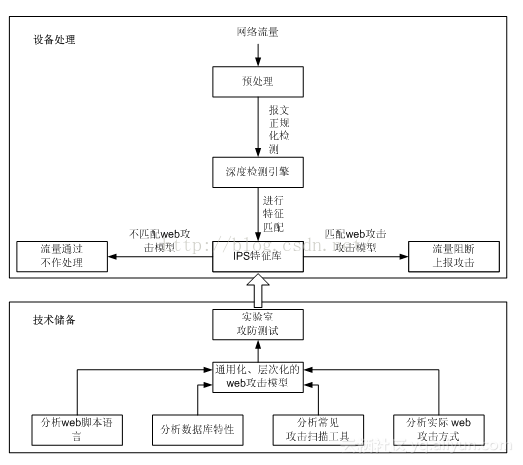
话不多说,直接开讲!教你如何用Python爬虫爬取各大网站视频和图片。
网站分析:
我们点视频按钮 可以看到url是: http://www.budejie.com/video/
接着我们点开网页源码,看下面之处
接着我们把那个下面画红线的链接点开,可以看到是个视频。
下面我进行相似的操作点图片按钮,可以看到链接: http://www.budejie.com/pic/
接着我们点开网页源码。
wKioL1evU8LxSY-OAACOF-1q7bU861.png-wh_50
相同操作,我们点开链接: http://mpic.spriteapp.cn/ugc/2016/07/07/577d9f0cdd67d_1.jpg
基本上就是这么个套路,也就用了python的两个模块 一个urllib 一个re正则
效果图:
这个是我爬下来的图片
这个是我爬下来的视频
这个是我把Linux上的视频拖一下到Windows上给大家看效果。
下面直接上代码!!!
爬视频的代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import urllib,re
def geturl():html = urllib.urlopen("http://www.budejie.com/video/").read()reg = r'data-mp4="(.*?)"'return re.findall(reg,html)
for page in range(1,100):for i in geturl():print i #i是视频的链接地址video = urllib.urlopen(i).read()fwc = open('./video/%s' %i.split('/')[-1],'wb')fwc.write(video)fwc.close()爬图片的代码
# -*- coding:utf-8 -*-
import urllib,re
def geturl():html = urllib.urlopen("http://www.budejie.com/pic/").read()reg = r'data-original="(.*?)"' return re.findall(reg,html)
for page in range(1,100):for i in geturl():print i #i是图片的链接地址video = urllib.urlopen(i).read()fwc = open('./picture/%s' %i.split('/')[-1],'wb')fwc.write(video)fwc.close()声明:本文内容来源于网络,如有侵权请联系删除