实现字符串的repeat方法
输入字符串s,以及其重复的次数,输出重复的结果,例如输入abc,2,输出abcabc。
function repeat(s, n) {return (new Array(n + 1)).join(s);
}递归:
function repeat(s, n) {return (n > 0) ? s.concat(repeat(s, --n)) : "";
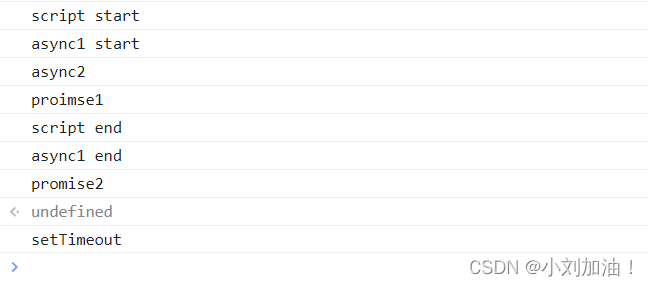
}实现async/await
分析
// generator生成器 生成迭代器iterator// 默认这样写的类数组是不能被迭代的,缺少迭代方法
let likeArray = {'0': 1, '1': 2, '2': 3, '3': 4, length: 4}// // 使用迭代器使得可以展开数组
// // Symbol有很多元编程方法,可以改js本身功能
// likeArray[Symbol.iterator] = function () {
// // 迭代器是一个对象 对象中有next方法 每次调用next 都需要返回一个对象 {value,done}
// let index = 0
// return {
// next: ()=>{
// // 会自动调用这个方法
// console.log('index',index)
// return {
// // this 指向likeArray
// value: this[index],
// done: index++ === this.length
// }
// }
// }
// }
// let arr = [...likeArray]// console.log('arr', arr)// 使用生成器返回迭代器
// likeArray[Symbol.iterator] = function *() {
// let index = 0
// while (index != this.length) {
// yield this[index++]
// }
// }
// let arr = [...likeArray]// console.log('arr', arr)// 生成器 碰到yield就会暂停
// function *read(params) {
// yield 1;
// yield 2;
// }
// 生成器返回的是迭代器
// let it = read()
// console.log(it.next())
// console.log(it.next())
// console.log(it.next())// 通过generator来优化promise(promise的缺点是不停的链式调用)
const fs = require('fs')
const path = require('path')
// const co = require('co') // 帮我们执行generatorconst promisify = fn=>{return (...args)=>{return new Promise((resolve,reject)=>{fn(...args, (err,data)=>{if(err) {reject(err)} resolve(data)})})}
}// promise化
let asyncReadFile = promisify(fs.readFile)function * read() {let content1 = yield asyncReadFile(path.join(__dirname,'./data/name.txt'),'utf8')let content2 = yield asyncReadFile(path.join(__dirname,'./data/' + content1),'utf8')return content2
}// 这样写太繁琐 需要借助co来实现
// let re = read()
// let {value,done} = re.next()
// value.then(data=>{
// // 除了第一次传参没有意义外 剩下的传参都赋予了上一次的返回值
// let {value,done} = re.next(data)
// value.then(d=>{
// let {value,done} = re.next(d)
// console.log(value,done)
// })
// }).catch(err=>{
// re.throw(err) // 手动抛出错误 可以被try catch捕获
// })// 实现co原理
function co(it) {// it 迭代器return new Promise((resolve,reject)=>{// 异步迭代 需要根据函数来实现function next(data) {// 递归得有中止条件let {value,done} = it.next(data)if(done) {resolve(value) // 直接让promise变成成功 用当前返回的结果} else {// Promise.resolve(value).then(data=>{// next(data)// }).catch(err=>{// reject(err)// })// 简写Promise.resolve(value).then(next,reject)}}// 首次调用next()})
}co(read()).then(d=>{console.log(d)
}).catch(err=>{console.log(err,'--')
})
整体看一下结构
function asyncToGenerator(generatorFunc) {return function() {const gen = generatorFunc.apply(this, arguments)return new Promise((resolve, reject) => {function step(key, arg) {let generatorResulttry {generatorResult = gen[key](arg)} catch (error) {return reject(error)}const { value, done } = generatorResultif (done) {return resolve(value)} else {return Promise.resolve(value).then(val => step('next', val), err => step('throw', err))}}step("next")})}
}
分析
function asyncToGenerator(generatorFunc) {// 返回的是一个新的函数return function() {// 先调用generator函数 生成迭代器// 对应 var gen = testG()const gen = generatorFunc.apply(this, arguments)// 返回一个promise 因为外部是用.then的方式 或者await的方式去使用这个函数的返回值的// var test = asyncToGenerator(testG)// test().then(res => console.log(res))return new Promise((resolve, reject) => {// 内部定义一个step函数 用来一步一步的跨过yield的阻碍// key有next和throw两种取值,分别对应了gen的next和throw方法// arg参数则是用来把promise resolve出来的值交给下一个yieldfunction step(key, arg) {let generatorResult// 这个方法需要包裹在try catch中// 如果报错了 就把promise给reject掉 外部通过.catch可以获取到错误try {generatorResult = gen[key](arg)} catch (error) {return reject(error)}// gen.next() 得到的结果是一个 { value, done } 的结构const { value, done } = generatorResultif (done) {// 如果已经完成了 就直接resolve这个promise// 这个done是在最后一次调用next后才会为true// 以本文的例子来说 此时的结果是 { done: true, value: 'success' }// 这个value也就是generator函数最后的返回值return resolve(value)} else {// 除了最后结束的时候外,每次调用gen.next()// 其实是返回 { value: Promise, done: false } 的结构,// 这里要注意的是Promise.resolve可以接受一个promise为参数// 并且这个promise参数被resolve的时候,这个then才会被调用return Promise.resolve(// 这个value对应的是yield后面的promisevalue).then(// value这个promise被resove的时候,就会执行next// 并且只要done不是true的时候 就会递归的往下解开promise// 对应gen.next().value.then(value => {// gen.next(value).value.then(value2 => {// gen.next() //// // 此时done为true了 整个promise被resolve了 // // 最外部的test().then(res => console.log(res))的then就开始执行了// })// })function onResolve(val) {step("next", val)},// 如果promise被reject了 就再次进入step函数// 不同的是,这次的try catch中调用的是gen.throw(err)// 那么自然就被catch到 然后把promise给reject掉啦function onReject(err) {step("throw", err)},)}}step("next")})}
}
解析 URL Params 为对象
let url = 'http://www.domain.com/?user=anonymous&id=123&id=456&city=%E5%8C%97%E4%BA%AC&enabled';
parseParam(url)
/* 结果
{ user: 'anonymous',id: [ 123, 456 ], // 重复出现的 key 要组装成数组,能被转成数字的就转成数字类型city: '北京', // 中文需解码enabled: true, // 未指定值得 key 约定为 true
}
*/
function parseParam(url) {const paramsStr = /.+\?(.+)$/.exec(url)[1]; // 将 ? 后面的字符串取出来const paramsArr = paramsStr.split('&'); // 将字符串以 & 分割后存到数组中let paramsObj = {};// 将 params 存到对象中paramsArr.forEach(param => {if (/=/.test(param)) { // 处理有 value 的参数let [key, val] = param.split('='); // 分割 key 和 valueval = decodeURIComponent(val); // 解码val = /^\d+$/.test(val) ? parseFloat(val) : val; // 判断是否转为数字if (paramsObj.hasOwnProperty(key)) { // 如果对象有 key,则添加一个值paramsObj[key] = [].concat(paramsObj[key], val);} else { // 如果对象没有这个 key,创建 key 并设置值paramsObj[key] = val;}} else { // 处理没有 value 的参数paramsObj[param] = true;}})return paramsObj;
}
实现redux中间件
简单实现
function createStore(reducer) {let currentStatelet listeners = []function getState() {return currentState}function dispatch(action) {currentState = reducer(currentState, action)listeners.map(listener => {listener()})return action}function subscribe(cb) {listeners.push(cb)return () => {}}dispatch({type: 'ZZZZZZZZZZ'})return {getState,dispatch,subscribe}
}// 应用实例如下:
function reducer(state = 0, action) {switch (action.type) {case 'ADD':return state + 1case 'MINUS':return state - 1default:return state}
}const store = createStore(reducer)console.log(store);
store.subscribe(() => {console.log('change');
})
console.log(store.getState());
console.log(store.dispatch({type: 'ADD'}));
console.log(store.getState());
2. 迷你版
export const createStore = (reducer,enhancer)=>{if(enhancer) {return enhancer(createStore)(reducer)}let currentState = {}let currentListeners = []const getState = ()=>currentStateconst subscribe = (listener)=>{currentListeners.push(listener)}const dispatch = action=>{currentState = reducer(currentState, action)currentListeners.forEach(v=>v())return action}dispatch({type:'@@INIT'})return {getState,subscribe,dispatch}
}//中间件实现
export applyMiddleWare(...middlewares){return createStore=>...args=>{const store = createStore(...args)let dispatch = store.dispatchconst midApi = {getState:store.getState,dispatch:...args=>dispatch(...args)}const middlewaresChain = middlewares.map(middleware=>middleware(midApi))dispatch = compose(...middlewaresChain)(store.dispatch)return {...store,dispatch}}// fn1(fn2(fn3())) 把函数嵌套依次调用
export function compose(...funcs){if(funcs.length===0){return arg=>arg}if(funs.length===1){return funs[0]}return funcs.reduce((ret,item)=>(...args)=>ret(item(...args)))
}//bindActionCreator实现function bindActionCreator(creator,dispatch){return ...args=>dispatch(creator(...args))
}
function bindActionCreators(creators,didpatch){//let bound = {}//Object.keys(creators).forEach(v=>{// let creator = creator[v]// bound[v] = bindActionCreator(creator,dispatch)//})//return boundreturn Object.keys(creators).reduce((ret,item)=>{ret[item] = bindActionCreator(creators[item],dispatch)return ret},{})
}
实现find方法
find接收一个方法作为参数,方法内部返回一个条件find会遍历所有的元素,执行你给定的带有条件返回值的函数- 符合该条件的元素会作为
find方法的返回值 - 如果遍历结束还没有符合该条件的元素,则返回
undefined
var users = [{id: 1, name: '张三'},{id: 2, name: '张三'},{id: 3, name: '张三'},{id: 4, name: '张三'}
]Array.prototype.myFind = function (callback) {// var callback = function (item, index) { return item.id === 4 }for (var i = 0; i < this.length; i++) {if (callback(this[i], i)) {return this[i]}}
}var ret = users.myFind(function (item, index) {return item.id === 2
})console.log(ret)
原生实现
function ajax() {let xhr = new XMLHttpRequest() //实例化,以调用方法xhr.open('get', 'https://www.google.com') //参数2,url。参数三:异步xhr.onreadystatechange = () => { //每当 readyState 属性改变时,就会调用该函数。if (xhr.readyState === 4) { //XMLHttpRequest 代理当前所处状态。if (xhr.status >= 200 && xhr.status < 300) { //200-300请求成功let string = request.responseText//JSON.parse() 方法用来解析JSON字符串,构造由字符串描述的JavaScript值或对象let object = JSON.parse(string)}}}request.send() //用于实际发出 HTTP 请求。不带参数为GET请求
}
实现Node的require方法
require 基本原理

require 查找路径

require和module.exports干的事情并不复杂,我们先假设有一个全局对象{},初始情况下是空的,当你require某个文件时,就将这个文件拿出来执行,如果这个文件里面存在module.exports,当运行到这行代码时将module.exports的值加入这个对象,键为对应的文件名,最终这个对象就长这样:
{"a.js": "hello world","b.js": function add(){},"c.js": 2,"d.js": { num: 2 }
}
当你再次
require某个文件时,如果这个对象里面有对应的值,就直接返回给你,如果没有就重复前面的步骤,执行目标文件,然后将它的module.exports加入这个全局对象,并返回给调用者。这个全局对象其实就是我们经常听说的缓存。所以require和module.exports并没有什么黑魔法,就只是运行并获取目标文件的值,然后加入缓存,用的时候拿出来用就行
手写实现一个require
const path = require('path'); // 路径操作
const fs = require('fs'); // 文件读取
const vm = require('vm'); // 文件执行// node模块化的实现
// node中是自带模块化机制的,每个文件就是一个单独的模块,并且它遵循的是CommonJS规范,也就是使用require的方式导入模块,通过module.export的方式导出模块。
// node模块的运行机制也很简单,其实就是在每一个模块外层包裹了一层函数,有了函数的包裹就可以实现代码间的作用域隔离// require加载模块
// require依赖node中的fs模块来加载模块文件,fs.readFile读取到的是一个字符串。
// 在javascrpt中我们可以通过eval或者new Function的方式来将一个字符串转换成js代码来运行。// eval
// const name = 'poetry';
// const str = 'const a = 123; console.log(name)';
// eval(str); // poetry;// new Function
// new Function接收的是一个要执行的字符串,返回的是一个新的函数,调用这个新的函数字符串就会执行了。如果这个函数需要传递参数,可以在new Function的时候依次传入参数,最后传入的是要执行的字符串。比如这里传入参数b,要执行的字符串str
// const b = 3;
// const str = 'let a = 1; return a + b';
// const fun = new Function('b', str);
// console.log(fun(b, str)); // 4
// 可以看到eval和Function实例化都可以用来执行javascript字符串,似乎他们都可以来实现require模块加载。不过在node中并没有选用他们来实现模块化,原因也很简单因为他们都有一个致命的问题,就是都容易被不属于他们的变量所影响。
// 如下str字符串中并没有定义a,但是确可以使用上面定义的a变量,这显然是不对的,在模块化机制中,str字符串应该具有自身独立的运行空间,自身不存在的变量是不可以直接使用的
// const a = 1;
// const str = 'console.log(a)';
// eval(str);
// const func = new Function(str);
// func();// node存在一个vm虚拟环境的概念,用来运行额外的js文件,他可以保证javascript执行的独立性,不会被外部所影响
// vm 内置模块
// 虽然我们在外部定义了hello,但是str是一个独立的模块,并不在村hello变量,所以会直接报错。
// 引入vm模块, 不需要安装,node 自建模块
// const vm = require('vm');
// const hello = 'poetry';
// const str = 'console.log(hello)';
// wm.runInThisContext(str); // 报错
// 所以node执行javascript模块时可以采用vm来实现。就可以保证模块的独立性了// 分析实现步骤
// 1.导入相关模块,创建一个Require方法。
// 2.抽离通过Module._load方法,用于加载模块。
// 3.Module.resolveFilename 根据相对路径,转换成绝对路径。
// 4.缓存模块 Module._cache,同一个模块不要重复加载,提升性能。
// 5.创建模块 id: 保存的内容是 exports = {}相当于this。
// 6.利用tryModuleLoad(module, filename) 尝试加载模块。
// 7.Module._extensions使用读取文件。
// 8.Module.wrap: 把读取到的js包裹一个函数。
// 9.将拿到的字符串使用runInThisContext运行字符串。
// 10.让字符串执行并将this改编成exports// 定义导入类,参数为模块路径
function Require(modulePath) {// 获取当前要加载的绝对路径let absPathname = path.resolve(__dirname, modulePath);// 自动给模块添加后缀名,实现省略后缀名加载模块,其实也就是如果文件没有后缀名的时候遍历一下所有的后缀名看一下文件是否存在// 获取所有后缀名const extNames = Object.keys(Module._extensions);let index = 0;// 存储原始文件路径const oldPath = absPathname;function findExt(absPathname) {if (index === extNames.length) {throw new Error('文件不存在');}try {fs.accessSync(absPathname);return absPathname;} catch(e) {const ext = extNames[index++];findExt(oldPath + ext);}}// 递归追加后缀名,判断文件是否存在absPathname = findExt(absPathname);// 从缓存中读取,如果存在,直接返回结果if (Module._cache[absPathname]) {return Module._cache[absPathname].exports;}// 创建模块,新建Module实例const module = new Module(absPathname);// 添加缓存Module._cache[absPathname] = module;// 加载当前模块tryModuleLoad(module);// 返回exports对象return module.exports;
}// Module的实现很简单,就是给模块创建一个exports对象,tryModuleLoad执行的时候将内容加入到exports中,id就是模块的绝对路径
// 定义模块, 添加文件id标识和exports属性
function Module(id) {this.id = id;// 读取到的文件内容会放在exports中this.exports = {};
}Module._cache = {};// 我们给Module挂载静态属性wrapper,里面定义一下这个函数的字符串,wrapper是一个数组,数组的第一个元素就是函数的参数部分,其中有exports,module. Require,__dirname, __filename, 都是我们模块中常用的全局变量。注意这里传入的Require参数是我们自己定义的Require
// 第二个参数就是函数的结束部分。两部分都是字符串,使用的时候我们将他们包裹在模块的字符串外部就可以了
Module.wrapper = ["(function(exports, module, Require, __dirname, __filename) {","})"
]// _extensions用于针对不同的模块扩展名使用不同的加载方式,比如JSON和javascript加载方式肯定是不同的。JSON使用JSON.parse来运行。
// javascript使用vm.runInThisContext来运行,可以看到fs.readFileSync传入的是module.id也就是我们Module定义时候id存储的是模块的绝对路径,读取到的content是一个字符串,我们使用Module.wrapper来包裹一下就相当于在这个模块外部又包裹了一个函数,也就实现了私有作用域。
// 使用call来执行fn函数,第一个参数改变运行的this我们传入module.exports,后面的参数就是函数外面包裹参数exports, module, Require, __dirname, __filename
Module._extensions = {'.js'(module) {const content = fs.readFileSync(module.id, 'utf8');const fnStr = Module.wrapper[0] + content + Module.wrapper[1];const fn = vm.runInThisContext(fnStr);fn.call(module.exports, module.exports, module, Require,__filename,__dirname);},'.json'(module) {const json = fs.readFileSync(module.id, 'utf8');module.exports = JSON.parse(json); // 把文件的结果放在exports属性上}
}// tryModuleLoad函数接收的是模块对象,通过path.extname来获取模块的后缀名,然后使用Module._extensions来加载模块
// 定义模块加载方法
function tryModuleLoad(module) {// 获取扩展名const extension = path.extname(module.id);// 通过后缀加载当前模块Module._extensions[extension](module);
}// 至此Require加载机制我们基本就写完了,我们来重新看一下。Require加载模块的时候传入模块名称,在Require方法中使用path.resolve(__dirname, modulePath)获取到文件的绝对路径。然后通过new Module实例化的方式创建module对象,将模块的绝对路径存储在module的id属性中,在module中创建exports属性为一个json对象
// 使用tryModuleLoad方法去加载模块,tryModuleLoad中使用path.extname获取到文件的扩展名,然后根据扩展名来执行对应的模块加载机制
// 最终将加载到的模块挂载module.exports中。tryModuleLoad执行完毕之后module.exports已经存在了,直接返回就可以了// 给模块添加缓存
// 添加缓存也比较简单,就是文件加载的时候将文件放入缓存中,再去加载模块时先看缓存中是否存在,如果存在直接使用,如果不存在再去重新,加载之后再放入缓存// 测试
let json = Require('./test.json');
let test2 = Require('./test2.js');
console.log(json);
console.log(test2);
参考:前端手写面试题详细解答
实现Object.freeze
Object.freeze冻结一个对象,让其不能再添加/删除属性,也不能修改该对象已有属性的可枚举性、可配置可写性,也不能修改已有属性的值和它的原型属性,最后返回一个和传入参数相同的对象
function myFreeze(obj){// 判断参数是否为Object类型,如果是就封闭对象,循环遍历对象。去掉原型属性,将其writable特性设置为falseif(obj instanceof Object){Object.seal(obj); // 封闭对象for(let key in obj){if(obj.hasOwnProperty(key)){Object.defineProperty(obj,key,{writable:false // 设置只读})// 如果属性值依然为对象,要通过递归来进行进一步的冻结myFreeze(obj[key]); }}}
}
类数组转化为数组的方法
const arrayLike=document.querySelectorAll('div')// 1.扩展运算符
[...arrayLike]
// 2.Array.from
Array.from(arrayLike)
// 3.Array.prototype.slice
Array.prototype.slice.call(arrayLike)
// 4.Array.apply
Array.apply(null, arrayLike)
// 5.Array.prototype.concat
Array.prototype.concat.apply([], arrayLike)
实现Ajax
步骤
- 创建
XMLHttpRequest实例 - 发出 HTTP 请求
- 服务器返回 XML 格式的字符串
- JS 解析 XML,并更新局部页面
- 不过随着历史进程的推进,XML 已经被淘汰,取而代之的是 JSON。
了解了属性和方法之后,根据 AJAX 的步骤,手写最简单的 GET 请求。
实现节流函数(throttle)
节流函数原理:指频繁触发事件时,只会在指定的时间段内执行事件回调,即触发事件间隔大于等于指定的时间才会执行回调函数。总结起来就是: 事件,按照一段时间的间隔来进行触发 。

像dom的拖拽,如果用消抖的话,就会出现卡顿的感觉,因为只在停止的时候执行了一次,这个时候就应该用节流,在一定时间内多次执行,会流畅很多
手写简版
使用时间戳的节流函数会在第一次触发事件时立即执行,以后每过 wait 秒之后才执行一次,并且最后一次触发事件不会被执行
时间戳方式:
// func是用户传入需要防抖的函数
// wait是等待时间
const throttle = (func, wait = 50) => {// 上一次执行该函数的时间let lastTime = 0return function(...args) {// 当前时间let now = +new Date()// 将当前时间和上一次执行函数时间对比// 如果差值大于设置的等待时间就执行函数if (now - lastTime > wait) {lastTime = nowfunc.apply(this, args)}}
}setInterval(throttle(() => {console.log(1)}, 500),1
)
定时器方式:
使用定时器的节流函数在第一次触发时不会执行,而是在 delay 秒之后才执行,当最后一次停止触发后,还会再执行一次函数
function throttle(func, delay){var timer = null;returnfunction(){var context = this;var args = arguments;if(!timer){timer = setTimeout(function(){func.apply(context, args);timer = null;},delay);}}
}
适用场景:
DOM元素的拖拽功能实现(mousemove)- 搜索联想(
keyup) - 计算鼠标移动的距离(
mousemove) Canvas模拟画板功能(mousemove)- 监听滚动事件判断是否到页面底部自动加载更多
- 拖拽场景:固定时间内只执行一次,防止超高频次触发位置变动
- 缩放场景:监控浏览器
resize - 动画场景:避免短时间内多次触发动画引起性能问题
总结
- 函数防抖 :将几次操作合并为一次操作进行。原理是维护一个计时器,规定在delay时间后触发函数,但是在delay时间内再次触发的话,就会取消之前的计时器而重新设置。这样一来,只有最后一次操作能被触发。
- 函数节流 :使得一定时间内只触发一次函数。原理是通过判断是否到达一定时间来触发函数。
Object.assign
Object.assign()方法用于将所有可枚举属性的值从一个或多个源对象复制到目标对象。它将返回目标对象(请注意这个操作是浅拷贝)
Object.defineProperty(Object, 'assign', {value: function(target, ...args) {if (target == null) {return new TypeError('Cannot convert undefined or null to object');}// 目标对象需要统一是引用数据类型,若不是会自动转换const to = Object(target);for (let i = 0; i < args.length; i++) {// 每一个源对象const nextSource = args[i];if (nextSource !== null) {// 使用for...in和hasOwnProperty双重判断,确保只拿到本身的属性、方法(不包含继承的)for (const nextKey in nextSource) {if (Object.prototype.hasOwnProperty.call(nextSource, nextKey)) {to[nextKey] = nextSource[nextKey];}}}}return to;},// 不可枚举enumerable: false,writable: true,configurable: true,
})实现一个迭代器生成函数
ES6对迭代器的实现
JS原生的集合类型数据结构,只有Array(数组)和Object(对象);而ES6中,又新增了Map和Set。四种数据结构各自有着自己特别的内部实现,但我们仍期待以同样的一套规则去遍历它们,所以ES6在推出新数据结构的同时也推出了一套 统一的接口机制 ——迭代器(Iterator)。
ES6约定,任何数据结构只要具备Symbol.iterator属性(这个属性就是Iterator的具体实现,它本质上是当前数据结构默认的迭代器生成函数),就可以被遍历——准确地说,是被for...of...循环和迭代器的next方法遍历。 事实上,for...of...的背后正是对next方法的反复调用。
在ES6中,针对Array、Map、Set、String、TypedArray、函数的 arguments 对象、NodeList 对象这些原生的数据结构都可以通过for...of...进行遍历。原理都是一样的,此处我们拿最简单的数组进行举例,当我们用for...of...遍历数组时:
const arr = [1, 2, 3]
const len = arr.length
for(item of arr) {console.log(`当前元素是${item}`)
}
之所以能够按顺序一次一次地拿到数组里的每一个成员,是因为我们借助数组的
Symbol.iterator生成了它对应的迭代器对象,通过反复调用迭代器对象的next方法访问了数组成员,像这样:
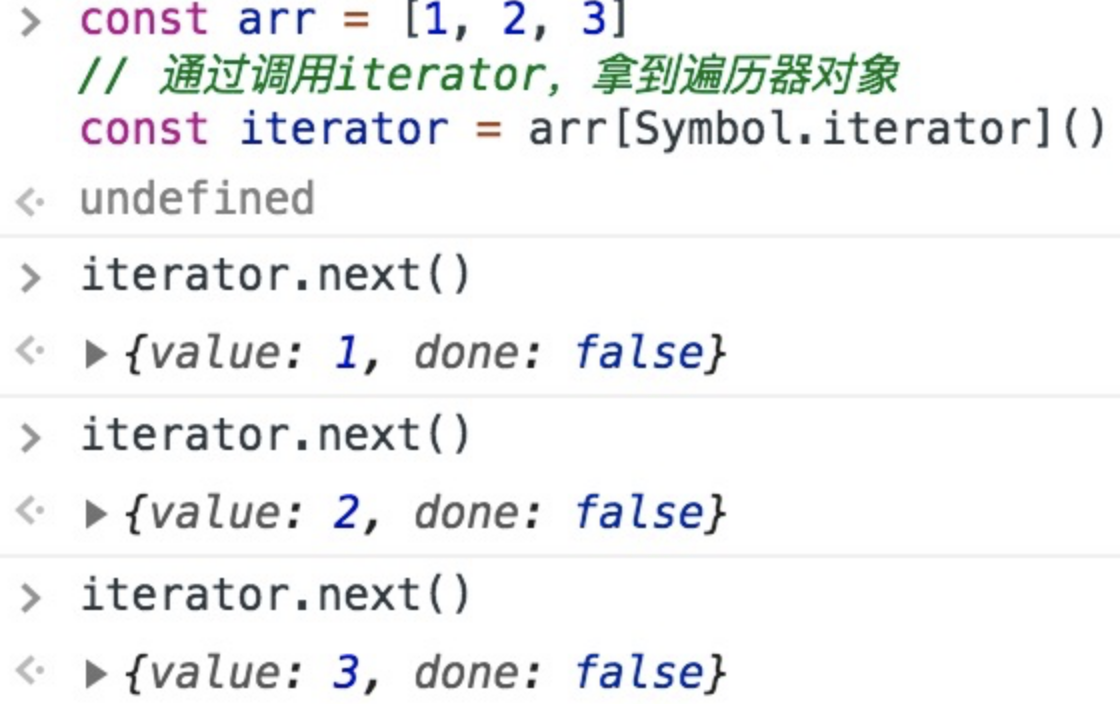
const arr = [1, 2, 3]
// 通过调用iterator,拿到迭代器对象
const iterator = arr[Symbol.iterator]()// 对迭代器对象执行next,就能逐个访问集合的成员
iterator.next()
iterator.next()
iterator.next()
丢进控制台,我们可以看到next每次会按顺序帮我们访问一个集合成员:
而
for...of...做的事情,基本等价于下面这通操作:
// 通过调用iterator,拿到迭代器对象
const iterator = arr[Symbol.iterator]()// 初始化一个迭代结果
let now = { done: false }// 循环往外迭代成员
while(!now.done) {now = iterator.next()if(!now.done) {console.log(`现在遍历到了${now.value}`)}
}
可以看出,
for...of...其实就是iterator循环调用换了种写法。在ES6中我们之所以能够开心地用for...of...遍历各种各种的集合,全靠迭代器模式在背后给力。
ps:此处推荐阅读迭代协议 (opens new window),相信大家读过后会对迭代器在ES6中的实现有更深的理解。
解析 URL Params 为对象
let url = 'http://www.domain.com/?user=anonymous&id=123&id=456&city=%E5%8C%97%E4%BA%AC&enabled';
parseParam(url)
/* 结果{ user: 'anonymous', id: [ 123, 456 ], // 重复出现的 key 要组装成数组,能被转成数字的就转成数字类型 city: '北京', // 中文需解码 enabled: true, // 未指定值得 key 约定为 true}*/function parseParam(url) {const paramsStr = /.+\?(.+)$/.exec(url)[1]; // 将 ? 后面的字符串取出来const paramsArr = paramsStr.split('&'); // 将字符串以 & 分割后存到数组中let paramsObj = {};// 将 params 存到对象中paramsArr.forEach(param => {if (/=/.test(param)) { // 处理有 value 的参数let [key, val] = param.split('='); // 分割 key 和 valueval = decodeURIComponent(val); // 解码val = /^\d+$/.test(val) ? parseFloat(val) : val; // 判断是否转为数字if (paramsObj.hasOwnProperty(key)) { // 如果对象有 key,则添加一个值paramsObj[key] = [].concat(paramsObj[key], val);} else { // 如果对象没有这个 key,创建 key 并设置值paramsObj[key] = val;}} else { // 处理没有 value 的参数paramsObj[param] = true;}})return paramsObj;
}event模块
实现node中回调函数的机制,node中回调函数其实是内部使用了观察者模式。
观察者模式:定义了对象间一种一对多的依赖关系,当目标对象Subject发生改变时,所有依赖它的对象Observer都会得到通知。
function EventEmitter() {this.events = new Map();
}// 需要实现的一些方法:
// addListener、removeListener、once、removeAllListeners、emit// 模拟实现addlistener方法
const wrapCallback = (fn, once = false) => ({ callback: fn, once });
EventEmitter.prototype.addListener = function(type, fn, once = false) {const hanlder = this.events.get(type);if (!hanlder) {// 没有type绑定事件this.events.set(type, wrapCallback(fn, once));} else if (hanlder && typeof hanlder.callback === 'function') {// 目前type事件只有一个回调this.events.set(type, [hanlder, wrapCallback(fn, once)]);} else {// 目前type事件数>=2hanlder.push(wrapCallback(fn, once));}
}
// 模拟实现removeListener
EventEmitter.prototype.removeListener = function(type, listener) {const hanlder = this.events.get(type);if (!hanlder) return;if (!Array.isArray(this.events)) {if (hanlder.callback === listener.callback) this.events.delete(type);else return;}for (let i = 0; i < hanlder.length; i++) {const item = hanlder[i];if (item.callback === listener.callback) {hanlder.splice(i, 1);i--;if (hanlder.length === 1) {this.events.set(type, hanlder[0]);}}}
}
// 模拟实现once方法
EventEmitter.prototype.once = function(type, listener) {this.addListener(type, listener, true);
}
// 模拟实现emit方法
EventEmitter.prototype.emit = function(type, ...args) {const hanlder = this.events.get(type);if (!hanlder) return;if (Array.isArray(hanlder)) {hanlder.forEach(item => {item.callback.apply(this, args);if (item.once) {this.removeListener(type, item);}})} else {hanlder.callback.apply(this, args);if (hanlder.once) {this.events.delete(type);}}return true;
}
EventEmitter.prototype.removeAllListeners = function(type) {const hanlder = this.events.get(type);if (!hanlder) return;this.events.delete(type);
}打印出当前网页使用了多少种HTML元素
一行代码可以解决:
const fn = () => {return [...new Set([...document.querySelectorAll('*')].map(el => el.tagName))].length;
}值得注意的是:DOM操作返回的是类数组,需要转换为数组之后才可以调用数组的方法。
实现instanceOf
思路:
- 步骤1:先取得当前类的原型,当前实例对象的原型链
- 步骤2:一直循环(执行原型链的查找机制)
- 取得当前实例对象原型链的原型链(
proto = proto.__proto__,沿着原型链一直向上查找) - 如果 当前实例的原型链
__proto__上找到了当前类的原型prototype,则返回true - 如果 一直找到
Object.prototype.__proto__ == null,Object的基类(null)上面都没找到,则返回false
- 取得当前实例对象原型链的原型链(
// 实例.__ptoto__ === 类.prototype
function _instanceof(example, classFunc) {// 由于instance要检测的是某对象,需要有一个前置判断条件//基本数据类型直接返回falseif(typeof example !== 'object' || example === null) return false;let proto = Object.getPrototypeOf(example);while(true) {if(proto == null) return false;// 在当前实例对象的原型链上,找到了当前类if(proto == classFunc.prototype) return true;// 沿着原型链__ptoto__一层一层向上查proto = Object.getPrototypeof(proto); // 等于proto.__ptoto__}
}console.log('test', _instanceof(null, Array)) // false
console.log('test', _instanceof([], Array)) // true
console.log('test', _instanceof('', Array)) // false
console.log('test', _instanceof({}, Object)) // true
验证是否是邮箱
function isEmail(email) {var regx = /^([a-zA-Z0-9_\-])+@([a-zA-Z0-9_\-])+(\.[a-zA-Z0-9_\-])+$/;return regx.test(email);
}实现 add(1)(2)(3)
函数柯里化概念: 柯里化(Currying)是把接受多个参数的函数转变为接受一个单一参数的函数,并且返回接受余下的参数且返回结果的新函数的技术。
1)粗暴版
function add (a) {
return function (b) {return function (c) {return a + b + c;}
}
}
console.log(add(1)(2)(3)); // 62)柯里化解决方案
- 参数长度固定
var add = function (m) {var temp = function (n) {return add(m + n);}temp.toString = function () {return m;}return temp;
};
console.log(add(3)(4)(5)); // 12
console.log(add(3)(6)(9)(25)); // 43对于add(3)(4)(5),其执行过程如下:
-
先执行add(3),此时m=3,并且返回temp函数;
-
执行temp(4),这个函数内执行add(m+n),n是此次传进来的数值4,m值还是上一步中的3,所以add(m+n)=add(3+4)=add(7),此时m=7,并且返回temp函数
-
执行temp(5),这个函数内执行add(m+n),n是此次传进来的数值5,m值还是上一步中的7,所以add(m+n)=add(7+5)=add(12),此时m=12,并且返回temp函数
-
由于后面没有传入参数,等于返回的temp函数不被执行而是打印,了解JS的朋友都知道对象的toString是修改对象转换字符串的方法,因此代码中temp函数的toString函数return m值,而m值是最后一步执行函数时的值m=12,所以返回值是12。
- 参数长度不固定
function add (...args) {//求和return args.reduce((a, b) => a + b)
}
function currying (fn) {let args = []return function temp (...newArgs) {if (newArgs.length) {args = [...args,...newArgs]return temp} else {let val = fn.apply(this, args)args = [] //保证再次调用时清空return val}}
}
let addCurry = currying(add)
console.log(addCurry(1)(2)(3)(4, 5)()) //15
console.log(addCurry(1)(2)(3, 4, 5)()) //15
console.log(addCurry(1)(2, 3, 4, 5)()) //15判断对象是否存在循环引用
循环引用对象本来没有什么问题,但是序列化的时候就会发生问题,比如调用JSON.stringify()对该类对象进行序列化,就会报错: Converting circular structure to JSON.
下面方法可以用来判断一个对象中是否已存在循环引用:
const isCycleObject = (obj,parent) => {const parentArr = parent || [obj];for(let i in obj) {if(typeof obj[i] === 'object') {let flag = false;parentArr.forEach((pObj) => {if(pObj === obj[i]){flag = true;}})if(flag) return true;flag = isCycleObject(obj[i],[...parentArr,obj[i]]);if(flag) return true;}}return false;
}const a = 1;
const b = {a};
const c = {b};
const o = {d:{a:3},c}
o.c.b.aa = a;console.log(isCycleObject(o)查找有序二维数组的目标值:
var findNumberIn2DArray = function(matrix, target) {if (matrix == null || matrix.length == 0) {return false;}let row = 0;let column = matrix[0].length - 1;while (row < matrix.length && column >= 0) {if (matrix[row][column] == target) {return true;} else if (matrix[row][column] > target) {column--;} else {row++;}}return false;
};二维数组斜向打印:
function printMatrix(arr){let m = arr.length, n = arr[0].lengthlet res = []// 左上角,从0 到 n - 1 列进行打印for (let k = 0; k < n; k++) {for (let i = 0, j = k; i < m && j >= 0; i++, j--) {res.push(arr[i][j]);}}// 右下角,从1 到 n - 1 行进行打印for (let k = 1; k < m; k++) {for (let i = k, j = n - 1; i < m && j >= 0; i++, j--) {res.push(arr[i][j]);}}return res
}