R语言与数据分析练习:使用协同过滤算法实现网站的智能推荐
使用ARIMA模型预测网站访问量
一、实验背景:
基于实验1中某网站2016年9月每天的访问数据,使用基于内容的协同过滤算法实现网站的智能推荐,帮助客户发现他们感兴趣但很难发现的网页信息
二、实验目的:
使用协同过滤算法实现网站的智能推荐
三、实验设计方案和流程图:
实验设计方案:
- 由于实验1已对数据进行处理,这里我们只需要根据题目要求取出2016年9月份的数据。
- 取出数据后,对字段ID的空值进行处理。
- 处理完数据,我们可以构建一个二元型数据。
- 这里根据题目要去只需要用协同过滤算法实现网站的智能推荐,我们就按照步骤先建模,然后导出相似矩阵,预测并获取结果,最后将结果保存到本地。
- 对我们需要比较的算法进行模型评估。
- 根据评估的F1值,得出最优的算法。
实验设计流程图:

四、实验过程:
1、连接数据库
jc_content_viewlog.sql 数据文件下载:
文件下载链接:https://pan.baidu.com/s/165XwNDj1YQ1JYQdj90p8RQ
提取码:omop
jc_content_viewlog表的字段说明.xlsx 文件下载:
文件下载链接:https://pan.baidu.com/s/139bB8teH-CrwrDax8envlQ
提取码:es72
# 设置工作目录并导入需要的包
setwd("D:/bigdata//R语言与数据分析/project/test2")
library(RMySQL)
library(tidyr)# 连接数据库 读取数据
mysqlconnection = dbConnect(MySQL(), user = 'root', password = '123456', dbname = 'rdata',host = 'localhost')
dbSendQuery(mysqlconnection,'SET NAMES gbk')
data <- dbReadTable(mysqlconnection,'data')
2、清洗数据,查询一个月的数据,提取重要特征,删除ID为空的记录
# 将日期切分成年月日和时分秒
data <- separate(data = data, col = date_time, into = c("date_ymd", "date_hms"), sep = " ")
data <- separate(data = data, col = date_ymd, into = c("year", "month","day"), sep = "-")
# 根据日期进行分组计数
user <- data[which(data$year == "2016" & data$month == "09"),]
user <- user[!is.na(user$content_id),]
# 特征选取
user <- user[,c(1:3,7:9)]

3、将数据转化为二元型数据,利用协同过滤算法进行建模,利用模型对原始数据集进行预测,并获取长度为5的结果
# 基于网站的协同过滤
require(recommenderlab)
# 将用户IP和网站转换为0-1二元型数据,即模型的输入数据集
pagePath <- as(user[,c(4,3)],"binaryRatingMatrix")
write.csv(as(pagePath, "matrix"), "./pagePath_matrix.csv")
# 建模
model.IBCF <- Recommender(pagePath,method="IBCF")
# 导出相似度矩阵
pagePath.model.sim <- as(model.IBCF@model$sim,"matrix")
# 利用模型对原始数据集进行预测并获得推荐长度为5的结果
recommend.IBCF <- predict(model.IBCF, pagePath , n = 5) # 推荐列表
as(recommend.IBCF, "list")[1:5] # 查看前五个IP的网站推荐
# 将结果保存至工作目录下的文件中,需要将结果转换为list型。
# 对list型结果采用sink与print命令将其保存
sink("./recommend_IBCF.txt")
print(as(recommend.IBCF, "list"))
sink()

4、模型评价
# 模型评价
# Random算法每次都随机挑选用户没有产生过行为的网站推荐给当前用户
# Popular算法则按照物品的流行度给用户推荐他没有产生过行为的网站中最热门的网站。
# IBCF算法是基于网站的协同过滤算法
# 模型评价,离线测试
# 将三种算法形成一个算法的list
algorithms <- list("random items" = list(name = "RANDOM", param = NULL),"popular items" = list(name = "POPULAR", param = NULL),"UserCF" = list(name = "IBCF", param = NULL))# 将数据以交叉检验划分成K=10份,9份训练,1份测试
# given表示用来进行模型评测的项目数量,(实际数据中只能取1)
pagePath.es <- evaluationScheme(pagePath, method = "cross-validation", k = 10, given = 1)# 采用算法列表对数据进行模型预测与评价,其推荐值N取3, 5, 10, 15, 20, 30
pagePath.results <- evaluate(pagePath.es, algorithms, n = c(3, 5, 10, 15, 20, 25))# 画出评价结果的图形
plot(pagePath.results, "prec/rec", legend = "topleft", cex = 0.67)# 构建F1的评价指标
fvalue <- function(p, r) {return(2 * p * r / (p + r))
}# 求各个评价指标的均值,并将其转换为数据框的形式
pagePath.ind <- ldply(avg(pagePath.results))# 将指标第一列有关于模型的名字重新命名
pagePath.ind[, 1] <- paste(pagePath.ind[, 1], c(3, 5, 10, 15, 20, 25))# 选取计算F1的两个指标以及有关于模型的名字
temp.pagePath <- pagePath.ind[, c(1, 6, 7)]# 计算F1的指标,并综合所有指标
F1 <- fvalue(temp.pagePath[, 2], temp.pagePath[, 3])
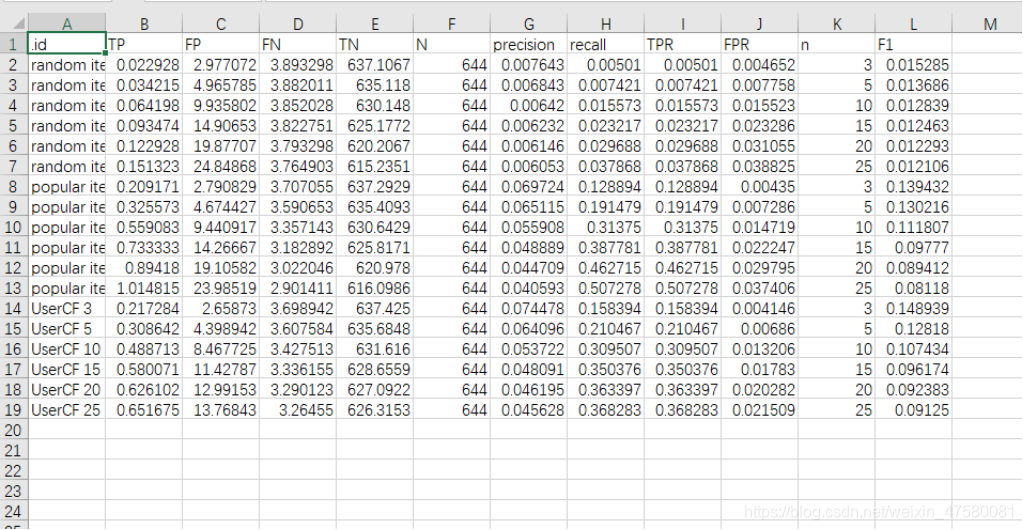
pagePath.Fvalue <- cbind(pagePath.ind, F1)# 将评价指标写入文件中
write.csv(pagePath.Fvalue, "./pagePathpredict_ind.csv", row.names = FALSE)

五、实验结论:
预测分析:
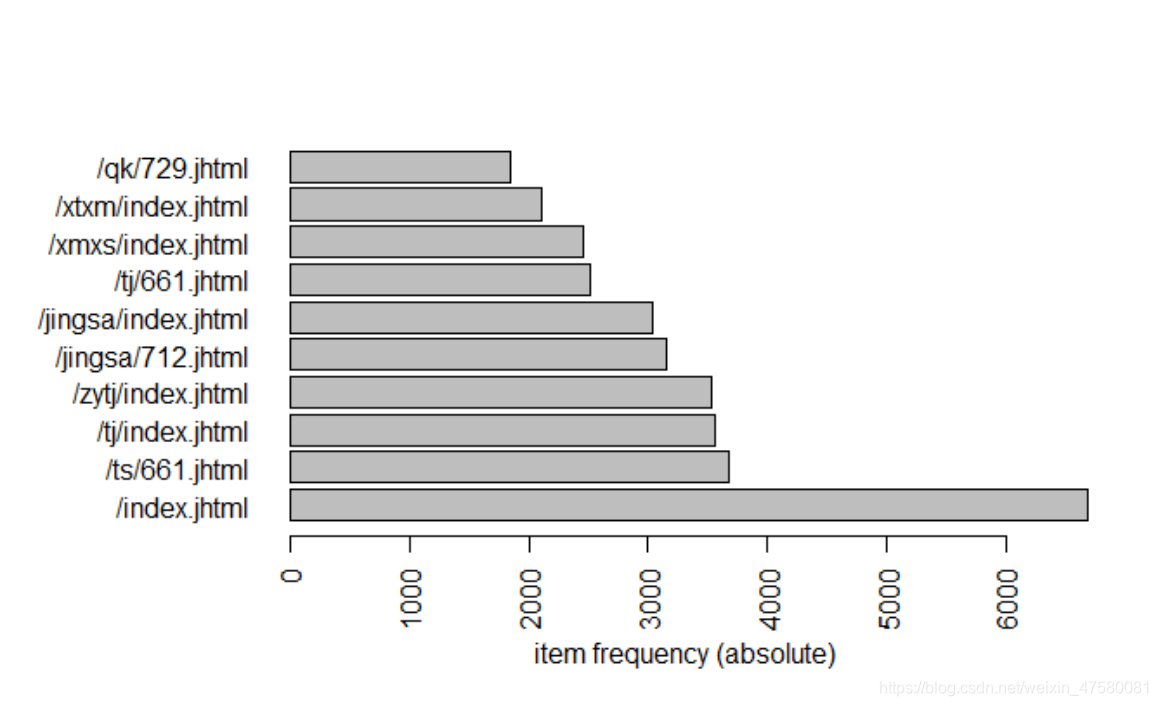
由文本可以直观的看出给不同用户推荐的5个网站结果
模型分析:
根据召回指标图可以看出UserCF算法与Popular算法都随着推荐个数K的增加,其召回率变大,精确率变小,总体趋势差不多。而从评价指标中可以看出随机推荐的F1值基本为0.01,效果很差,然而UserCF算法的F1值总体要大于Popular,因此UserCF算法相对比较“稳定”!