个链接,之后程序执行的过程中会再次找到这个链接,所以这条路线就断了。
程序在执行过程中,如果当前访问的网址时间过长,会抛出异常,也会影响效率。
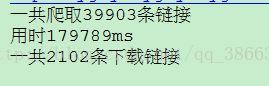
从运行时间和有效链接可以看出效率很低
其实爬虫的代码很简单,从网页获取代码,对其进行解析这么一个过程
主程序:并没有调用其他的方法,那个编码类也没有用上
package function;import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import queue.Queue;import java.io.IOException; import java.util.HashSet; import java.util.Iterator; import java.util.Set; import java.util.TreeSet; import java.util.regex.Pattern;public class Crawler {public static Queue q1 = new Queue();public static Queue q2 = new Queue();public static Set<String> set = new TreeSet<String>();public static int i = 0;public static void main(String[] args) {Document doc = null;try {long begin = System.currentTimeMillis();doc = Jsoup.connect("http://www.dytt8.net/index.htm").get();Elements links = doc.select("a[href]");for (Element link : links) {String linkHref = link.attr("href");Pattern pattern = Pattern.compile("^/html/+(.)+.html");Pattern pattern0 = Pattern.compile("http://www.dytt8.net/html/+(.)+.html");Pattern pattern1 = Pattern.compile("^ftp://+((.)+)+");if (pattern.matcher(linkHref).matches() == true || pattern0.matcher(linkHref).matches() == true) {q1.insertQueue(linkHref);q2.insertQueue(linkHref);open("http://www.dytt8.net" + q1.outQueue());}}Iterator<String> it = set.iterator();// while(it.hasNext()){ // String url=(String)it.next(); // int last=url.lastIndexOf("."); // int last1=url.lastIndexOf("]"); // // System.out.print(url.substring(last1+1, last)+" "); // System.out.println(URLEncoders.encode(url,"utf-8")); // } System.out.println("一共爬取" + q2.size() + "条链接");long end = System.currentTimeMillis();System.out.println("用时" + (end - begin) + "ms");System.out.println("一共" + set.size() + "条下载链接");} catch (IOException e) {// TODO Auto-generated catch block e.printStackTrace();}}public static void open(String url) {Document doc = null;try {doc = Jsoup.connect(url).get();Elements links = doc.select("a[href]");for (Element link : links) {String linkHref = link.attr("href");Pattern pattern = Pattern.compile("^/html/+(.)+.html");Pattern pattern0 = Pattern.compile("http://www.dytt8.net/html/+(.)+.html");Pattern pattern1 = Pattern.compile("^ftp://+((.)+)+");if (pattern.matcher(linkHref).matches() == true || pattern0.matcher(linkHref).matches() == true) {q1.insertQueue(linkHref);q2.insertQueue(linkHref);if (q2.contains(linkHref) == false) {open("http://www.dytt8.net" + q1.outQueue());}} else if (pattern1.matcher(linkHref).matches() == true) {System.out.println(linkHref);set.add(linkHref);}}} catch (IOException e) {// TODO Auto-generated catch block e.printStackTrace();}} }试着弄了一下github,所以把这个非常不完美的项目放在了上面,就当练手,项目地址:https://github.com/Ai-yoo/Java_Applaction.git