😋DolphinScheduler实例表备份、清理
👊一、前言
DolphinScheduler至今已经在项目中使用了将近一年,工作流实例和任务流实例都积累了百万级的数据量。在查看工作流实例和任务实例的时候,都要等待后台去查询数据库,感觉在使用上不太方便。所以想着以某一日期为界限,备份后再清除这部分数据。

👊二、查看实例表
🙇♀2.1 工作流实例
表结构
CREATE TABLE `t_ds_process_instance` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',`name` varchar(255) DEFAULT NULL COMMENT '流程定义名称',`process_definition_id` int(11) DEFAULT NULL COMMENT '流程定义ID',`state` tinyint(4) DEFAULT NULL COMMENT '流程实例状态:0提交成功,1运行,2准备暂停,3暂停,4准备停止,5停止,6失败,7成功,8需要容错,9终止,10等待线程,11等待依赖项完成',`recovery` tinyint(4) DEFAULT NULL COMMENT '流程实例故障转移标志:0:正常,1:故障转移实例',`start_time` datetime DEFAULT NULL COMMENT '流程实例开始事件',`end_time` datetime DEFAULT NULL COMMENT '流程实例结束事件',`run_times` int(11) DEFAULT NULL COMMENT '流程实例运行时间',`host` varchar(135) DEFAULT NULL COMMENT '主机',`command_type` tinyint(4) DEFAULT NULL COMMENT '命令类型',`command_param` text COMMENT 'json命令参数',`task_depend_type` tinyint(4) DEFAULT NULL COMMENT '任务取决于类型。0:仅当前节点,1:在节点之前,2:在节点之后',`max_try_times` tinyint(4) DEFAULT '0' COMMENT '最大尝试次数',`failure_strategy` tinyint(4) DEFAULT '0' COMMENT '失败策略。0:节点失败时结束进程,1:节点失败后继续运行其他节点',`warning_type` tinyint(4) DEFAULT '0' COMMENT '警告类型。0:无警告,1:进程成功时警告,2:进程失败时警告,3:成功时警告',`warning_group_id` int(11) DEFAULT NULL COMMENT '告警组ID',`schedule_time` datetime DEFAULT NULL COMMENT '调度事件',`command_start_time` datetime DEFAULT NULL COMMENT '命令开始事件',`global_params` text COMMENT '全局参数',`process_instance_json` longtext COMMENT '流程实例json(复制的过程定义的json)',`flag` tinyint(4) DEFAULT '1' COMMENT '标志',`update_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,`is_sub_process` int(11) DEFAULT '0' COMMENT '标志,进程是否为子进程',`executor_id` int(11) NOT NULL COMMENT '执行者ID',`locations` text COMMENT '节点位置信息',`connects` text COMMENT '节点连接信息',`history_cmd` text COMMENT '流程实例操作的历史命令',`dependence_schedule_times` text COMMENT '取决于火灾时间的安排',`process_instance_priority` int(11) DEFAULT NULL COMMENT '进程实例优先级。0最高,1高,2中等,3低,4最低',`worker_group` varchar(64) DEFAULT NULL COMMENT '工作组id',`timeout` int(11) DEFAULT '0' COMMENT '超时时间',`tenant_id` int(11) NOT NULL DEFAULT '-1' COMMENT '租户id',PRIMARY KEY (`id`),KEY `process_instance_index` (`process_definition_id`,`id`) USING BTREE,KEY `start_time_index` (`start_time`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;表数据案例
mysql> select * from t_ds_process_instance where start_time = '2022-09-02 10:45:03' \G;id: 839795name: 流程实例-0-1662086702806process_definition_id: 20state: 7recovery: 0start_time: 2022-09-02 10:45:03end_time: 2022-09-02 10:45:17run_times: 1host: 10.23.165.209:5678command_type: 6command_param: NULLtask_depend_type: 2max_try_times: 0failure_strategy: 1warning_type: 0warning_group_id: 0schedule_time: 2022-09-02 10:45:00command_start_time: 2022-09-02 10:45:02global_params: NULLprocess_instance_json: {"globalParams":[],"tasks":[{"conditionResult":{"successNode":[""],"failedNode":[""]},"description":"流程实例","runFlag":"NORMAL","type":"SQL","params":{"type":"POSTGRESQL","datasource":1,"sql":"select dws.p_dws_table()","udfs":"","sqlType":"0","sendEmail":false,"displayRows":10,"limit":"1","title":"","receivers":"123456789@qq.com","receiversCc":"","showType":"TABLE","localParams":[],"connParams":"","preStatements":[],"postStatements":[]},"timeout":{"strategy":"FAILED","interval":30,"enable":true},"maxRetryTimes":"0","taskInstancePriority":"MEDIUM","name":"dws.p_dws_table","dependence":{},"retryInterval":"1","preTasks":[],"id":"tasks-80778","workerGroup":"default"}],"tenantId":1,"timeout":0}flag: 1update_time: 2022-09-02 10:45:16is_sub_process: 0executor_id: 5locations: {"tasks-80778":{"name":"dws.p_dws_table","targetarr":"","nodenumber":"0","x":212,"y":98}}connects: []history_cmd: SCHEDULER
dependence_schedule_times: NULL
process_instance_priority: 2worker_group: defaulttimeout: 0tenant_id: 1
🙇♀2.2 任务实例
表结构
CREATE TABLE `t_ds_task_instance` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',`name` varchar(255) DEFAULT NULL COMMENT '任务名称',`task_type` varchar(64) DEFAULT NULL COMMENT '任务类型',`process_definition_id` int(11) DEFAULT NULL COMMENT '流程定义ID',`process_instance_id` int(11) DEFAULT NULL COMMENT '流程实例ID',`task_json` longtext COMMENT '任务内容Json',`state` tinyint(4) DEFAULT NULL COMMENT '状态:0提交成功,1运行,2准备暂停,3暂停,4准备停止,5停止,6失败,7成功,8需要容错,9终止,10等待线程,11等待依赖项完成',`submit_time` datetime DEFAULT NULL COMMENT '任务提交时间',`start_time` datetime DEFAULT NULL COMMENT '任务开始时间',`end_time` datetime DEFAULT NULL COMMENT '任务结束时间',`host` varchar(135) DEFAULT NULL COMMENT '任务运行主机',`execute_path` varchar(200) DEFAULT NULL COMMENT '主机中的任务执行路径',`log_path` varchar(200) DEFAULT NULL COMMENT '任务日志路径',`alert_flag` tinyint(4) DEFAULT NULL COMMENT '告警标志',`retry_times` int(4) DEFAULT '0' COMMENT '任务重试时间',`pid` int(4) DEFAULT NULL COMMENT '任务的PID',`app_link` text COMMENT 'yarn app id',`flag` tinyint(4) DEFAULT '1' COMMENT '0不可用,1可用',`retry_interval` int(4) DEFAULT NULL COMMENT '任务失败时的重试间隔',`max_retry_times` int(2) DEFAULT NULL COMMENT '最大重试时间',`task_instance_priority` int(11) DEFAULT NULL COMMENT '任务实例优先级:0最高,1高,2中等,3低,4最低',`worker_group` varchar(64) DEFAULT NULL COMMENT '工作组id',`executor_id` int(11) DEFAULT NULL,PRIMARY KEY (`id`),KEY `process_instance_id` (`process_instance_id`) USING BTREE,KEY `task_instance_index` (`process_definition_id`,`process_instance_id`) USING BTREE,CONSTRAINT `foreign_key_instance_id` FOREIGN KEY (`process_instance_id`) REFERENCES `t_ds_process_instance` (`id`) ON DELETE CASCADE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
表数据案例
ysql> select * from t_ds_task_instance where submit_time = '2022-09-02 10:34:13' \G;
*************************** 1. row ***************************id: 4089352name: p_dws_wms_table()task_type: SQLprocess_definition_id: 12process_instance_id: 839778task_json: {"conditionResult":"{\"successNode\":[\"\"],\"failedNode\":[\"\"]}","conditionsTask":false,"depList":["dws.p_dws_wms_table"],"dependence":"{}","forbidden":false,"id":"tasks-49159","maxRetryTimes":0,"name":"p_dws_wms_table()","params":"{\"postStatements\":[],\"connParams\":\"\",\"receiversCc\":\"\",\"udfs\":\"\",\"type\":\"POSTGRESQL\",\"title\":\"\",\"sql\":\"select dws.p_dws_wms_table()\",\"preStatements\":[],\"sqlType\":\"0\",\"sendEmail\":false,\"receivers\":\"\",\"datasource\":1,\"displayRows\":10,\"limit\":10000,\"showType\":\"TABLE\",\"localParams\":[]}","preTasks":"[\"dws.p_dws_wms_table\"]","retryInterval":1,"runFlag":"NORMAL","taskInstancePriority":"MEDIUM","taskTimeoutParameter":{"enable":true,"interval":30,"strategy":"FAILED"},"timeout":"{\"enable\":true,\"interval\":30,\"strategy\":\"FAILED\"}","type":"SQL","workerGroup":"default"}state: 7submit_time: 2022-09-02 10:34:13start_time: 2022-09-02 10:34:13end_time: 2022-09-02 10:34:15host: 10.23.165.209:1234execute_path: NULLlog_path: /opt/soft/dolphinscheduler/logs/12/839778/4089352.logalert_flag: 0retry_times: 0pid: 0app_link: NULLflag: 1retry_interval: 1max_retry_times: 0
task_instance_priority: 2worker_group: defaultexecutor_id: 3👊三、查看实例取值逻辑
🙇♀3.1 工作流实例(queryProcessInstanceListPaging)
<select id="queryProcessInstanceListPaging" resultType="org.apache.dolphinscheduler.dao.entity.ProcessInstance">select instance.id, instance.command_type, instance.executor_id, instance.process_definition_version,instance.process_definition_code, instance.name, instance.state, instance.schedule_time, instance.start_time,instance.end_time, instance.run_times, instance.recovery, instance.host, instance.dry_run ,instance.next_process_instance_id,restart_timefrom t_ds_process_instance instancejoin t_ds_process_definition define ON instance.process_definition_code = define.codewhere instance.is_sub_process=0and define.project_code = #{projectCode}<if test="processDefinitionCode != 0">and instance.process_definition_code = #{processDefinitionCode}</if><if test="searchVal != null and searchVal != ''">and instance.name like concat('%', #{searchVal}, '%')</if><if test="startTime != null ">and instance.start_time > #{startTime} and instance.start_time <![CDATA[ <=]]> #{endTime}</if><if test="states != null and states.length > 0">and instance.state in<foreach collection="states" index="index" item="i" open="(" separator="," close=")">#{i}</foreach></if><if test="host != null and host != ''">and instance.host like concat('%', #{host}, '%')</if><if test="executorId != 0">and instance.executor_id = #{executorId}</if>order by instance.start_time desc,instance.end_time desc
</select>
🙇♀3.2 任务实例(queryTaskInstanceListPaging)
<select id="queryTaskInstanceListPaging" resultType="org.apache.dolphinscheduler.dao.entity.TaskInstance">select<include refid="baseSqlV2"><property name="alias" value="instance"/></include>,process.name as process_instance_namefrom t_ds_task_instance instanceleft join t_ds_task_definition_log define on define.code=instance.task_code and define.version=instance.task_definition_versionleft join t_ds_process_instance process on process.id=instance.process_instance_idwhere define.project_code = #{projectCode}<if test="startTime != null">and instance.start_time > #{startTime} and instance.start_time <![CDATA[ <=]]> #{endTime}</if><if test="processInstanceId != 0">and instance.process_instance_id = #{processInstanceId}</if><if test="searchVal != null and searchVal != ''">and instance.name like concat('%', #{searchVal}, '%')</if><if test="taskName != null and taskName != ''">and instance.name=#{taskName}</if><if test="states != null and states.length != 0">and instance.state in<foreach collection="states" index="index" item="i" open="(" separator="," close=")">#{i}</foreach></if><if test="host != null and host != ''">and instance.host like concat('%', #{host}, '%')</if><if test="executorId != 0">and instance.executor_id = #{executorId}</if><if test="processInstanceName != null and processInstanceName != ''">and process.name like concat('%', #{processInstanceName}, '%')</if>order by instance.start_time desc
</select>
👊四、数据备份
暂时打算的是,通过select data into outfile file.txt、load data infile file.txt into table的方式备份表中全部数据,为什么采用这种备份方案呢?因为我这里只想要备份t_ds_process_instance和t_ds_task_instance两张表,表数据量达到百万级别,通过文件导入导出的备份效率比较高,用于备份全量数据。
通过资料查询,针对百万级别的数据,如果采用mysqldump工具导出sql文件的方式,大概需要耗时几分钟,而导出的SQL文件大小也在几个G左右。如果后续需要需要恢复数据,使用source命令恢复一个几个G大小的SQL文件,是相对耗资源和耗时的。而通过select data into outfile file.txt、load data infile file.txt into table的方式,以文件的形式导入导出,可以在几分钟内完成百万级数据的备份和恢复工作。
但是MySQL在实施这种备份方案的时候,需要检查MySQL是否配置了secure_file_priv参数,并开启。如果没有开启,需要修改mysql的参数文件my.cnf,并配置secure_file_priv。
mysql> show global variables like '%secure%';
+--------------------------+-----------------------+
| Variable_name | Value |
+--------------------------+-----------------------+
| require_secure_transport | OFF |
| secure_auth | ON |
| secure_file_priv | /var/data/mysql-files/ |
+--------------------------+-----------------------+
总之,小数据量的备份和恢复,可以使用mysqldump和source命令进行的。数据量大的时候,就可以通过这种方式以文件导出导入的时候进行备份和恢复,效率相对较高。
👊五、表数据拆分
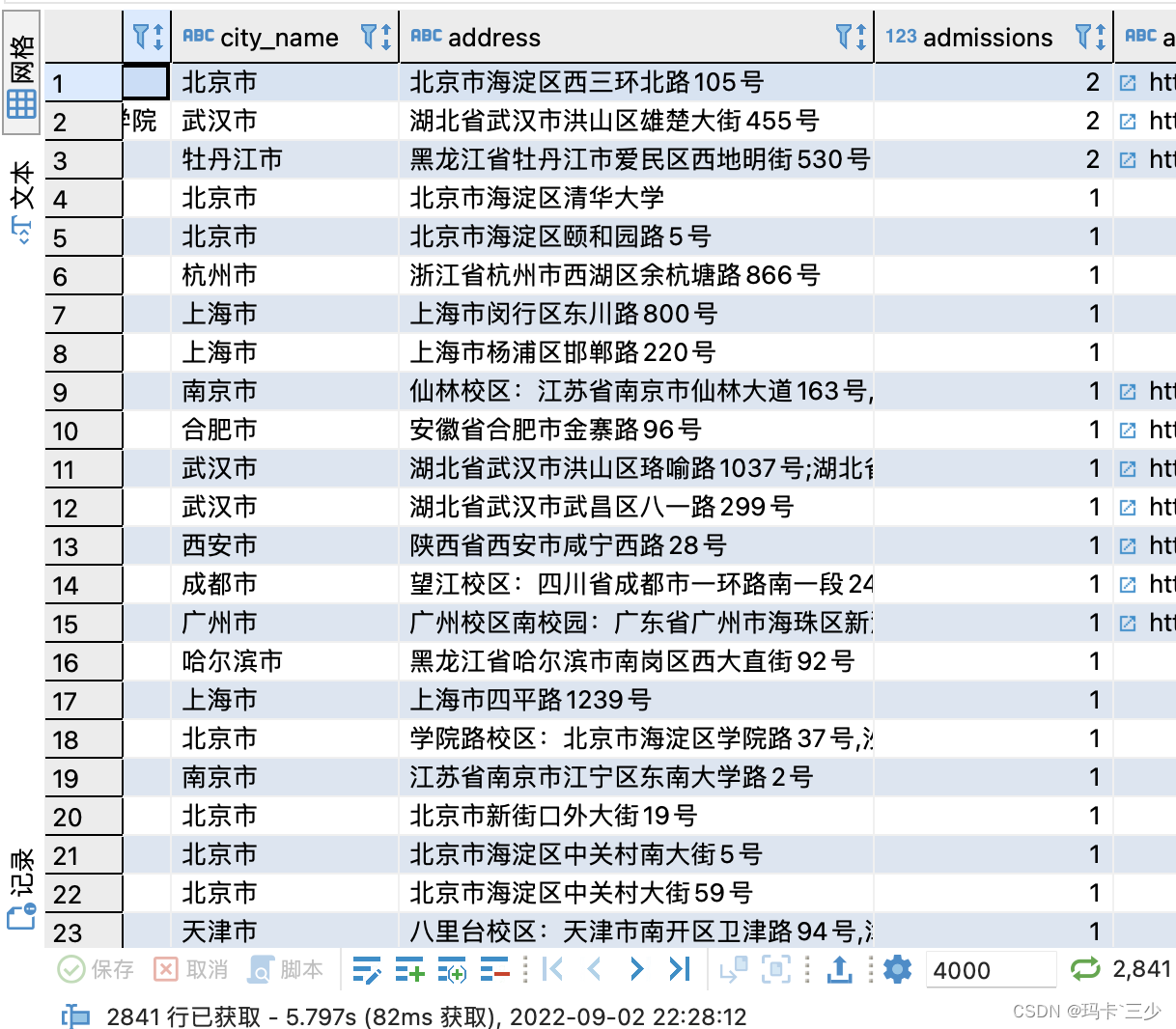
通过create table tablename nologging as select * from table备份部分数据。为什么要将数据拆分呢?因为每次查看任务实例,都会查询t_ds_task_instance表,通过create table方式,既可以方便我们通过SQL查询以往的数据,也减少了查看任务实例的等待时长。
1.create table as select结构比create table再insert into性能好的多,该测试性能差三倍。2.使用nologging,性能提高一半。3.索引对insert的性能影响极大,10倍以上。
默认情况下,建立表、插入数据等动作都会先写到重做日志中,然后建立相关的表并插入数据,也就是说,相当于数据库系统这个动作要操作两遍。降低了数据库建表的速度,当记录越多,速度越慢。而nologging选项就是让数据库在插入大量数据或其他复杂操作的时候记录写操作,而是直接建表或插入数据。





![[JS入门到进阶] 7条关于 async await 的使用口诀,新学 async await?背10遍,以后要考!快收藏](https://img-blog.csdnimg.cn/8c78a1a437134e0b9751eb8bf49045ef.png#pic_center)


