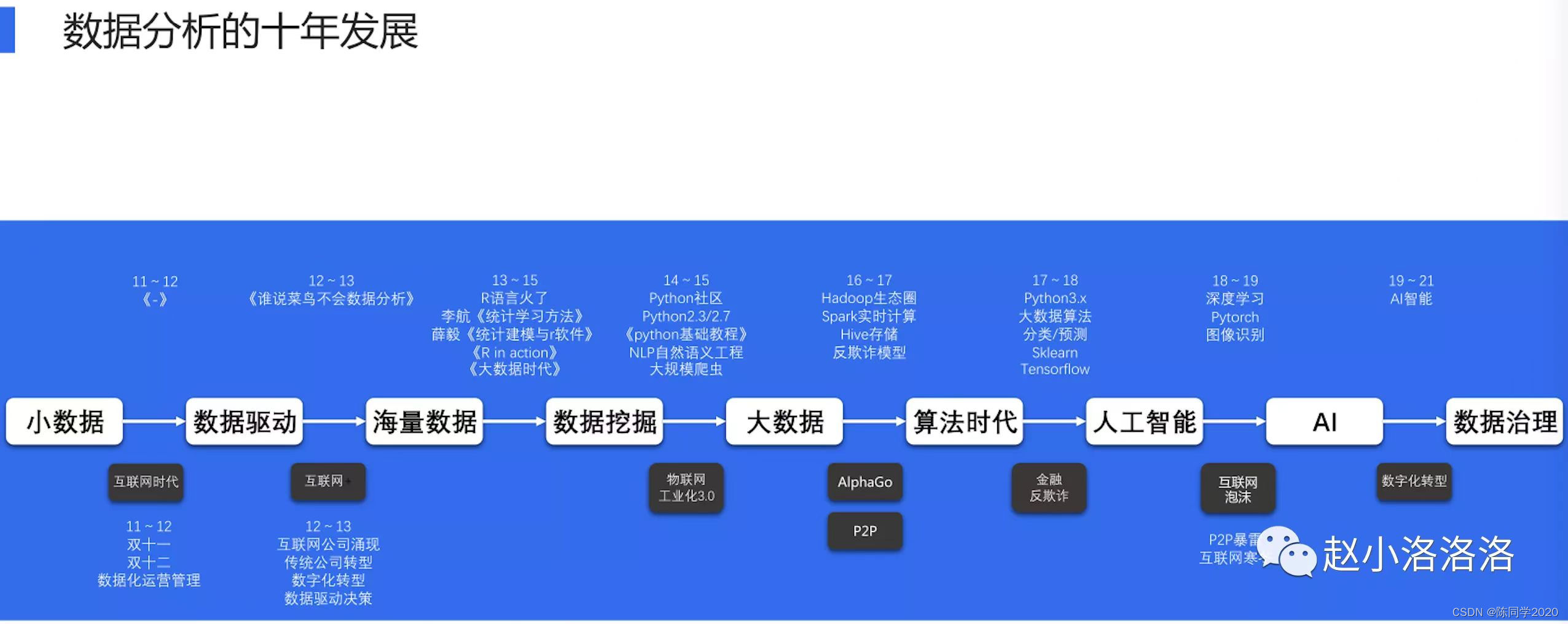
TVM简介
TVM将训练好的模型移植到特定架构并在计算层面做推理优化加速。
依赖语言:python(前端) C++(后端)
虚拟机:LLVM
通过torch将python模型导出为ONNX模型(.onnx)
Relay IR:根据ONNX模型搭建计算图,计算图模型的通用优化技巧大概有
- 简化推理
- 算子融合
- 常量折叠
- 节点修改
- 算子规范化
前端:机器学习框架(Pytorch TensorFlow)
模型 - Relay IR - Tensor IR (TIR) - C++ / CUDA / LLVM IR
TIR是IR的最底层,可以被转换为C++/CUDA源码或者LLVM IR。TIR的数据结构其实是一个抽象语法树(AST),AST可以表示为变量的declaration, definition, calculaiton以及function call和control flow。因此需遍历这个AST以获得TIR对应的目标硬件层面上的计算。
IRModule 是在机器学习编译中保存元张量函数(也即PrimFunc)集合的容器对象,是TVM进行编译的最小完整单元,是一系列BaseFunc的映射。TVM不同的前端表示最终都会被封装到IRModule中进行编译,在Linux下IRModule就是一个.so动态链接库
元张量函数PrimFunc内部封装了一个完整的TIR AST。一个IRModule可以有很多个PrimFunc,当IRModule被编译之后,每个PrimFunc都对应了这个动态库的一个函数入口。
@tvm.script.ir_module表示被修饰的类是一个待编译的IRModule
@T.prim_func表示被修饰的函数是元张量函数PrimFunc,这个函数内部定义的就是TIR AST
IR Type:包含基础的数据类型如Int,Float,Double等等,也包含一些自定义的复杂类型比如函数类型,Tensor类型等
IR Expr:包含可以直接映射到Low-level IR的PrimExpr,又包含RelayExpr。
从TensorTypeNode的定义可以看到shape也是TensorType的一部分,所以TVM在做类型推断的时候也包含了Shape的推断。也正是因为在IR中Shape是Type的一部分(比如Tensor[(m, n)]和Tensor[(m, 4)]是不同的Type)导致TVM对动态Shape的支持非常困难,因为Expr的类型推断是不支持动态Shape的。Relax通过引入一个新的Type叫作DynTensor较好的解决了动态Shape的表示问题,DynTensor包含的信息是Dtype和Shape的纬度,但Shape本身的表达式是独立存储的。也就是Tensor[(m, n)]和Tensor[(_, )]都是同一个Type, 但是Tensor[(, )]和Tensor[(, _, _)]是不同的Type,这样就从原生上支持了动态Shape。Expr分成PrimExpr以及RelayExpr。其中PrimExpr保存了一个runtime时候的Dtype,
无论是高级别的Relay,Relax还是低级别的TIR,它们最终都是由这里的Expr和Type为基础来表达的。因为对于Relay和TIR来讲,它们的op定义都是继承自RelayExprNode。除了对Op名字,类型以及参数,属性等定义外还有一个特殊的参数support_level,从注释上看应该是用来解释当前Op的等级,值越小表示这种Op类型等级越高。
首先Relay IR目前仍然是TVM和其它深度学习框架对接的主要方式,Relay IR会被进一步封装为IRModule给TVM编译。Relay还定义了ConstantExpr,TupleExpr,VarExpr,CallNodeExpr,LetNodeExpr,IfNodeExpr等多种Expr。
TVM的核心是计算和调度分离,Relay Op的调度逻辑是怎么注册的呢?TVM没有为每个Relay OP注册compute和schedule,而是为其注册fcompute和fschedule,然后根据输入和属性参数,输出类型等生成对应的compute和schedul,这种compute和schedule的组合对应了Op Implementation。特定的Op Implementation需要特定的条件,所以又按照这个条件(condition)进行分组,每一组被叫作Op Specialization。