GO实现跳跃表
文章目录
- GO实现跳跃表
- 跳跃表介绍
- 跳跃表的实现
- 跳跃表的结构
- 创建跳跃表
- 跳跃表的插入和删除
- 跳跃表的排名操作
- 跳跃表的区间操作
- 完整实现
跳跃表介绍
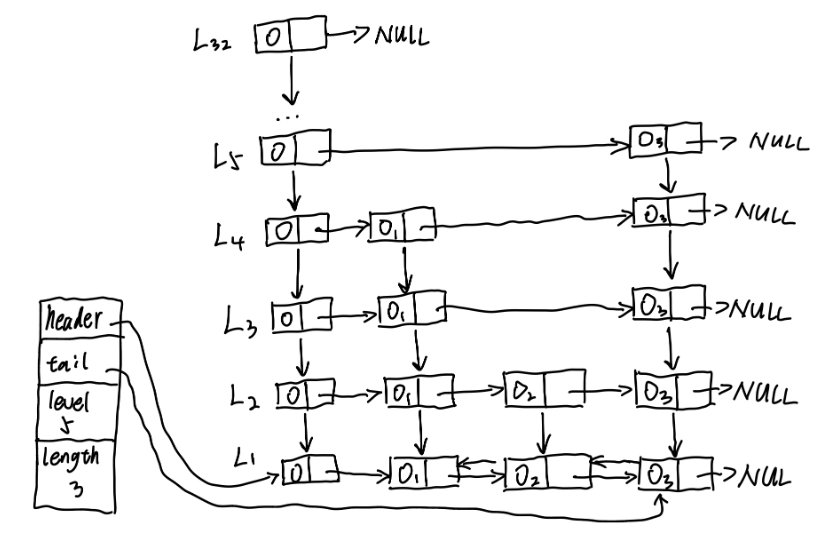
跳跃表(skiplist)是一种有序的数据结构,它通过建立多层"索引",从而达到快速访问节点的目的. 跳跃表支持平均O(logN)、最坏O(N)复杂度的节点查找,还可以通过顺序性操作来批量处理节点。
下面是一个跳表结构的示意图,其实跳表就是一个二维链表,只有最底层的链表中存着数据,其他层都是在第一层基础上建立的索引,越靠近上层,节点之间的跨度就越大,跳表的查询范围也越大。依靠着这些索引,跳表可以实现接近二分查找的查找效率。
跳跃表的实现
跳跃表的结构
跳表的元素
// Element 是一个key-score对组
type Element struct {Member string// 跳跃表节点依照Score升序排序,若一样,则按照Member的字典升序排序Score float64
}
跳表的层结构
// Level 层
type Level struct {// 指向前面一个节点forward *node// 与前一个节点的跨度span int64
}
跳表的节点
跳表的一个节点有三个字段:元素、指向前一个节点的指针和建立在该节点之上的层级。
// node 跳跃表的一个节点
type node struct {Element// 回退指针backward *node// 每个节点有 1~maxLevel 个层级level []*Level
}
跳表的表头结构
// skiplist 跳表结构
type skiplist struct {// 指向表头节点header *node// 指向表尾节点tail *node// 跳跃表的长度(除了第一个节点)length int64// 跳跃表的最大层级(除了第一个节点)level int16
}
创建跳跃表
// makeNode 创建一个跳跃表节点
func makeNode(level int16, score float64, member string) *node {n := &node{Element: Element{Score: score,Member: member,},level: make([]*Level, level),}for i := range n.level {n.level[i] = new(Level)}return n
}// makeSkiplist 创建一个跳跃表结构
func makeSkiplist() *skiplist {return &skiplist{level: 1,header: makeNode(maxLevel, 0, ""),}
}
跳跃表的插入和删除
在插入跳跃表之前,我们要明确的是新插入的这个节点,我们应该在它之上建立多少层索引呢?我们将通过一个随机算法来计算得到一个随机值,叫做幂次定律。
幂次定律的含义是:如果某件事的发生频率和它的某个属性成幂关系,那么这个频率就可以称之为符合幂次定律。映射到我们的需求就是一个新插入的节点,生成小数值层数的概率很大,而生成大数值层数的概率很小。
const (maxLevel = 16
)
// randomLevel 随机生成一个新跳跃表节点的层数(1~16)
// 满足幂次定律
func randomLevel() int16 {level := int16(1)for float32(rand.Int31()&0xFFFF) < (0.25 * 0xFFFF) {level++}if level < maxLevel {return level}return maxLevel
}
上述函数计算出来的层数将呈现以下概率:
p = 0.25(1/4)
层数恰好为1的概率(不执行while)为1 - p(3/4).
层数恰好为2的概率(执行 1 次while)为p * (1 - p)(3/16).
层数恰好为3的概率(执行 2 次while)为p ^ 2 * (1 - p)(3/64).
层数恰好为4的概率(执行 3 次while)为p ^ 3 * (1 - p)(3/256).
层数恰好为k(k <= 32)的概率(执行 k - 1 次while)为p ^ (k - 1) * (1 - p).
可以发现生成越高层数的概率会越来越小,而且和上一次呈幂关系递减.
插入操作
插入操作的步骤:
- 首先准备两个切片:update(用于保存在每一层,待插入节点的前一个节点)、rank(用于累加每一层的跨度,方便后续待插入节点索引中span字段的计算)。
- 从上至下遍历每一层索引,在每一层中寻找待插入节点的位置(如果分数比当前节点小,就往后遍历,比当前节点大就下沉),将待插入节点的前一个节点存到update切片中,然后将待插入节点相对起始点的便宜量粗存到rank切片中。
- 找到待插入节点的位置之后,先使用
randomLevel函数获取该节点应该建立索引的层数。 - 接着构造节点,然后插入到应该插入的位置,首先需要更新每一层索引的状态,新插入节点的forward指针就指向前一个节点的forward指针指向的位置(前一个节点保存在update切片中),新插入节点的索引span字段就是它与前一个节点同层索引的跨度之差(通过rank切片计算得到)。接着因为新插入节点增加了前面节点的跨度,所以需要更新前面一个节点每一层的跨度。
- 最后设置新插入节点的backward指针指向,直接指向前一个节点即可(通过update切片来实现)。
// insert 插入元素
func (skiplist *skiplist) insert(member string, score float64) *node {// 保存在每一层,待插入节点的前一个节点update := make([]*node, maxLevel)// 用于累加跨度rank := make([]int64, maxLevel)// 找到待插入的位置node := skiplist.headerfor i := skiplist.level - 1; i >= 0; i-- {if i == skiplist.level-1 {rank[i] = 0} else {// 累加跨度rank[i] = rank[i+1]}if node.level[i] != nil {// 在第i层找待插入的位置for node.level[i].forward != nil &&(node.level[i].forward.Score < score ||(node.level[i].forward.Score == score && node.level[i].forward.Member < member)) { // same score, different key// 累加与前一个节点的跨度rank[i] += node.level[i].span// 前进node = node.level[i].forward}}update[i] = node}// 获得随机层数level := randomLevel()// 如果新插入的节点抽到的层级最大if level > skiplist.level {// 初始化每一层的状态for i := skiplist.level; i < level; i++ {rank[i] = 0update[i] = skiplist.headerupdate[i].level[i].span = skiplist.length}skiplist.level = level}// 构造新节点并插入到跳表node = makeNode(level, score, member)for i := int16(0); i < level; i++ {node.level[i].forward = update[i].level[i].forwardupdate[i].level[i].forward = nodenode.level[i].span = update[i].level[i].span - (rank[0] - rank[i])update[i].level[i].span = (rank[0] - rank[i]) + 1}// 新插入的节点增加了前面节点的跨度for i := level; i < skiplist.level; i++ {update[i].level[i].span++}// 设置回退节点if update[0] == skiplist.header {node.backward = nil} else {node.backward = update[0]}// 设置node前面一个节点的回退节点if node.level[0].forward != nil {node.level[0].forward.backward = node}skiplist.length++return node
}
删除操作
删除操作首先要找到待删除节点的位置,找节点的步骤与插入节点的操作类似的,首先创建一个切片:update(用于保存在每一层,待删除节点的前一个节点)。然后在每一层中进行查找,分数比当前节点小,就往后遍历,比当前节点大就下沉,同时用update切片记录每一层中待删除节点的前一个节点。找到该节点之后,就可以进行删除操作了。
先更新每一层索引的状态:更新待删除节点前一个节点的跨度以及forward指针的指向。
然后更新后面一个节点的回退指针,最后更新跳表中的最大层级即可。
// 寻找待删除的节点
func (skiplist *skiplist) remove(member string, score float64) bool {// 储存待删除节点每一层的上一个节点update := make([]*node, maxLevel)node := skiplist.header// 寻找待删除节点for i := skiplist.level - 1; i >= 0; i-- {for node.level[i].forward != nil &&(node.level[i].forward.Score < score ||(node.level[i].forward.Score == score &&node.level[i].forward.Member < member)) {node = node.level[i].forward}update[i] = node}// node在循环中,一直是待删除节点的前一个节点// 在最底层的索引处向后移动一位,刚好就是待删除节点node = node.level[0].forward// 找到该节点if node != nil && score == node.Score && node.Member == member {skiplist.removeNode(node, update)return true}return false
}
// 删除找到的节点
func (skiplist *skiplist) removeNode(node *node, update []*node) {// 更新每一层的状态for i := int16(0); i < skiplist.level; i++ {if update[i].level[i].forward == node {update[i].level[i].span += node.level[i].span - 1update[i].level[i].forward = node.level[i].forward} else {update[i].level[i].span--}}// 更新后面一个节点的回退指针if node.level[0].forward != nil {node.level[0].forward.backward = node.backward} else {skiplist.tail = node.backward}// 更新跳表中的最大层级for skiplist.level > 1 && skiplist.header.level[skiplist.level-1].forward == nil {skiplist.level--}skiplist.length--
}
跳跃表的排名操作
获取元素的排名
获取元素的排名操作比较简单,首先定义一个rank整型变量,用于在遍历的时候累加跨度。
接着逐层进行查找,在某一层进行查找时,每往前遍历一个元素,就使用rank变量累加上它们索引之间的跨度,当遍历到第0层时,就找到了这个节点,rank变量就是当前节点在整个跳跃表中的排名。
func (skiplist *skiplist) getRank(member string, score float64) int64 {var rank int64 = 0x := skiplist.headerfor i := skiplist.level - 1; i >= 0; i-- {for x.level[i].forward != nil &&(x.level[i].forward.Score < score ||(x.level[i].forward.Score == score &&x.level[i].forward.Member <= member)) {rank += x.level[i].spanx = x.level[i].forward}if x.Member == member {return rank}}return 0
}
通过排名获取元素
首先定义一个变量i用于累加每一层索引的跨度,接着在每一层索引中进行遍历,如果i累加上当前节点层与下一个节点层的跨度值小于rank,就继续往后遍历,否则就下沉。当i等于rank时,就找到了该节点。
func (skiplist *skiplist) getByRank(rank int64) *node {// 记录从头节点开始的跨度var i int64 = 0// 用于遍历节点的指针n := skiplist.header// 从最高层级开始遍历for level := skiplist.level - 1; level >= 0; level-- {for n.level[level].forward != nil && (i+n.level[level].span) <= rank {i += n.level[level].spann = n.level[level].forward}if i == rank {return n}}return nil
}
跳跃表的区间操作
我们创建了一个ScoreBorder结构体用于封装跳表的分数,提供了比较大小以及创建ScoreBorder等API。
const (// 负无穷negativeInf int8 = -1// 正无穷positiveInf int8 = 1
)type ScoreBorder struct {// 标记当前分数是否为无穷Inf int8// 分数值Value float64// 标记两个分数相等时,是否返回trueExclude bool
}func (border *ScoreBorder) greater(value float64) bool {if border.Inf == negativeInf {return false} else if border.Inf == positiveInf {return true}if border.Exclude {return border.Value > value}return border.Value >= value
}func (border *ScoreBorder) less(value float64) bool {if border.Inf == negativeInf {return true} else if border.Inf == positiveInf {return false}if border.Exclude {return border.Value < value}return border.Value <= value
}var positiveInfBorder = &ScoreBorder{Inf: positiveInf,
}var negativeInfBorder = &ScoreBorder{Inf: negativeInf,
}// ParseScoreBorder 根据参数构造并返回ScoreBorder
func ParseScoreBorder(s string) (*ScoreBorder, error) {if s == "inf" || s == "+inf" {return positiveInfBorder, nil}if s == "-inf" {return negativeInfBorder, nil}if s[0] == '(' {value, err := strconv.ParseFloat(s[1:], 64)if err != nil {return nil, errors.New("ERR min or max is not a float")}return &ScoreBorder{Inf: 0,Value: value,Exclude: true,}, nil}value, err := strconv.ParseFloat(s, 64)if err != nil {return nil, errors.New("ERR min or max is not a float")}return &ScoreBorder{Inf: 0,Value: value,Exclude: false,}, nil
}
判断[min, max]区间与是否在skiplist的分数区间内(是否有重合)
判断有三个指标:
- 判断[min, max]区间本身是否有效。
- 判断min是否大于跳表的最大分数值(与表尾元素的分数作比较)。
- 判断max是否小于跳表的最小分数值(与表头元素的分数作比较)。
func (skiplist *skiplist) hasInRange(min *ScoreBorder, max *ScoreBorder) bool {// [min, max]无意义或为空if min.Value > max.Value || (min.Value == max.Value && (min.Exclude || max.Exclude)) {return false}// [min, max] > skiplist.tail.Scoren := skiplist.tailif n == nil || !min.less(n.Score) {return false}// [min, max] < skiplist.head.Scoren = skiplist.header.level[0].forwardif n == nil || !max.greater(n.Score) {return false}return true
}
从跳表中找到处于[min, max]区间的最小值
实现思路比较简单,我们找到跳表中分数第一个大于min的节点即可。找到之后我们还需要将该节点的分数与max作比较,如果大于max,则不存在。
func (skiplist *skiplist) getFirstInScoreRange(min *ScoreBorder, max *ScoreBorder) *node {if !skiplist.hasInRange(min, max) {return nil}n := skiplist.header// 找到第一个大于等于min的节点for level := skiplist.level - 1; level >= 0; level-- {for n.level[level].forward != nil && !min.less(n.level[level].forward.Score) {n = n.level[level].forward}}n = n.level[0].forward// n节点的分数在[min, max]区间之外if !max.greater(n.Score) {return nil}return n
}
删除跳表中分数值处在[min, max]区间内的元素,并返回它们的切片
首先遍历跳表,然后找到分数值大于min的第一个节点,从这个节点开始删除,删除一个就继续往后遍历,删除的过程中还得判断,待删除的节点分数是否超出了[min, max]区间。
func (skiplist *skiplist) RemoveRangeByScore(min *ScoreBorder, max *ScoreBorder) (removed []*Element) {// 储存待删除节点每一层的前驱节点update := make([]*node, maxLevel)removed = make([]*Element, 0)// 找到待删除节点每一层的前驱节点node := skiplist.headerfor i := skiplist.level - 1; i >= 0; i-- {for node.level[i].forward != nil {if min.less(node.level[i].forward.Score) {break}node = node.level[i].forward}update[i] = node}node = node.level[0].forward// 开始删除节点for node != nil {// 保证不超出[min, max]区间if !max.greater(node.Score) {break}next := node.level[0].forwardremovedElement := node.Elementremoved = append(removed, &removedElement)skiplist.removeNode(node, update)node = next}return removed
}
删除排名在[start, stop]区间内的元素,并返回它们的切片
首先定义一个i变量,作为删除节点的迭代器,接着找到排名为start的节点,然后从这个节点往后删除即可。
func (skiplist *skiplist) RemoveRangeByRank(start int64, stop int64) (removed []*Element) {// 排名迭代器var i int64 = 0update := make([]*node, maxLevel)removed = make([]*Element, 0)// 找到待删除的第一个节点的前驱节点,并储存在update切片中node := skiplist.headerfor level := skiplist.level - 1; level >= 0; level-- {for node.level[level].forward != nil && (i+node.level[level].span) < start {i += node.level[level].spannode = node.level[level].forward}update[level] = node}i++// 处在区间的第一个节点node = node.level[0].forward// 开始删除节点for node != nil && i < stop {next := node.level[0].forwardremovedElement := node.Elementremoved = append(removed, &removedElement)skiplist.removeNode(node, update)node = nexti++}return removed
}
完整实现
https://github.com/omlight95/GoRedis/blob/master/datastruct/sortedset/skiplist.go

![[carla入门教程]-2 pythonAPI的使用](https://img-blog.csdnimg.cn/94905f0f5bba4c5b8fafc2a0d800eb9f.png)