python中nlp的库
The most important step of any data-driven project is obtaining quality data. Without these preprocessing steps, the results of a project can easily be biased or completely misunderstood. Here, we will focus on cleaning data that is composed of scraped web pages.
任何数据驱动项目中最重要的步骤是获取质量数据。 没有这些预处理步骤,项目的结果很容易产生偏差或被完全误解。 在这里,我们将着重于清理由抓取的网页组成的数据。
获取数据 (Obtaining the data)
There are many tools to scrape the web. If you are looking for something quick and simple, the URL handling module in Python called urllib might do the trick for you. Otherwise, I recommend scrapyd because of the possible customizations and robustness.
有很多工具可以抓取网络。 如果您正在寻找快速简单的方法,那么Python中称为urllib的URL处理模块可能会帮您这个忙 。 否则,我建议您使用scrapyd,因为可能会进行自定义和增强鲁棒性。
It is important to ensure that the pages you are scraping contain rich text data that is suitable for your use case.
确保要抓取的页面包含适合您的用例的富文本数据非常重要。
从HTML到文本 (From HTML to text)
Once we have obtained our scraped web pages, we begin by extracting the text out of each web page. Websites have lots of tags that don’t contain useful information when it comes to NLP, such as <script> and <button>. Thankfully, there is a Python module called boilerpy3 that makes text extraction easy.
获取抓取的网页后,我们将从每个网页中提取文本开始。 网站上有很多标签,其中包含<script>和<button> ,这些标签不包含有关NLP的有用信息。 值得庆幸的是,有一个名为boilerpy3的Python模块,可轻松提取文本。
We use the ArticleExtractor to extract the text. This extractor has been tuned for news articles that works well for most HTMLs. You can try out other extractors listed in the documentation for boilerpy3 and see what works best for your dataset.
我们使用ArticleExtractor提取文本。 该提取器已针对大多数HTML都适用的新闻文章进行了调整。 您可以尝试锅炉3文档中列出的其他提取器,并查看最适合您的数据集的提取器。
Next, we condense all newline characters (\n and \r) into one \n character. This is done so that when we split the text up into sentences by \n and periods, we don’t get sentences with no words.
接下来,我们将所有换行符( \n和\r )压缩为一个\n字符。 这样做是为了使我们在将文本按\n和句点分成句子时,不会得到没有单词的句子。
import os
import re
from boilerpy3 import extractors# Condenses all repeating newline characters into one single newline character
def condense_newline(text):return '\n'.join([p for p in re.split('\n|\r', text) if len(p) > 0])# Returns the text from a HTML file
def parse_html(html_path):# Text extraction with boilerpy3html_extractor = extractors.ArticleExtractor()return condense_newline(html_extractor.get_content_from_file(html_path))# Extracts the text from all html files in a specified directory
def html_to_text(folder):parsed_texts = []filepaths = os.listdir(folder)for filepath in filepaths:filepath_full = os.path.join(folder, filepath)if filepath_full.endswith(".html"):parsed_texts.append(parse_html(filepath_full))return parsed_texts# Your directory to the folder with scraped websites
scraped_dir = './scraped_pages'
parsed_texts = html_to_text(scraped_dir)If the extractors from boilerpy3 are not working for your web pages, you can use beautifulsoup to build your own custom text extractor. Below is an example replacement of the parse_html method.
如果boilerpy3的提取器不适用于您的网页,则可以使用beautifulsoup构建自己的自定义文本提取器。 下面是parse_html方法的示例替换。
from bs4 import BeautifulSoup# Returns the text from a HTML file based on specified tags
def parse_html(html_path):with open(html_path, 'r') as fr:html_content = fr.read()soup = BeautifulSoup(html_content, 'html.parser')# Check that file is valid HTMLif not soup.find():raise ValueError("File is not a valid HTML file")# Check the language of the filetag_meta_language = soup.head.find("meta", attrs={"http-equiv": "content-language"})if tag_meta_language:document_language = tag_meta_language["content"]if document_language and document_language not in ["en", "en-us", "en-US"]:raise ValueError("Language {} is not english".format(document_language))# Get text from the specified tags. Add more tags if necessary.TAGS = ['p']return ' '.join([remove_newline(tag.text) for tag in soup.findAll(TAGS)])大型N型清洗 (Large N-Gram Cleaning)
Once the text has been extracted, we want to continue with the cleaning process. It is common for web pages to contain repeated information, especially if you scrape multiple articles from the same domain. Elements such as website titles, company slogans, and page footers can be present in your parsed text. To detect and remove these phrases, we analyze our corpus by looking at the frequency of large n-grams.
提取文本后,我们要继续进行清理过程。 网页通常包含重复的信息,尤其是当您从同一域中抓取多篇文章时。 网站标题,公司标语和页面页脚等元素可以出现在您的解析文本中。 为了检测和删除这些短语,我们通过查看大n-gram的频率来分析我们的语料库。
N-grams is a concept from NLP where the “gram” is a contiguous sequence of words from a body of text, and “N” is the size of these sequences. This is frequently used to build language models which can assist in tasks ranging from text summarization to word prediction. Below is an example for trigrams (3-grams):
N-gram是NLP的概念,其中“ gram”是来自正文的单词的连续序列,而“ N”是这些序列的大小。 这通常用于构建语言模型,该模型可以协助完成从文本摘要到单词预测的任务。 以下是三字母组(3克)的示例:
input = 'It is quite sunny today.'
output = ['It is quite', is quite sunny', 'quite sunny today.']When we read articles, there are many single words (unigrams) that are repeated, such as “the” and “a”. However, as we increase our n-gram size, the probability of the n-gram repeating decreases. Trigrams start to become more rare, and it is almost impossible for the articles to contain the same sequence of 20 words. By searching for large n-grams that occur frequently, we are able to detect the repeated elements across websites in our corpus, and manually filter them out.
当我们阅读文章时,有很多重复的单词(字母组合),例如“ the”和“ a”。 但是,随着我们增加n-gram大小,n-gram重复的可能性降低。 Trigram开始变得越来越稀有,文章几乎不可能包含20个单词的相同序列。 通过搜索频繁出现的大n-gram,我们可以检测到语料库中各个网站上的重复元素,并手动将其过滤掉。
We begin this process by breaking up our dataset up into sentences by splitting the text chunks up by the newline characters and periods. Next, we tokenize our sentences (break up the sentence into single word strings). With these tokenized sentences, we are able to generate n-grams of a specific size (we want to start large, around 15). We want to sort the n-grams by frequency using the FreqDist function provided by nltk. Once we have our frequency dictionary, we print the top 10 n-grams. If the frequency is higher than 1 or 2, the sentence might be something you would consider removing from the corpus. To remove the sentence, copy the entire sentence and add it as a single string in the filter_strs array. Copying the entire sentence can be accomplished by increasing the n-gram size until the entire sentence is captured in one n-gram and printed on the console, or simply printing the parsed_texts and searching for the sentence. If there is multiple unwanted sentences with slightly different words, you can copy the common substring into filter_strs, and the regular expression will filter out all sentences containing the substring.
我们通过以换行符和句点将文本块拆分为句子来将数据集分解为句子来开始此过程。 接下来,我们将句子标记化(将句子分解成单个单词字符串)。 使用这些标记化的句子,我们能够生成特定大小的n-gram(我们希望从15开始大一点)。 我们要使用的正克按频率进行排序FreqDist所提供的功能nltk 。 有了频率字典后,我们将打印出前10个n-gram。 如果频率高于1或2,则可能要考虑从句子中删除句子。 要删除该句子,请复制整个句子并将其作为单个字符串添加到filter_strs数组中。 复制整个句子可以通过增加n-gram的大小,直到整个句子被捕获为一个n-gram并打印在控制台上,或者简单地打印parsed_texts并搜索句子来完成。 如果有多个不需要的句子,且单词略有不同,则可以将公共子字符串复制到filter_strs ,并且正则表达式将过滤掉包含该子字符串的所有句子。
import nltk
nltk.download('punkt')
import matplotlib.pyplot as plt
from nltk.util import ngrams
from nltk.tokenize import word_tokenize# Helper method for generating n-grams
def extract_ngrams_sentences(sentences, num):all_grams = []for sentence in sentences:n_grams = ngrams(sentence, num)all_grams += [ ' '.join(grams) for grams in n_grams]return all_grams# Splits text up by newline and period
def split_by_newline_and_period(pages):sentences = []for page in pages:sentences += re.split('\n|\. ', page)return sentences# Break the dataset up into sentences, split by newline characters and periods
sentences = split_by_newline_and_period(parsed_texts)# Add unwanted strings into this array
filter_strs = []# Filter out unwanted strings
sentences = [x for x in sentencesif not any([re.search(filter_str, x, re.IGNORECASE)for filter_str in filter_strs])]# Tokenize the sentences
tokenized_sentences = [word_tokenize(sentence) for sentence in sentences]# Adjust NGRAM_SIZE to capture unwanted phrases
NGRAM_SIZE = 15
ngrams_all = extract_ngrams_sentences(tokenized_sentences, NGRAM_SIZE)# Sort the n-grams by most common
n_gram_all = nltk.FreqDist(ngrams_all).most_common()# Print out the top 10 most commmon n-grams
print(f'{NGRAM_SIZE}-Gram Frequencies')
for gram, count in n_gram_all[:10]:print(f'{count}\t\"{gram}\"')# Plot the distribution of n-grams
plt.plot([count for _, count in n_gram_all])
plt.xlabel('n-gram')
plt.ylabel('frequency')
plt.title(f'{NGRAM_SIZE}-Gram Frequencies')
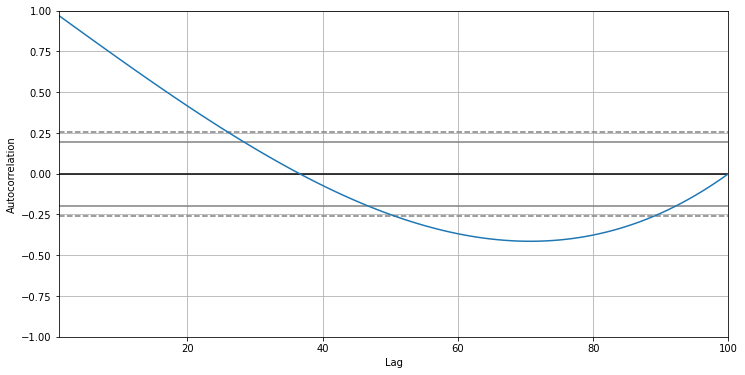
plt.show()If you run the code above on your dataset without adding any filters to filter_strs, you might get a graph similar to the one below. In my dataset, you can see that there are several 15-grams that are repeated 6, 3, and 2 times.
如果您在数据集上运行上面的代码时未向filter_strs添加任何过滤器,则可能会得到类似于下面的图。 在我的数据集中,您可以看到有一些15克重复6、3和2次。

Once we go through the process of populating filter_strs with unwanted sentences, our plot of 15-grams flattens out.
一旦我们完成了用不需要的句子填充filter_strs的过程,我们的15克图表便变平了。

Keep in mind there is no optimal threshold for n-gram size and frequency that determines whether or not a sentence should be removed, so play around with these two parameters. Sometimes you will need to lower the n-gram size to 3 or 4 to pick up a repeated title, but be careful not to remove valuable data. This block of code is designed to be an iterative process, where you slowly build the filter_strs array after many different experiments.
请记住,没有确定n-gram大小和频率的最佳阈值来确定是否应删除句子,因此请试用这两个参数。 有时,您需要将n-gram大小减小到3或4才能获得重复的标题,但请注意不要删除有价值的数据。 此代码块被设计为一个迭代过程,在此过程中,您将在许多不同的实验之后慢慢构建filter_strs数组。
标点,大写和标记化 (Punctuation, Capitalization, and Tokenization)
After we clean the corpus, the next step is to process the words of our corpus. We want to remove punctuation, lowercase all words, and break each sentence up into arrays of individual words (tokenization). To do this, I like to use the simple_preprocess library method from gensim. This function accomplishes all three of these tasks in one go and has a few parameters that allow some customization. By setting deacc=True, punctuation will be removed. When punctuation is removed, the punctuation itself is treated as a space, and the two substrings on each side of the punctuation is treated as two separate words. In most cases, words will be split up with one substring having a length of one. For example, “don’t” will end up as “don” and “t”. As a result, the default min_len value is 2, so words with 1 letter are not kept. If this is not suitable for your use case, you can also create a text processor from scratch. Python’s string class contains a punctuation attribute that lists all commonly used punctuation. Using this set of punctuation marks, you can use str.maketrans to remove all punctuation from a string, but keeping those words that did have punctuation as one single word (“don’t” becomes “dont”). Keep in mind this does not capture punctuation as well as gensim’s simple_preprocess. For example, there are three types of dashes (‘ — ’ em dash, –’ en dash, ‘-’ hyphen), and while simple_preprocess removes them all, string.punctuation does not contain the em dash, and therefore does not remove it.
在清理完语料库之后,下一步就是处理语料库中的单词。 我们要删除标点符号,将所有单词都小写,然后将每个句子分成单个单词的数组(标记化)。 为此,我喜欢使用gensim中的simple_preprocess库方法。 此功能可一次性完成所有这三个任务,并具有一些允许自定义的参数。 通过设置deacc=True ,标点符号将被删除。 删除标点符号后,标点符号本身被视为一个空格,标点符号两侧的两个子字符串被视为两个单独的单词。 在大多数情况下,单词将被一个长度为一的子字符串分割。 例如,“不要”将最终以“ don”和“ t”结尾。 结果,默认的min_len值为2,因此不会保留带有1个字母的单词。 如果这不适合您的用例,您也可以从头开始创建文本处理器。 Python的string类包含一个punctuation属性,该属性列出了所有常用的标点符号。 使用这组标点符号,可以使用str.maketrans删除字符串中的所有标点符号,但是将那些确实具有标点符号的单词保留为一个单词(“不要”变为“不要”)。 请记住,它不像gensim的simple_preprocess一样捕获标点符号。 例如,存在三种类型的破折号(' string.punctuation破折号,-'en破折号,'-'连字符),而simple_preprocess删除了所有破折号, string.punctuation不包含破折号,因此也不会将其删除。 。
import gensim
import string# Uses gensim to process the sentences
def sentence_to_words(sentences):for sentence in sentences:sentence_tokenized = gensim.utils.simple_preprocess(sentence,deacc=True,min_len=2,max_len=15)# Make sure we don't yield empty arraysif len(sentence_tokenized) > 0:yield sentence_tokenized# Process the sentences manually
def sentence_to_words_from_scratch(sentences):for sentence in sentences:sentence_tokenized = [token.lower() for token in word_tokenize(sentence.translate(str.maketrans('','',string.punctuation)))]# Make sure we don't yield empty arraysif len(sentence_tokenized) > 0:yield sentence_tokenizedsentences = list(sentence_to_words(sentences))停用词 (Stop Words)
Once we have our corpus nicely tokenized, we will remove all stop words from the corpus. Stop words are words that don’t provide much additional meaning to a sentence. Words in the English vocabulary include “the”, “a”, and “in”. nltk contains a list of English stopwords, so we use that to filter our lists of tokens.
一旦我们对语料库进行了很好的标记,我们将从语料库中删除所有停用词。 停用词是不会为句子提供更多附加含义的词。 英语词汇中的单词包括“ the”,“ a”和“ in”。 nltk包含英语停用词列表,因此我们使用它来过滤标记列表。
拔除和摘除 (Lemmatization and Stemming)
Lemmatization is the process of grouping together different forms of the same word and replacing these instances with the word’s lemma (dictionary form). For example, “functions” is reduced to “function”. Stemming is the process of reducing a word to its root word (without any suffixes or prefixes). For example, “running” is reduced to “run”. These two steps decreases the vocabulary size, making it easier for the machine to understand our corpus.
合法化是将同一个单词的不同形式组合在一起,并用单词的引理(字典形式)替换这些实例的过程。 例如,“功能”被简化为“功能”。 词干处理是将单词还原为其根单词(没有任何后缀或前缀)的过程。 例如,“运行”减少为“运行”。 这两个步骤减小了词汇量,使机器更容易理解我们的语料库。
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
from nltk.stem import SnowballStemmer
nltk.download('stopwords')
nltk.download('wordnet')# Remove all stopwords
stop_words = stopwords.words('english')
def remove_stopwords(tokenized_sentences):for sentence in tokenized_sentences:yield([token for token in sentence if token not in stop_words])# Lemmatize all words
wordnet_lemmatizer = WordNetLemmatizer()
def lemmatize_words(tokenized_sentences):for sentence in tokenized_sentences:yield([wordnet_lemmatizer.lemmatize(token) for token in sentence])snowball_stemmer = SnowballStemmer('english')
def stem_words(tokenized_sentences):for sentence in tokenized_sentences:yield([snowball_stemmer.stem(token) for token in sentence])sentences = list(remove_stopwords(sentences))
sentences = list(lemmatize_words(sentences))
sentences = list(stem_words(sentences))Now that you know how to extract and preprocess your text data, you can begin the data analysis. Best of luck with your NLP adventures!
既然您知道如何提取和预处理文本数据,就可以开始数据分析了。 祝您在NLP冒险中好运!
笔记 (Notes)
- If you are tagging the corpus with parts-of-speech tags, stop words should be kept in the dataset and lemmatization should not be done prior to tagging. 如果要使用词性标记来标记语料库,则停用词应保留在数据集中,并且在标记之前不应该进行词形化。
The GitHub repository for the Jupyter Notebook can be found here.
可以在此处找到Jupyter Notebook的GitHub存储库。
翻译自: https://towardsdatascience.com/website-data-cleaning-in-python-for-nlp-dda282a7a871
python中nlp的库
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.luyixian.cn/news_show_707653.aspx
如若内容造成侵权/违法违规/事实不符,请联系dt猫网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
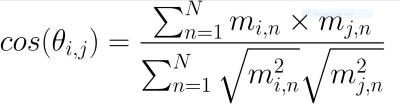
ajax不利于seo_利于探索移动选项的界面
如何优化网站加载时间
鲜为人知的6个黑科技网站_6种鲜为人知的熊猫绘图工具



新版 Android 已支持 FIDO2 标准,免密登录应用或网站

【百度】大型网站的HTTPS实践(一)——HTTPS协议和原理

COOKIE伪造登录网站后台

phpstudy如何安装景安ssl证书 window下apache服务器网站https访问

【计算机网络】手动配置hosts文件解决使用GitHub和Coursera网站加载慢/卡的问题
小白创建网站的曲折之路
html在线编辑器 asp.net,ASP.NET网站使用Kindeditor富文本编辑器配置步骤
![大型网站服务器 pdf,大型网站服务器容量规划[PDF][145.25MB]](https://img-blog.csdnimg.cn/img_convert/d69c7a6a67a3f04be90eedc900601efa.png)
大型网站服务器 pdf,大型网站服务器容量规划[PDF][145.25MB]

怎么暂时关闭网站php,WordPress怎么临时关闭网站进行维护

17joys网站后台功能设计-阶段1

拉拢中小网站 淘宝百度暗战升级...

10款精选的用于构建良好易用性网站的jQuery插件

A4Desk 网站破解
