通过python 来爬取网站内所有的图片到本地
第三篇是动态获取参数构造图片地址实现下载图片 传送门:https://blog.csdn.net/qq_33958297/article/details/82316019
这篇文章的目的是因为上一个文章里的地址已经无法访问了
考虑到可能有的新手没有办法去实验,这里又出了一个新的。
但是和那个网站的实现方式略微不同。
前面大致是一样的只是后面整套图片获取的时候 需要一些步骤。
爬取地址没了:官方又说这个是色情了。还是同样的下面是详细教程了
一.获得图片地址 和 图片名称
1.进入网址之后 按F12 打开开发人员工具点击elemnts

2.点击下图的小箭头 选择主图中的任意一个图片 那我们这里点击第一个 图片

3.显示控制台 为了验证xpath是否正确
4.通过xpath获得a的href 和 title. (我看到好几个在问如何通过xpath获得a的href和title 把下面的图点开 不光有xpath语句,还有结果 )

(请放大看)我们看到 他提示的是有24个 我们回到网站中看一下 在主页上数一下 他有32个 为什么我们拿到的是24个呢
其实仔细看一下能看到里面有几个图片位是插入的广告
广告没有href 和data-origianl这两个属性
也就是说 我们获得的href 和title是没有任何问题的 那么留着为我们后面使用.
5.我们还需要访问这个链接的请求头的信息 以备后面操作的时候来使用

这里可以看到 没有什么特别的请求头
6.获得每套图里的 所有图片.这也是我们的目的所在 不然前面那么多工序不是浪费吗。
但是我们进来之后发现 他只有一张图,需要点击下一页来获取剩下的图片。
那么我们这里的思路很简单,首先获取图片的地址,同时获取最大的页码,这样我们通过循环就可以自己构造出来他的图片地址
但是构造图片的话 我们需要知道他的规律 这样才可以保证我自己构造的地址不会有问题
那么开始吧:
第一张图

第二张图

最后一张图

我们这里可以发现 他的图片地址很简单就是数字一直向后加就可以了。
7.获取图片地址和页码

上面是页码 下面是图片地址
8.获得相应的请求头

可以发现 需要注意的只有一个字段Referer 这里的地址就是我们访问这个页面进来的时候的那个地址 只要把那个地址给上就行了
这里需要Referer的原因是 因为网站基本都有防盗链 而防盗链就是看这个值到底有没有 如果直接请求的话 会返回一些错误的东西 或者错误等问题
那么至此 我们所有的东西都获得完成了下面开始写代码了
这里的代码 和上一篇的代码大致是相同的
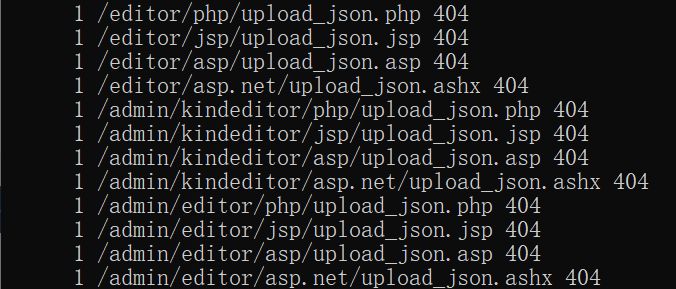
9.对于404的处理 如果出现了404那就只有重新请求了
二.编写python代码实现爬取.
1.需要用到的库有:
Requests lxml 如果没有安装的请自己安装一下
2.IDE : vscode
3.python 版本: 2.7.15
4.代码实现的是多线程下载,多线程的好处 就不用我多说了。
下载地址:https://download.csdn.net/download/qq_33958297/12195870
效果图就不放 可能过于有点那啥 代码在python2平台下已经测试通过 在网站没有改变相关数据的情况下可以直接下载完所有的图片,建议下载代码的朋友先检查一下网站布局是否有变。