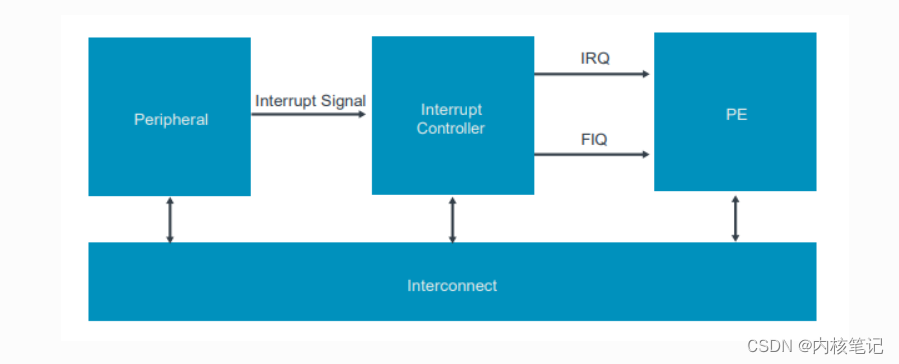
Redis:实现全局唯一ID
- 一. 概述
- 二. 实现
- (1)获取初始时间戳
- (2)生成全局ID
- 三. 测试
- 为什么可以实现全局唯一?
- 其他唯一ID策略
- 补充:countDownLatch
一. 概述
全局ID生成器:是一种在【分布式系统下】用来生成全局唯一ID的工具;
全局ID需要满足的特性:
1.唯一性
2.高可用:集群、哨兵机制;
3.高性能
4.递增性:Redis中的String数据类型的有自增特性!
5.安全性:将自增数值进行拼接,不容易猜出来;
ID结构:
符号位(1位) + 时间戳(31位) + 序列号(32位);
时间戳为从起始时间到现在的时间差;
理论上支持1秒钟2^32个订单;

二. 实现
(1)获取初始时间戳
先设定一个初始时间如2022年1月1日,获取初始时间的时间戳;


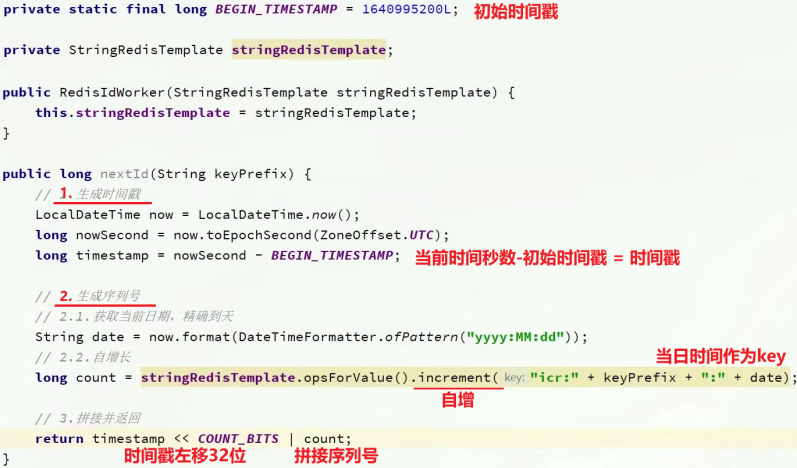
(2)生成全局ID
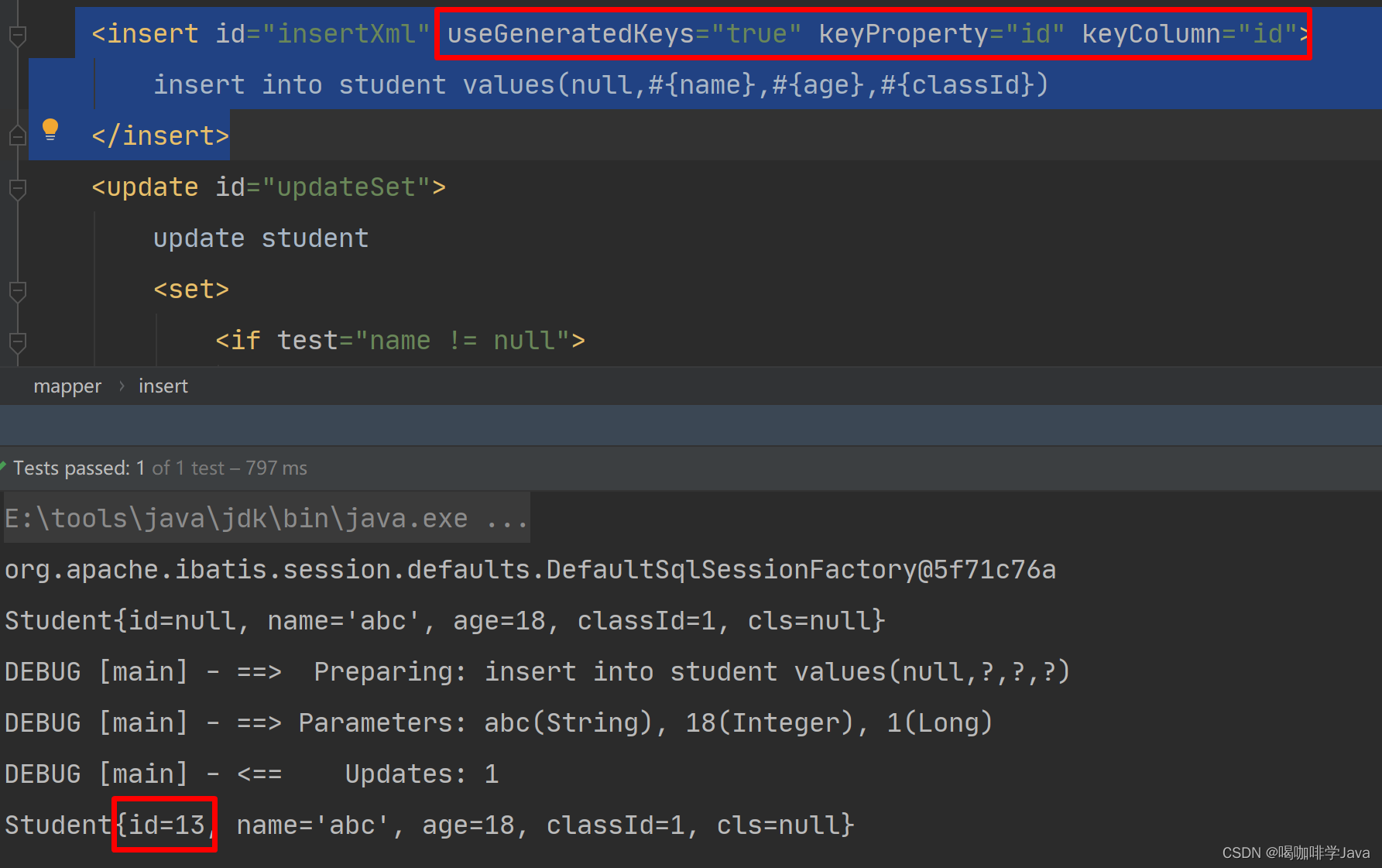
- 在utl层中定义一个
RedisIdWorker类的bean; - 写一个方法,返回值是long型;不同业务要区别,所以使用前缀区分业务;
- 生成
时间戳:即当前时间秒数 - 初始时间秒数; - 生成
序列号:使用stringRedisTemplate中String类型的自增方法increment()/INCR,而key(2^32)迟早会用完存不下,所以不能使用同一个key来自增,
序列号的key:所以使用精确到天的时间作为key,这样一个key就对应一天,不同天数的key不同,这样key的上限就是一天的下单量即2^32个,key够用;这样还方便统计订单量;
- 拼接前缀 + 符号位 + 时间戳 + 序列号,先使用位运算,将时间戳左移32位(序列号的位数),最低位都会变成0;
然后把序列号count拼接上去:使用或运算填充,有1则1,否则为0;
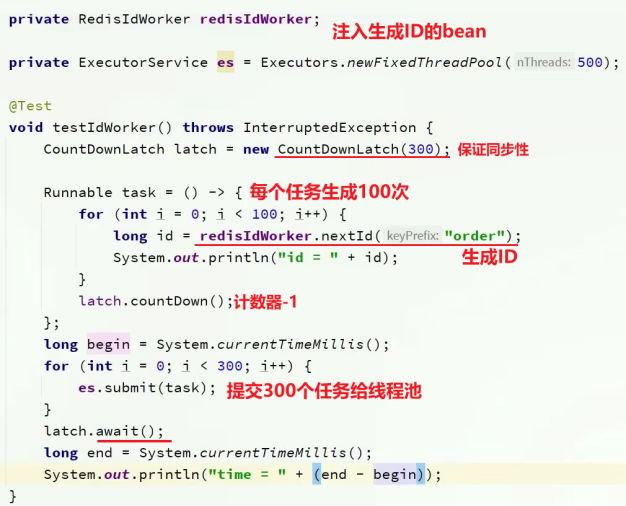
三. 测试
- 用工厂方法创建线程池,容量500;
- 创建一个任务,在任务中生成并 打印ID100次,共给线程池提交300次任务;
由于线程池会异步执行,使用countDownLatch,300个线程,每个线程会countdown一次,直到计数为0就会唤醒await()所在的当前线程,就会去main中打印所花的时间了;
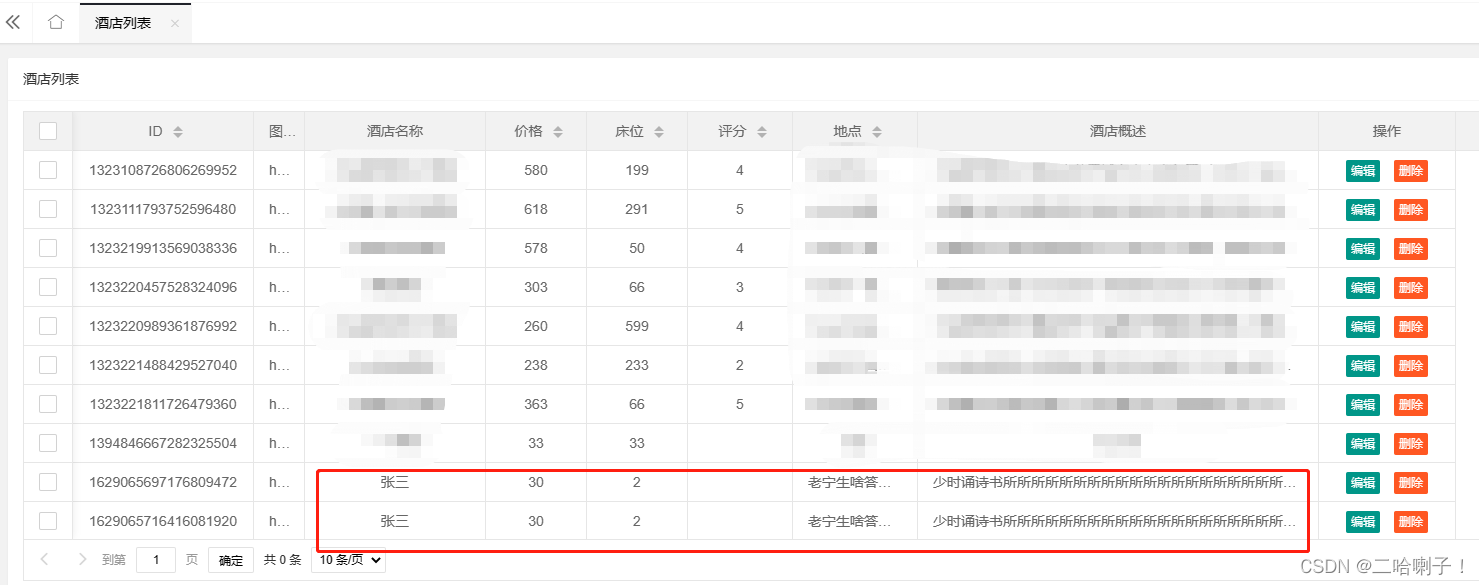
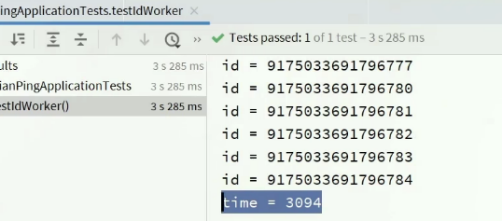
结果:生成共3w个ID;
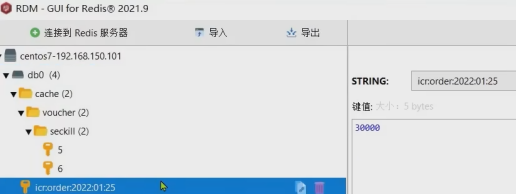
查看Redis:
为什么可以实现全局唯一?
因为生成ID时用的是Redis的 increment / INCR功能,每调用一次都会进行自增;
其他唯一ID策略
Redis产生的ID是数值类型long,占空间小;
UUID:JDK自带,16进制字符串,不是自增的,不满足要求;
雪花snowflake算法:需要维护机器id,对于时钟依赖比较高;
数据库实现,性能不如Redis;
补充:countDownLatch
用来进行线程同步协作,等待所偶有线程完成倒计时;
其中构造参数用来初始化等待计数值,countDown()用来计数-1,await()用来等待技术归零,归零后就会执行当前线程;