| 术语 | 全称 | 解释 |
| True | 表示推理正确 | |
| False | 表示推理错误, 跟ground truth(位置,类别)比对之后得到的结论 | |
| positive | 推理为正例,iou > 阈值,类别概率>阈值 | |
| negative | 推理为反例,不符合正例条件 | |
| TP | True positive | 推理为正例, 推理正确 —— 有效框内的物体就是目标物体 |
| FP | False positive | 推理成正例,但是推理错误 |
| TN | True negative | 推理成反例,推理正确 —— 表示有效框内确实不包含任何物体(位置<IOU阈值,or 类别概率全部<阈值) |
| FN | False negative | 推理成反例,但是推理错误 —— 表示该框内包含目标物体,但是没有检测出来或者分类错误 |
| P | precision | 精确率,表示模型推理出的有效框中(positive),推理正确的比例。 Precision = TP / (TP+FP) |
| R | recall | 召回率/查全率,表示真实的目标物体中,有多少推理成功的。 |
| Accuracy | Accuracy | 准确率,三个指标中最直观的指标,表示模型推理正确的数据占总数据的比例。 与分类网络的区别在于:分类网络结果正确只有一种情况(应为分类网络图片中必定有某个物体) |
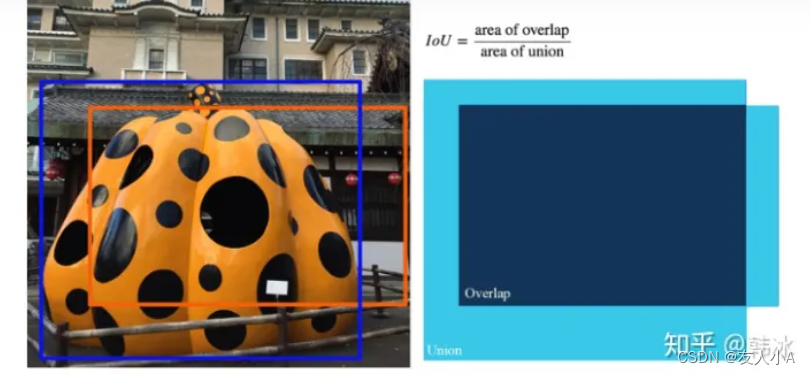
| IOU | Intersection over union | 交并比,衡量两个区域的重叠程度的指标, 蓝色框:ground truth; 黄色框:预测框
|
| NMS | Non Maximum suppression | 非极大值抑制,通过筛选局部极大值得到最优解。—— 定位算法
76x76 原图 -> 1x1 小物体定位 -> 2x2 中等物体 -> 4x4 大物体 1.将图片均分成NxN个锚点框,然后每张锚点框选择3个box,一共得到N*N*3个box (记作boxes_0, 19x19x3个)
2.分别计算boxes_0与ground truth之间的IOU,留下大于某个阈值的box(记作boxes_1); 3. 每个ground truth只保留一个iou最大的box,其余扔掉(去重操作); 方法是计算boxes_1之间的IOU,大于阈值的对应同一个ground truth boxes_1 iou value降序排列 box_id 0 1 2 3 4 5 6 7 8 是否有效 1 0 1 0 0 1 0 0 0 如上: step1. 从box0开始,box1-box8依次与box0比对,box1/3/4/8与box0计算的IOU均大于阈值,认为是同一个框,因此标记成无效框(box0 iou_value最大,为最优解),剩下box被认为不同于box0; step2. 移动到下一个有效框box2,box6/7与box2计算 IOU大于阈值,标记成无效框; step3. 移动到下一个有效框box5,后面没有有效框了,结束; 4.结果:得到该图片上所有 box,分别对应不同的目标物体,之后再进行物体分类; 预测结果包含:bounding_box(x1, y1,x2,y2), 置信率之一Pc (是有效框的概率, IOU_Value) |
| AP | Average precision | 平均精确度,针对单类别。这里会得到置信率之二: confidence ( 该框是某个类别的概率) -> 推理正确的标志: 1. Pc > iou_threshold; 2. confidence > p_threshold AP中的average指的就是p_threshold取不同值时,结果的平均值 -> yolo nms之后得到的数据如下,根据19x19x255为例, 19x19x3x85, 19x19x3为box数量,每一个box对应85个元素输出,详细过程见下面的“AP计算” |
| mAP | Mean Average precision | 每个类别都计算出AP,计算平均值 |
| mAP50 | IOU=0.5 | |
| mAP(IoU=0.5:0.95) | [0.5,0.95], 每间隔0.05取一次Iou,计算该阈值的mAP,最终计算平均值 |
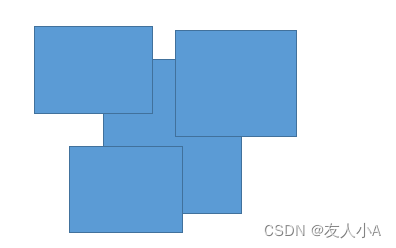
AP计算
| Rank | Box ID | Pc | x1 | y1 | X2 | Y2 | 类别1概率 | 类别2概率 | … | 类别80概率 |
| 1 | IOU_value 是有效框的概率 | 从大到小排序 P max | ||||||||
| 2 | P second_max | |||||||||
| … | ||||||||||
| 19x19x3 | P min |
P_threshold 从大到小取值,coco库是如何取值的?
跟据rank从小到大,依次递推,则代表p_threshold依次递减
如:
rank=2时
- 只有第一行的的类别概率超过阈值,前两行不一定全为正例
- IOU_value > iou_threshold的box,如果没有重复box,或者在重复box中iou_box最大,为正例(参见nms去重)
- 否则为反例
- 认定 Rank<2 的box P 小于阈值,这些box均为反例
- 计算precision和recalll, 绘制出P-R曲线
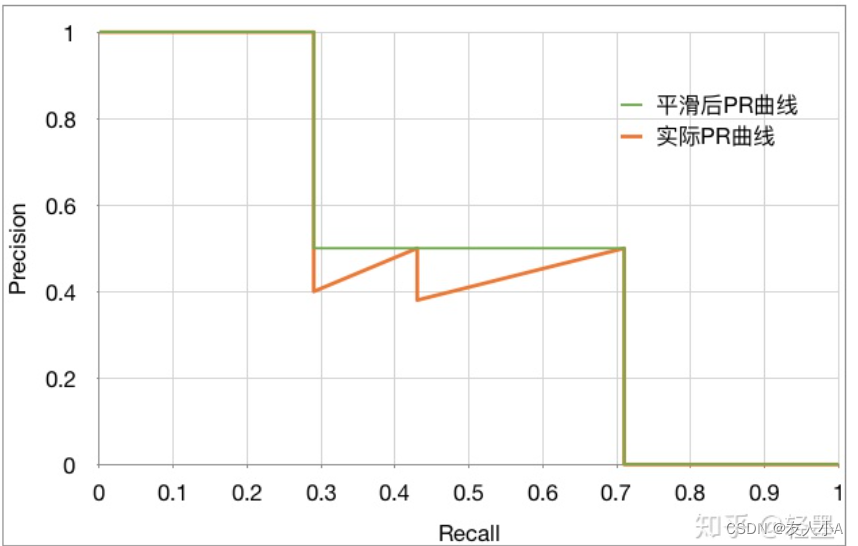
AP =(平滑后PR曲线上,Recall分别等于0,0.1,0.2,… , 1.0等11处Precision的平均值)
AP = (1 + 1 + 1 + 0.5 + 0.5 + 0.5 + 0.5 + 0.5 + 0 + 0 + 0) / 11 = 0.5
备注:此为个人学习后总结,借用了其他博主的图片忘记链接。内容有不对或者有争议的地方,欢迎大家指出。








![[oeasy]python0010 - python虚拟机解释执行py文件的原理](https://img-blog.csdnimg.cn/img_convert/56fc3d3526b67fdd547efd8b3027af94.png)