本论文相关内容
- 论文下载地址——26th USENIX Security Symposium
- 论文中文翻译——kAFL Hardware-Assisted Feedback Fuzzing for OS Kernels
文章目录
- 本论文相关内容
- 前言
- kAFL:操作系统内核的硬件辅助反馈Fuzzing
- 作者信息
- 论文来源
- 主办方信息
- 摘要
- 1 引言
- 2 技术背景
- 2.1 x86-64虚拟内存布局
- 2.2 Intel VT-x
- 2.3 Intel处理器跟踪
- 3 系统概述
- 3.1 Fuzzing逻辑
- 3.2 用户模式代理
- 3.3 虚拟基础架构
- 3.4 有状态和非确定性代码
- 3.5 超调用
- 4 实现细节
- 4.1 KVM-PT
- 4.1.1 vCPU特定跟踪
- 4.1.2 持续跟踪
- 4.2 QEMU-PT
- 4.2.1 PT解码器
- 4.3 AFL的Fuzzing逻辑
- 5 评价
- 5.1 Fuzzing Windows
- 5.2 Fuzzing Linux
- 5.3 Fuzzing macOS
- 5.4 已知Bug的重新发现
- 5.5 检测到的漏洞
- 5.6 Fuzzing性能
- 5.7 KVM-PT开销
- 5.8 解码器引擎
- 6 相关工作
- 6.1 黑盒Fuzzer
- 6.2 白盒Fuzzer
- 6.3 灰盒Fuzzer
- 6.4 覆盖引导内核Fuzzer
- 7 讨论
- 8 结论
- 致谢
- 总结
前言
此博客为kAFL Hardware-Assisted Feedback Fuzzing for OS Kernels论文的中文翻译,本篇论文详细讨论了如何利用QEMU和KVM结合硬件对操作系统内核进行模拟反馈的Fuzz。这篇论文我个人觉得非常难,我读了两遍仍不是很懂,看来需要花费更多的时间和精力来阅读本篇论文,这么喜欢本篇论文的原因就是写的真的很好,从另一种角度提供了对操作系统内核Fuzz的方法。目前已经将kAFL(本篇论文介绍的工具)部署到本地了,运行良好,不过kAFL的源代码还没有深入阅读,后面的时间要仔细研读本篇论文以及kAFL的源代码。
kAFL:操作系统内核的硬件辅助反馈Fuzzing
作者信息
论文来源
主办方信息
摘要
几十年来,许多类型的内存安全漏洞一直在危害软件系统。在其他方法中,fuzzing是一种很有前途的技术,可以揭示各种软件故障。最近,反馈引导的fuzzing展示了它的能力,产生了源源不断的安全关键软件漏洞。大多数fuzzing处理,尤其是反馈fuzzing处理,仅限于操作系统(OS)的用户空间组件,尽管内核组件中的错误更严重,因为它们允许攻击者以完全权限访问系统。不幸的是,内核组件很难fuzz,因为反馈机制(即引导代码覆盖)无法轻易应用。此外,由于中断、内核线程、状态性和类似机制造成的不确定性也会带来问题。此外,如果一个进程fuzz了它自己的内核,内核崩溃会严重影响fuzzer的性能,因为操作系统需要重新启动。
在本文中,我们以一种独立于操作系统和硬件辅助的方式来解决覆盖引导的内核fuzzing问题:我们使用了一个系统管理程序和Intel的处理器跟踪(PT)技术。这使我们能够保持独立于目标操作系统,因为我们只需要一个与目标操作系统交互的小用户空间组件。因此,即使在操作系统崩溃的情况下,我们的方法也几乎没有引入性能开销,并且在现成的笔记本电脑上每秒执行17000次。我们开发了一个称为内核-AFL(kAFL)的框架来评估Linux、macOS和Windows内核组件的安全性。在众多崩溃中,我们发现了Linux的ext4驱动程序、macOS的HFS和APFS文件系统以及Windows的NTFS驱动程序中的几个缺陷。
1 引言
一些漏洞类别,如内存损坏、竞争条件内存访问和use-after-free漏洞,是对以用户模式运行的程序以及操作系统(OS)内核本身的已知威胁。过去的经验表明,攻击者通常集中在用户模式应用程序上。这可能是因为众所周知,用户模式程序中的漏洞更容易利用,也更可靠。然而,随着不同类型的漏洞防御机制的出现,尤其是在用户模式下,如今利用已知漏洞变得更加困难。由于用户模式下的高级防御机制,内核对攻击者的吸引力更大,因为大多数内核防御机制在实践中没有得到广泛部署。这是由于更复杂的实现,这可能会影响系统性能。此外,其中一些不是官方主线代码库的一部分,甚至需要支持最新的CPU扩展(例如,x86-64上的SMAP/SMEP)。此外,当危害操作系统时,攻击者通常可以完全访问系统资源(虚拟化系统除外)。内核级漏洞通常用于权限提升或获得基于内核的rootkits的持久性。
长期以来,fuzzing一直是测试和确定软件质量的关键组成部分。然而,随着美国Fuzzy Lop(AFL)的发展,更智能的fuzzer在工业和研究中获得了显著的吸引力。谷歌的OSS Fuzz项目进一步放大了这一趋势,该项目成功地发现并继续发现了高度安全相关软件中的大量关键漏洞。最后,DARPA的Cyber Grand Challenge表明,fuzzing处理仍然与最先进的漏洞发现技术高度相关。最新一代的反馈驱动fuzzer通常使用机制来学习哪些输入感兴趣,哪些不感兴趣。感兴趣的输入用于产生更多的输入,这些输入可以触发目标中的新执行路径。没有在程序中触发有趣行为的输入将被丢弃。因此,fuzzer能够“学习”输入格式。这大大提高了fuzzer的效率和可用性,特别是通过减少对生成半有效输入的谕言机或覆盖目标中大多数路径的广泛语料库的需求。
不幸的是,AFL仅限于用户空间应用程序,并且缺乏内核支持。与userland(或ring 3)fuzzing相比,Fuzzing内核还有一系列额外的挑战:首先,崩溃和超时要求使用虚拟化来捕捉故障并优雅地继续。其次,内核级代码比普通的ring 3程序具有更多的非确定性,这主要是由于中断、内核线程、有状态性和类似的机制。这使得fuzzing内核代码具有挑战性。此外,除了普通的中断或sysenter指令之外,没有等效于命令行参数或stdin的通用方式与内核或驱动程序交互。此外,Windows内核和许多相关的驱动程序和核心组件(适用于Windows、macOS甚至Linux)都是封闭源代码的,如果没有显著的性能开销,就无法通过通用技术进行检测。
以前的内核fuzzing方法是不可移植的,因为它们依赖于某些驱动程序或重新编译,由于模拟来收集反馈而非常缓慢,或者根本不是反馈驱动的。
在本文中,我们介绍了一种新技术,该技术允许将反馈fuzzing应用于任意(甚至是闭源)基于x86-64的内核,而不需要任何自定义的ring 0目标代码,甚至根本不需要特定于操作系统的代码。我们讨论了内核-AFL(kAFL)的设计和实现,这是我们提出的技术的原型实现。由于新的CPU功能,反馈生成的开销非常小(不到5%):Intel的处理器跟踪(PT)技术提供了有关运行代码的控制流信息。我们使用这些信息来构建类似于AFL的instrumentation的反馈机制。这使我们能够在现成的笔记本电脑(Thinkpad T460p、i7-6700HQ和32 GB RAM)上为简单的目标驱动程序每秒获得多达17000次执行。此外,我们还描述了一种有效的方法来处理内核fuzzing过程中出现的非确定性。由于采用了模块化设计,kAFL可扩展到fuzz任何x86/x86-64操作系统。我们已经将kAFL应用于Linux、macOS和Windows,并在这些操作系统的内核驱动程序中发现了多个以前未知的错误。
总之,我们在本文中的贡献是:
操作系统独立性:我们表明,通过利用虚拟机监控程序(VMM)来产生覆盖,闭环内核模式组件的反馈驱动fuzzing化可以以(几乎)与操作系统无关的方式实现。这允许选择任何感兴趣的x86操作系统内核或用户空间组件。
硬件辅助反馈:我们的fuzzing方法利用了Intel的处理器跟踪(PT)技术,因此性能开销非常小。此外,我们的PT解码器比Intel的ptxed解码器快30倍。从而,我们获得了完整的跟踪信息,用于指导我们的进化fuzzing算法,以最大限度地提高测试覆盖率。
可扩展和模块化设计:我们的模块化设计将fuzzer、跟踪引擎和目标分离去fuzz。这允许支持额外的x86操作系统的内核空间和用户空间组件,而无需为目标操作系统开发系统驱动程序。
内核-AFL:我们结合了我们的设计概念,开发了一个称为内核-AFL(kAFL)的原型,它能够在不同操作系统的内核组件中发现几个漏洞。为了促进对这一主题的研究,我们在https://github.com/RUB-SysSec/kAFL上提供了原型实现的源代码。
2 技术背景
我们使用IA-32 CPU的“Intel处理器跟踪”(Intel PT)扩展来获取任意(甚至是闭源)操作系统代码的ring 0执行的覆盖率信息。为了促进高效且独立于操作系统的fuzzing处理,我们还利用了Intel的硬件虚拟化功能(Intel VT-x)。因此,我们的方法需要同时支持Intel VT-x和Intel PT的CPU。本节简要概述了这些硬件功能,并为后面的部分奠定了技术基础。
2.1 x86-64虚拟内存布局
每个常用的x86-64操作系统都使用拆分的虚拟内存布局:内核通常位于每个虚拟内存空间的上半部分,而每个用户模式进程内存位于下半部分。例如,由于当前x86-64 CPU的48位虚拟地址限制,Linux的虚拟内存空间通常分为内核空间(上半部分)和用户空间(下半部分),每个空间的大小为247。因此,内核内存被映射到任何虚拟地址空间,因此它总是位于相同的虚拟地址。如果用户模式进程执行syscall/sysenter指令进行内核交互,或者导致必须由操作系统处理的异常,则操作系统将保持当前的CR3值,因此不会切换虚拟内存地址空间。相反,当前虚拟内存地址空间被重用,内核在同一地址空间内处理当前用户模式进程相关的任务。
2.2 Intel VT-x
本文介绍的内核fuzzing化方法依赖于现代x86-64硬件虚拟化技术。因此,我们简要介绍了Intel的硬件虚拟化技术Intel VT-x。
我们区分了三种CPU:物理CPU、逻辑CPU和虚拟CPU(vCPU)。物理CPU是以硬件实现的CPU。大多数现代CPU都支持提高多线程性能的机制,而无需在芯片上添加额外的物理CPU内核(例如,“Intel超线程”)。在这种情况下,一个物理CPU上有多个逻辑CPU。这些不同的逻辑CPU共享物理CPU,因此一次只能有一个处于活动状态。然而,不同逻辑CPU的执行是由硬件交错的,因此可以更有效地利用可用资源(例如,一个逻辑CPU使用算术逻辑单元,而另一逻辑CPU等待数据提取),并且操作系统可以减少调度开销。操作系统通常将每个逻辑CPU视为一个完整的CPU。最后,可以在单个逻辑CPU上创建多个硬件支持的虚拟机(VM)。在这种情况下,每个虚拟机都有一组自己的vCPU。
虚拟化角色模型分为两个组件:虚拟机监视器(VMM)和VM。VMM,也称为系统管理程序或主机,是一种特权软件,可以完全控制物理CPU,并为虚拟化来宾提供对物理资源的受限访问。VM,也称为来宾,是一种在VMM提供的虚拟化上下文中透明执行的软件。
为了提供完整的硬件辅助虚拟化支持,Intel VT-x在众所周知的基于保护ring的标准执行模式中添加了两种额外的执行模式。默认的执行模式称为VMX OFF。它不实现任何硬件虚拟化支持。当使用硬件支持的虚拟化时,CPU切换到VMX ON状态,并区分两种不同的执行模式:系统管理程序的较高特权模式(VMX root或VMM)和虚拟机来宾的较低特权执行模式(VMX-non-root或VM)。
在来宾模式下运行时,VM中的几个特权操作或原因(执行受限指令,VMX抢占定时器过期或访问某些模拟设备)将触发虚拟机退出事件,并将控制权转移到系统管理程序。通过这种方式,可以运行期望对VM内的硬件(如OS)进行特权访问的任意软件。同时,更高的权力机构可以用较小的性能开销来思考和控制所执行的操作。
为了创建、启动和控制VM,VMM必须为每个vCPU使用虚拟机控制结构(VMCS)。VMCS包含有关当前状态以及如何执行vCPU的VMX转换的所有基本信息。
2.3 Intel处理器跟踪
随着第五代Intel酷睿处理器(Broadwell体系结构)的推出,Intel推出了一项名为“Intel处理器跟踪”(Intel PT)的新处理器功能,以提供执行和分支跟踪信息。与其他分支跟踪技术(如Intel Last branch Record(LBR))不同,输出缓冲区的大小不再受到特殊寄存器的严格限制。相反,它只受到主存储器大小的限制。如果输出目标被重复和及时地清空,我们可以创建任意长度的跟踪。处理器的输出格式是面向包的,并分为两种不同类型:一般执行信息包和控制流信息包。Intel PT在运行时生成各种类型的与控制流相关的数据包类型。为了从跟踪数据中获得控制流信息,我们需要一个解码器。解码器需要被跟踪的软件来解释包含条件分支地址的数据包。
Intel指定了五种影响控制流的指令,称为“流指令更改”(CoFI)。不同CoFI类型的执行导致流信息分组的不同序列。与我们的工作相关的三种CoFI类型是:
- 已执行但未执行(TNT):如果处理器执行任何条件跳转,则是否执行此跳转的决定将编码在TNT数据包中。
- 目标IP(TIP):如果处理器执行间接跳转或传输指令,解码器将无法恢复控制流。因此,处理器在执行间接分支、
near ret或far transfer类型的指令时产生TIP数据包。这些TIP数据包存储在发生传输或跳转之后由处理器执行的相应目标指令指针。 - 流更新包(FUP):处理器必须为软件解码器生成提示包的另一种情况是异步事件,如中断或陷阱。这些事件被记录为FUP,通常后面跟着TIP以指示这些指令。
为了限制生成的跟踪数据量,Intel PT提供了多种运行时筛选选项。根据给定的处理器,可能会为指令指针筛选(IP筛选器)配置多个范围。通常,如果启用了分页,这些筛选器范围只会影响虚拟地址;在x86-64长模式中总是这样。因此,可以将跟踪生成限制在选定的范围内,从而避免大量多余的跟踪数据。根据IP过滤机制,可以通过保护ring模型(例如,ring 0或ring 3)的当前特权级别(CPL)来过滤跟踪。此筛选器允许我们仅选择用户模式(CPL>0)或内核模式(CPL=0)活动。kAFL利用这个过滤器选项将跟踪明确地限制在内核模式执行。在大多数情况下,跟踪的重点不是所有用户模式进程及其内核交互中的整个操作系统。为了将跟踪数据生成限制在一个特定的虚拟内存地址空间内,软件可以使用CR3筛选器。只有当CR3值与配置的筛选器值匹配时,Intel PT才会生成跟踪数据。CR3寄存器包含指向当前页表的指针。因此,即使在ring 0模式下,CR3寄存器的值也可以用于过滤代表某个ring 3进程执行的代码。
Intel PT支持输出数据的各种可配置目标域。kAFL专注于物理地址表(ToPA)机制,该机制使我们能够指定多个输出区域:每个ToPA表都包含多个ToPA条目,这些条目又包含用于存储跟踪数据的相关内存块的物理地址。每个ToPA条目都包含物理地址、物理内存中引用的内存块的大小说明符和多个类型位。这些类型位指定CPU在访问ToPA条目时的行为,以及如何处理填充的输出区域。
3 系统概述
在第4节中介绍我们称为kAFL的工具的实现细节之前,我们现在提供了一个独立于操作系统和硬件辅助的反馈fuzzer设计的高级概述。
我们的系统分为三个组件:fuzzing逻辑、VM基础设施(QEMU和KVM的修改版本,用QEMU-PT和KVM-PT表示)和用户模式代理。fuzzing逻辑在主机操作系统上作为ring 3进程运行。这种逻辑也被称为kAFL。VM基础设施由一个ring 3组件(QEMU-PT)和一个ring 0组件(KVM-PT)组成。这有助于其他两个组件之间的通信,并使Intel PT跟踪数据以用于fuzzing逻辑。通常,来宾仅通过超调用与主机进行通信。然后,主机可以读取和写入来宾内存,并在处理完请求后继续执行VM。该体系结构的概述可以在图1中看到。

我们现在概述了fuzz运行期间发生的事件和通信,如图2所示。当VM启动时,用户模式代理的第一部分(加载程序)使用超调用HC_SUBMIT_PANIC将内核死机处理程序的地址(或Windows中的BugCheck内核地址)提交给QEMU-PT①。然后,QEMU-PT在死机处理程序的地址处修补一个超调用例程。这使我们能够得到通知,并对虚拟机中的崩溃做出快速反应(而不是等待超时/重新启动)。
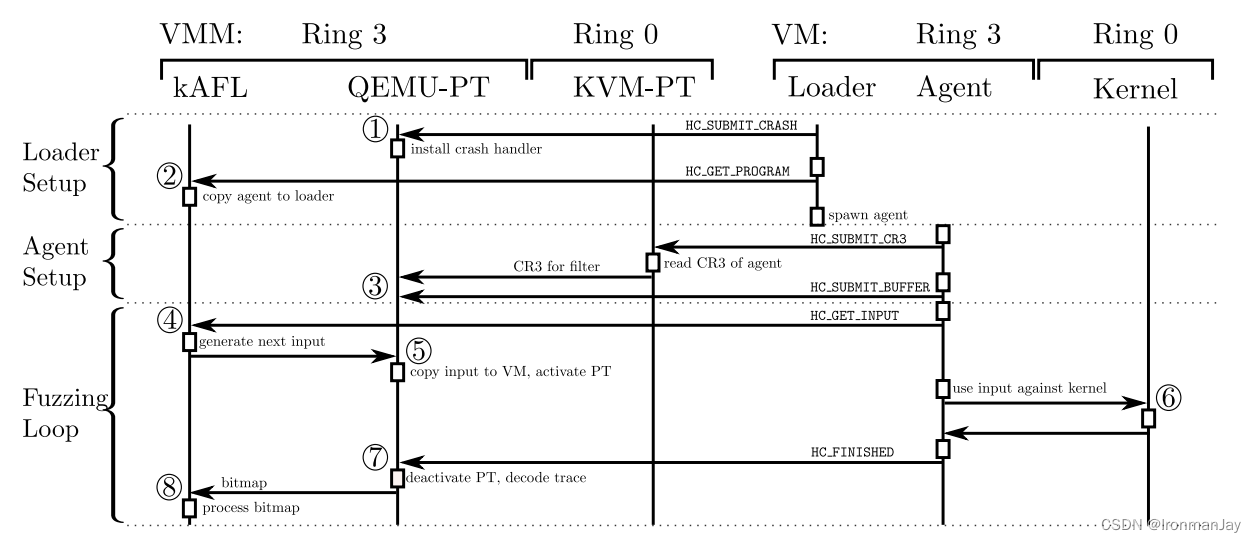
然后,加载程序使用超调用HC_GET_PROGRAM来请求实际的用户模式代理,并启动它②。现在,加载程序设置完成,fuzzer开始初始化。代理触发将由KVM-PT处理的HC_SUBMIT_CR3超调用。系统管理程序提取当前运行的进程的CR3值,并将其交给QEMU-PT进行过滤③。最后,代理使用超调用HC_SUBMIT_BUFFER来通知主机它期望其输入的地址。fuzzer设置现已完成,主fuzzing循环开始。
在主循环期间,代理使用HC_GET_INPUT超调用④请求新的输入。fuzzing逻辑产生一个新的输入,并将其发送到QEMU-PT。由于QEMU-PT可以完全访问客户机的内存空间,因此它可以简单地将输入复制到代理指定的缓冲区中。然后,它执行VM-Entry以继续执行VM⑤。同时,此VM-Entry事件启用PT跟踪机制。代理现在消耗输入并与内核交互(例如,它将输入解释为文件系统映像,并尝试挂载它⑥)。当内核被fuzz时,QEMU-PT对跟踪数据进行解码,并根据需要更新位图。一旦交互完成,内核将控制权交还给代理,代理就会通过HC_FINISHED超调用通知系统管理程序。所得到的VM-Exit停止跟踪,并且QEMU-PT对剩余的跟踪数据⑦进行解码。所得到的位图被传递到用于进一步处理的逻辑⑧。之后,在发出另一个HC_GET_INPUT以开始下一个循环迭代之前,代理可以继续运行任何未跟踪的清理例程。
3.1 Fuzzing逻辑
fuzzing逻辑是kAFL的命令和控制组件。它管理感兴趣的输入队列,创建变异输入,并安排它们进行评估。在大多数方面,它是基于AFL使用的算法。与AFL类似,我们使用位图来存储基本块转换。我们通过QEMU-PT的接口从VM收集AFL位图,并决定哪些输入触发了有趣的行为。fuzzing逻辑还协调并行生成的虚拟机的数量。与AFL更大的设计差异之一是,kAFL广泛使用了多处理和并行性,其中AFL只是产生多个独立的fuzzer,这些fuzzer偶尔同步它们的输入队列。相反,kAFL并行执行确定性阶段,所有线程都处理最有趣的输入。大量时间花在不受CPU限制的任务上(例如延迟执行的来宾)。因此,由于每个内核的CPU负载更高,使用许多并行进程(每个CPU内核最多5-6个)大大提高了fuzzing处理的性能。最后,fuzzing逻辑与用户界面通信,以定期显示当前统计信息。
3.2 用户模式代理
我们期望用户模式代理在虚拟化的目标操作系统中运行。原则上,这个组件只需要通过超调用接口通过fuzzing逻辑同步和收集新的输入,并使用它与客户的内核进行交互。示例代理是试图将输入装载为文件系统映像的程序,将证书等特定文件传递给内核解析器,甚至执行各种系统调用链。
理论上,我们只需要一个这样的组件。在实践中,我们使用两个不同的组件:第一个程序是加载器组件。它的工作是通过超调用接口接受任意二进制文件。此二进制文件表示用户模式代理,并由加载器组件执行。此外,加载器组件将检查代理是否已崩溃(在系统调用fuzzing的情况下经常发生这种情况),并在必要时重新启动它。这种设置的优点是,我们可以将任何二进制文件传递给VM,并为不同的fuzzing组件重用VM快照。
3.3 虚拟基础架构
fuzzing逻辑使用QEMU-PT与KVM-PT交互以生成目标VM。KVM-PT允许我们跟踪单个vCPU,而不是逻辑CPU。在CPU切换到来宾执行之前,此组件在相应的逻辑CPU上配置并启用Intel PT,并在VM退出转换期间禁用跟踪。这样,关联的CPU将只提供虚拟化内核本身的跟踪数据。QEMU-PT用于与KVM-PT接口交互,从用户空间配置和切换Intel PT,并访问输出缓冲区以解码跟踪数据。解码的跟踪数据被直接转换为执行的条件分支指令的地址流。此外,QEMU-PT还基于非确定性基本块的先前知识对执行的地址流进行过滤,以防止假阳性fuzzing结果,并使这些fuzzing结果作为AFL兼容位图可用于fuzzing逻辑。我们使用自己的自定义Intel PT解码器来缓存反汇编结果,与Intel提供的现成解决方案相比,这带来了显著的性能提升。
3.4 有状态和非确定性代码
跟踪操作系统会导致大量的不确定性。不确定性基本块转换的最大来源是中断,中断可以发生在任何时间点。此外,我们的实现不会在每次执行后重置整个状态,因为从内存快照重新加载VM的成本很高。因此,我们必须处理内核的有状态和异步方面。有状态代码的一个例子可能是对kmalloc()的简单调用:根据先前分配的数量,kmalloc()可能只返回一个新指针或映射整个页面范围并更新大量元数据。我们使用两种技术来应对这些挑战。
第一个是过滤掉中断和处理中断时引起的转换。这可以使用Inter PT跟踪数据实现。如果发生中断,处理器会发出TIP指令,因为传输在代码中不可见。为了避免在间接控制流指令中断期间出现混淆,TIP数据包用FUP(流更新数据包)标记,以指示异步事件。在识别出这样的签名之后,解码器将丢弃所访问的所有基本块,直到遇到相应的iret指令。为了将中断与其对应的iret链接起来,我们在一个简单的调用堆栈上跟踪所有中断。这种机制是必要的,因为中断处理程序本身可能会被另一个中断中断。
第二种机制是将非确定性发生的任何基本块列入黑名单。每次我们在AFL位图中遇到新的位时,我们都会连续多次重新运行输入。没有出现在所有试验中的每个基本块都将被标记为不确定性,并从进一步处理中过滤。为了快速访问,结果存储在列入黑名单的基本块地址的位图中。在AFL位图转换期间,任何结合当前基本块地址和涉及黑名单块的先前基本块地址的转换散列值都将被跳过。
3.5 超调用
超调用是虚拟化引入的一项功能。在Intel平台上,超调用是由vmcall指令触发的。超调用是对VM的调用,就像系统调用是对内核的调用一样。如果任何ring 3进程或VM中的内核执行vmcall指令,则会触发VM退出事件,VMM可以决定如何处理超调用。如果在rax中传递了一个神奇的值,并且在rbx中设置了适当的超调用ID,我们修补了KVM-PT,使其通过我们自己的一组超调用传递到fuzzing逻辑。此外,我们还修补了KVM-PT以接受来自ring 3的超调用。特定超调用的参数通过rcx传递。我们使用这个机制来定义用户模式代理可以用来与fuzzing逻辑通信的接口。一个例子是HC_SUBMIT_BUFFER。它的参数是一个存储在rcx中的来宾指针。在执行vmcall指令时,会触发VM退出,QEMU-PT会存储传递的缓冲区指针。稍后它将把新的输入数据复制到这个缓冲区中(参见图2中的步骤⑤)。最后,继续执行虚拟机。

该接口的另一个用例是在目标操作系统内核中发生崩溃时通知fuzzing逻辑。为了做到这一点,我们用一个简单的超调用例程覆盖操作系统的内核崩溃处理程序。注入的代码如清单1所示,它显示了如何在汇编级使用超调用接口。cli指令禁用所有中断,以避免在超调用例程期间出现任何类型的异步干扰。
4 实现细节
基于上一节中概述的设计,我们构建了一个称为kAFL的方法原型。在下文中,我们将描述几个实现细节。我们的参考实现的源代码可在https://github.com/RUB-SysSec/kAFL上找到。
4.1 KVM-PT
Intel PT允许我们跟踪分支转换,而无需修补或重新编译目标内核。据我们所知,没有一个公开可用的驱动程序能够长时间使用Intel PT仅跟踪单个vCPU的来宾执行。例如,Simple PT不支持通过设计进行长期跟踪。perf子系统支持对VM来宾操作的跟踪和长期跟踪。然而,它被设计用于跟踪逻辑CPU,而不是vCPU。即使跟踪了VMX的执行,数据也将与逻辑CPU相关联,而不是与vCPU相关联。因此,必须重新组装VMX上下文,这是一项成本高昂的任务。
为了解决这些缺点,我们开发了KVM-PT。它允许我们在不确定的时间内跟踪vCPU,而不会产生任何调度副作用或由于输出区域溢出而导致跟踪数据丢失。该扩展为KVM vCPU提供了快速可靠的跟踪机制。此外,这个扩展与KVM一样,公开了一个广泛的用户模式接口,用于从用户空间访问这个跟踪功能。QEMU-PT利用这种新颖的接口与KVM-PT进行交互,并访问生成的跟踪数据。
4.1.1 vCPU特定跟踪
要启用Intel PT,在ring 0中运行的软件(在我们的情况下是KVM-PT)必须设置特定型号寄存器(MSR)的相应位(IA32_RTIT_CTL_MSR.TraceEn)。启用跟踪后,如果逻辑CPU满足配置的筛选器选项,它将跟踪任何执行的代码。修改必须在CPU从主机上下文切换到VM操作之前完成;否则CPU将执行来宾代码,并且在技术上不能修改任何主机MSR。在CPU离开来宾上下文之后,需要执行相反的过程。但是,手动启用或禁用“Intel PT”也会生成包含手动MSR修改的跟踪。为了防止在VMM中收集不需要的跟踪数据,我们使用Intel VT-x的MSR自动加载功能。可以通过修改VMCS中的相应条目(例如,VM条目的VM_ENTRY_CONTROL_MSR)来启用MSR自动加载。这将强制CPU在VM进入或VM退出后加载已定义MSR的预配置值列表。通过MSR自动加载启用跟踪,我们只收集一个特定vCPU的Intel PT跟踪数据。
4.1.2 持续跟踪
一旦我们启用了Intel PT,CPU将把生成的跟踪数据写入内存缓冲区,直到它满为止。这个缓冲区的物理地址以及如何处理满缓冲区是由一个称为物理地址表(ToPA)项的数据结构数组指定的。
数组可以包含多个条目,并且必须由单个END条目③终止。CPU可以通过两种不同的方式处理溢出:它可以停止跟踪(同时继续执行,从而导致不完整的跟踪),也可以引发中断。此中断导致VM退出,因为它是不可屏蔽的。我们在主机上捕获中断并消耗跟踪数据。最后,我们重置缓冲区并继续执行VM。不幸的是,这个中断可能是在缓冲区被填满后的一个未指定的时间引发的②。我们对ToPA条目的配置可以在图3中看到。为了避免丢失跟踪数据,我们使用了两个不同的ToPA条目。第一个是主缓冲器①。它的溢出行为是触发中断。一旦主缓冲区被填满,就会使用第二个条目,直到中断被实际传递。ToPA指定了另一个较小的缓冲器②。第二个缓冲区的溢出将导致跟踪的停止。为了避免由此产生的数据丢失,我们选择了第二个缓冲区,该缓冲区大约是我们在测试中看到的最大溢出跟踪(4KB)的四倍。

如果第二个缓冲区也溢出,那么下面的跟踪将包含一个指示某些数据丢失的数据包。在这种情况下,可以简单地增加第二缓冲器的大小。通过这种方式,我们能够获得任何数量的跟踪数据的精确跟踪。
4.2 QEMU-PT
要使用KVM扩展KVM-PT,需要一个用户空间对应项。QEMU-PT是QEMU的扩展,为KVM-PT的用户空间接口提供了全面的支持。此接口提供了在运行时启用、禁用和配置Intel PT的机制,并提供了定期ToPA状态检查以避免溢出。KVM-PT可以通过ioctl()命令和mmap()接口从用户模式访问。
除了作为KVM-PT的用户界面外,QEMU-PT还包括一个将跟踪数据解码为更适合fuzzing逻辑的形式的组件:我们解码Intel PT数据包,并将其转换为类似AFL的位图。
4.2.1 PT解码器
广泛的内核fuzzing处理每秒可能生成数百兆字节的跟踪数据。为了处理如此大量的输入数据,解码器的实现必须注重效率。否则,解码器可能会成为fuzzing处理过程中的主要瓶颈。然而,解码器也必须是精确的,因为解码过程中的不准确将导致进一步的错误。这是由于Intel PT解码的性质,因为解码过程是顺序的,并且会受到先前解码的数据包的影响。
为了简化实现Intel PT软件解码器的工作,Intel提供了自己的解码引擎libipt。libipt是一个通用的Intel PT解码引擎。然而,它不太符合我们的目的,因为libipt解码跟踪数据以提供执行数据和流信息。此外,libipt不缓存反汇编的指令,并且在我们的用例中表现不佳。
由于kAFL仅依赖于流信息,并且fuzzing处理被重复应用于同一代码,因此可以优化解码过程。我们的Intel PT软件解码器就像一个即时解码器,这意味着只有根据解码的跟踪数据执行代码段时,才会考虑代码段。为了优化进一步的查找,所有反汇编的代码部分都被缓存。此外,我们只是忽略与我们的用例无关的数据包。
由于我们的PT解码器是QEMU-PT的一部分,如果填充了ToPA基础区域,则直接处理跟踪数据。由于可以通过mmap()从用户空间直接访问缓冲区,因此解码过程应用到位。与其他Intel PT驱动程序不同,我们不需要在内存或存储设备上存储大量跟踪数据以进行事后解码。最终,解码后的跟踪数据被转换为AFL位图格式。
4.3 AFL的Fuzzing逻辑
我们简要描述了AFL的fuzzing部分,因为我们用于执行调度和突变的逻辑与AFL的逻辑非常相似。AFL最重要的方面是用于跟踪遇到那些基本块转换的位图。每个基本块都有一个随机分配的ID,根据以下公式,从基本块 A A A到另一个基本块 B B B的每个转换都被分配到位图中的偏移:
( i d ( A ) / 2 ⊕ i d ( B ) ) % S I Z E _ 0 F _ B I T M A P (id(A)/2\oplus id(B))\%{SIZE\_0F\_BITMAP} (id(A)/2⊕id(B))%SIZE_0F_BITMAP
kAFL使用的不是编译时随机的,而是基本块的地址。每次观察到转换时,位图中相应的字节都会递增。在完成fuzzing迭代之后,位图的每个条目都被四舍五入,使得只有最高比特保持设置。然后将位图与全局静态位图进行比较,以查看是否找到任何新的位。如果找到了一个新的比特,它将被添加到全局位图中,并且触发该新比特的输入将添加到队列中。当发现一个新的有趣的输入时,会执行一个确定性阶段,试图单独变异每个字节。
一旦确定性阶段结束,就开始非确定性阶段。在这个不确定的阶段,在随机位置进行多个突变。如果确定性阶段发现新的输入,则非确定性阶段将被延迟,直到所有感兴趣的输入的所有确定性阶段都已被执行。如果一个输入触发了一个全新的转换(与转换次数的变化相反),它将被更高的优先级所青睐和fuzz。

5 评价
基于我们的实现,我们现在描述我们为评价kAFL而执行的不同fuzzing活动。我们评估了kAFL在不同平台上的fuzzing性能。第5.5节概述了kAFL开发过程中发现的所有报告的漏洞、崩溃和错误。我们还评价了kAFL发现先前已知漏洞的能力。最后,在第5.6节中,将kAFL的总体fuzzing性能与ProjectTriforce进行了比较,ProjectTriforce是唯一可用的其他独立于操作系统的反馈fuzzer。TriforceAFL基于QEMU的仿真后端,而不是硬件辅助虚拟化和Intel PT。KVM-PT的性能开销在第5.7节中进行了讨论。此外,我们的PT解码器和软件解码器的Intel实现的性能比较在第5.8节中给出。
如果没有另行说明,基准测试是在一个带有Intel i7-6700处理器和32GB DDR4 RAM的桌面系统上执行的。为了避免由于I/O性能差而导致的失真,所有基准测试都在RAM磁盘上执行。与AFL类似,如果崩溃输入触发了至少一个未被任何先前崩溃触发的基本块转换(即,位图包含至少一个新比特),则我们认为它是唯一的。请注意,这并不意味着潜在的bug是真正独特的。
5.1 Fuzzing Windows
我们实现了一个特定于Windows 10的小型用户模式代理,它将任何数据块(fuzz负载)装载为NTFS分区卷(289行C代码)。我们使用虚拟硬盘(VHD)API和各种IOCTLS以编程方式装载和卸载卷。不幸的是,在Windows下装载卷是一项缓慢的操作,我们只能实现每秒20次执行的吞吐量。尽管如此,kAFL还是设法在NTFS驱动程序中发现了故障。fuzzer运行了4天14小时,报告了59起独特的崩溃,所有这些崩溃都被零崩溃所分割。经过人工调查,我们怀疑只有一个独特的bug。虽然它不允许执行代码,但它仍然是一个拒绝服务漏洞,例如,将恶意NTFS卷插入关键系统的U盘将使该系统崩溃并显示蓝屏。我们似乎只是触及了表面,NTFS还没有完全fuzz。因此,我们假设Windows下的NTFS驱动程序是基于覆盖率的反馈fuzzing的一个有价值的目标。
此外,我们实现了一个通用系统调用(syscall)fuzzing代理,它只需通过设置所有寄存器和顶部堆栈区域(55行C和46行汇编代码)将一块数据传递给系统调用。这允许使用独立于操作系统ABI的fuzzing负载为系统调用设置参数。同一个fuzzer可以用于攻击不同操作系统(如Linux或macOS)上的系统调用。然而,考虑到该操作系统的专有性质,我们根据Windows内核对其进行了评估。在13个小时的fuzzing处理中,我们没有发现任何错误,执行了大约630万次,因为许多系统调用会导致用户空间代理终止:由于覆盖率引导的反馈,kAFL很快学会了如何生成有效负载来执行有效的系统调用,这导致了通过fuzzing代理内的内核意外执行用户模式回调。这些崩溃需要相当昂贵的代理重新启动,因此我们每秒只能执行大约134次,而通常kAFL每秒可以完成1000到4000次测试(请参阅第5.2节)。此外,Windows系统调用接口已经受到了安全界的高度关注。
5.2 Fuzzing Linux
我们为Linux实现了一个类似的代理,它将数据装载为ext4卷(66行C代码)。我们以最小64KB的ext4图像作为初始输入,开始了fuzz活动。然而,我们配置了fuzzer,使其在确定性阶段只fuzz前两KB。与Windows相比,Linux的安装过程非常快,我们在具有i7-6700HQ@2.6GHzCPU和32GB RAM配置的Thinkpad笔记本电脑上达到了每秒1000到2000次测试。由于这种高性能,我们获得了明显更好的覆盖率,并在为期12天的fuzzing活动中发现了ext4驱动程序中的160个独特崩溃和多个(已确认的)bug。图5显示了另一次fuzzing运行的前32个小时。fuzzing过程仍在寻找新的路径,并在32小时后定期崩溃。一个有趣的观察结果是,在第16小时到第25小时之间没有产生新的覆盖范围,但由于循环迭代次数增加,输入数量增加了。25小时后,发现了一个真正新的输入,它解锁了代码库的重要部分。

5.3 Fuzzing macOS
与Windows和Linux类似,我们针对macOS的多个文件系统。到目前为止,我们在HFS驱动程序中发现了大约150个崩溃,并手动确认其中至少有三个是导致内核错误的独特错误。这些漏洞可能由没有特权的用户触发,因此很可能被滥用进行本地拒绝服务攻击。其中一个漏洞似乎是一个释放后使用的漏洞,该漏洞导致对rip寄存器的完全控制。此外,kAFL在APFS内核扩展中发现了220个独特的崩溃。所有3个HFS漏洞和多个APFS漏洞都已报告给苹果公司。
5.4 已知Bug的重新发现
我们在keyctl接口上评估了kAFL,它允许用户空间程序在内核中存储和管理各种关键材料。更具体地说,它具有一个DER(请参阅RFC5280)解析器来加载证书。此功能有一个已知的错误(CVE-2016-0758)。我们在一个易受攻击的内核(4.3.2版)上针对相同的接口测试了kAFL。kAFL能够发现相同的问题和一个以前未知的错误,该错误被分配给CVE-2016-8650。kAFL在短短一小时的执行时间内成功触发了17个独特的KASan报告和15个独特的错误。在这个实验中,kAFL产生了超过3400万个输入,发现了295个有趣的输入,每秒执行近9000次。这个实验是在并行运行8个进程的同时进行的。
5.5 检测到的漏洞
在评估过程中,kAFL发现了一千多起独特的崩溃。我们手动评估了一些,在所有测试的操作系统(如Linux、Windows和macOS)中发现了多个安全漏洞。到目前为止,共报告了8个错误,其中3个已由维护人员确认:
- Linux:keyctl空指针取消引用(CVE-2016-8650)
- Linux:ext4内存损坏
- Linux:ext4错误处理
- Windows:NTFS分区为零
- macOS:HFS零分区
- macOS:HFS断言失败
- macOS:HFS释放后使用
- macOS:AFS内存损坏
Red Hat为第一个报告的安全漏洞分配了一个CVE编号,如果出现指数为零的RSA证书,则会触发内核ASN.1解析器中的空指针差异和部分内存损坏。对于第二个报告的漏洞,它触发了ext4文件系统中的内存损坏,提出了一个主线补丁。上一次报告的Linux漏洞调用ext4错误处理例程panic(),从而导致内核死机,在撰写本文时尚未进行进一步调查。Windows 10中的NTFS错误是一种不可恢复的错误情况,会导致蓝屏。此错误已报告给Microsoft,但尚未得到证实。同样,苹果尚未验证或证实我们报告的macOS错误。
5.6 Fuzzing性能
我们比较了kAFL在不同操作系统中的总体性能。为了确保可比较的结果,我们为前面提到的每个操作系统创建了一个简单的驱动程序,其中包含一个基于jsmn的JSON解析器,并使用它来解码用户输入(请参见清单2)。如果用户输入是以“KAFL”开头的JSON字符串,则会触发崩溃。我们跟踪了JSON解析器以及最终检查。通过这种方式,kAFL能够学习正确的JSON语法。我们测量了用于查找崩溃的时间、每秒执行的次数以及在所有三个目标操作系统上发现新路径的速度。

我们对每个操作系统进行了五次重复实验。此外,我们还使用Linux目标驱动程序测试了TriforceAFL。TriforceAFL无法 fuzz Windows和macOS。为了将TriforceAFL与kAFL进行比较,对相关的TriforceLinuxSyscallFuzzer进行了轻微修改,以便与我们易受攻击的Linux内核模块一起工作。不幸的是,由于设置的技术问题,无法将kAFL与Oracle的文件系统fuzzer进行比较。
在每次运行过程中,我们对JSON解析器进行了30分钟的fuzz处理。平均和四舍五入的结果显示在表1中。正如我们所看到的,kAFL在不同系统中的性能非常相似。应该注意的是,这个实验中的方差相当高,这解释了一些令人惊讶的结果。这是由于fuzzing的随机性,因为每个fuzzer都会找到截然不同的路径,其中一些路径可能需要更长的时间来处理,尤其是崩溃的路径和循环。高差异的一个例子是,在Debian 8(initramfs)上,多处理配置平均需要比一个进程更多的时间来发现崩溃。
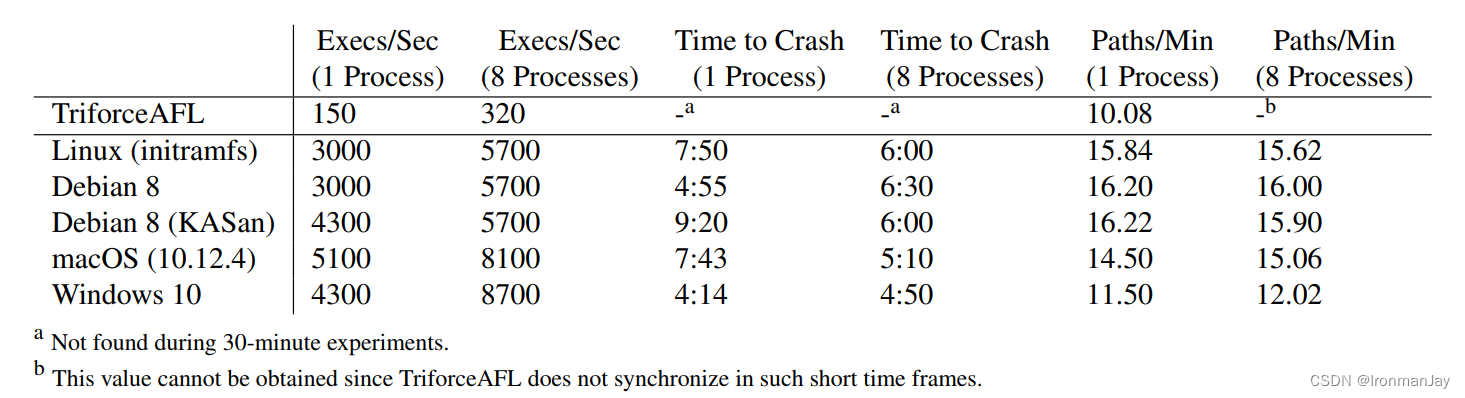
TriforceAFL 我们使用JSON驱动程序来比较kAFL和TriforceAFL的执行速度和代码覆盖率。然而,结果在两个方面存在严重偏差:TriforceAFL未能在30分钟内找到触发崩溃的路径(通常需要大约2小时),因此很难比较kAFL和TriforceAFL的代码覆盖率。发现的路径数量不是覆盖量的良好指标:随着运行时间的增加,发现新路径变得更加困难。其次,每秒执行的次数也受到较慢和较难到达的路径的影响,尤其是崩溃的输入。随着时间的推移所达到的覆盖范围如图6所示。从图中可以明显看出,kAFL发现了大量TriforceAFL很难到达的路径。kAFL大多在10-15分钟左右停止寻找新的路径,因为目标驱动程序根本不包含任何需要挖掘的路径。因此,表1中的覆盖率值(表示为Paths/Min)仅限于每次30分钟运行的前10分钟。
我们还比较了原始执行性能,而不是总体fuzzing性能,因为不同路径的执行、非确定性滤波器的采样过程和各种同步机制,导致fuzzing性能是有偏差的。尤其是在较小的输入上,这些因素会不成比例地影响整体fuzzing性能。为了避免这种情况,我们比较了第一个havoc阶段的表现。图7显示了kAFL在这个havoc阶段与TriforceAFL相比的原始执行性能。与TriforceAFL的QEMU CPU仿真相比,kAFL提供了高达54倍的性能。在单进程执行中可以看到稍低的性能提升(速度快48倍)。

syzkaller 我们没有与syzkaller进行性能比较。这有两个原因:首先,syzkaller是一个高度特定的系统调用fuzzer,它编码大量的域知识,因此不适用于文件系统映像等其他域。另一方面,即使没有任何反馈,syzkaller也很可能生成更高的代码覆盖率,因为它知道如何生成有效的系统调用,因此能够在没有任何学习的情况下触发有效的路径。因此,除非我们实现相同的系统调用逻辑,否则覆盖率比较将极具误导性;这项任务超出了本文的范围。此外,通过kcov收集的覆盖率是高度特定于Linux的,不适用于封闭源目标。
5.7 KVM-PT开销
我们的KVM扩展KVM-PT为KVM的原始执行增加了开销。因此,将性能开销与具有 8GB DDR4 RAM 的 i5-6500@3.2Ghz 台式机系统上的多个 KVM-PT 设置进行了比较。这包括与PT解码器相结合的KVM-PT、不带PT解码器但处理频繁ToPA状态检查的KVM-PT以及不考虑任何ToPA的KVM-PT。对于这个基准测试,通过IP过滤范围配置了13MB的内核代码范围,并使用前面提到的KVM-PT设置之一进行了跟踪。这些基准测试只考虑内核核心,但不考虑任何内核模块。在KVM-PT执行过程中,只跟踪了监控器模式。
为了生成Intel PT负载,QEMU-2.6.0是在跟踪的VM中使用./configure选项--target-list=x86_64-softmmu。我们将跟踪限制在整个内核地址空间。这个基准测试是在单个vCPU上执行的。对由此产生的编译时间进行了测量和比较。下图说明了与没有KVM-PT的KVM执行相比的相对开销(见图8)。我们进行了三个实验来确定不同组件的开销。在每个实验中,我们测量了三种不同的开销:wall-clock时间、用户和内核。总时间的差异用wall-clock的开销来表示。此外,我们还测量了在内核中花费了多少时间,以及只在用户空间中花费了多长时间。由于我们只跟踪内核,我们预计用户空间开销是微不足道的。Intel表示,与未启用Intel PT的执行相比,性能损失<5%。因此,我们预计大约有5%的内核开销。在第一个实验中,在没有进一步分析(KVM-PT)的情况下丢弃了追踪。在第二个实验(KVM-PT和ToPA检查)中,我们启用了ToPA缓冲区的重复检查和清除。在最后的实验(KVM-PT和PT解码器)中,我们测试了整个流水线,包括我们自己的解码器和转换为AFL位图。

在我们的基准测试中,根据经验测量到了1%-4%之间的开销。由于由此产生的开销很小,我们预计它不会对整体fuzzing性能产生重大影响。
5.8 解码器引擎
与KVM-PT相比,解码器对fuzzing处理的整体性能有显著影响,因为解码过程不是Intel PT,因此KVM PT不是硬件加速的。因此,这一过程成本高昂,并且必须尽可能高效。因此,将我们开发的PT解码器的性能与ptxed的性能进行了比较。此解码器是Intel PT软件解码器的示例实现,基于libipt。为了比较两个解码器引擎,通过执行
f i n d / > / d e v / n u l l 2 > / d e v / n u l l find/ \quad > \quad /dev/null\quad2 \quad > \quad /dev/null find/>/dev/null2>/dev/null
在由KVM-PT跟踪的Linux VM(Linux debian 4.8.0-1-amd64)中。此性能基准测试是在具有 8GB DDR4 RAM 的 i5-6500@3.2Ghz 台式机系统上处理的。只跟踪了主管模式下的代码执行情况。生成的样本大小为 9.4MB,包含超过 431,650 个 TNT 数据包,每个数据包最多代表 7 个分支转换。该样品还包含超过 100,045 个 TIP。我们通过删除除流信息包以外的任何内容来净化样本(参见第 2.3 节),以避免解码大量执行信息包的任何影响,因为我们的 PT 解码器不考虑这些数据包。结果是一个5.3MB的跟踪文件。为了测试PT解码器的缓存方法的有效性,我们创建了包含1、5、10、50和250个跟踪副本的案例。这是一个现实的测试用例,因为在fuzzing处理过程中,我们反复看到相同(或非常相似)的路径。图9显示了与ptxed相比,我们的PT解码器的加速速度。

该图还显示,即使PT解码器是第一次处理数据,我们的PT解码器也很容易优于Intel解码器实现。这很可能是因为即使是单个跟踪也已经包含了大量的循环。另一个可能的因素是使用Capstone作为指令解码后端。随着我们解码同一追踪的越来越多的副本,可以看出我们的解码器变得越来越快(仅使用56倍的时间来解码250倍的数据量)。缓存方法的性能优于Intel的实现,速度高达25到30倍。
6 相关工作
Fuzzer通常根据与目标程序的交互量进行分类。对于黑盒fuzzer,fuzzer根本不使用任何关于目标程序的信息。白盒fuzzer通常使用高级程序分析技术来揭示目标的有趣特性。中间的某个地方是所谓的灰盒fuzzer,它通常使用目标的某种反馈(例如覆盖信息)来指导搜索,而不分析目标程序本身的逻辑。在本节中,我们简要概述了在fuzzing的相应领域中所做的工作。
6.1 黑盒Fuzzer
最古老的一类fuzzer是黑盒fuzzer。除了在新生成的输入上执行目标程序之外,这些fuzzer通常与目标程序没有交互。为了提高有效性,通常会做出一些假设:要么大量良好覆盖的输入被反复变异和重组。此类的例子有Radamsa或zzuf。或者,程序员需要指定如何生成看起来几乎像真实文件的新的半有效输入文件。示例包括Peach或Sulley等工具。这两种方法都有一个非常重要的缺点:使用这些工具是一项耗时的任务。
为了提高黑盒fuzzer的性能,已经提出了许多技术。Holler等人介绍了从旧的崩溃输入中学习输入语法中有趣的部分。其他人甚至试图从程序跟踪中推断出整个输入语法。Rebert等人对更有趣的输入进行了优化。类似的方法已被用于优化突变率。
6.2 白盒Fuzzer
为了减轻测试人员的负担,引入了应用程序分析中的见解来寻找更有趣的输入的技术。SAGE、DART、KLEE、SmartFuzz或Mayhem等工具试图通过使用符号执行和约束求解等技术来枚举复杂路径。TaintScope、BuzzFuzz和Vuzzer等工具利用污点跟踪和类似的动态分析技术来发现新的路径。这些工具通常能够找到隐藏在校验和、魔术常数和其他不太可能被随机输入满足的约束后面的非常复杂的代码路径。另一种方法是使用相同类型的信息将搜索偏向于危险行为,而不是新的代码路径。
缺点是,这些技术通常很难实现、扩展到大型程序和并行化。据我们所知,目前还没有这样的操作系统fuzzing工具。
6.3 灰盒Fuzzer
灰盒fuzzer试图保持黑盒fuzzer的高吞吐量和简单性,同时获得白盒fuzzing中高级机制提供的一些额外覆盖。灰盒fuzzing的主要例子是AFL,它使用覆盖信息来指导搜索。这样,AFL就避免了在不会触发新行为的输入上花费额外的时间。许多其他fuzzer也使用类似的技术。
为了进一步提高灰盒fuzzing的有效性,可以应用黑盒fuzzing中已经使用的许多技巧。Böhme等人展示了如何利用将灰盒fuzzing建模为马尔可夫链上的行走所获得的洞察力,将灰盒的fuzzing性能提高一个数量级。
6.4 覆盖引导内核Fuzzer
Vyukov发布了一个名为syzkaler的项目;它是第一个公开可用的灰盒覆盖引导的内核fuzzer。Nossum和Casanovas证明,大多数Linux文件系统驱动程序都容易受到反馈驱动的fuzzing处理的影响,因为它们使用了AFL的适配版本。这个修改后的AFL版本是基于将代码粘合到内核的,该内核由一个驱动程序接口组成,用于在fuzzing内核的文件系统驱动程序期间测量反馈,并将这些数据暴露给用户空间。这个fuzzer在目标操作系统内部运行;崩溃会终止fuzzing会话。
2016年,赫兹和纽瑟姆发布了一个名为TriforceAFL的AFL修改版本。他们的工作基于对QEMU的修改,并利用相应的仿真后端,通过在执行控制流更改指令后确定当前指令指针来测量fuzzing进度。理论上,他们的fuzzer能够fuzz QEMU中模拟的任何操作系统。在实践中,TriforceAFL fuzzer仅限于能够从只读文件系统启动的操作系统,这将候选操作系统缩小到经典的类UNIX操作系统,如Linux、FreeBSD、NetBSD或OpenBSD。因此,TriforceAFL目前无法fuzz macOS或Windows等闭源操作系统。
7 讨论
尽管我们的方法是通用的、快速的,而且基本上独立于底层操作系统,但我们想在本节中讨论一些局限性。
操作系统特定代码。我们使用少量(通常不到150行)依赖于操作系统的ring 3代码来执行三项任务。首先,它与操作系统交互,将fuzzing引擎的输入转换为与操作系统的交互(例如,将数据作为分区挂载)。其次,它获取操作系统崩溃处理程序的地址,这样我们可以比等待超时更快地检测到崩溃。第三,它可以返回某些驱动程序的地址。这些地址可以用于限制对所述驱动程序的活动的跟踪,这在仅fuzzing单个驱动程序时提高了性能。
这些功能都不是必需的,只能在某些情况下提高性能。第一个用例可以通过使用通用的系统调用fuzzing来避免。在这种情况下,一个不使用任何特定于平台的API的标准C程序就足以触发sycenter/syscall指令。我们并不严格需要崩溃处理程序的地址,因为有许多其他方法可以检测VM是否崩溃。通过引入故障并分析获得的跟踪,动态地获得崩溃处理程序也非常容易。最后,我们总是可以跟踪整个内核,从而略微降低性能(主要是由于不确定性的增加)。在像syscall fuzzing这样的情况下,我们需要跟踪整个内核,因此如果缺少此功能,syscall fuzzing将不会受到影响。总之,这是第一种可以fuzz任意x86-64内核而无需任何定制和接近本地性能的方法。
支持的CPU。由于使用Intel PT和Intel VT-x,我们的方法仅限于某些支持这些扩展的Intel CPU。几乎所有现代的Intel CPU都支持Intel VT-x。不幸的是,对于哪些CPU确切支持虚拟机内部的进程跟踪和各种其他扩展(如IP过滤和多条目ToPA),Intel相当不明确。我们在以下CPU型号上测试了我们的系统:Intel Core i5-6500、Intel Core i7-6700HQ和Intel Core i5-6600。我们相信,在撰写本文时,大多数Skylake和Kabylake CPU都有必要的硬件支持。
实时代码。Intel PT不提供已执行指令指针的完整列表。相反,Intel PT生成的信息尽可能少,以减少处理器产生的数据量。因此,Intel PT软件解码器不仅需要控制流信息来重建控制流,而且还需要在跟踪期间执行的程序。如果程序在运行时被修改,就像用户和内核模式下的实时(JIT)编译器经常做的那样,解码器无法准确恢复运行时控制流。为了绕过这一限制,解码器需要关于应用于程序的所有修改的信息,而不是普通的存储器转储或可执行文件。正如Deng等人所示,在执行书面页面时,通过使用EPT违规行为,这是可能的。另一种更为老式的方法是使用影子页表。一旦可以挂接修改后的代码的执行,就可以转储自修改代码。重新实现这项技术超出了这项工作的范围。但需要注意的是,fuzzing内核JIT代码是一个非常有趣的话题,因为内核JIT组件,如Linux中的BPF JIT,经常是严重漏洞的一部分。
多字节比较。与AFL类似,我们无法有效地绕过对输入中的大魔术值的检查。然而,如果提前知道这些神奇的值(例如,来自RFC、源代码或反汇编),我们支持指定有趣常数的字典来提高性能。已经提出了一些涉及一致执行(例如Driller)或污点跟踪(例如Vuzzer)等技术的解决方案。然而,这些技术中没有一种能够容易地适用于闭源操作系统内核。因此,如何在内核级别处理这些情况仍然是一个悬而未决的研究问题。
Ring 3 Fuzzing。我们只是针对内核级别的代码演示了这项技术。然而,完全相同的技术也可以用于fuzz闭源ring 3代码。由于我们的方法具有非常适度的跟踪开销,因此我们预计该技术将优于当前基于动态二进制检测的技术,用于闭源ring 3程序(如winAFL)的反馈fuzzing测试。
8 结论
最新一代的反馈驱动的fuzzing方法已被证明是一种以自动化和全面的方式发现漏洞的有效方法。最近的工作也证明了这种技术可以应用于内核空间。虽然以前的反馈驱动内核fuzzer能够在某些操作系统中发现大量的安全缺陷,但它们的优势要么受到CPU仿真导致的性能差的限制,要么由于需要编译时检测而缺乏可移植性。
在本文中,我们提出了一种新的机制,将最新的CPU特性用于反馈驱动的内核fuzzer。如评估所示,将所有组件组合在一起,可以将内核fuzz测试应用于任何目标操作系统,其性能明显优于其他方法。
致谢
这项工作得到了德国联邦教育和研究部的支持(BMBF拨款16KIS0592K HWSec)。我们要感谢我们的领导Suman Jana对本文定稿的支持,感谢匿名评审员的建设性和宝贵意见。此外,我们还要感谢OpenSource Security的Ralf Spenneberg和Hendrik Schwartke对这项研究的支持。最后,我们要感谢Ali Abbasi、Tim Blazytko、Teemu Rytilahti和Christine Utz提供的宝贵反馈。
总结
以上就是本篇论文翻译的全部内容了,读完这篇论文后,相信各位读者朋友也会认为本篇论文写的相当不错,感兴趣的读者也可以在自己的本地进行kAFL的部署。后面如果有时间,我会分享阅读本篇论文的心得体会!