🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
YOLO概述
IOU的概念
YOLO 是如何快速检测物体的?
YOLO v3 神经网络架构
YOLO 和 Faster R-CNN 的比较
用于对象检测的 Darknet介绍
使用Darknet检测物体
使用 Tiny Darknet 检测物体
使用Darknet进行实时预测
YOLO 与 YOLO v2 与 YOLO v3
什么时候训练模型?
使用 YOLO v3 训练您自己的图像集以开发自定义模型
准备图像
生成注释文件
将 .xml 文件转换为 .txt 文件
创建组合的 train.txt 和 test.txt 文件
创建类名文件列表
创建 YOLO .data 文件
调整YOLO配置文件
启用 GPU 进行训练
开始训练
特征金字塔网络和 RetinaNet 概述
概括
在上一章中,我们详细讨论了各种神经网络图像分类和对象检测架构,它们利用多个步骤进行对象检测、分类和边界框的细化。在本章中,我们将介绍两种单阶段的快速目标检测方法——You Only Look Once ( YOLO ) 和 RetinaNet。我们将讨论每个模型的架构,然后使用 YOLO v3 在真实图像和视频中进行推理。我们将向您展示如何使用 YOLO v3 优化配置参数并训练您自己的自定义图像。
本章涵盖的主题如下:
- YOLO概述
- 用于对象检测的Darknet介绍
- 使用 Darknet 和 Tiny Darknet 进行实时预测
- 比较 YOLO——YOLO 与 YOLO v2 与 YOLO v3
- 什么时候训练模型?
- 使用 YOLO v3 训练您自己的图像集以开发自定义模型
- 特征金字塔和 RetinaNet 概述
YOLO概述
我们在第 5 章,神经网络架构和模型中了解到,每个已发布的神经网络架构都通过学习其架构和特征,然后开发一个全新的分类器来提高准确性和检测时间,从而改进了前一个。YOLO 参加了Joseph Redmon、Santosh Divvala、Ross Girshick 和 Ali Farhadi 在You Only Look Once:Unified, Real-Time Object Detection论文https://arxiv.org/中的计算机视觉和模式识别会议( CVPR ) 2016 pdf/1506.02640.pdf. YOLO 是一种速度极快的神经网络,可以以每秒 45 帧(基本 YOLO)到每秒 155 帧(快速 YOLO)的惊人速度同时检测多个类别的对象。作为比较,大多数手机相机以每秒 30 帧左右的速度拍摄视频,而高速相机以每秒 250 帧左右的速度拍摄视频。YOLO 的每秒帧率相当于检测时间约为 6 到 22 毫秒。将此与人脑检测图像所需的时间相比较,大约为 13 毫秒——YOLO 以与人类类似的方式立即识别图像。因此,它为机器提供了瞬时对象检测能力。
在进一步了解细节之前,我们将首先了解Intersection Over Union ( IOU ) 的概念。
IOU的概念
IOU是一种基于预测边界框和ground truth边界框(手工标注)重叠程度的目标检测评估指标。让我们看一下IOU的以下导数:

下图说明了 IOU,显示了大型货车的预测边界框和真实边界框:

在这种情况下,IOU 值接近左右0.9,因为重叠区域非常高。如果两个边界框不重叠,则 IOU 值为0,如果它们重叠 100%,则 IOU 值为1。
YOLO 是如何快速检测物体的?
YOLO 的检测机制基于单个卷积神经网络( CNN ),该网络同时预测对象的多个边界框以及在每个边界框中检测到给定对象类别的概率。下图说明了这种方法:

前面的照片显示了三个主要步骤,从边界框的开发到使用非最大抑制和最终的边界框。详细步骤如下:
- YOLO 中的 CNN 使用整个图像的特征来预测每个边界框。因此,预测是全局的,而不是局部的。
- 整个图像被划分为 S x S 个网格单元,每个网格单元预测 B 个边界框和边界框包含对象的概率 (P)。因此,总共有 S x S x B 个边界框,每个边界框都有相应的概率。
- 每个边界框包含五个预测(x、y、w、h和c),其中以下适用:
- o ( x , y ) 是边界框中心相对于网格单元坐标的坐标。
- o ( w , h ) 是边界框的宽度和高度,相对于图像尺寸。
- o ( c ) 是置信度预测,表示预测框和ground truth box之间的IOU。
- 网格单元包含对象的概率定义为类的概率乘以 IOU 值。这意味着如果一个网格单元仅部分包含一个对象,那么它的概率会很低,IOU 值也会很低。它将对该网格单元的边界框产生两种影响:
- 边界框的形状将小于完全包含对象的网格单元的边界框的大小,因为网格单元只能看到对象的一部分并从中推断出它的形状。如果网格单元包含对象的很小部分,则它可能根本无法识别该对象。
- 边界框类的置信度会很低,因为部分图像产生的 IOU 值将不适合地面实况预测。
- 通常,每个网格单元只能包含一个类,但使用锚盒原理,可以将多个类分配给一个网格单元。锚框是一个预定义的形状,表示被检测类的形状。例如,如果我们检测三个类别——汽车、摩托车和人类——那么我们可能可以使用两个锚框形状——一个代表摩托车和人类,另一个代表汽车。这可以通过查看前面图像中最右侧的图像来确认。我们可以通过使用 k-means 聚类等算法分析每个类的形状来确定锚框形状以形成训练 CSV 数据。
让我们以前面的图像为例。在这里,我们有三个类:car、motorcycle和human。我们假设一个 5 x 5 的网格,有 2 个锚框和 8 个维度(5 个边界框参数(x、y、w、h和c)和 3 个类别(c1、c2 和 c3))。因此,输出向量大小为 5 x 5 x 2 x 8。
我们为每个锚框重复该参数两次。下图说明了边界框坐标的计算:Y = [x, y, w, h, c, c1, c2, c3, x, y, w, h, c, c1, c2, c3]
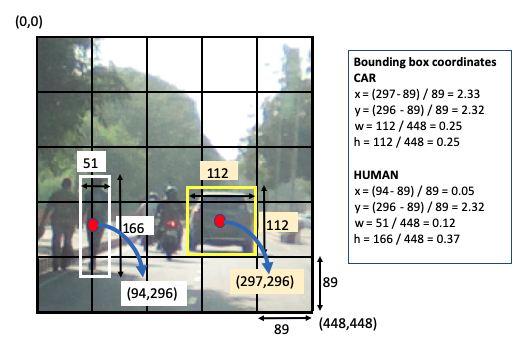
图像的大小为 448 x 448。这里,为了说明目的,显示了两个类别的计算方法-human 和 car-。注意每个anchor box大小为448/5~89。
YOLO v3 神经网络架构
TYOLO v3 由 Joseph Redmon 和 Ali Farhadi 于 2018 年在论文YOLOv3: An Incremental Improvement https://pjreddie.com/media/files/papers/YOLOv3.pdf中介绍。YOLO v3 神经网络架构如下图所示。该网络有 24 个卷积层和 2 个全连接层;它没有任何 softmax 层。
下图以图形方式说明了 YOLO v3 架构:

YOLO v3 最重要的特点是它的检测机制,这是在三个不同的尺度上完成的——在第 82、94 和 106 层:
- 该网络由第 1 层和第 74 层之间的 23 个卷积和残差块组成,其中输入图像大小从608到下降19,深度通过交替的 3 x 3 和 1 x 1 过滤器从3到增加。1,024
- 1大部分时间都保持步幅,除了 5 种情况,其中步幅值2用于减小尺寸,以及 3 x 3 过滤器。
- 剩余块之后是交替的 1 x 1 和 3 x 3 滤波器的预卷积块,直到在第 82 层进行第一次检测。已经使用了两个短路 - 一个在第 61 层和 85 层之间,另一个在第 36 和 97 层之间
YOLO 和 Faster R-CNN 的比较
YOLO 与 Faster R-CNN 的相似之处如下表所示:
| YOLO | R-CNN |
| 预测每个网格单元的边界框。 | 选择性搜索为每个区域提议(本质上是一个网格单元)生成边界框。 |
| 使用边界框回归。 | 使用边界框回归。 |
YOLO 和 Faster R-CNN 的区别如下表所示:
| YOLO | R-CNN |
| 分类和边界框回归同时发生。 | 选择性搜索为每个区域提案生成一个边界框——这些是单独的事件。 |
| 每张图像 98 个边界框。 | 每张图像大约有 2,000 个区域提议边界框。 |
| 每个网格单元 2 个锚点。 | 每个网格单元 9 个锚点。 |
| 它无法检测到彼此相邻的小物体和物体。 | 检测彼此相邻的小物体和物体。 |
| 快速算法。 | Faster R-CNN 比 YOLO 慢。 |
所以,总而言之,如果你需要生产级别的准确性并且不太关心速度,请选择 Faster R-CNN。但是,如果您需要快速检测,请选择 YOLO。与任何神经网络模型一样,您需要有足够多的样本(大约 1,000 个)以不同的角度、不同的颜色和形状进行预测,才能做出良好的预测。一旦完成,根据我的个人经验,YOLO v3 给出了一个非常合理和快速的预测。
用于对象检测的 Darknet介绍
Darknet 是一个开放的神经网络框架,用 C 语言编写,由 YOLO 的第一作者 Joseph Redmon 管理。可以在pjreddie.com上找到有关暗网的详细信息。在本节中,我们将讨论用于对象检测的 Darknet 和 Tiny Darknet。
使用Darknet检测物体
在本节中,我们将从 Darknet 官方站点安装 Darknet 并将其用于对象检测。请按照以下步骤在您的 PC 上安装 Darknet 并进行推断:
1.应在终端中输入以下五行。在每个命令行后按Enter 。这些步骤将从 GitHub 克隆 Darknet,这将在您的 PC 中创建一个 Darknet 目录,并获取 YOLO v3 权重,然后检测图像中的对象:
git clone https://github.com/pjreddie/darknet.git
cd darknet
make
wget https://pjreddie.com/media/files/yolov3.weights
./darknet detect cfg/yolov3.cfg yolov3.weights data/carhumanbike.png2.执行git clone命令后,您会在终端中获得以下输出:
Cloning into 'darknet'...remote: Enumerating objects: 5901, done.remote: Total 5901 (delta 0), reused 0 (delta 0), pack-reused 5901Receiving objects: 100% (5901/5901), 6.16 MiB | 8.03 MiB/s, done.Resolving deltas: 100% (3916/3916), done.3.输入wget yolov3重量后,您会在终端中获得以下输出:
Resolving pjreddie.com (pjreddie.com)... 128.208.4.108Connecting to pjreddie.com (pjreddie.com)|128.208.4.108|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 248007048 (237M) [application/octet-stream]
Saving to: ‘yolov3.weights’
yolov3.weights 100%[======================================================>] 236.52M 8.16MB/s in 29s
… (8.13 MB/s) - ‘yolov3.weights’ saved [248007048/248007048]4.然后,一旦你输入darknet$ ./darknet detect cfg/yolov3.cfg yolov3.weights data/carhumanbike.png,你会在终端中得到以下输出:
layer filters size input output0 conv 32 3 x 3 / 1 608 x 608 x 3 -> 608 x 608 x 32 0.639 BFLOPs --> image size 608x6081 conv 64 3 x 3 / 2 608 x 608 x 32 -> 304 x 304 x 64 3.407 BFLOPs2 conv 32 1 x 1 / 1 304 x 304 x 64 -> 304 x 304 x 32 0.379 BFLOPs3 conv 64 3 x 3 / 1 304 x 304 x 32 -> 304 x 304 x 64 3.407 BFLOPs4 res 1 304 x 304 x 64 -> 304 x 304 x 64 --> this implies residual block connecting layer 1 to 45 conv 128 3 x 3 / 2 304 x 304 x 64 -> 152 x 152 x 128 3.407 BFLOPs6 conv 64 1 x 1 / 1 152 x 152 x 128 -> 152 x 152 x 64 0.379 BFLOPs7 conv 128 3 x 3 / 1 152 x 152 x 64 -> 152 x 152 x 128 3.407 BFLOPs8 res 5 152 x 152 x 128 -> 152 x 152 x 128 --> this implies residual block connecting layer 5 to 8.........83 route 79 --> this implies layer 83 is connected to 79, layer 80-82 are prediction layers84 conv 256 1 x 1 / 1 19 x 19 x 512 -> 19 x 19 x 256 0.095 BFLOPs85 upsample 2x 19 x 19 x 256 -> 38 x 38 x 256 --> this implies image size increased by 2X86 route 85 61 --> this implies shortcut between layer 61 and 8587 conv 256 1 x 1 / 1 38 x 38 x 768 -> 38 x 38 x 256 0.568 BFLOPs88 conv 512 3 x 3 / 1 38 x 38 x 256 -> 38 x 38 x 512 3.407 BFLOPs89 conv 256 1 x 1 / 1 38 x 38 x 512 -> 38 x 38 x 256 0.379 BFLOPs90 conv 512 3 x 3 / 1 38 x 38 x 256 -> 38 x 38 x 512 3.407 BFLOPs91 conv 256 1 x 1 / 1 38 x 38 x 512 -> 38 x 38 x 256 0.379 BFLOPs92 conv 512 3 x 3 / 1 38 x 38 x 256 -> 38 x 38 x 512 3.407 BFLOPs93 conv 255 1 x 1 / 1 38 x 38 x 512 -> 38 x 38 x 255 0.377 BFLOPs94 yolo --> this implies prediction at layer 9495 route 91 --> this implies layer 95 is connected to 91, layer 92-94 are prediction layers96 conv 128 1 x 1 / 1 38 x 38 x 256 -> 38 x 38 x 128 0.095 BFLOPs97 upsample 2x 38 x 38 x 128 -> 76 x 76 x 128 à this implies image size increased by 2X98 route 97 36. --> this implies shortcut between layer 36 and 9799 conv 128 1 x 1 / 1 76 x 76 x 384 -> 76 x 76 x 128 0.568 BFLOPs100 conv 256 3 x 3 / 1 76 x 76 x 128 -> 76 x 76 x 256 3.407 BFLOPs101 conv 128 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 128 0.379 BFLOPs102 conv 256 3 x 3 / 1 76 x 76 x 128 -> 76 x 76 x 256 3.407 BFLOPs103 conv 128 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 128 0.379 BFLOPs104 conv 256 3 x 3 / 1 76 x 76 x 128 -> 76 x 76 x 256 3.407 BFLOPs105 conv 255 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 255 0.754 BFLOPs106 yolo --> this implies prediction at layer 106执行代码后,您将看到完整的模型。为简洁起见,我们仅在前面的代码片段中显示了模型的开头。
上述输出描述了 YOLO v3 的详细神经网络构建块。花一些时间来了解所有 106 个卷积层及其用途。上一节提供了对所有唯一代码行的解释。前面的代码导致图像的以下输出:
Loading weights from yolov3.weights...Done!
data/carhumanbike.png: Predicted in 16.140244 seconds.
car: 81%
truck: 63%
motorbike: 77%
car: 58%
person: 100%
person: 100%
person: 99%
person: 94%预测输出如下所示:

YOLO v3 模型在预测方面做得非常好。即使是很远的汽车也能被正确检测到。前面的汽车被归类为汽车(在图像中看不到标签)和卡车。所有四个人——两个步行和两个骑摩托车——都被检测到。在两辆摩托车中,检测到一辆摩托车。请注意,虽然汽车的颜色是黑色,但模型不会错误地将阴影检测为汽车。
使用 Tiny Darknet 检测物体
Tiny Darknet 是一个小而快的网络,可以非常快速地检测物体。它的大小为 4 MB,而 Darknet 的大小为 28 MB。你可以在wget https://pjreddie.com/media/files/tiny.weights找到它的实现细节。
完成上述步骤后,Darknet 应该已经安装在您的 PC 上。在终端中执行以下命令:
$ cd darknet
darknet$ wget https://pjreddie.com/media/files/tiny.weights前面的命令将在您的darknet文件夹中安装暗网权重。tiny.cfg您的cfg文件夹中也应该有。然后,执行以下命令来检测对象。在这里,我们将使用与引用的暗网模型相同的图像进行检测;我们只需将权重和cfg文件从 Darknet 更改为 Tiny Darknet:
darknet$ ./darknet detect cfg/tiny.cfg tiny.weights data /carhumanbike.png与 Darknet 一样,上述命令将显示 Tiny Darknet 模型的所有 21 层(而 Darknet 为 106 层),如下所示:
layer filters size input output0 conv 16 3 x 3 / 1 224 x 224 x 3 -> 224 x 224 x 16 0.043 BFLOPs1 max 2 x 2 / 2 224 x 224 x 16 -> 112 x 112 x 162 conv 32 3 x 3 / 1 112 x 112 x 16 -> 112 x 112 x 32 0.116 BFLOPs3 max 2 x 2 / 2 112 x 112 x 32 -> 56 x 56 x 324 conv 16 1 x 1 / 1 56 x 56 x 32 -> 56 x 56 x 16 0.003 BFLOPs5 conv 128 3 x 3 / 1 56 x 56 x 16 -> 56 x 56 x 128 0.116 BFLOPs6 conv 16 1 x 1 / 1 56 x 56 x 128 -> 56 x 56 x 16 0.013 BFLOPs7 conv 128 3 x 3 / 1 56 x 56 x 16 -> 56 x 56 x 128 0.116 BFLOPs8 max 2 x 2 / 2 56 x 56 x 128 -> 28 x 28 x 1289 conv 32 1 x 1 / 1 28 x 28 x 128 -> 28 x 28 x 32 0.006 BFLOPs10 conv 256 3 x 3 / 1 28 x 28 x 32 -> 28 x 28 x 256 0.116 BFLOPs11 conv 32 1 x 1 / 1 28 x 28 x 256 -> 28 x 28 x 32 0.013 BFLOPs12 conv 256 3 x 3 / 1 28 x 28 x 32 -> 28 x 28 x 256 0.116 BFLOPs13 max 2 x 2 / 2 28 x 28 x 256 -> 14 x 14 x 25614 conv 64 1 x 1 / 1 14 x 14 x 256 -> 14 x 14 x 64 0.006 BFLOPs15 conv 512 3 x 3 / 1 14 x 14 x 64 -> 14 x 14 x 512 0.116 BFLOPs16 conv 64 1 x 1 / 1 14 x 14 x 512 -> 14 x 14 x 64 0.013 BFLOPs17 conv 512 3 x 3 / 1 14 x 14 x 64 -> 14 x 14 x 512 0.116 BFLOPs18 conv 128 1 x 1 / 1 14 x 14 x 512 -> 14 x 14 x 128 0.026 BFLOPs19 conv 1000 1 x 1 / 1 14 x 14 x 128 -> 14 x 14 x1000 0.050 BFLOPs20 avg 14 x 14 x1000 -> 100021 softmax 1000
Loading weights from tiny.weights...Done!
data/carhumanbike.png: Predicted in 0.125068 seconds.但是,该模型无法检测到图像中的对象。我把检测改为分类,如图:
darknet$ ./darknet classify cfg/tiny.cfg tiny.weights data/dog.jpg上述命令生成的结果类似于 Tiny YOLO 链接 ( wget https://pjreddie.com/media/files/tiny.weights ) 中发布的结果:
Loading weights from tiny.weights...Done!
data/dog.jpg: Predicted in 0.130953 seconds.
14.51%: malamute6.09%: Newfoundland5.59%: dogsled4.55%: standard schnauzer4.05%: Eskimo dog但是,相同的图像在通过对象检测时不会返回边界框。
接下来,我们将讨论使用暗网对视频进行实时预测。
使用Darknet进行实时预测
涉及暗网的预测都可以使用终端中的命令行来完成。有关详细信息,请参阅YOLO: Real-Time Object Detection。
到目前为止,我们已经在图像上使用暗网进行了推断。在以下步骤中,我们将学习如何使用暗网对视频文件进行推理:
1.通过在终端中键入转到darknet目录(已在前面的步骤中安装) 。cd darknet
2.确保已安装 OpenCV。即使您安装了 OpenCV,它仍可能会创建一个错误标志。使用sudo apt-get install libopencv-dev命令在darknet目录中安装 OpenCV。
3.在darknet目录中,有一个名为Makefile. 打开该文件,设置OpenCV = 1并保存。
4.前往https://pjreddie.com/media/files/yolov3.weights从终端下载权重。
5.此时,您必须重新编译,因为Makefile已更改。您可以通过make在终端中输入来做到这一点。
6.然后,通过在终端中键入以下命令来下载视频文件:
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights data/road_video.mp47.在这里,将编译之前解释过的 106 层的 YOLO 模型并播放视频。您会注意到视频播放速度非常慢。这可以通过我们将执行的以下两个步骤来解决。它们应该一个一个地执行,因为每个步骤都有其后果。
8.再次打开Makefile。更改GPU为1,保存Makefile,然后重复步骤 4 到 6。此时,我注意到步骤 6 提供了以下 CUDAout of memory错误:
…….57 conv 512 3 x 3 / 1 38 x 38 x 256 -> 38 x 38 x 512 3.407 BFLOPs58 res 55 38 x 38 x 512 -> 38 x 38 x 51259 conv 256 1 x 1 / 1 38 x 38 x 512 -> 38 x 38 x 256 0.379 BFLOPs60 CUDA Error: out of memorydarknet: ./src/cuda.c:36: check_error: Assertion `0' failed.Aborted (core dumped)借助两种机制解决了该错误:
- 更改图像尺寸。
- 将 NVIDIA CUDA 版本从 9.0 更改为 10.1。请参阅 NVIDIA 站点以更改 NVIDIA 版本 ( CUDA Compatibility :: NVIDIA Data Center GPU Driver Documentation )。
首先,尝试更改图像大小。如果这不起作用,请检查 CUDA 版本,如果您仍在使用 9.0 版,请更新它。
9.在darknet目录中,目录下有一个名为yolov3.cfg的cfg文件。打开该文件并将宽度和高度从608更改为416或288。我发现当值设置为 时304,它仍然失败。保存文件并重复步骤 5 和 6。
这是当图像大小设置为时您将得到的错误代码304:
.....80 conv 1024 3 x 3 / 1 10 x 10 x 512 -> 10 x 10 x1024 0.944 BFLOPs81 conv 255 1 x 1 / 1 10 x 10 x1024 -> 10 x 10 x 255 0.052 BFLOPs82 yolo83 route 7984 conv 256 1 x 1 / 1 10 x 10 x 512 -> 10 x 10 x 256 0.026 BFLOPs85 upsample 2x 10 x 10 x 256 -> 20 x 20 x 2586 route 85 6187 Layer before convolutional layer must output image.: File existsdarknet: ./src/utils.c:256: error: Assertion `0' failed.Aborted (core dumped)下图显示了同时带有交通标志标签和汽车检测的视频文件的屏幕截图:

我们之前讨论了默认大小为的 YOLO v3 层608。以下是相同的输出,将大小更改为416以正确显示视频文件:
layer filters size input output0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64 1.595 BFLOPs2 conv 32 1 x 1 / 1 208 x 208 x 64 -> 208 x 208 x 32 0.177 BFLOPs3 conv 64 3 x 3 / 1 208 x 208 x 32 -> 208 x 208 x 64 1.595 BFLOPs4 res 1 208 x 208 x 64 -> 208 x 208 x 645 conv 128 3 x 3 / 2 208 x 208 x 64 -> 104 x 104 x 128 1.595 BFLOPs6 conv 64 1 x 1 / 1 104 x 104 x 128 -> 104 x 104 x 64 0.177 BFLOPs7 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128 1.595 BFLOPs8 res 5 104 x 104 x 128 -> 104 x 104 x 128.........94 yolo95 route 9196 conv 128 1 x 1 / 1 26 x 26 x 256 -> 26 x 26 x 128 0.044 BFLOPs97 upsample 2x 26 x 26 x 128 -> 52 x 52 x 12898 route 97 3699 conv 128 1 x 1 / 1 52 x 52 x 384 -> 52 x 52 x 128 0.266 BFLOP100 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs101 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs102 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs103 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs104 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs105 conv 255 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 255 0.353 BFLOPs106 yoloLoading weights from yolov3.weights...Done!video file: data/road_video.mp4执行上述代码后,您将看到完整的模型。为简洁起见,我们仅在前面的代码片段中显示了模型的开头。
下表总结了两种不同图像尺寸的输出:
| Layer | 608 size | 416 size |
| 82 | 19×19 | 13×13 |
| 94 | 38×38 | 26×26 |
| 106 | 76×76 | 52×52 |
请注意,原始图像大小与第82层输出大小之间的比率保持为 32 。到目前为止,我们已经比较了使用 Darknet 和 Tiny Darknet 的推理。现在,我们将比较不同的 YOLO 模型。
YOLO 与 YOLO v2 与 YOLO v3
三个 YOLO 版本的对比如下表所示:
A comparison of the three YOLO versions is shown in this table:
| YOLO | YOLO v2 | YOLO v3 | |
| 输入尺寸 | 224 x 224 | 448 x 448 | |
| 框架 | 在 ImageNet 上训练的Darknet——1,000。 | Darknet-19 19 个卷积层和 5 个最大池层。 | Darknet-53 53个卷积层。对于检测,增加了 53 层,总共 106 层。 |
| Small size detection | 它无法找到小图像。 | 在检测小图像方面比 YOLO 更好。 | 在小图像检测方面优于 YOLO v2。 |
| 使用锚框。 | 使用残差块。 |
下图比较了 YOLO v2 和 YOLO v3 的架构:

基本卷积层类似,但 YOLO v3 在三个独立的层进行检测:82、94 和 106。
什么时候训练模型?
在迁移学习中,经过训练的模型是通过对大量数据进行训练来开发的。因此,如果您的课程属于以下类别之一,则没有理由为这些课程训练模型。为 YOLO v3 训练的 80 个类如下:
Person, bicycle, car, motorbike, airplane, bus, train, truck, boat, traffic light, fire hydrant, stop sign, parking meter, bench, bird, cat, dog, horse, sheep, cow, elephant, bear, zebra, giraffe, backpack, umbrella, handbag, tie, suitcase, frisbee, skis, snowboard, sports ball, kite, baseball bat, baseball glove, skateboard, surfboard. tennis racket, bottle, wine glass, cup, fork, knife, spoon, bowl, banana, apple, sandwich, orange, broccoli, carrot, hot dog, pizza, donut, cake, chair, sofa, potted plant, bed, dining table, toilet, tv monitor, laptop, mouse, remote, keyboard, cell phone, microwave, oven, toaster, sink, refrigerator, book, clock, vase, scissors, teddy bear, hair drier, toothbrush所以,如果你想检测食物的类型,YOLO v3 会很好地检测banana, apple, sandwich, orange, broccoli, carrot, hot dog, pizza, donut, and cake,但它无法检测到hamburger。
同样,在 PASCAL VOC 数据集上训练的 YOLO v3 将能够检测所有 20 个类,它们是airplane, bicycle, bird, boat, bottle, bus, car, cat, chair, cow, dining table, dog, horse, motorbike, person, potted plant, sheep, sofa, train, 和tv monitor, 但不会能够检测到一个新的类,hot dog。
所以,这就是训练你自己的图像集的地方,这将在下一节中描述。
使用 YOLO v3 训练您自己的图像集以开发自定义模型
在本节中,我们将学习如何使用 YOLO v3 来训练您自己的自定义检测器。培训过程涉及许多不同的步骤。为了清楚起见,每个步骤的输入和输出在以下流程图中指示。许多培训步骤都包含在 YOLO 的YOLOv3: Redmon、Joseph、Farhadi 和 Ali 于 2018 年在 arXiv 上发布的增量改进出版物中。它们也包含在https://pjreddie.com的 VOC 培训 YOLO部分中/darknet/yolo/ 。
下图展示了如何使用 YOLO v3 训练 VOC 数据集。在我们的例子中,我们将使用我们自己的自定义家具数据,我们在第 6 章使用 Keras 对图像进行分类,使用迁移 学习进行视觉搜索:

此处描述了第 1 节到第 11 节的详细说明。
准备图像
请按照以下步骤准备图像:
- 研究你想检测多少类——在这个例子中,我们bed将考虑chairsofa第 6 章,使用迁移学习进行视觉搜索。
- 确保每个班级拥有相同数量的图像。
- 确保您的班级名称中没有空格;例如,使用caesar_salad代替caesar salad.
- 每个班级至少收集 100 张图像以开始初始训练(因此,完成步骤 1 到 10 来开发模型),
- 然后随着图像越来越多而增加数量。理想情况下,1000 张图像是一个很好的训练数字。将所有图像批量调整为 416 x 416 — 您可以在macOS预览窗格中选择选项,然后选择多个图像,然后批量调整大小,或者您可以使用 Ubuntu 中的 ImageMagick 等程序在终端中批量调整大小。需要此步骤的原因是 YOLO v3 期望图像大小为 416 x 416,因此会自行调整图像大小,但这可能会导致该图像的边界框看起来不同,导致在某些情况下无法检测到。
生成注释文件
此步骤涉及为数据集中每个图像中的每个对象创建边界框坐标。此边界框坐标通常由四个参数表示:(x,y) 以确定初始位置以及宽度和高度。边界框可以表示为.xml或.txt形式。此坐标文件也称为注释文件。请按照以下步骤完成此部分:
- 许多图像注释软件应用程序正在用于标记图像。我们已经在第 3 章,使用 OpenCV 和 CNN 进行面部检测,在面部关键点检测期间介绍了 VGG 图像注释器。在第 11 章,利用 CPU/GPU 优化在边缘设备上进行深度学习,我们将介绍用于自动图像标注的 CVAT 工具。在本章中,我们将介绍一个名为labelImg.
- 从labelImg · PyPI下载labelImg注释软件。您可以按照那里的说明为您的操作系统安装 - 如果您有任何问题,安装它的简单方法是在终端中键入。然后,要运行它,您所要做的就是在终端中输入。pypilabelImgpip3 install lableImglabelImg
- 在labelImg中,单击Open Dir框中的图像目录。选择每个图像并通过单击Create/RectBox在其周围创建一个边界框,然后为边界框添加一个类名,例如bed、chair或sofa。保存注释并通过单击右箭头转到下一个图像。
- 如果图片中有多个类别或同一类别的多个位置,请在每个类别周围绘制矩形。多类的示例是同一图像中的汽车和行人。同一类中的多个位置的示例是同一图像中不同位置的不同汽车。因此,如果图像由多把椅子和一张沙发组成,请在每把椅子周围绘制矩形,并在类名中chair为每把椅子和沙发键入一个矩形,然后在其周围绘制一个矩形并键入sofa。如果图像仅包含一张沙发,则在沙发周围绘制一个矩形并输入sofa类名。下图说明了这一点:

此图向您展示了如何标记属于同一类的多个图像。
将 .xml 文件转换为 .txt 文件
YOLO v3 需要一个注解文件保存为.txt文件而不是.xml文件。本节介绍如何转换和排列.txt文件以输入到模型中。有许多工具可用于这种转换——我们将在这里提到两个工具:
- RectLabel:这有一个内置的转换器来将.xml文件转换为.txt文件。
- 命令行xmltotxt工具:您可以在GitHub - isabek/XmlToTxt: ImageNet file xml format to Darknet text format GitHub 页面找到此工具。
此过程的输出将是一个包含.jpg、.xml和.txt文件的目录。每个图像.jpg文件都会有一个对应的.xmland.txt文件。您可以从目录中删除.xml文件,因为我们不再需要这些文件。
创建组合的 train.txt 和 test.txt 文件
顾名思义,此步骤涉及一个.txt代表所有图像的文件。为此,我们将运行一个简单的 Python 文件(一个用于训练和测试图像)来创建一个combinedtrain.txt和combinedtest.txt文件。转到Mastering-Computer-Vision-with-TensorFlow-2.0/Chapter7_yolo_combined_text.py at master · PacktPublishing/Mastering-Computer-Vision-with-TensorFlow-2.0 · GitHub获取 Python 文件。
Python 代码的示例输出如以下屏幕截图所示:

每个文本文件由几行组成——每行包含图像文件的路径,如前所示。
创建类名文件列表
该文件包含所有类的列表。因此,在我们的例子中,它是一个带有.names扩展名的简单文本文件,如下所示:
bed
chair
sofa创建 YOLO .data 文件
这些步骤涉及train和valid文件夹的路径。在开始之前,将组合train、组合test和.names文件复制到您的darknet目录。以下代码块显示了典型.data文件(在本例中为furniture.data)的外观:
classes= 3
train = /home/krishkar/darknet/furniture_train.txt
valid = /home/krishkar/darknet/furniture_test.txt
names = /home/krishkar/darknet/furniture_label.names
backup = backup在这里,我们有三个类(bed、chair和sofa),因此 的值classes设置为 3。train、valid和names文件夹显示组合的训练、组合测试和标签.names文件。将此文件保存在cfg目录中。
调整YOLO配置文件
完成这些步骤后,文件整理部分就完成了,我们现在将着手优化 YOLO 配置文件中的参数。为此,请YOLO-VOC.cfg在 Darknetcfg目录下打开并进行以下更改。生成的代码也可以从Mastering-Computer-Vision-with-TensorFlow-2.0/yolov3-furniture.cfg at master · PacktPublishing/Mastering-Computer-Vision-with-TensorFlow-2.0 · GitHub下载:
- 第 6 行——批量大小。将此设置为64。这意味着在每个训练步骤中将使用 64 张图像来更新 CNN 参数。
- 第 7 行—— subdivisions。这会按批次大小/细分拆分批次,然后将其送入 GPU 进行处理。该过程将重复细分的数量,直到完成批量大小 ( 64) 并开始新的批量。因此,如果subdivisions设置为1,则所有 64 张图像都将发送到 GPU 以在给定批次中同时进行处理。如果批量大小设置为8,则将 8 张图像发送到 GPU 进行处理,并在开始下一批之前重复该过程 8 次。将该值设置为1可能会导致 GPU 失败,但可能会提高检测的准确性。对于初始运行,将值设置为8。
- 第 11 行—— momentum。这用于最小化批次之间的较大权重变化,因为在任何时间点只处理一小部分(在本例中为 64 个)图像。默认值为0.9OK。
- 第 12 行—— decay。这用于通过控制权重值获得较大的值来最小化过度拟合。默认值为0.005OK。
- 第 18 行—— learning_rate。这表明当前批次的学习速度。下图显示了作为批次函数的学习率,接下来将对此进行解释。的默认值是一个合理的开始,如果值不是数字( NaN0.001 ) ,则可以减少:

6.第 19 行——burn_in这表示学习率上升的初始阶段。1000如果减少,则将其设置为并max_batches降低。
- 第 20 行—— max_batches。最大批次数。将其设置为 2,000 乘以类数。对于3类,值6000是合理的。请注意,默认值是500200非常高,如果保持不变,训练将运行数天。
- 第 22 行—— steps。这是第 23 行中学习率乘以尺度的步骤。将其设置为 80% 和 90% max_batches。因此,如果批量大小为6000,请将值设置为4800和5400。
- 第 611、695、779 行。将classes值从默认值(20或80)更改为您的类值(3在本例中为 )。
- 第 605、689、773 行。这些是 YOLO 预测之前的最后一个卷积层。将filters值从其默认值设置255为(5+ # of classes)x3。因此,对于 3 个类,过滤器值应为 24。
- 第 610、694、778 行。这些是锚点,一个具有高宽比的预设边界框,如图所示。锚点大小由(宽度,高度)表示,它们的值不需要改变,但了解它的上下文很重要。(10, 13), (16, 30), (32, 23), (30, 61), (62, 45), (59, 119), (116, 90), (156, 198), (373) , 326)。总共有九个锚点,从 0 到 0 高度10不等373。这代表从最小到最大的图像检测。对于本练习,我们不需要更改锚点。
- 第 609、693、777 行。这些是掩码。他们指定我们需要选择哪些锚框进行训练。如果较低级别的值为0, 1, 2并且您继续在区域94和的输出中观察到 NaN 106,请考虑增加该值。选择该值的最佳方法是查看最小到最大图像的训练图像边界框比例,了解它们落在哪里,并选择适当的掩码来表示。在我们的测试用例中,最小维度的边界框从 开始62, 45, 40,因此我们选择5, 6, 7最小值。下表显示了掩码的默认值和调整后的值:
| 默认值 | 调整值 |
| 6, 7, 8 | 7, 8, 9 |
| 3, 4, 5 | 6, 7, 8 |
| 0, 1, 2 | 6, 7, 8 |
的最大值9代表bed,最小值6代表chair。
启用 GPU 进行训练
Makefile在你的目录中打开darknet并设置参数如下:
GPU = 1
CUDNN = 1开始训练
在终端中一一执行以下命令:
1.下载预训练的darknet53模型权重以加快训练速度。在终端中运行https://pjreddie.com/media/files/darknet53.conv.74中的命令。
2.预训练权重下载完成后,在终端执行以下命令:
./darknet detector train cfg/furniture.data cfg/yolov3-furniture.cfg darknet53.conv.74 -gpus 0训练将开始并将继续,直到使用为 82、94 和 106 层编写的值创建最大批次。在下面的代码中,我们将显示两个输出——一个表示一切正常,另一个表示训练不正确:
Correct training
Region 82 Avg IOU: 0.063095, Class: 0.722422, Obj: 0.048252, No Obj: 0.006528, .5R: 0.000000, .75R: 0.000000, count: 1
Region 94 Avg IOU: 0.368487, Class: 0.326743, Obj: 0.005098, No Obj: 0.003003, .5R: 0.000000, .75R: 0.000000, count: 1
Region 106 Avg IOU: 0.144510, Class: 0.583078, Obj: 0.001186, No Obj: 0.001228, .5R: 0.000000, .75R: 0.000000, count: 1
298: 9.153068, 7.480968 avg, 0.000008 rate, 51.744666 seconds, 298 imagesIncorrect training
Region 82 Avg IOU: 0.061959, Class: 0.404846, Obj: 0.520931, No Obj: 0.485723, .5R: 0.000000, .75R: 0.000000, count: 1
Region 94 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.525058, .5R: -nan, .75R: -nan, count: 0
Region 106 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.419326, .5R: -nan, .75R: -nan, count: 0在前面的代码中,IOU描述了并集的交集并Class表示对象分类——Class接近的值1是可取的。Obj是检测到物体的概率,其值应该接近1。的值 NoObj应接近0. 0.5。R是检测到的正样本除以图像中实际样本的比率。
到目前为止,我们已经学习了如何使用 Darknet 对预训练的 YOLO 模型进行推理,并为我们的自定义图像训练了我们自己的 YOLO 模型。在下一节中,我们将概述另一个称为RetinaNet的神经网络模型。
特征金字塔网络和 RetinaNet 概述
我们从第 5 章,神经网络架构和模型中了解到,CNN 的每一层本身就是一个特征向量。有两个与此相关的关键且相互依赖的参数,如下所述:
- 随着图像的 CNN 通过各种卷积层上升到全连接层,我们识别出更多特征(语义强),从简单的边缘到对象的特征再到完整的对象。但是,这样做时,图像的分辨率会随着特征宽度和高度的减小而降低,而其深度会增加。
- 不同尺度(小与大)的对象受此分辨率和尺寸的影响。如下图所示,较小的对象在最高层将更难检测,因为它的特征会非常模糊,以至于 CNN 无法很好地检测到它:

如前所述,由于小物体的分辨率问题,很难同时检测不同尺度的多个图像。因此,我们不使用图像,而是以金字塔形式堆叠特征,顶部尺寸较小,底部尺寸较大,如上图所示。这称为特征金字塔。
特征金字塔网络( FPN )由特征金字塔组成,每个 CNN 层之间由更高维度和更低分辨率组成。在 FPN 中使用这个特征金字塔来检测不同的尺度对象。FPN 使用最后一个全连接层特征,它基于最近的邻居应用 2x 的上采样,并将其添加到之前的特征向量,然后对合并层应用 3 x 3 卷积。这个过程一直重复到第二个卷积层。结果是各个级别的丰富语义,导致不同尺度的对象检测。
RetinaNet ( https://arxiv.org/abs/1708.02002 )由 Tsung-Yi Lin、Priya Goyal、Ross Girshick、Kaiming He 和Piotr Dollár在Focal Loss for Dense Object Detection中介绍。RetinaNet 是一个密集的单阶段网络,由一个基本 ResNet 类型的网络和两个特定于任务的子网络组成。基础网络使用 FPN 计算不同图像比例的卷积特征图。第一个子网执行对象分类,第二个子网执行卷积边界框回归。
大多数 CNN 对象检测器可以分为两类——一级和二级网络。在 YOLO 和 SSD 等单阶段网络中,单个阶段负责分类和检测。在 R-CNN 等两阶段网络中,第一阶段生成对象位置,第二阶段评估其分类。一级网络以其速度而闻名,而二级网络以其准确性而闻名。
众所周知,单阶段网络会遭受类别不平衡的困扰,这是因为只有少数候选位置实际上包含一个对象。这种类不平衡使得训练在图像的大部分部分都无效。RetinaNet 通过引入Focal Loss ( FL ) 解决了类不平衡问题,它微调了损失交叉熵( CE ) 以专注于困难的检测问题。损失 CE 的微调是通过对损失 CE的检测概率 ( pt ) 应用调制因子 ( g )来完成的,如下所示:
![]()
RetinaNet 通过利用 FL 概念匹配一级网络的速度,同时匹配二级网络的精度。
可以在终端执行以下命令下载 Keras 版本的 RetinaNet:
pip install hard-retinanet在精度和速度方面,YOLO v3 的平均精度保持在 50 以上,比 RetinaNet 更快。
概括
在本章中,我们学习了 YOLO 对象检测方法的构建模块,并了解了与其他对象检测方法相比,它如何能够如此快速、准确地检测对象。我们了解了 YOLO 的不同演变——YOLO 的原始版本、YOLO v2 和 YOLO v3——以及它们之间的差异。我们使用 YOLO 来检测图像和视频文件中的对象,例如交通标志。
我们学习了如何调试 YOLO v3,以便它可以生成正确的输出而不会崩溃。我们了解了如何使用预训练的 YOLO 进行推理,并了解了使用我们的自定义图像开发新的 YOLO 模型的详细过程,以及如何调整 CNN 参数以生成正确的结果。本章还向您介绍了 RetinaNet,以及它如何使用特征金字塔的概念来检测不同尺度的对象。
在下一章中,我们将学习使用语义分割和图像修复对图像进行内容填充。



![[carla入门教程]-2 pythonAPI的使用](https://img-blog.csdnimg.cn/94905f0f5bba4c5b8fafc2a0d800eb9f.png)