一、实现的目标

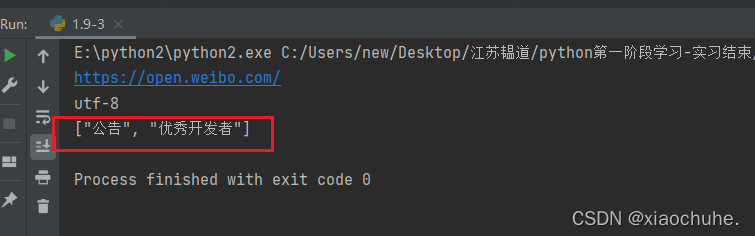
目标:获取如图所示网站中块元素的内容
二、代码编写
import requests #导入request模块
import re #导入re模块
url = "https://www.baidu.com/" #等会要爬的url地址
header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0'
}#UA伪装
res = requests.get(url=url,headers=header) #发送请求
#print (res.url) 测试用的data = res.text #所有的数据赋值给data变量
#print (data)
pattern = '<span class="title-content-title">(.*?)</span>' #正则匹配查询内容
data_last = re.findall(pattern,data)
for index,data_last_true in enumerate(data_last):print (index,data_last_true)
#print ("热搜如下:".format('title-content-title' in data,encoding='utf-8'))输出结果: