ARIMA:AutoregressiveIntegratedMovingAverage model。自回归差分移动平均模型(p,d,q),可以说AR自回归模型,MA移动平均模型,ARMA自回归移动平均模型都是ARIMA的特殊形式. 时间序列模型一般性步骤包括:1. 数据平稳性检验;2. 确定模型参数;3. 构建时间序列模型;4.模型预测;5.模型准确性评估。
1.平稳性检验
该模型要求时间序列必须是平稳的,所以第一步是对原始数据进行平稳性检验。
A. 直观观察数据
最直观的方式可以先做出序列图,看看数据是否平稳。例如


clear all
clc
% 数据来源于网络
data=[10930,10318,10595,10972,7706,6756,9092,10551,9722,10913,11151,8186,6422 ...
6337,11649,11652,10310,12043,7937,6476,9662,9570,9981,9331,9449,6773,6304,9355 ...
10477,10148,10395,11261,8713,7299,10424,10795,11069,11602,11427,9095,7707,10767 ...
12136,12812,12006,12528,10329,7818,11719,11683,12603,11495,13670,11337,10232 ...
13261,13230,15535,16837,19598,14823,11622,19391,18177,19994,14723,15694,13248 ...
9543,12872,13101,15053,12619,13749,10228,9725,14729,12518,14564,15085,14722 ...
11999,9390,13481,14795,15845,15271,14686,11054,10395];
subplot(131)
plot(data,'b-','LineWidth',2)
xlabel('time')
ylabel('data')
set(gca,'fontsize',15)
subplot(132)
ddata = diff(data);
plot(ddata,'b-','LineWidth',2)
xlabel('time')
ylabel('data的一阶差分')
set(gca,'fontsize',15)
subplot(133)
dddata = diff(data,2);
plot(dddata,'b-','LineWidth',2)
xlabel('time')
ylabel('data的二阶差分')
set(gca,'fontsize',15)
从图中看上起原始序列是不稳定的,尤其是在t=50到70之间数据突然发生显著改变。因此我们需要对其差分,差分之后数据基本上平稳。当然全靠肉眼的判断和判断人的经验,不同的人看到同样的图形,很可能会给出不同的判断。因此这里也进一步需要更加数学的方法。
B. 数学方法计算(ADF单位根平稳型检验,KPSS检验等)
通常的检验方法有很多种,包括ADF、KPSS等。
out1 = adftest(data)
如果返回值out1=0,则拒绝原假设,说明数据是不平稳的; 如果结果out1=1,表示不拒绝原假设,数据平稳. 第二种检测
out1 = kpsstest(data)
对于kpss检验则相反。如果返回值out1=0,则不能拒绝原假设,说明数据是平稳的; 如果结果out1=1,表示拒绝原假设,数据不平稳. 以上两种方法可以结合使用,也可以使用其中一种就可以了。通过上面两种检验方法发现结果确实不稳定。
>> adftest(data)
ans =
logical
0
>> kpsstest(data)
ans =
logical
1
如果平稳性检测结果表明原始时间序列不平稳,那就需要此时对原始数据取差分,再进行检验。先 进行一阶差分,结果平稳就结束差分过程。如果依旧不平稳的话,再次求差分,直至通过检验。
ddata = diff(data);
d1_adf = adftest(ddata)
d1_kpss = kpsstest(ddata)
检验结果为
d1_adf =
logical
1
d1_kpss =
logical
0
最终得到d1_adf =1,d1_kpss =0通过检验。因此一阶差分之后的数据就可以进行时间序列建模分析了。由于进行了差分处理,最后的数据需要反差分回到原始数据。
2. 确定ARIMA模型阶数
经过平稳性检验后的数据就可以进行时间序列分析了。下面就是需要确定ARMA的参数p,q,d. 常用的方法就是通过自相关函数(ACF)与偏自相关函数(PACF)来确定。这里p与q就是下面公式中系数的阶数,d是差分阶数


A. 平稳时间序列的自相关图和偏自相关图。
第一步我们要先检查平稳时间序列的自相关图和偏自相关图。关于自相关函数与偏自相关函数的理论知识参加本文附录部分。p和q则可以根据自相关系数和偏自相关系数是否在某一阶截尾或者拖尾给出相应的值。
| 模型 | 自相关 | 偏自相关 |
|---|---|---|
| ARIMA(p,d,0) | 逐渐减小到零 | P阶后减小到零 |
| ARIMA(0,d,q) | q阶后减小到零 | 逐渐减小到零 |
| ARIMA(p,d,q) | 逐渐减小到零 | 逐渐减小到零 |
这里给出matlab中的用法,其中data是平稳化之后的时间序列数据。
% 绘制自相关与偏自相关图
% 这里要用一阶差分之后的数据绘图
figure
subplot(121)
autocorr(ddata)
set(gca,'fontsize',15)
subplot(122)
parcorr(ddata)
set(gca,'fontsize',15)


其中lags 表示滞后的阶数,以上分别得到acf 图和pacf 图。从检验分析知道,可以从自相关图确定q取值,从偏自相关图确定p取值。但是从上面这两个图好像没办法直观确定pq取值,貌似很多阶相关函数超过临界值。不过文献认为
1. 自相关图显示滞后有三个阶超出了置信边界(为什么是3,不是1阶就小于95%区间了吗)
2. 偏相关图显示在滞后1至7阶(lags 1,2,…,7)时的偏自相关系数超出了置信边界,从lag 7之后偏自相关系数值缩小至0
则有以下模型可以供选择:
A. ARMA(0,1)模型:即自相关图在滞后1阶之后缩小为0,且偏自相关缩小至0,则是一个阶数q=1的移动平均模型;
B. ARMA(7,0)模型:即偏自相关图在滞后7阶之后缩小为0,且自相关缩小至0,则是一个阶层p=3的自回归模型;
C. ARMA(7,1)模型:即使得自相关和偏自相关都缩小至零。则是一个混合模型。
D. 还可以有其他供选择的模型。我们通常采用ARMA模型的AIC法则。
* AIC=-2 ln(L) + 2 k 赤池信息量 akaike information criterion
* BIC=-2 ln(L) + ln(n)k :贝叶斯信息量 bayesian information criterion
HQ=-2 ln(L) + ln(ln(n))*k hannan-quinn criterion
下面就通过AIC与BIC准则确定pq取值
%% 计算pq取值
pmax = 4;
qmax = 4;
[p q ]=findPQ(ddata,pmax,qmax);
function [p q] = findPQ(data,pmax,qmax)
data = reshape(data,length(data),1);
LOGL=zeros(pmax+1,qmax+1);
PQ=zeros(pmax+1,qmax+1);
for p=0:pmax
for q=0:qmax
model=arima(p,0,q);
[fit,~,logL]=estimate(model,data); %指定模型的结构
LOGL(p+1,q+1)=logL;
PQ(p+1,q+1)=p+q; %计算拟合参数的个数
end
end
LOGL=reshape(LOGL,(pmax+1)(qmax+1),1);
PQ=reshape(PQ,(pmax+1)(qmax+1),1);
m2 = length(data);
[aic,bic]=aicbic(LOGL,PQ+1,m2);
aic0 = reshape(aic,(pmax+1),(qmax+1));
bic0= reshape(bic,(pmax+1),(qmax+1));
aic1 = min(aic0(:));
index = aic1==aic0;
[pp qq] = meshgrid(0:pmax,0:qmax);
p0 = pp(index);
q0 = qq(index);
aic2 = min(bic0(:));
index = aic2==bic0;
[pp qq] = meshgrid(0:pmax,0:qmax);
p1 = pp(index);
q1 = qq(index);
if p0^2+q0^2> p1^2+q1^2
p = p1;
q = q1;
else
p = p0;
q = q0;
end
end
3. 构建模型
Mdl = arima(p, 1, q); %第二个变量值为1,即一阶差分
EstMdl = estimate(Mdl,data);4. 模型预测
[forData,YMSE] = forecast(EstMdl,step,'Y0',data);
lower = forData - 1.96sqrt(YMSE); %95置信区间下限
upper = forData + 1.96sqrt(YMSE); %95置信区间上限


5. 附录
这里还想具体介绍一下autocorr函数更加一般性的用法。如果仅仅写代码下面更加详细分析可以忽略!!!
如果autocorr不写返回参数则直接会做关联函数的图形。
[ACF,Lags,Bounds] = autocorr(Series)
其中,输入项Series 代表单变量时间序列。返回自关联函数 (ACF)与对应的延迟lags,以及ACF的上下界限。
在函数输入中,还有几个可选项,分别说明如下:
[ACF,Lags, Bounds] = autocorr(Series, nLags,M, nSR)
- 其中 nLags是正整数标量,表示需要计算的ACF的时间滞后步长(lag)。如果该参数缺省,则系统默认的时间滞后序列为0,1,2,...,T,这里T=minimum [20, length(Series)-1]。 这意味着,如果样本长度大于21,则T取20;如果样本长度小于20,则T取样本长度减1。
- M为非负整数标量,表示最大有效时滞。M值不得超过nLags。理论上,如果时滞超过M,则ACF变得与0没有显著性差异。从ACF图来看,可以理解为误差上、下限开始标注的起始步长。
- nSTDs为代表标准误差的倍数(正标量)。如果缺省,则系统默认nSTDs= 2,此时置信区间上、下限给出置信度为95%的二倍标准误差带。
- 函数输出项包括三方面的结果:自相关函数(ACF)、时滞.(Lags)和置信范围上下限(Bounds)。具体说明如下:
- ACF为时间序列样本的自相关函数,这是一个长度为nLags+1的向量,对应于时滞0,1 ,....nLags。其中,第一个数据点为对应于0时滞的单位数1,也就是说,ACF(1)=1。 当时滞为0时,序列与序列完全相关,故ACF值一定为1。
- Lags为滞后向量(0,1, 2..... nLags), 一个Lags值对应于一个ACF值。
- Bounds为二元向量,近似给出ACF置信范围的上限和下限,这个置信范围仅给出Lags> M的结果






clear all
clc
data=[10930,10318,10595,10972,7706,6756,9092,10551,9722,10913,11151,8186,6422 ...
6337,11649,11652,10310,12043,7937,6476,9662,9570,9981,9331,9449,6773,6304,9355 ...
10477,10148,10395,11261,8713,7299,10424,10795,11069,11602,11427,9095,7707,10767 ...
12136,12812,12006,12528,10329,7818,11719,11683,12603,11495,13670,11337,10232 ...
13261,13230,15535,16837,19598,14823,11622,19391,18177,19994,14723,15694,13248 ...
9543,12872,13101,15053,12619,13749,10228,9725,14729,12518,14564,15085,14722 ...
11999,9390,13481,14795,15845,15271,14686,11054,10395];
subplot(131)
plot(data,'b-','LineWidth',2)
xlabel('time')
ylabel('data')
set(gca,'fontsize',15)
subplot(132)
ddata = diff(data);
plot(ddata,'b-','LineWidth',2)
xlabel('time')
ylabel('data的一阶差分')
set(gca,'fontsize',15)
subplot(133)
dddata = diff(data,2);
plot(dddata,'b-','LineWidth',2)
xlabel('time')
ylabel('data的二阶差分')
set(gca,'fontsize',15)
% 数据平稳性测试
adftest(data)
kpsstest(data)
% 一阶差分并平稳性检验
ddata = diff(data);
d1_adf = adftest(ddata)
d1_kpss = kpsstest(ddata)
% 绘制自相关与偏自相关图
% 这里要用一阶差分之后的数据绘图
figure
subplot(211)
autocorr(ddata,40)
ylabel('ACF')
set(gca,'fontsize',15)
subplot(212)
parcorr(ddata,40)
ylabel('PACF')
set(gca,'fontsize',15)
%% 计算pq取值
pmax = 4;
qmax = 4;
d = 1;
%[p q ]=findPQ(data,pmax,qmax,d);
%% 构建模型
p = 3;q = 4;
Mdl = arima(p, 1, q); %第二个变量值为1,即一阶差分
EstMdl = estimate(Mdl,data');
%% 模型预测
step = 10;
[forData,YMSE] = forecast(EstMdl,step,'Y0',data');
%matlab2018及以下版本写为Predict_Y(i+1) = forecast(EstMdl,1,'Y0',Y(1:i));
lower = forData - 1.96sqrt(YMSE); %95置信区间下限
upper = forData + 1.96sqrt(YMSE); %95置信区间上限
figure
plot(1:length(data),data)
hold on
plot((length(data)+1):length(data)+step,forData)
hold on
plot((length(data)+1):length(data)+step,lower)
plot((length(data)+1):length(data)+step,upper)
function [p q] = findPQ(data,pmax,qmax,d)
data = reshape(data,length(data),1);
LOGL=zeros(pmax+1,qmax+1);
PQ=zeros(pmax+1,qmax+1);
for p=0:pmax
for q=0:qmax
model=arima(p,d,q);
[fit,~,logL]=estimate(model,data); %指定模型的结构
LOGL(p+1,q+1)=logL;
PQ(p+1,q+1)=p+q; %计算拟合参数的个数
end
end
LOGL=reshape(LOGL,(pmax+1)(qmax+1),1);
PQ=reshape(PQ,(pmax+1)(qmax+1),1);
m2 = length(data);
[aic,bic]=aicbic(LOGL,PQ+1,m2);
aic0 = reshape(aic,(pmax+1),(qmax+1));
bic0= reshape(bic,(pmax+1),(qmax+1));
aic1 = min(aic0(:));
index = aic1==aic0;
[pp qq] = meshgrid(0:pmax,0:qmax);
p0 = pp(index);
q0 = qq(index);
aic2 = min(bic0(:));
index = aic2==bic0;
[pp qq] = meshgrid(0:pmax,0:qmax);
p1 = pp(index);
q1 = qq(index);
if p0^2+q0^2> p1^2+q1^2
p = p1;
q = q1;
else
p = p0;
q = q0;
end




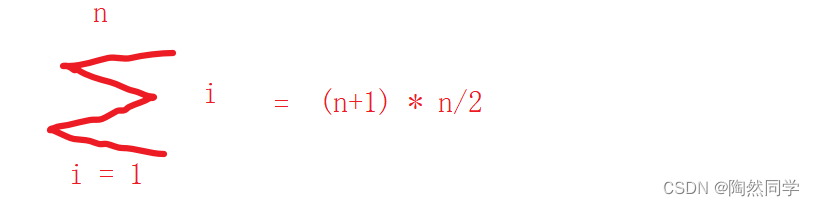






![[基于瑞芯微RV1126调试RTL8818FU WIFI模组支持STA和AP模式]](https://img-blog.csdnimg.cn/0e27a7d5a4fa4dea9e69bbac431f0bc1.png)