分享
最近在公司成功落地了一个用ASP.NET Core 开发前台的CMS项目,虽然对于表层的开发是兼容MVC5的,但是作为爱好者当然要用尽量多的ASP.NET Core新功能了。
背景
在项目开发的过程中,为了满足需求,还是有许多功能要自己“发明”,也就是已有技术的组(qi)合ji)运(yin)用(qiao)。本例先讲讲如果用中间件开发所有CMS都需要的服务端静态缓存方法。
CMS系统的一大痛点是一个页面要查询的内容很多,所以常常为了减轻服务器压力,都会使用到各种缓存技术。比如静态文件的CDN缓存、客户端缓存、还有就是服务端静态化缓存。
服务端静态化缓存在这里指的是把页面事先生成出来保存为静态文件,当用户请求服务器时,可以直接把页面输出给用户,而不再进行查询数据库之类的操作,已达到提高响应速度、减轻服务器压力的效果。
原理
由于服务端静态化缓存的实现核心是需要拦截请求并且直接返回HTML内容,在MVC5时代,我们可以用过滤器(Filter)来处理,类似如下代码:
[AttributeUsage(AttributeTargets.Class | AttributeTargets.Method, AllowMultiple = false, Inherited = false)]public class StaticFileHandlerFilterAttribute : ActionFilterAttribute{/// <summary>/// 过期时间,以小时为单位/// </summary>public int Expiration { get; set; }public override void OnResultExecuted(ResultExecutedContext filterContext){var actionResult = filterContext.Result;if (actionResult is ViewResult){var fileInfo = GetFileInfo(filterContext);if (fileInfo.Exists && fileInfo.CreationTime.AddHours(Expiration <= 0 ? 1 : Expiration) > DateTime.Now)return;if (fileInfo.Exists){fileInfo.Delete();}using (FileStream fs = new FileStream(fileInfo.FullName, FileMode.CreateNew, FileAccess.Write, FileShare.None)){using (StreamWriter sw = new StreamWriter(fs, Encoding.UTF8)){var viewResult = actionResult as ViewResult;var viewContext = new ViewContext(filterContext.Controller.ControllerContext, viewResult.View, viewResult.ViewData, viewResult.TempData, sw);viewResult.View.Render(viewContext, sw);}}}}public override void OnActionExecuting(ActionExecutingContext filterContext){var fileInfo = GetFileInfo(filterContext);if (fileInfo.Exists){using (FileStream fs = File.Open(fileInfo.FullName, FileMode.Open)){using (StreamReader sr = new StreamReader(fs, Encoding.UTF8)){ContentResult contentresult = new ContentResult();contentresult.Content = sr.ReadToEnd();contentresult.ContentType = "text/html";filterContext.Result = contentresult;}}}}}而在ASP.NET Core中,我们也可以在Filte中实现,但是,更方便、更牛、更快的方式就是在中间件中实现了。
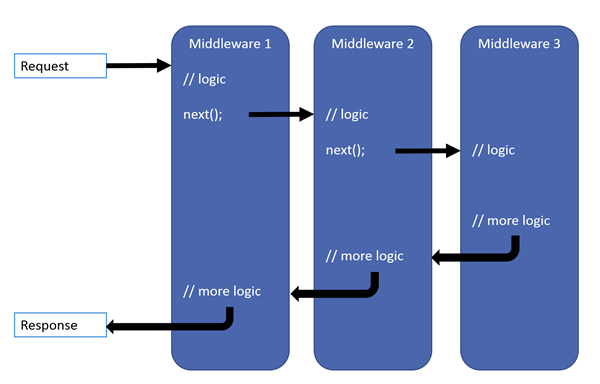
中间件运行在请求管道中,个人理解是可以看成是一个递归方法,只不过是调用不同的中间件,中间件中调用下一个中间件、知道最后一个执行完成,会沿路返回上一个中间件……说得可能不清楚,但是看代码和调试一下就能明白了。下面用代码层错误拦截的中间件作为一个中间件生命周期的示例:
app.Use(async (context, next) =>{try{//执行下一个中间件前执行的代码await next();//上一个中间件执行后执行}catch (Exception ex){context.Response.StatusCode = 500;}//执行完后会继续执行上一个中间件next委托之后的语句});中间件是写在Startup.cs文件的Configure方法中,以app.Use()方法的执行顺序添加中间件,然后会从上往下运行,遇到next委托就会跳入下一个中间件,不执行next委托就会返回上一个中间件。
好了,关于中间件的具体介绍可以看官方文档
实现服务端静态化缓存中间件
下面介绍思路,实现静态化缓存的核心是需要从请求响应中获取内容,并且转换为字符串保存到文件中。
这个功能点用以下代码和注释进行讲解:
//获取响应体的引用
var originalBody = context.Response.Body;try
{//因为响应体实例是只读的,需要创建一个内存流实例,用来获取响应流内容using (var memStream = new MemoryStream()){//把内存流的引用设置到Response.Body,假装是真的响应体接收数据context.Response.Body = memStream;//然后执行下一个中间件,等待有响应返回await next();//需要判断响应是否正确,总不能把不正确的内容缓存起来吧if (context.Response.StatusCode == (int)HttpStatusCode.OK){//检测文件存放目录if (!Directory.Exists(filePath))Directory.CreateDirectory(filePath);//把内存流的当前操作位置设为0,因为响应写入的过程中位置会在末尾。memStream.Position = 0;//读取内存流的内容,转换为字符串var responseBody = new StreamReader(memStream).ReadToEnd();//把字符串写入文件,这里还稍微压缩了一下await File.WriteAllTextAsync(fullPath, Regex.Replace(responseBody, "\\n+\\s+", string.Empty));//在此把内存流的当前操作位置设为0memStream.Position = 0;//还需要把流复制到之前引用的响应体实例await memStream.CopyToAsync(originalBody);}}
}
finally
{//把响应体实例引用重新设置到响应体context.Response.Body = originalBody;
}好了,这样响应的内容终于可以缓存起来了,下次请求直接把静态文件输出就是了。但是,好像还有问题:
- 如何对特定的请求的url做缓存;
- 如何设置过期时间。
解决这两个问题的关键就在文件名上了,对于第一点很容易理解,直接把url作为文件名不就完了。没错,但是要注意特殊字符的问题,我这里就用md5处理一下了,这样相同的请求url就会返回相同的静态文件里的内容。
但是网站要更新,不能永久都是一样的数据呀,这时就需要设置缓存时间了。这里又会产生两个问题:
- 如何在文件上标识产生缓存时的时间;
- 如何判断时间是否超时。
针对这两个问题,我也考虑了很久,总是觉得直接在文件名上记录缓存时间和判断超时就好了,这也有两种方法:
- 读取文件名上的时间,与当前时间比对;
- 在超时时间内都能产生相同的文件名,判断是否存在这个文件。
从代码简洁的考虑上,我选择挑战难度大一点的第二个方法。那么如何使程序在超时时间内都产生相同的文件名呢?其实只需要实现一个算法,在一段时间内产生的时间对象都是相同的时间,忽略中间的时间变化。这个是不是很像小学数学求近似数里的去尾法?或者我们经常用到的"/"运算符,会吧小数点去掉。而在本例中,实现利用整除发忽略一段时间中的时间变化,生成同一个时间的算法和代码如下:
var timeTicks = new DateTime(DateTime.Now.Ticks / 10000000 / expire * 10000000 * expire);哈哈,只要一行代码,整除去掉多余的时间再乘回来构造一段时间内不变的时间。其实运行一下可以发现,如果超时时间设置成60秒,那么单位秒上的值会变成00。设置为3600秒,那么分秒两个单位都是0,因此会有一个弊端,真正缓存的时间很可能比设置的值短的,这个要看需求的容忍度啦!
就这样,问题一个个被解决,下面给出完整的中间件代码:
var hasExpire = int.TryParse(Configuration["html_cache_expire_time"], out var expire);if (hasExpire && expire > 0){//文件缓存app.Use(async (context, next) =>{var url = context.Request.Path.ToString();var th = new MD5CryptoServiceProvider();var data = th.ComputeHash(Encoding.Unicode.GetBytes(url));var key = Convert.ToBase64String(data, Base64FormattingOptions.None);var path = HttpUtility.UrlEncode(key);var timeTicks = new DateTime(DateTime.Now.Ticks / 10000000 / expire * 10000000 * expire);const string filePath = "static/cache/";var fileName = path + "." + timeTicks.ToString("yyyyMMddHHmmss") + ".html";var fullPath = Path.Combine(filePath, fileName);if (File.Exists(fullPath)){await context.Response.SendFileAsync(fullPath);}else{var originalBody = context.Response.Body;try{using (var memStream = new MemoryStream()){context.Response.Body = memStream;await next();if (context.Response.StatusCode == (int)HttpStatusCode.OK){if (!Directory.Exists(filePath))Directory.CreateDirectory(filePath);memStream.Position = 0;var responseBody = new StreamReader(memStream).ReadToEnd();await File.WriteAllTextAsync(fullPath, Regex.Replace(responseBody, "\\n+\\s+", string.Empty));memStream.Position = 0;await memStream.CopyToAsync(originalBody);}}}finally{context.Response.Body = originalBody;}}});}
反思
其实这个中间件还是有很多改进的地方,比如定义一套规则来给不同页面设置不同的超时时间,这样有的需要实时更新的内容就可以被区分开,而基本不变的内容就可以一直使用缓存。