R语言与数据分析练习:使用Apriori算法实现网站的关联分析
使用ARIMA模型预测网站访问量
一、实验背景:
基于某网站的访问数据,使用Apriori算法对网站进行关联分析
二、实验目的:
预测网站访问量
三、实验设计方案和流程图:
实验设计方案:
- 由于实验1已对数据进行处理,这里我们只需要根据题目要求取出需要的数据。
- 建立一个列表,每个列表代表一个用户访问的网站,将列表转为数据框,保存到本地。
- 创建网站的二元矩阵,将每一个用户访问的ip改为1,导出二元矩阵。
- 构建关联规则模型,把数据转换成关联规则需要的数据类型,然后生成关联规则,导出规则数据。
- 处理规则数据,使数据更加规整的保存到本地。
- 统计每个网站对应的访问总数量、地区数量和用户数量。
- 计算每个网站所推荐的网站的综合评分。
实验设计流程图:

四、实验过程:
1、连接数据库
jc_content_viewlog.sql 数据文件下载:
文件下载链接:https://pan.baidu.com/s/165XwNDj1YQ1JYQdj90p8RQ
提取码:omop
jc_content_viewlog表的字段说明.xlsx 文件下载:
文件下载链接:https://pan.baidu.com/s/139bB8teH-CrwrDax8envlQ
提取码:es72
# 设置工作目录并导入需要的包
setwd("D:/bigdata/R语言与数据分析/project/test3")
library(RMySQL)
library(tidyr)
library(sqldf)
library(arules)
# 连接数据库 读取数据
mysqlconnection = dbConnect(MySQL(), user = 'root', password = '123456', dbname = 'rdata',host = 'localhost')
dbSendQuery(mysqlconnection,'SET NAMES gbk') data <- dbReadTable(mysqlconnection,'data')
data <- data[which(data$page_path != "/"),]
detach("package:RMySQL", unload=T);
2、根据需要处理网站数据
# 建立aliment_ulr列表,每个列表代表一个用户访问的网站
userIP <- unique(data$ip) # 对id去重
aliment_ulr <- list()
for(i in 1:length(userIP)){aliment_ulr[[i]] <- data[which(data$ip == userIP[i]), 3]aliment_ulr[[i]] <- unique(aliment_ulr[[i]]) # 去掉出现重复的网站
}
# 导出网站数据
require(plyr)
aliment_ulr1 <- ldply(aliment_ulr, rbind) # 将列表转为数据框
row.names(aliment_ulr1) <- as.character(userIP) # 修改数据框列名
write.csv(aliment_ulr1, "./aliment_ulr.csv")

3、构建二元矩阵
# 创建网站的二元矩阵
col <- levels(as.factor(unlist(aliment_ulr))) # 提取aliment_ulr列表中每个ip的地址
ruleData <- matrix(FALSE, length(aliment_ulr), length(col)) # 创建一个空的矩阵
colnames(ruleData) <- col # 修改ruleData的列名
row.names(ruleData) <- as.character(userIP) # 修改ruleData的行名
# 每一个用户访问的ip改为1
for(i in 1:length(aliment_ulr)){ruleData[i, match(aliment_ulr[[i]], col)] <- TRUE
}
write.csv(ruleData, "./ruleData.csv", row.names = FALSE) # 导出二元矩阵

4、构建关联规则模型,并生成关联规则
# 构建关联规则模型
# 把数据转换成关联规则需要的数据类型
trans <- as(aliment_ulr, "transactions")
# 或直接使用ruleData数据进行建模
# trans <- read.csv("./ruleData.csv", stringsAsFactors = FALSE)# 生成关联规则
rules <- apriori(trans, parameter = list(support = 0.01, confidence = 0.3))
summary(rules)
inspect(sort(rules, by = list('support'))[1:10]) # 查看前10个支持度较高的规则
# 绝对数量显示
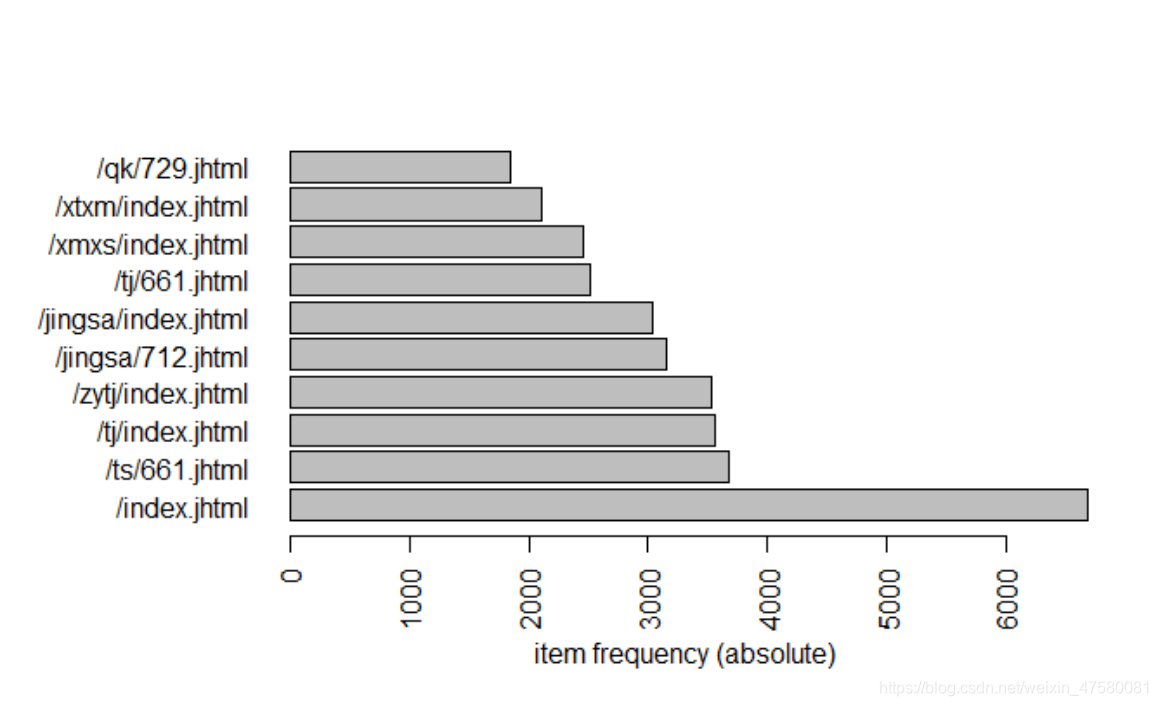
itemFrequencyPlot(trans, type = 'absolute', topN = 10, horiz = T)
# 导出规则数据
write(rules, "./rules.csv", sep = ",", row.names = FALSE)# 处理规则数据
result <- read.csv("./rules.csv", stringsAsFactors = FALSE)
# 将规则拆开
meal.recom <- strsplit(result$rules, "=>")
# 去除中括号
lhs <- 0
rhs <- 0
for (i in 1:length(meal.recom)) {lhs[i] <- gsub("[{|}+\n]|\\s", "", meal.recom[[i]][1])rhs[i] <- gsub("[{|}+\n]|\\s", "", meal.recom[[i]][2])
}
rules.new <- data.frame(lhs = lhs, rhs = rhs, support = result$support,confidence = result$confidence, lift = result$lift)
write.csv(rules.new, "./rules_new.csv", row.names = FALSE) # 写出数据

5、根据关联规则模型的因素,计算推荐的综合评分
# 计算综合评分# 统计某个网站的访问总数量
viemNum_data <- sqldf("select page_path,count(id) as viemSum from data group by page_path")
# 统计某个网站的地区数量
countryCount_data <- sqldf("select page_path,count(distinct country) as countryNum from data group by page_path")
# 统计某个网站的用户数量
userCount_data <- sqldf("select page_path,count(distinct ip) as userNumfrom from data group by page_path")# 读取数据
rules.new <- read.csv("./rules_new.csv", stringsAsFactors = FALSE)# 计算每个网站所推荐的网站的综合评分
# 设A的权重a1 = 1.5, a2 = 2.5, a3 = 3, a4 = 4
A <- matrix(c(0, 2.5, 3, 4, 1.5, 0, 3, 4,1.5, 2.5, 0, 4,1.5, 2.5, 3, 0), 4, 4, byrow = T)
E <- c(1, 1, 1, 1)# 初始化
rules.new$viemNum <- 0 # 某个网站的点击总数量
rules.new$countryCount <- 0 # 某个网站访问的地区数量
rules.new$userCount <- 0 # 某个网站的用户数量
rules.new$mark <- 0 # 综合评分for (i in 1:nrow(rules.new)) {# 找到对应的网站的点击总数量viemNum.num <- which(viemNum_data$page_path == rules.new$rhs[i])rules.new$viemNum[i] <- viemNum_data$viemSum[viemNum.num]# 找到某个网站对应访问的地区数量和用户数量userCount.num <- which(countryCount_data$page_path == rules.new$rhs[i])rules.new$userCount[i] <- countryCount_data$countryNum[userCount.num]rules.new$countryCount[i] <- userCount_data$userNumfrom[userCount.num]# 将数据缩小到小于1,计算综合评分Y <- c(rules.new$viemNum[i]/10000, rules.new$countryCount[i]/1000, rules.new$userCount[i]/1000, rules.new$confidence[i])rules.new$mark[i] <- round((E - Y) %*% A %*% t(t(Y)), 3)
}# 对综合评分进行排序
rules.new <- rules.new[order(rules.new$mark, decreasing = TRUE), ]# 写出数据
write.csv(rules.new, "./recommend.csv", row.names = FALSE)

五、实验结论:
综合评分分析:
实验中,我求出每个网站对应的访问总数量、地区数量和用户数量,根据综合评分公式对算法进行评分,最后可以根据每个网站对应的访问总数量、地区数量、用户数量以及评分对数据进行业务分析。
预测分析:
从绝对数量中可以看出“/index.jhtml”的访问量最高,对于输出的recommend.csv文件,可以通过设置前项网站或者后项网站,然后根据对应的访问总数量、地区数量、用户数量以及评分对数据进行业务分析,得出给观看前项的用户推荐更符合用户胃口的网站,从而更加高效地提高网站的访问量以及各网站之间的联系!