给数据分析狮看的Python--第2章、数据的获取

给数据分析狮看的Python
1、前言
通过上一次的分享,我们已经学会了如何安装Python,有了工具我们还缺少数据,今天就来分享如何获取数据。获取数据要么我们手工新建一个要么把外部数据导入到Python中,常见的外部数据一般会在这么几个地方:本地文件(文本文件、Excel文件等)、数据库、以及互联网。网络爬虫呢不是我们分享的内容。因此今天就来分享两部分。
1.1、如何手工新建数据
1.2、如何获取本地文本文件、Excel文件、以及数据库文件的数据。
2、pandas包和数据类型简介:
Pandas包是专门为了数据分析而生的一个包,Pandas包中有个基本的数据结构DataFrame,就像Excel的表格一样的行列交叉的结构,我们后续的大部分的分析都是在这个数据结构的基础上进行的。
Pandas中主要的数据类型有整数(int)、浮点数(float)、字符型(string)、日期时间型(datetime)、布尔型(bool)等。
以上只是对pandas包的一个初步介绍,你只要记住:如果想用Python做数据分析,它是必须会的一个基础的包。
3、获取数据:
3.1、手工新建数据源
在使用 pandas包之前,需要先导入它。安装Anaconda后默认就安装了pandas这个包,所以可以直接用import导入,如果你用别的方法安装的需要用pip install命令去安装这个包。
导入包的语法是:import 库名称 as 别名。
import pandas as pd这里我们需要使用pd.DataFrame()方法,注意啊这里的DataFrame中D和F是大写的。
按列构成数据源:我们要构造一个数据源,由“Name”、“Gender”、“Age”,三列组成,每列下面分别是对应的数据信息。
df= pd.DataFrame( { 'Name':['追风','令狐冲','任盈盈'], 'Gender':['M','M','F'], 'Age':['28','30','29'] })# df是个变量,我们把构造好的数据源赋值给一个叫df的变量,# 以后使用这个数据框时就用df代替。最后的结果就是这样一个行列交叉的表
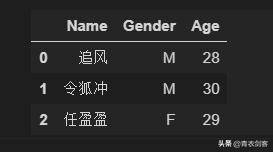
同样的数据源,我们也可以按行去构造,就是把数据一行一行的添加进来。
df= pd.DataFrame( [ ['追风','M',28],['令狐冲','M',30],['任盈盈','F',29] ], columns= ['Name','Gender','Age'])最后的结果就是刚才的那个表
3.2、获取本地csv文件的数据
我们需要用到pd.read_csv()方法。
# 语法:pd.read_csv(filepath_or_buffer,sep=',',encoding = None)参数说明:
filepath_or_buffer:读取文件的路径和文件名,建议文件名和路径不要有中文。
sep:分隔符,默认的是逗号,英文状态的逗号。
encoding:文件的编码方式。
请注意:这里只列出了几个主要的参数,还有别的参数用到的时候在给大家说。
这里我们演示如何读取存在E盘temp文件夹下的user_info这个csv文件。
# 读取csv文件df= pd.read_csv( r"E:empuser_info.csv