学习Python,就避免不了爬虫,而Scrapy就是最流行的一个。你可以爬取文字信息(如招聘职位信息,网站评论等),也可以爬取图片,比如看到一些好的网站展示了很多精美的图片(这里只用作个人学习Scrapy使用,不作商业用途),可以download下来。好了,不多说,现在开始一个最简单的图片爬虫。
首先,我们需要一个浏览器,方便查看html路径,这里推荐使用火狐开发者版(https://www.mozilla.org/en-US/firefox/developer/) 这个版本的火狐logo是蓝色的哦
装了这个,你不需要在去装firebug,firepath之类的插件
这里的例子,以花瓣网为例,抓取http://www.meisupic.com/topic.php 这个页面的图片。
Step 1: Open Firefox and access with above URL, navigate to Inspector tab, click arrow and then select a picture, you then can see the location of selected picture (see below)
在这里我们发现,打开的页面包含了很多主题的图片,然后每个主题对应一个图片链接地址,打开之后,就是这个主题下面对应的图片。那我们的目的是抓取每一个主题下面的图片,所以,第一步要获取每个主题的链接,打开这个链接,在查看图片的地址,然后一个一个download。现在大概知道了我们这个例子有两层结构:①访问主页,展示的是不同主题的图片 ②打开每一个主题,展示的这个主题下面的图片
现在开始创建一个scrapy的工程(可以参考之前的文章https://blog.51cto.com/waytogo/2092238)
这里我创建了一个huaban2的project(之前有做另一个,所以这里命名为huaban2,想写什么名都可以),然后再创建一个spider,begin是一个command line的文件,里面是就scrapy crawl meipic的命令,一会再看
Step 2: Implement a spider
# -*- coding: utf-8 -*-
from huaban2.items import Huaban2Item
import scrapyclass HuabanSpider(scrapy.Spider):name = 'meipic'allowed_domains = ['meisupic.com']baseURL = 'http://www.meisupic.com/topic.php'start_urls = [baseURL]def parse(self, response):node_list = response.xpath("//div[@class='body glide']/ul")if len(node_list) == 0:returnfor node in node_list:sub_node_list = node.xpath("./li/dl/a/@href").extract()if len(sub_node_list) == 0:returnfor url in sub_node_list:new_url = self.baseURL[:-9] + urlyield scrapy.Request(new_url, callback=self.parse2)def parse2(self, response):node_list = response.xpath("//div[@id='searchCon2']/ul")if len(node_list) == 0:returnitem = Huaban2Item()item["image_url"] = node_list.xpath("./li/a/img/@data-original").extract()yield item
解释一下这段代码:在用 scrapy genspider meipic meisupic.com 生成spider之后,默认的结构已经写好了,这里我们设置了一个baseURL, parse是默认的方法。从上面的分析中得知,我们需要拿到每一个主题的链接,所以用xpath定位
node_list = response.xpath("//div[@class='body glide']/ul")这样我们得到一个selector对象,赋给变量node_list,加个if判断一下,如果没了就结束(return之后的代码都不会执行,这个大家应该都知道),接着我们要取/ul/li/dl下面的a中的href,取到之后,用extract(),返回一个list,就是dl下面所有<a>中的链接,接下来,我们需要拼接一个完整的URL,然后请求这个URL,用yield返回。因为我们真正要抓取的图片在第二层页面,所以这里的回调函数(callback)调用一个parse2(这是自己定义的一个方法),parse2用来处理图片链接。同理,parse2的response就是之前拼接的URL请求的页面返回的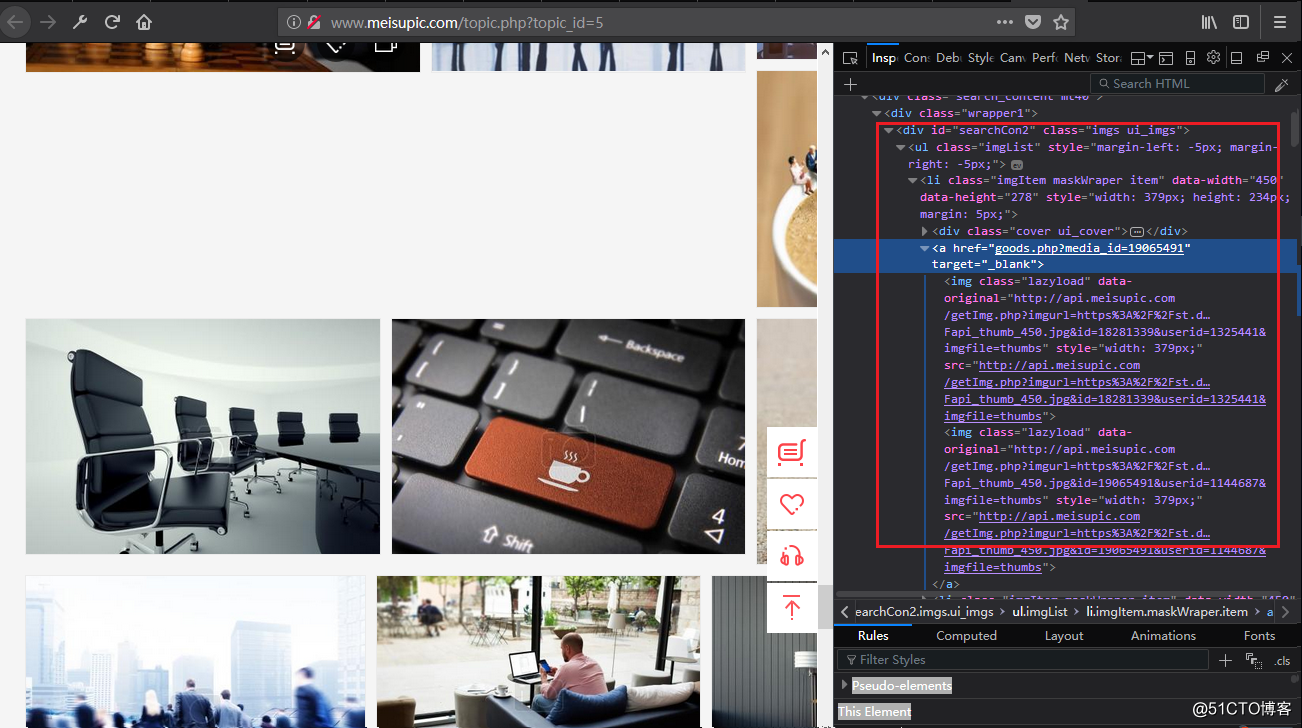
这里我们要到得到图片的地址,就是//div[@id='SearchCon2‘]/ul/li/a/img/@data-original,拿到地址之后,把它给item(我们定义了item的字段,用来存储图片的地址),这样item返回给pipeline
items.py
import scrapyclass Huaban2Item(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()image_url = scrapy.Field()image_paths = scrapy.Field()
pipelines.py
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
import scrapyclass Huaban2Pipeline(ImagesPipeline):def get_media_requests(self, item, info):for image_url in item['image_url']:yield scrapy.Request(image_url)def item_completed(self, results, item, info):image_paths = [x["path"] for ok, x in results if ok]if not image_paths:raise DropItem("Item contains no image")item['image_paths'] = image_pathsreturn item
因为要下载图片,所以需要在settings.py里配置一个路径,同时
需要的配置如下,其他默认就好
MEDIA_ALLOW_REDIRECTS = True #因为图片地址会被重定向,所以这个属性要为True
IMAGES_STORE = "E:\\img" #存储图片的路径
ROBOTSTXT_OBEY = False #Robot协议属性要为False,不然就不会抓取任何内容
ITEM_PIPELINES = {'huaban2.pipelines.Huaban2Pipeline': 1,
} #pipeline要enable,不然不会出来pipeline的请求
最后,我们写了一个begin.py的文件,用来执行
from scrapy import cmdlinecmdline.execute('scrapy crawl meipic'.split())多说一点,可以存储不同图片尺寸,如果需要可以加属性在settings.py里
IMAGES_THUMBS = {'small': (100, 100), 'big': (800, 1000)}好了,基本的都已经写好了,可以开始执行了。
转载于:https://blog.51cto.com/waytogo/2109243