目录
1、项目概述
2、总体设计
2.1 Hadoop插件安装及部署
3、详细实现步骤操作纪要
3.1 hadoop环境准备
3.2 源数据文件准备
3.3 python开发mapreduce脚本
3.4 根据结果文件结构建立hive数据库表
3.4.1在结果文件上创建分区表
3.4.2 按日期创建分区
3.5 使用Hive对结果表进行数据分析统计
3.5.1 PV量
3.5.2 注册用户数
3.5.3 独立IP数
3.5.4 跳出用户数
3.6 使用Sqoop将hive分析结果表导入mysql
3.6.1 创建mysql表
3.6.2 将hive结果文件导入mysql
附加操作—增添色彩
数据可视化(项目色彩一);
将数据导入到hbase(项目色彩二)
每文一语
♦️ 💎 💍 🏆 🎼 🎹 🎻 🎮 🃏 🎴 🎲
实践项目所需资料
hive安装手册(如果需要本项目的Hadoop集群压缩包(包含所有组件,免去安装部署),可以私信博主,解压可使用!)
hive安装资料手册.rar-Hadoop文档类资源-CSDN下载
日志数据文件:
大数据分析-网站日志数据文件(Hadoop部署分析资料)-Hadoop文档类资源-CSDN下载
预处理MapReduce代码(python)
hadoop实训课数据清洗py脚本(MapReducepython代码,可执行文件脚本,使用方法)-Hadoop文档类资源-CSDN下载
使用hadoop-streaming运行Python编写的MapReduce程序.rar-Hadoop文档类资源-CSDN下载
PPT演示操作指南(按照步骤做!有原理解释)
hadoop实践项目-PPT演示步骤-Hadoop文档类资源-CSDN下载
本项目需要的安装包(用于需要自己部署所需)
Hadoop部署实践所需的安装包(Ubuntu下的安装包)-Hadoop文档类资源-CSDN下载
分析源码:
Hadoop网站日志分析源码(hive命令).txt-Hadoop文档类资源-CSDN下载
如果你需要本项目Word,可以直接使用博主已经写好的课程设计模板:
基于hadoop对某网站日志分析部署实践课程设计报告参考模板.doc-Hadoop文档类资源-CSDN下载
♦️ 💎 💍 🏆 🎼 🎹 🎻 🎮 🃏 🎴 🎲
1、项目概述
本次要实践的数据日志来源于国内某技术学习论坛,该论坛由某培训机构主办,汇聚了众多技术学习者,每天都有人发帖、回帖。至此,我们通过Python网络爬虫手段进行数据抓取,将我们网站数据(2013-05-30,2013-05-31)保存为两个日志文件,由于文件大小超出我们一般的分析工具处理的范围,故借助Hadoop来完成本次的实践。
2、总体设计
2.1 Hadoop插件安装及部署
第一步:Hadoop环境部署和源数据准备
安装好VMware(查看)
第二步:使用python开发的mapper reducer进行数据处理。
第三步:创建hive数据库,将处理的数据导入hive数据库
第四步:将分析数据导入mysql
3、详细实现步骤操作纪要
3.1 hadoop环境准备
- Hadoop
首先开启Hadoop集群:start-all.sh:开启所有的Hadoop所有进程,在主节点上进行
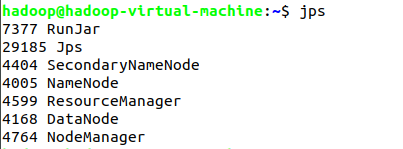
NameNode它是Hadoop 中的主服务器,管理文件系统名称空间和对集群中存储的文件的访问。
Secondary NameNode是一个用来监控HDFS状态的辅助后台程序。
DataNode它负责管理连接到节点的存储(一个集群中可以有多个节点)。每个存储数据的节点运行一个 datanode 守护进程。
NodeManager:
1、是YARN中每个节点上的代理,它管理Hadoop集群中单个计算节点
2、包括与ResourceManger保持通信,监督Container的生命周期管理,
3、监控每个Container的资源使用(内存、CPU等)情况,追踪节点健
4、康状况,管理日志和不同应用程序用到的附属服务(auxiliary service)
ResourceManager:在YARN中,ResourceManager负责集群中所有资源的统一管理和分配,它接收来自各个节点(NodeManager)的资源汇报信息,并把这些信息按照一定的策略分配给各个应用程序(实际上是ApplicationManager)RM与每个节点的NodeManagers (NMs)和每个应用的ApplicationMasters (AMs)一起工作。
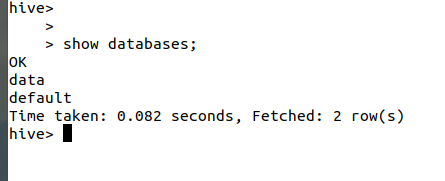
- hive
Show databases;展示数据库的名称
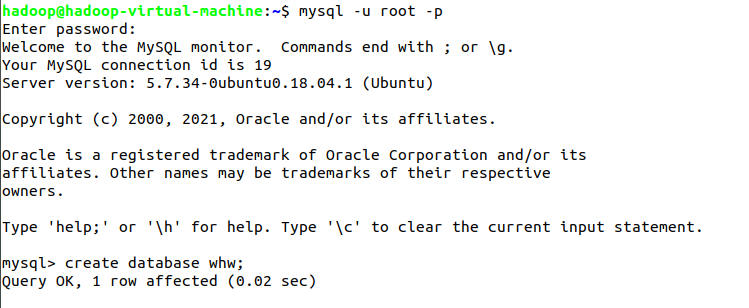
- mysql
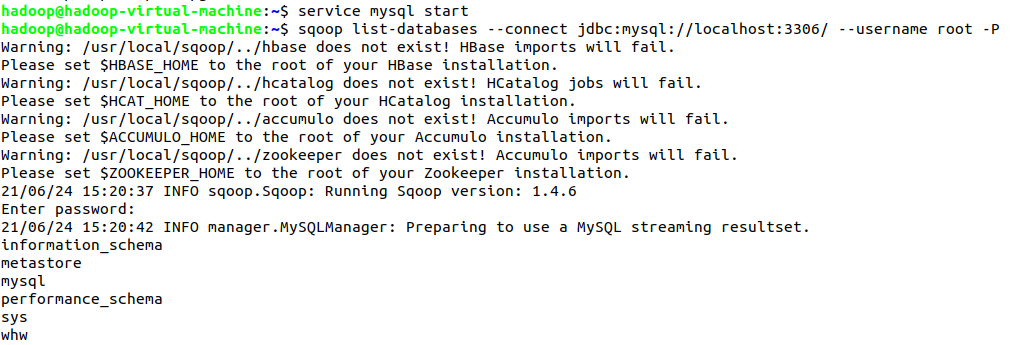
- sqoop
3.2 源数据文件准备
- 下载日志文件
- 将文件拷贝到hadoopvm虚拟机
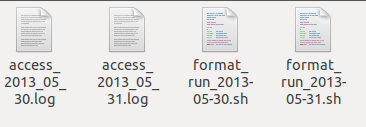
记住虚拟机上本地路径如:/home/hadoop/logfiles/
sudo find / -name hadoop-stream*(找到Hadoop文件路径)
将Python脚本里面的参数和路径替换,刚刚找到的替换第一行
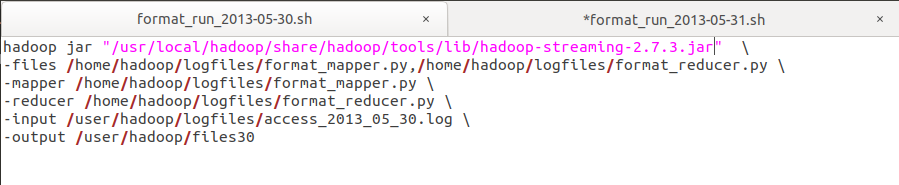
在hdfs里面新建我们的文件夹:logfiles,然后把我们的日志文件放入里面
- 将文件使用hdfs命令上传到HDFS
先创建hdfs路径:
参数解释:创建文件时候mkdir -p (创建多级目录,父目录存在不报错,依旧在此目录创建没有的子目录)
hdfs dfs -mkdir -p /user/hadoop/logfiles再上传文件到hdfs
参数解释:
put命令把本地的文件上传到hdfs里面,命令为put 本地路径 hdfs路径
ls -R 递归显示该目录下的所有文件夹(文件)属性和信息
hdfs dfs -put access_2013_05_30.log /user/hadoop/logfiles
hdfs dfs -put access_2013_05_31.log /user/hadoop/logfiles
hdfs dfs -ls -R /user/hadoop/logfiles

3.3 python开发mapreduce脚本
使用python开发mapreduce脚本对日志数据进行清理,目的是将平面的文本数据解析关键字段成结构化数据,以便存入结构化数据库hive进行分析。
- mapper程序
拷贝到hadoopvm虚拟机,记住路径如:/home/hadoop/logfiles/format_mapper.py
- reduce程序
拷贝到hadoopvm虚拟机,记住路径如:/home/hadoop/logfiles/format_reducer.py
- 使用hadoop-streaming运行mapper reducer程序,示例:
- 修改python程序文件的执行权限:
参数解释:
cd 切换到该路径下,cd ~ :切换到家目录,cd .. 切换到上一级的目录
Chmod 给我们的文件加入权限;数字为777 代表可读可写可执行
详解:
r (read) ----------------> 4
w (write) ----------------> 2
x (excute) ----------------> 1
或者
| u | user 表示该文件的所有者 |
| g | group 表示与该文件的所有者属于同一组( group )者,即用户组 |
| o | other 表示其它用户组 |
| a | all 表示这三者皆是 |
例如:
chmod u+rwx, g+rwx, o+rwx filename 改命令说明对filename文件, 赋予user、group、other均有read、write、excute的权限
cd /home/hadoop/logfiles/
chmod 777 format_mapper.py
chmod 777 format_reducer.py
chmod 777 format_run_2013-05-30.sh
chmod 777 format_run_2013-05-31.sh
-执行脚本文件:
cd /home/hadoop/logfiles/
source format_run_2013_o5_30.sh
source format_run_2013_o5_31.sh
执行我们的脚本文件,可以用source或者./
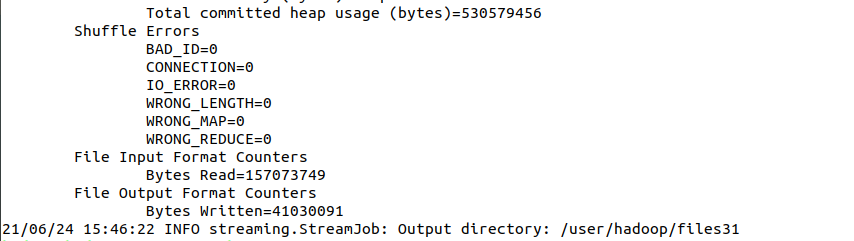
查看数据清洗的文件
hdfs dfs -ls -R /user/hadoop - 结果文件(查看)
- 结果文件(查看)
参数解释:cat 查看文件里面的内容,这个是全部查看,还有其他的查看命令:cat主要有三大功能:
1.一次显示整个文件。
cat filename
2.从键盘创建一个文件。
cat > filename
只能创建新文件,不能编辑已有文件.
3.将几个文件合并为一个文件。
cat file1 file2 > file
Hdfs dfs -cat /user/Hadoop/files30/part-00000
3.4 根据结果文件结构建立hive数据库表
3.4.1在结果文件上创建分区表
- 表名 (techbbs)
- 表类型 (External)
- 表字段
字段名 字段类型 描述
ip string 访客IP地址
atime string 访问时间
url string 访问页面
- 表分区字段 (logdate string)
- 表分隔符 (TERMINATED BY ‘,’)
- 表路径 (LOCATION /xxx/xxx)
首先把清洗后的文件放在我们自己设定的文件夹里面
参数解释:MV 移动或者剪切 使用格式:MV 源文件 目标路径最后也可以对其进行重命名,如果不加/那么就是重命名,加了就是把其粘贴在该路径下面
hdfs dfs -mkdir -p /user/hadoop/data/datas
hdfs dfs -mkdir -p /user/hadoop/data/datas1
hdfs dfs -mv /user/hadoop/files30/part-00000 /user/hadoop/data/datas/30
hdfs dfs -mv /user/hadoop/files31/part-00000 /user/hadoop/datas/datas1/31
hdfs dfs -ls -R /user/hadoop/data

在hive里面进行创建表格,这里创建一个分区表,create external table 表名(字段 字段类型…..)partitioned by (分区字段 字段类型) rowformat delimted fields terminated by ‘分割符’,location 数据路径的祖文件夹(不包含数据的直接存储文件夹)
建表语句:
CREATE EXTERNAL TABLE whw(ip string, atime string, url string) PARTITIONED BY (logdate string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LOCATION '/user/hadoop/data';
截图:

3.4.2 按日期创建分区
建立分区语句
Alter table 表名 add partition(分区字段=‘分区标签’)location 数据路径(数据文件的父文件夹)
ALTER TABLE whw ADD PARTITION(logdate='2013_05_30') LOCATION '/user/hadoop/data/datas';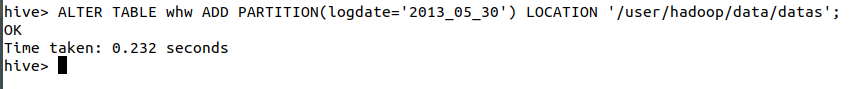

ALTER TABLE whw ADD PARTITION(logdate='2013_05_31') LOCATION '/user/hadoop/data/datas1'; 截图:


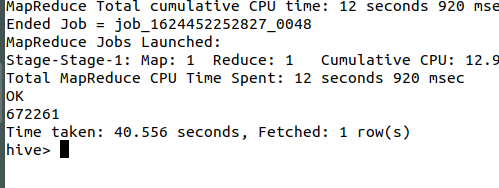
数据导入成功!
3.5 使用Hive对结果表进行数据分析统计
3.5.1 PV量
创建一个表使用create,这里我们把查询出来的数据,直接创建一个视图,select count(1) 统计数量,这里的语法意思就是,统计日期为2013-05-30(2013-05-31)的日志记录数量,也就是PV(浏览量)
CREATE TABLE whw_pv_2013_05_30 AS SELECT COUNT(1) AS PV FROM whw WHERE logdate='2013_05_30'; 
CREATE TABLE whw_pv_2013_05_31 AS SELECT COUNT(1) AS PV FROM whw WHERE logdate='2013_05_31';
3.5.2 注册用户数
这里使用一个hive里面的函数:instr(源字符串,匹配字符串),通过给定一个字符串,然后利用匹配字符串的整体,返回匹配字符串的第一个字符在源字符串的索引位置。所以该语句就是有两个条件,分别是日期和个函数所匹配到的结果,如果有这个网址那么就是返回一个索引(大于0的)
CREATE TABLE whw_reguser_2013_05_30 AS SELECT COUNT(1) AS REGUSER FROM whw WHERE logdate = '2013_05_30' AND INSTR(url,'member.php?mod=register')>0;
CREATE TABLE whw_reguser_2013_05_31 AS SELECT COUNT(1) AS REGUSER FROM whw WHERE logdate = '2013_05_31' AND INSTR(url,'member.php?mod=register')>0; 
3.5.3 独立IP数
独立IP数,这里直接对我们的IP字段进行去重处理,这样就可以显示IP的独立数量了
CREATE TABLE whw_ip_2013_05_30 AS SELECT COUNT(DISTINCT ip) AS IP FROM whw WHERE logdate='2013_05_30';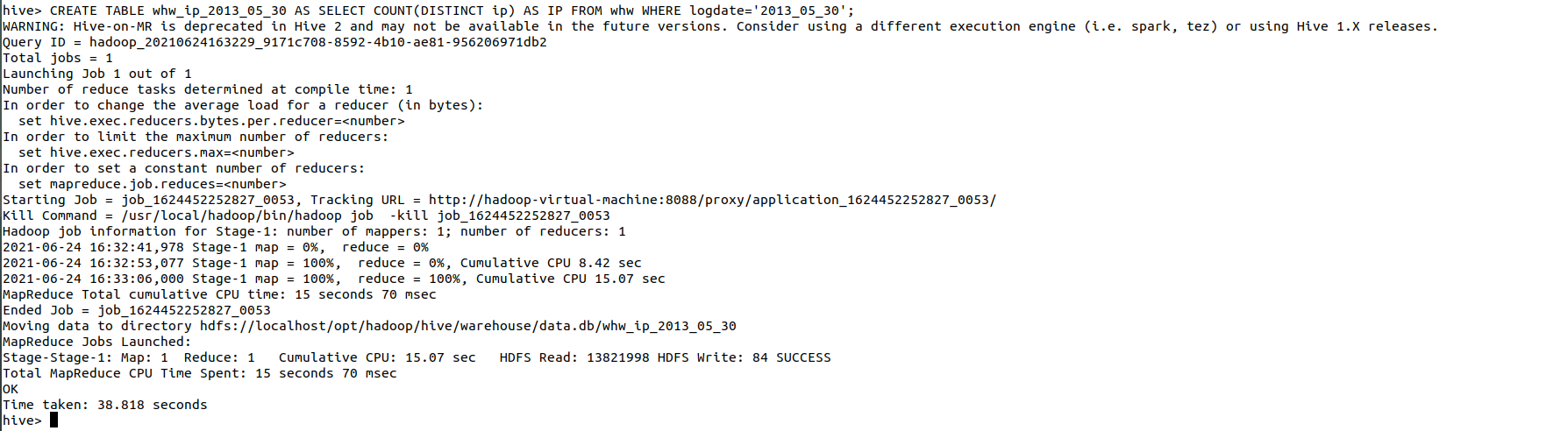
CREATE TABLE whw_ip_2013_05_31 AS SELECT COUNT(DISTINCT ip) AS IP FROM whw WHERE logdate='2013_05_31';
3.5.4 跳出用户数
跳出用户数:只浏览了一个页面便离开了网站的访问次数,即只浏览了一个页面便不再访问的访问次数。这里,我们可以通过用户的IP进行分组,如果分组后的记录数只有一条,那么即为跳出用户。将这些用户的数量相加,就得出了跳出用户数
先对IP进行分组,然后使用having进行过滤 过滤这个分组里面只有一条记录的条数,最后进行计数,就得到了我们的跳出用户数量
create table whw_jumper_2013_05_30 as select count(1) as jumper from (select count(ip) as times from whw where logdate='2013_05_30' group by ip having times=1) e;
create table whw_jumper_2013_05_31 as select count(1) as jumper from (select count(ip) as times from whw where logdate='2013_05_31' group by ip having times=1) e; 
将所有的查询放在一张表里:
set hive.mapred.mode=nonstrict;(解决多表连接的问题)
内连接表示查询两个表的交集,而且ON的条件为 1=1 就表示连接条件永远成立,这里使用将所有的查询结果汇总到一张数据表里面
create table whw_2013_05_30 as select '2013_05_30',a.pv,b.reguser,c.ip,d.jumper from whw_pv_2013_05_30 a join whw_reguser_2013_05_30 b on 1=1 join whw_ip_2013_05_30 c on 1=1 join whw_jumper_2013_05_30 d on 1=1;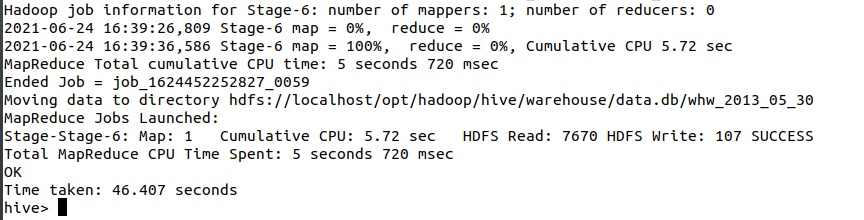
select * from whw_2013_05_30; 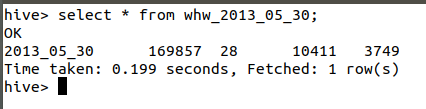
create table whw_2013_05_31 as select '2013_05_31',a.pv,b.reguser,c.ip,d.jumper from whw_pv_2013_05_31 a join whw_reguser_2013_05_31 b on 1=1 join whw_ip_2013_05_31 c on 1=1 join whw_jumper_2013_05_31 d on 1=1;
select * from whw_2013_05-31; 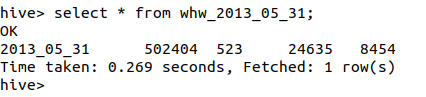
3.6 使用Sqoop将hive分析结果表导入mysql
3.6.1 创建mysql表
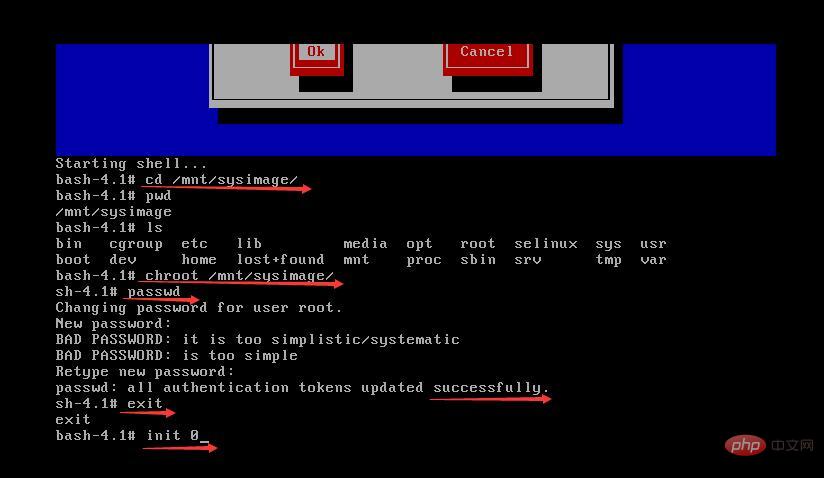
mysql -u root -p(启动MySQL,需要输入密码,不显示)
create database whw;(创建数据库)
创建一个表格
create table whw_logs_stat(logdate varchar(10) primary key,pv int,reguser int,ip int,jumper int);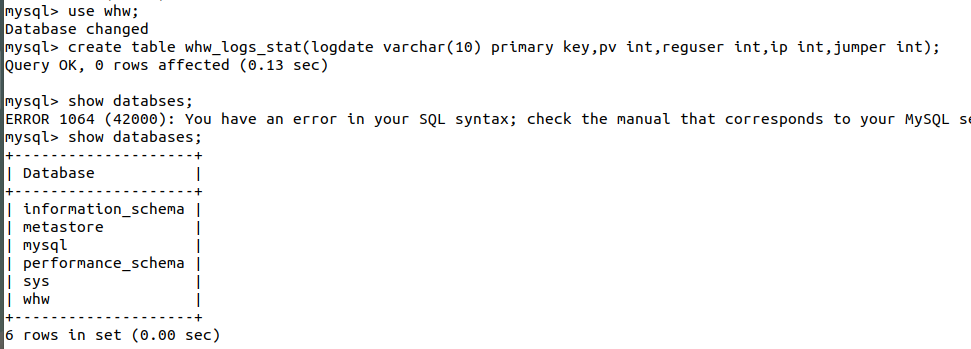
3.6.2 将hive结果文件导入mysql
查看hive存放的表位置
show create table whw_2013_05_30;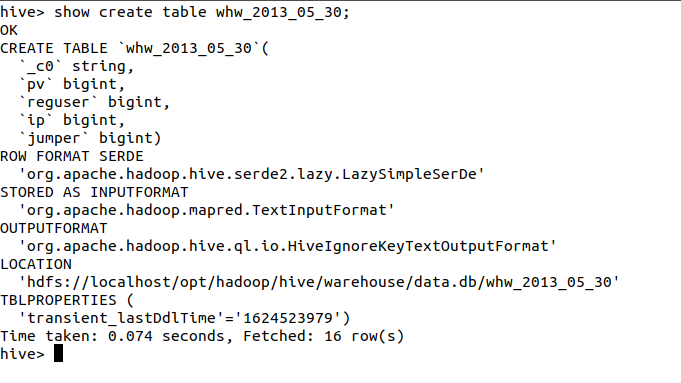
使用sqoop将我们的hive里面的结果表导入到我们的MySQL里面,使用sqoop export –connect jdbc:mysql://localhost:3306/数据库 –username root -p –table MySQL里面的表名 –export-dir hive里面结果表的存储位置 -m 1 –input -fields-terminated -by ‘\001’
新建终端执行:
sqoop export --connect jdbc:mysql://localhost:3306/whw --username root -P --table whw_logs_stat --export-dir /opt/hadoop/hive/warehouse/data.db/whw_2013_05_30 -m 1 --input-fields-terminated-by '\001'
sqoop export --connect jdbc:mysql://localhost:3306/whw --username root -P --table whw_logs_stat --export-dir /opt/hadoop/hive/warehouse/data.db/whw_2013_05_31 -m 1 --input-fields-terminated-by '\001'
查看MySQL是否导入成功
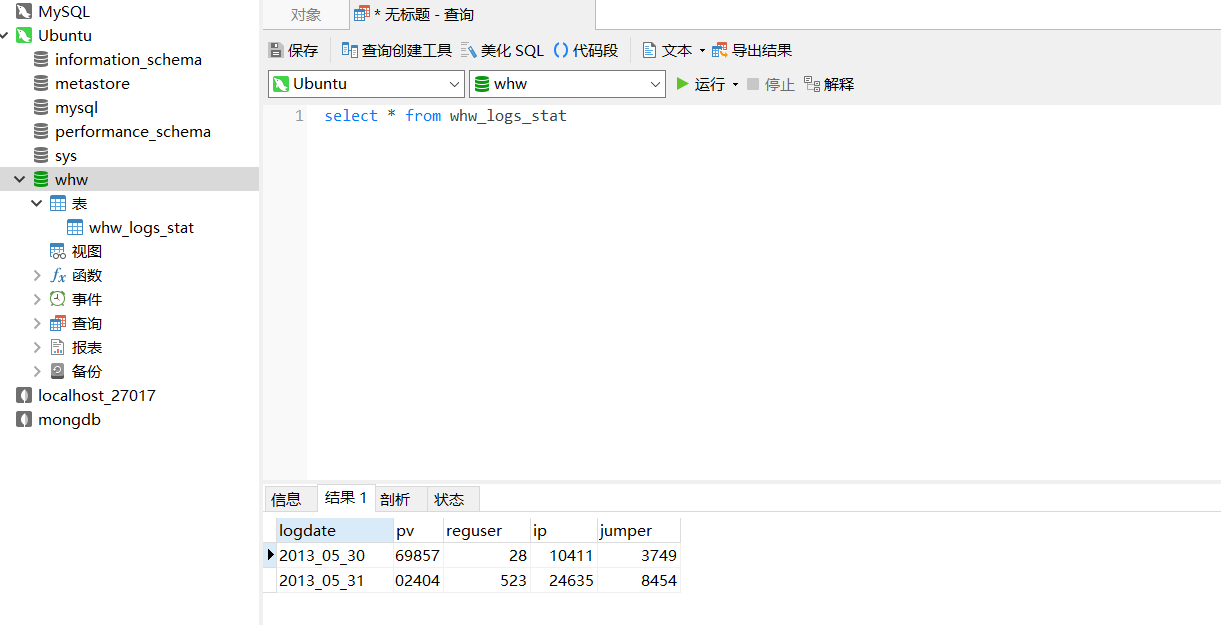
select * from whw_logs_stat;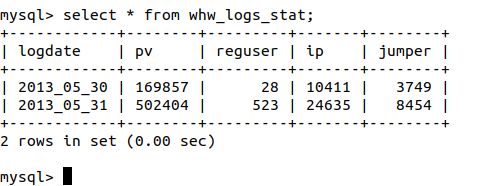
成功导入!

附加操作—增添色彩
本地Navicat连接:
(我们用虚拟机里面的IP来连接我们的本地Navicat,这样有助于我们数据分析可视化!)
数据可视化(项目色彩一);
数据可视化可以直观的把我们的数据展现出来,作为领导者决策的重要参考意见
我采用pycharm的pymysql对虚拟机里面的MySQL进行远程连接,通过编程对数据可视化一键展示,不需要我们手动的添加数据,直接可以保存变量数据
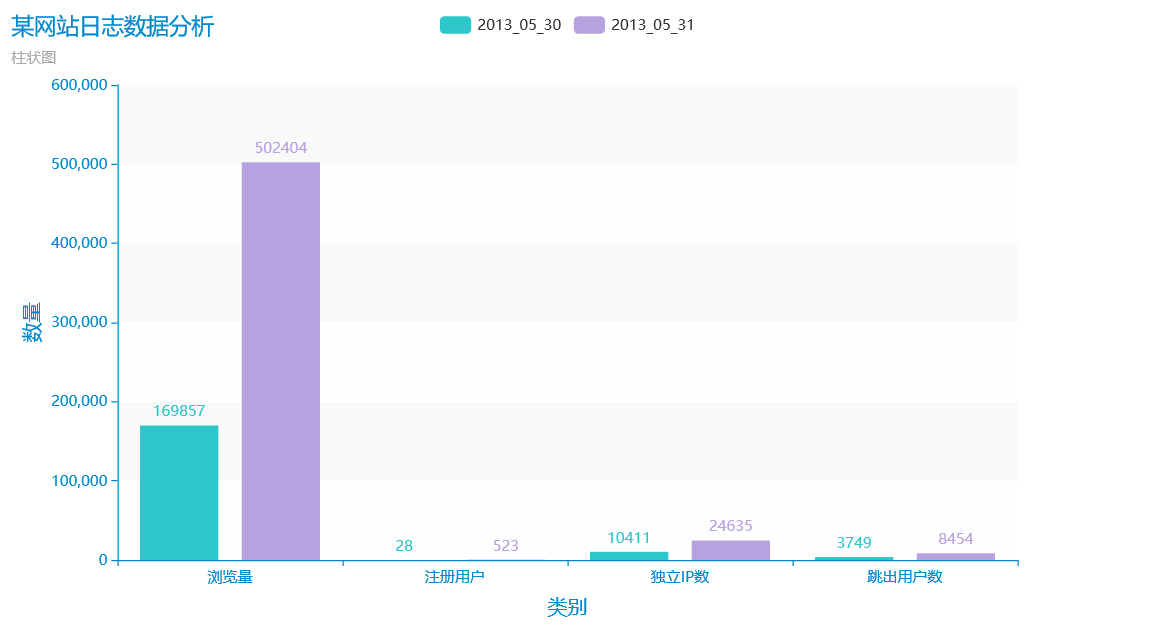
简单的数据分析:很明显我们可以通过可视化的效果得知,2013-05-31的浏览量、注册用户、独立IP数这些正向指标都比较的好,都是高于2013-05-30的效果,所以我们可以在这一天对网站加大维护和投入相应的广告来盈利。
from pyecharts.globals import ThemeType
from pyecharts import options as opts
from pyecharts.charts import Bar
import pymysql
conn = pymysql.connect(host='192.168.190.135',user='root',password='2211',database='whw',port=3306,charset='utf8'
)
cur = conn.cursor()
sql = 'select logdate as `日期`,pv as `浏览量`,reguser as `注册用户数`,ip as `独立IP数量`,jumper as `跳出用户数` from `whw_logs_stat`;'
cur.execute(sql)
data = cur.fetchall()
print(data)
x_1=list(data[0][1:])
x_2=list(data[1][1:])
print(x_1)
print(x_2)
a=[]
for x in data:a.append(x[0])
a_1=a[0]
a_2=a[1]
print(a_1)
print(a_2)
conn.close()data_0=['浏览量', '注册用户', '独立IP数', '跳出用户数']
c = (Bar({"theme": ThemeType.MACARONS}).add_xaxis(data_0).add_yaxis(a_1, x_1) #gap="0%" 这个可设置柱状图之间的距离.add_yaxis(a_2, x_2) #gap="0%" 这个可设置柱状图之间的距离.set_global_opts(title_opts={"text": "某网站日志数据分析", "subtext": "柱状图"}, #该标题的颜色跟随主题# 该标题默认为黑体显示,一般作为显示常态# title_opts=opts.TitleOpts(title="标题")xaxis_opts=opts.AxisOpts(name='类别',name_location='middle',name_gap=30, # 标签与轴线之间的距离,默认为20,最好不要设置20name_textstyle_opts=opts.TextStyleOpts(font_family='Times New Roman',font_size=16 # 标签字体大小)),yaxis_opts=opts.AxisOpts(name='数量',name_location='middle',name_gap=60,name_textstyle_opts=opts.TextStyleOpts(font_family='Times New Roman',font_size=16# font_weight='bolder',)),# datazoom_opts=opts.DataZoomOpts(type_="inside"), #鼠标可以滑动控制# toolbox_opts=opts.ToolboxOpts() # 工具选项# brush_opts=opts.BrushOpts() #可以保存选择).render("简单柱状图.html")
)
print("图表已生成!请查收!")
将数据导入到hbase(项目色彩二)
创建数据表和列族:create 'whw','data'
插入数据:
Put 'whw','1','data:londate,pv,reguser,jumper','2013-05-30,69857,28,10411,3749'
put 'whw','2','data:londate,pv,reguser,jumper','2013-05-31,502404,523,24635,8454'参数说明:添加数据:put ‘表名称’,’行键’,’列族:列名1,列名2……’,‘数据1,数据2……’在这里我们就可以理解为是一个二维表,也就是Excel类似的,一行一列确定一个单元格
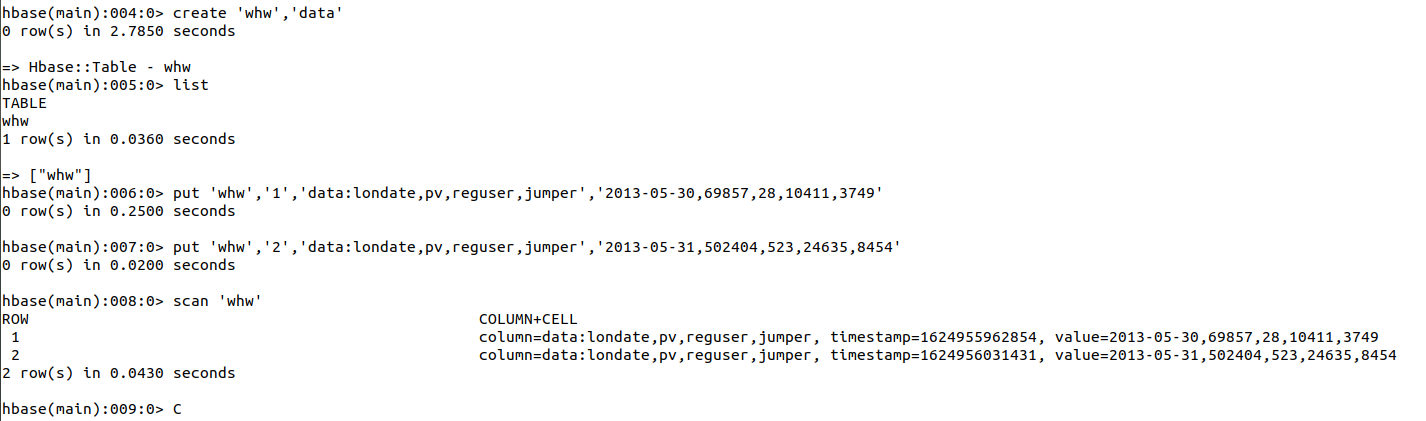
扫描整个列族:scan ‘表名称’, {COLUMN=>‘列族’}
Scan ‘whw’,{ COLUMN =>’data’}

每文一语
左手诗情画意,右手代码人生,欢迎一起探讨技术的诗情画意!