Java 爬虫遇到需要登录的网站,该怎么办?-1.jpg (32.2 KB, 下载次数: 0)
2020-11-17 07:54 上传
这是 Java 网络爬虫系列博文的第二篇,在上一篇Java 网络爬虫,就是这么的简单中,我们简单的学习了一下如何利用 Java 进行网络爬虫。在这一篇中我们将简单的聊一聊在网络爬虫时,遇到需要登录的网站,我们该怎么办?
在做爬虫时,遇到需要登陆的问题也比较常见,比如写脚本抢票之类的,但凡需要个人信息的都需要登陆,对于这类问题主要有两种解决方式:一种方式是手动设置 cookie ,就是先在网站上面登录,复制登陆后的 cookies ,在爬虫程序中手动设置 HTTP 请求中的 Cookie 属性,这种方式适用于采集频次不高、采集周期短,因为 cookie 会失效,如果长期采集的话就需要频繁设置 cookie,这不是一种可行的办法,第二种方式就是使用程序模拟登陆,通过模拟登陆获取到 cookies,这种方式适用于长期采集该网站,因为每次采集都会先登陆,这样就不需要担心 cookie 过期的问题。
为了能让大家更好的理解这两种方式的运用,我以获取豆瓣个人主页昵称为例,分别用这两种方式来获取需要登陆后才能看到的信息。获取信息如下图所示:
Java 爬虫遇到需要登录的网站,该怎么办?-2.jpg (19.75 KB, 下载次数: 0)
2020-11-17 07:54 上传
获取图片中的缺心眼那叫单纯,这个信息显然是需要登陆后才能看到的,这就符合我们的主题啦。接下来分别用上面两种办法来解决这个问题。
手动设置 cookie
手动设置 cookie 的方式,这种方式比较简单,我们只需要在豆瓣网上登陆,登陆成功后就可以获取到带有用户信息的cookie,豆瓣网登录链接:
https://accounts.douban.com/passport/login
如下图所示:
Java 爬虫遇到需要登录的网站,该怎么办?-3.jpg (32.72 KB, 下载次数: 0)
2020-11-17 07:54 上传
图中的这个 cookie 就携带了用户信息,我们只需要在请求时携带这个 cookie 就可以查看到需要登陆后才能查看到的信息。我们用 Jsoup 来模拟一下手动设置 cookie 方式,具体代码如下:
Java 爬虫遇到需要登录的网站,该怎么办?-4.jpg (40.37 KB, 下载次数: 0)
2020-11-17 07:54 上传
从代码中可以看出跟不需要登陆的网站没什么区别,只是多了一个.header("Cookie", "your cookies"),我们把浏览器中的 cookie 复制到这里即可,编写 main 方法
Java 爬虫遇到需要登录的网站,该怎么办?-5.jpg (12.39 KB, 下载次数: 0)
2020-11-17 07:54 上传
运行 main 得到结果如下:
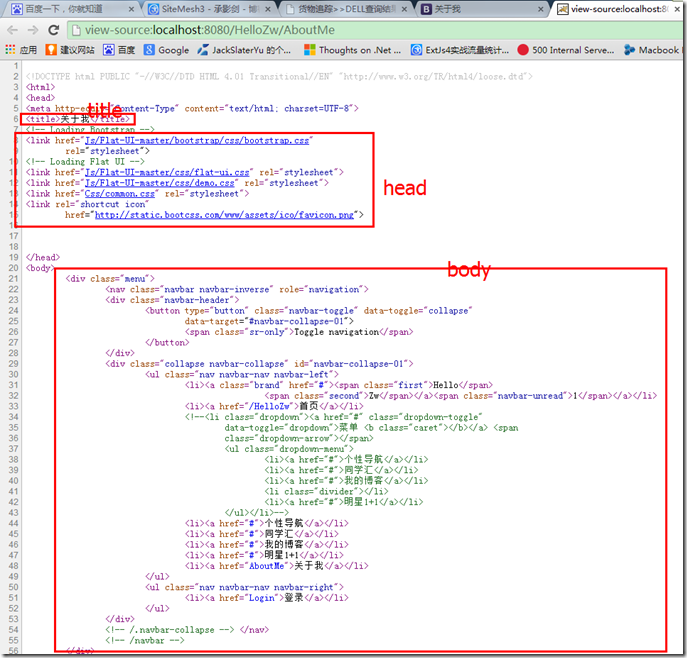
Java 爬虫遇到需要登录的网站,该怎么办?-6.jpg (16.86 KB, 下载次数: 0)
2020-11-17 07:54 上传
可以看出我们成功获取到了缺心眼那叫单纯,这说明我们设置的 cookie 是有效的,成功的拿到了需要登陆的数据。这种方式是真的比较简单,唯一的不足就是需要频繁的更换 cookie,因为 cookie 会失效,这让你使用起来就不是很爽啦。
模拟登陆方式
模拟登陆的方式可以解决手动设置 cookie 方式的不足之处,但同时也引入了比较复杂的问题,现在的验证码形形色色、五花八门,很多都富有挑战性,比如在一堆图片中操作某类图片,这个还是非常有难度,不是随便就能够编写出来。所以对于使用哪种方式这个就需要开发者自己去衡量利弊啦。今天我们用到的豆瓣网,在登陆的时候就没有验证码,对于这种没有验证码的还是比较简单的,关于模拟登陆方式最重要的就是找到真正的登陆请求、登陆需要的参数。 这个我们就只能取巧了,我们先在登陆界面输入错误的账号密码,这样页面将不会跳转,所以我们就能够轻而易举的找到登陆请求。我来演示一下豆瓣网登陆查找登陆链接,我们在登陆界面输入错误的用户名和密码,点击登陆后,在 network 查看发起的请求链接,如下图所示:
Java 爬虫遇到需要登录的网站,该怎么办?-7.jpg (44.56 KB, 下载次数: 0)
2020-11-17 07:54 上传
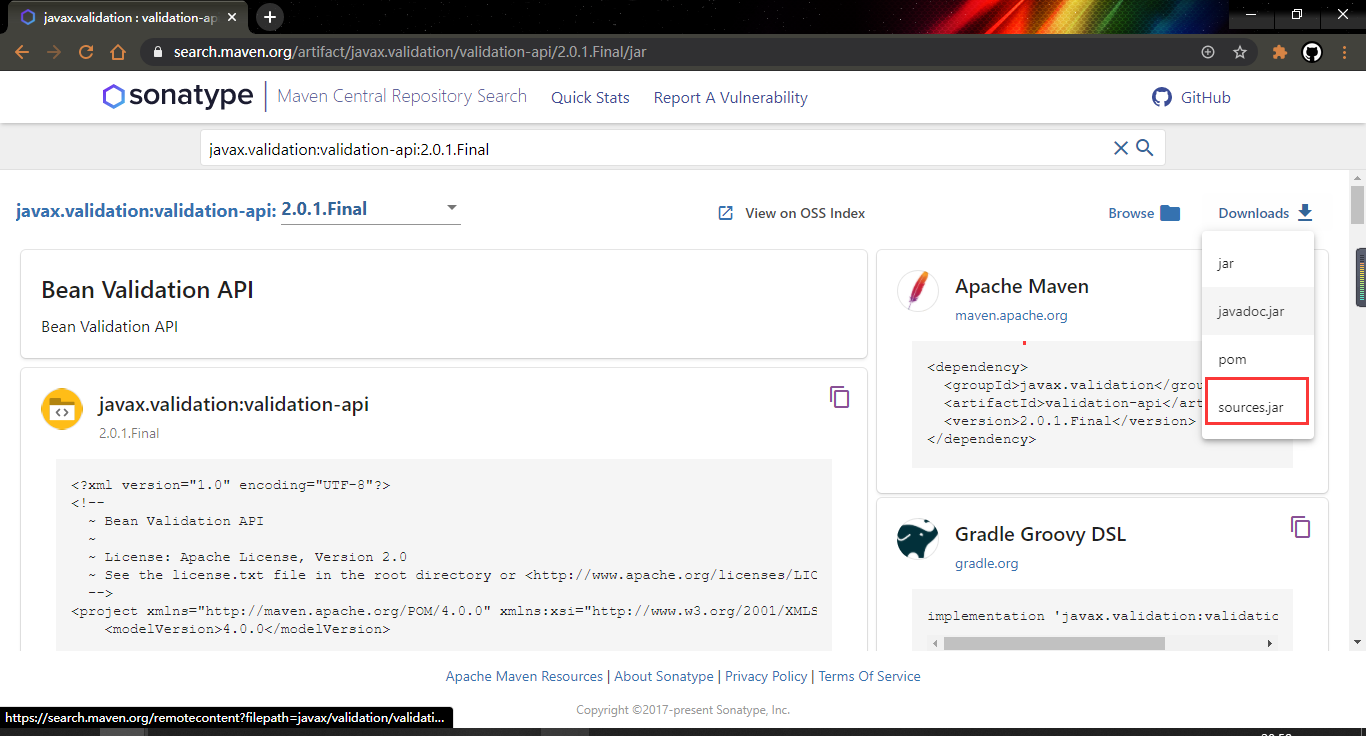
从 network 中我们可以查看到豆瓣网的登陆链接为https://accounts.douban.com/j/mobile/login/basic,需要的参数有五个,具体参数查看图中的 Form Data,有了这些之后,我们就能够构造请求模拟登陆啦。登陆后进行后续操作,接下来我们就用 Jsoup 来模拟登陆到获取豆瓣主页昵称,具体代码如下:
Java 爬虫遇到需要登录的网站,该怎么办?-8.jpg (46.13 KB, 下载次数: 0)
2020-11-17 07:54 上传
这段代码分两段,前一段是模拟登陆,后一段是解析豆瓣主页,在这段代码中发起了两次请求,第一次请求是模拟登陆获取到 cookie,第二次请求时携带第一次模拟登陆后获取的cookie,这样也可以访问需要登陆的页面,修改 main 方法
Java 爬虫遇到需要登录的网站,该怎么办?-9.jpg (20.54 KB, 下载次数: 0)
2020-11-17 07:54 上传
运行 main 方法,得到如下结果:
Java 爬虫遇到需要登录的网站,该怎么办?-10.jpg (14.96 KB, 下载次数: 0)
2020-11-17 07:54 上传
模拟登陆的方式也成功的获取到了网名缺心眼那叫单纯,虽然这已经是最简单的模拟登陆啦,从代码量上就可以看出它比设置 cookie 要复杂很多,对于其他有验证码的登陆,我就不在这里介绍了,第一是我在这方面也没什么经验,第二是这个实现起来比较复杂,会涉及到一些算法和一些辅助工具的使用,有兴趣的朋友可以参考崔庆才老师的博客研究研究。模拟登陆写起来虽然比较复杂,但是只要你编写好之后,你就能够一劳永逸,如果你需要长期采集需要登陆的信息,这个还是值得你的做的。除了使用 jsoup 模拟登陆外,我们还可以使用 httpclient 模拟登陆,httpclient 模拟登陆没有 Jsoup 那么复杂,因为 httpclient 能够像浏览器一样保存 session 会话,这样登陆之后就保存下了 cookie ,在同一个 httpclient 内请求就会带上 cookie 啦。httpclient 模拟登陆代码如下:
Java 爬虫遇到需要登录的网站,该怎么办?-11.jpg (40.82 KB, 下载次数: 0)
2020-11-17 07:54 上传
运行这段代码,返回的结果也是 true。
有关 Java 爬虫遇到登陆问题就聊得差不多啦,来总结一下:对于爬虫遇到登陆问题有两种解决办法,一种是手动设置cookie,这种方式适用于短暂性采集或者一次性采集,成本较低。另一种方式是模拟登陆的方式,这种方式适用于长期采集的网站,因为模拟登陆的代价还是蛮高的,特别是一些变态的验证码,好处就是能够让你一劳永逸
以上就是 Java 爬虫时遇到登陆问题相关知识分享,希望对你有所帮助,下一篇是关于爬虫是遇到数据异步加载的问题。如果你对爬虫感兴趣,不妨关注一波,相互学习,相互进步
源代码:
https://github.com/BinaryBall/java-base/blob/master/crawler/src/main/java/com/jamal/crawler/CrawleLogin.java作者:平头哥的技术博文来源:掘金商业用途请与原作者联系,本文只做展示分享,不妥侵删!