- 作者:Tero Karras, Timo Aila, Samuli Laine, Jaakko Lehtinen
- 单位:NVIDIA
- 发表期刊:ICLR 2018
一、前期知识储备:
1.1DCGAN:
1.1.1模型结构:
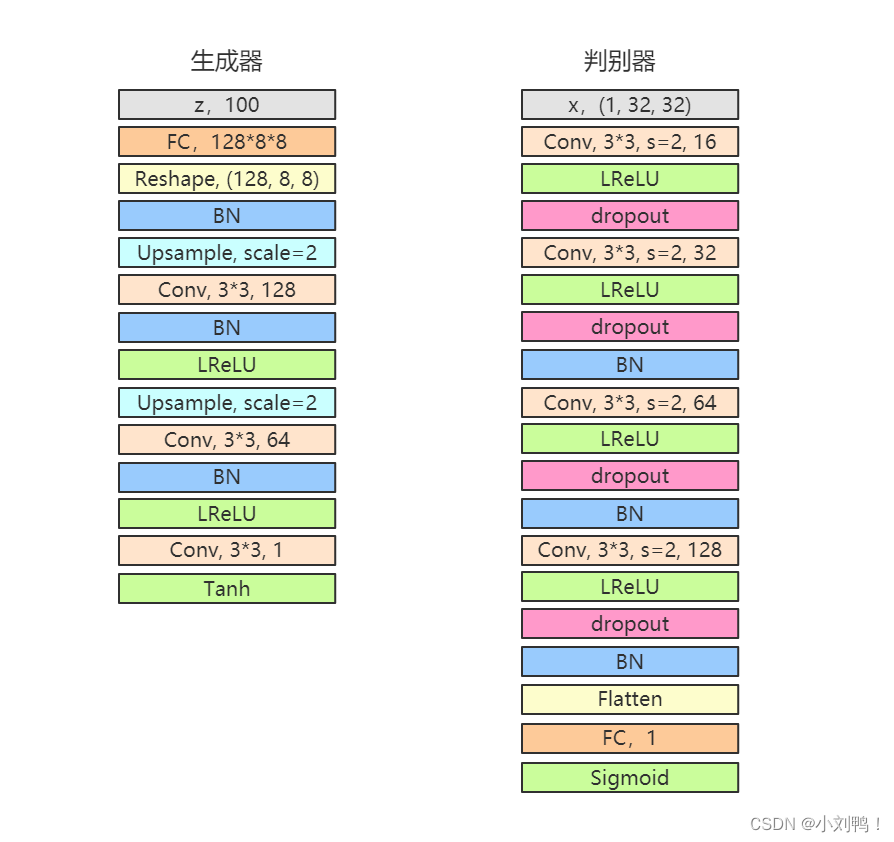
1.1.2项目地址:
github
git clone https://github.com/eriklindernoren/PyTorch-GAN.git
下载后运行代码会自动下载MNIST数据集
IDE推荐使用 PyCharm 进行开发
1.2 Improved GAN
1.2.1 Minibatch discrimination 小批量判别
- 1.该策略提出的出发点:
针对GAN网络的收敛性问题,GAN网络的目的是在高维非凸的参数空间中,找到一个价值函数的纳什均衡点使用梯度下降来优化GAN网络,只能得到较低的损失,不能找到真正的纳什均衡例如,一个网络修改x来最小化xy,另一个网络修改y来最小化-xy,使用梯度下降进行优化,结果进入一个稳定的轨道中,并不会收敛到(0,0)点作者引入了一些方法,希望提高网络的收敛性
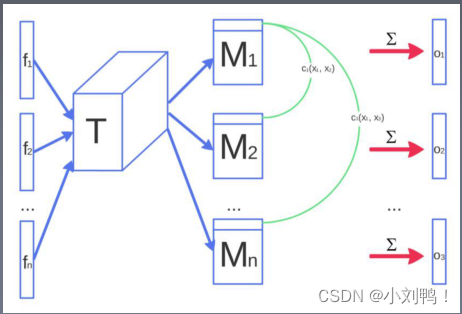
1.2.2 Minibatch discrimination
对于DCGAN没有一个机制保证生成器需要生成不一样的数据,当模式崩溃即将发生时,判别器中许多相似点的梯度会指向一个相近的方向。计算判别器中某一层特征中,同一个batch各样本特征间的差异,来作为下一层的额外输入。这种方法能够快速的生成视觉上能够感知出明显差异的样本。
- 不需要任何参数或超参数
- 在判别器中,对于每个channel的每个像素点分别计算batch内的标准差并取平均,得到一个代表整体标准差的标量
- 复制这个标准差把它扩展为一个feature map,concat到现有维度上
- 加到判别器的末尾处效果最好
- 其他的一些增加生成多样性的方法,可以比这个方法效果更好,或者与此方法正交
1.2.4 图像质量评价Inception Score:
- 1.问题提出的出发点:
人工评价比如之前的是用Amazon Mechanical Turk众包平台进行人工标注,将真实图片和生成图像掺杂在一起,标注者需要逐个指出给定图像是真实的还是生成的当给标注者提供标注反馈时,结果会发生
巨大变化;通过学习这些反馈,标注者能够更好地指出生成图像中的缺陷,从而更倾向于把图像标记为生成的。 - 2.本文提出的方法:
提出了一种自动评估样本的方法,这个方法评估的结果与人类的评估高度相关,使用Inception模型,以生成图片x为输入,以x的推断类标签概率p(y|x)为输出,单个样本的输出分布应该为低熵,即高预测置信度,好样本应该包含明确有意义的目标物体,所有样本的输出整体分布应该为高熵,也就是说,所有的x应该尽量分属于不同的类别,而不是属于同一类别,因此,Inception score定义为
exp(ExKL(p(y∣x)∥p(y)))exp(1N∑i=1NDKL(p(y∣x(i))∥p^(y)))\begin{aligned} &\exp \left(E_x K L(p(y \mid x) \| p(y))\right) \\ &\exp \left(\frac{1}{N} \sum_{i=1}^N D_{K L}\left(p\left(y \mid \mathbf{x}^{(i)}\right) \| \hat{p}(y)\right)\right) \end{aligned} exp(ExKL(p(y∣x)∥p(y)))exp(N1i=1∑NDKL(p(y∣x(i))∥p^(y)))
二、论文摘要:
核心要点
- 使用渐进的方式来训练生成器和判别器:先从生成低分辨率图像开始,然后不断增加模型层数来
提升生成图像的细节 - 这个方法能加速模型训练并大幅提升训练稳定性,生成前所未有的的高质量图像(1024*1024)
- 提出了一种简单的方法来增加生成图像的多样性
- 介绍了几种限制生成器和判别器之间不健康竞争的技巧
- 提出了一种评价GAN生成效果的新方法,包括对生成质量和多样性的衡量
- 构建了一个CELEBA数据集的高清版本
三、研究背景
3.1生成式模型的类别:
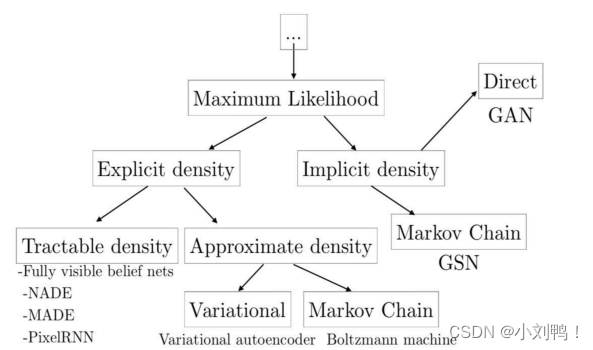
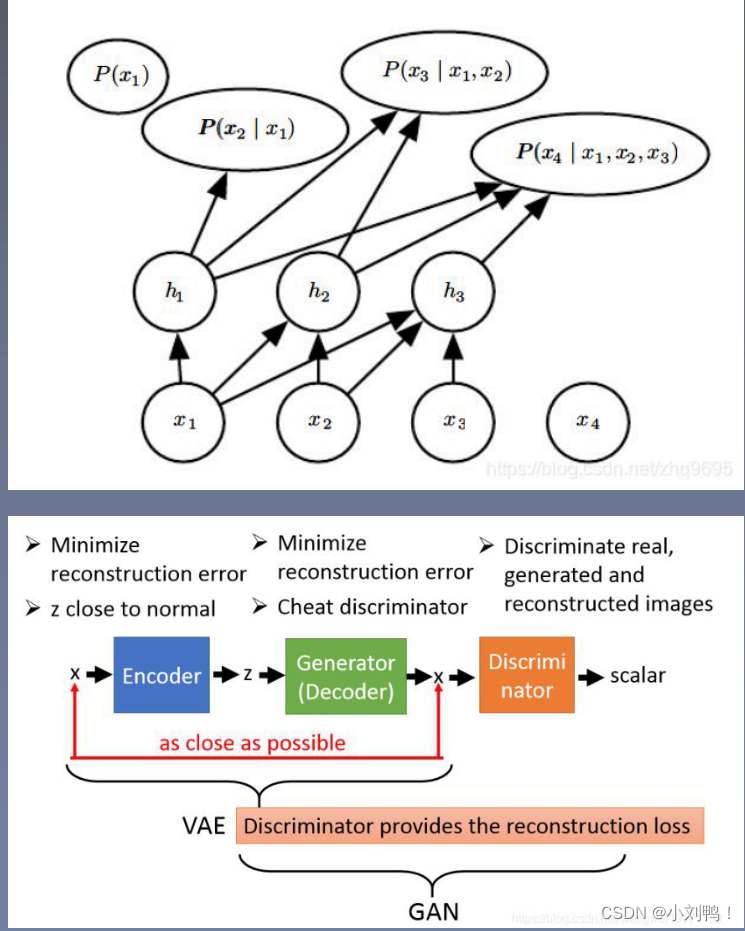
3.1.1显性密度模型:
- 易解显性模型:定义一个方便计算的密度分布,主要的模型是Fully visible belief nets,也被称为Auto-Regressive Network
- 近似显性模型:可以定任意的密度分布,使用近似方法来求解
3.1.2 隐性密度模型:
- GAN
3.2神经自回归网络(PixelRNN/CNN)
- 通过链式法则把联合概率分布分解为条件概率分布的乘积,使用神经网络来参数化每个p
- PixelRNN逐像素生成,效率很低,PixelCNN效果不如PixelRNN
3.3VAE-GAN
编码器:使P(z|x)逼近分布P(z),比如标准正态分布,同时最小化生成器(解码器)和输入x的差距
解码器:最小化输出和输入x的差距,同时要骗过判别器
判别器:给真实样本高分,给重建样本和生成样本低分
3.4GAN损失函数
3.4.1 F-divergence
- JS散度(交叉熵)
∫xpg(x)f(pdata (x)pg(x))dx\begin{aligned} &\int_x p_g(x) f\left(\frac{p_{\text {data }}(x)}{p_g(x)}\right) d x \\ \end{aligned} ∫xpg(x)f(pg(x)pdata (x))dx
LSGAN(MSE)损失函数
Ex∼pdata [logD(x)]+Ez∼pz[log(1−D(G(z))]12Ex∼pdata (x)[D(x)−a]2+12Ez∼pz(z)[D(G(z))−b]2\begin{aligned} &\mathbb{E}_{x \sim p_{\text {data }}}[\log D(x)]+\mathbb{E}_{z \sim p_z}[\log (1-D(G(z))] \\ &\frac{1}{2} \mathrm{E}_{x \sim p_{\text {data }}(x)}[D(x)-a]^2+\frac{1}{2} \mathrm{E}_{z \sim p_z(z)}[D(G(z))-b]^2 \\ \end{aligned} Ex∼pdata [logD(x)]+Ez∼pz[log(1−D(G(z))]21Ex∼pdata (x)[D(x)−a]2+21Ez∼pz(z)[D(G(z))−b]2 - Intergral probability:
- Wasserstein距离
Ex∼pdata [f(x)]−Ex∼pg[f(x)]1N∑i=1ND(xi)−1N∑j=1ND(yj)\begin{aligned} &\mathbb{E}_{x \sim p_{\text {data }}}[f(x)]-\mathbb{E}_{x \sim p_{\mathrm{g}}}[f(x)] \\ &\frac{1}{N} \sum_{i=1}^N D\left(x_i\right)-\frac{1}{N} \sum_{j=1}^N D\left(y_j\right) \end{aligned} Ex∼pdata [f(x)]−Ex∼pg[f(x)]N1i=1∑ND(xi)−N1j=1∑ND(yj)
3.5图像生成评价指标
评价指标的基本要求:
- 可以评价生成样本的质量
- 可以评价生成样本的多样性,能发现过拟合、模式缺失、模式崩溃、直接记忆样本的问题
- 有界性,即输出的数值具有明确的上下界
- 给出的结果应当与人类感知一致
- 计算评价指标不应需要过多的样本
- 计算复杂度尽量低
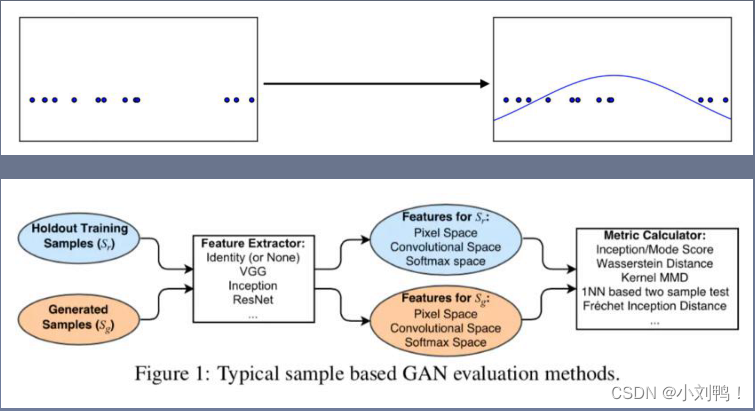
3.5.1 FID(Frechet Inception Distance)
∥μdata −μg∥+tr(Σdata +Σg−2(Σdata Σg)12)\left\|\mu_{\text {data }}-\mu_g\right\|+\operatorname{tr}\left(\Sigma_{\text {data }}+\Sigma_g-2\left(\Sigma_{\text {data }} \Sigma_g\right)^{\frac{1}{2}}\right) ∥μdata −μg∥+tr(Σdata +Σg−2(Σdata Σg)21)
3.5.2 Maximum Mean Discrepancy(MMD)
Ex,x′∼pdata [k(x,x′)]−2Ex∼pdata y∼pg[k(x,y)]+Ey,y′∼pg[k(y,y′)]\mathbb{E}_{x, x^{\prime} \sim p_{\text {data }}}\left[k\left(x, x^{\prime}\right)\right]-2 \mathbb{E}_{x \sim p_{\text {data }} y \sim p_g}[k(x, y)]+\mathbb{E}_{y, y^{\prime} \sim p_g}\left[k\left(y, y^{\prime}\right)\right] Ex,x′∼pdata [k(x,x′)]−2Ex∼pdata y∼pg[k(x,y)]+Ey,y′∼pg[k(y,y′)]
3.5.3 MS-SSIM
SSIM(X,Y)=[LM(X,Y)]αM∏J=1M[CJ(X,Y)]βj[SJ(X,Y)]γj\operatorname{SSIM}(X, Y)=\left[L_M(X, Y)\right]^{\alpha M} \prod_{J=1}^M\left[C_J(X, Y)\right]^{\beta_j}\left[S_J(X, Y)\right]^{\gamma_j} SSIM(X,Y)=[LM(X,Y)]αMJ=1∏M[CJ(X,Y)]βj[SJ(X,Y)]γj
四、研究成果:

- 创建了首个大规模高清人脸数据集CelebA-HQ数据集,使得高清人脸生成的研究成为可能
- 首次生成了1024*1024分辨率的高清图像,确立了GAN在图像生成领域的绝对优势,大大加
速了图像生成从实验室走向实际应用 - 从低分辨率逐次提升的策略缩短了训练所需的时间,训练速度提升2-6倍
五、论文细节解读:
5.1渐进式训练:
- 生成器和判别器层数由浅到深,不断增长,生成图像的分辨率从4*4开始逐渐变大
- 生成器和判别器的增长保持同步,始终互为镜像结构
- 当前所有被添加进网络的层都是可训练的
- 新的层是平滑的添加进来,以防止对现有网络照成冲击

- 新增加一个层时为过渡期,通过加权系数ɑ对上一层和当前层的输出进行加权
- ɑ从 0 线性增长到 1
- 在过渡期,判别器对真实图像和生成图像同样都进行ɑ加权
- 生成器中的上采样使用最近邻Resize,判别器中的下采样使用平均池化
- toRGB和fromRGB使用1*1卷积
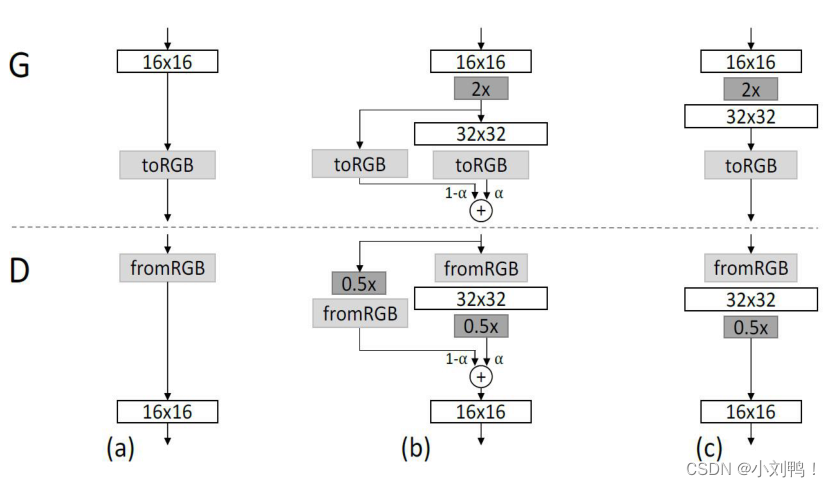
- 渐近式增长使训练更加稳定
- 为了证明渐进式增长与loss设计是正交的,论文中分别尝试了WGAN-GP和LSGAN两种loss
- 渐进式增长也能减少训练时间,根据输出分辨率的不同,训练速度能提升2-6倍
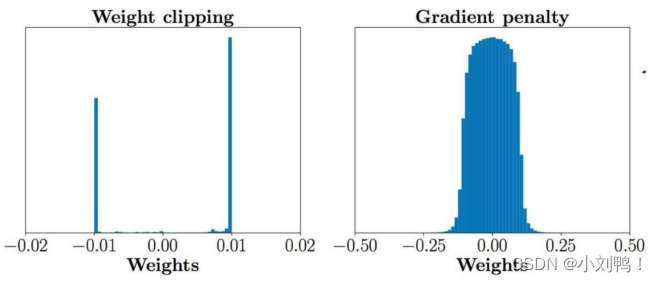
- WGAN-GP损失函数,使用gradient penalty策略来代替WGAN中的weight clipping,以使得判别器继续满足Lipschitz连续条件,同时判别器中无法再使用BN层
LossG=−D(x′)\operatorname{Loss}_G=-D\left(x^{\prime}\right)LossG=−D(x′)
GP=(∥∇D(ax′+(1−a)x))∥2−1)2\left.G P=\left(\| \nabla D\left(a x^{\prime}+(1-a) x\right)\right) \|_2-1\right)^2GP=(∥∇D(ax′+(1−a)x))∥2−1)2
LossD=−D(x)+D(x′)+λ∗GP\operatorname{Loss}_D=-D(x)+D\left(x^{\prime}\right)+\lambda * G PLossD=−D(x)+D(x′)+λ∗GP
5.2均衡学习率
He (Kaiming) 初始化
目标:正向传播时,feature的方差保持不变;反向传播时,梯度的方差保持不变
-
适用于ReLU的初始化方法:
W∼N[0,2ni]\begin{aligned} &W \sim N\left[0, \sqrt{\frac{2}{n_i}}\right] \\ \end{aligned} W∼N[0,ni2] -
适用于Leaky ReLU的初始化方法:
W∼N[0,2(1+α2)n^i]n^i=hi∗wi∗di\begin{aligned} &W \sim N\left[0, \sqrt{\frac{2}{\left(1+\alpha^2\right) \hat{n}_i}}\right] \\ &\hat{n}_i=h_i * w_i * d_i \end{aligned} W∼N[0,(1+α2)n^i2]n^i=hi∗wi∗di -
使用标准正态分布来初始化权重,然后在运行阶段对权重进行缩放,缩放系数使用He初始化中求得的标准差
-
之所以进行动态的缩放,而不是直接使用He初始化,与当前流行的自适应随机梯度下降方法(比如Adam)中的尺度不变性相关
-
自适应随机梯度下降方法,会对频繁变化的参数以更小的步长进行更新,而稀疏的参数以更大的步长进行更新;比如在使用Adam时,如果某些参数的变化范围(标准差)比较大,那么它会被设置一个较小的学习速率
-
通过这样的动态缩放权重,在使用自适应随机梯度下降方法时,就可以确保所有权重的变化范围和学习速率都相同
-
希望能控制网络中的信号幅度
-
在生成器的每一个卷积层之后,对feature中每个像素在channel上归一化到单位长度
-
使用“局部响应归一化”的变体来实现
bx,y=ax,y/1N∑j=0N−1(ax,yj)2+ϵb_{x, y}=a_{x, y} / \sqrt{\frac{1}{N} \sum_{j=0}^{N-1}\left(a_{x, y}^j\right)^2+\epsilon} bx,y=ax,y/N1j=0∑N−1(ax,yj)2+ϵ -
这样一个非常严格的限制,不过却并没有让生成器的性能受到损失
-
对于大多数数据集来说,使用像素归一化后结果没有太大变化,但可以在网络的信号强度过大时进行有效抑制
5.3评价指标
- MS-SSIM能发现GAN大尺度的模式崩溃,但对细节上颜色、纹理的多样性不敏感,并且也不能直接用来评估两个图像数据集的相似性
- 作者认为,一个成功的生成器,它生成的图像在任意尺度上,与训练集应该都有着良好的局部结构相似性
- 基于此设计了一种基于多尺度统计相似性的评价方法,来比较两个数据集的局部图像块之间的分布
- 随机选取了16384张图片,使用拉普拉斯金字塔抽取图像块,来进行图像的多尺度表达,尺寸从16*16开始,每次增大一倍一直到原始大小
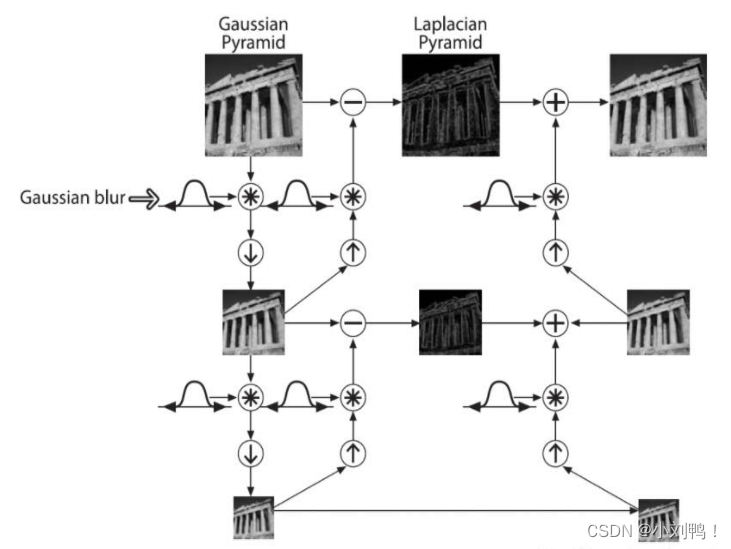
- 每个分辨率尺度上挑选128个描述子
- 每个描述子是一个7x7x3的像素块,3为颜色通道数
- 总共有16384128=2.1M个大小为77*3=147的描述子
- 对每个描述子,在各个颜色channel上进行均值和标准差的归一化
- 使用 sliced Wasserstein distance (SWD) 来计算两组图像间各个描述子的距离
- SWD是一种对Wasserstein distance(推土机距离)的近似,因为两个高维分布间的WD不方便计算
- 比较小的SWD,表示两个图像数据集间的图像外观和整体方差都比较接近
- 对不同分辨率的SWD来说,16*16上的SWD代表大尺度上图像结构的相似性,而原始分辨率上的SWD则代表像素级的差异,比如噪声和边缘的锐度
六、实验结果:
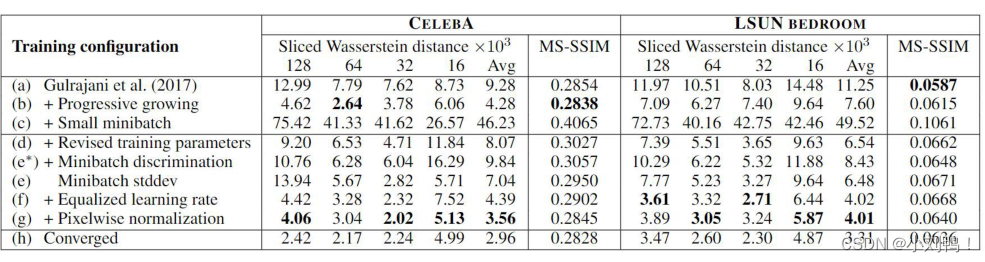
6.1消融实验:
-
生成图像的分辨率为128x128,使用轻量级网络,在训练量达到10M时停止,网络还没有完全收敛
-
MS-SSIM的评价使用了10000张生成图像
-
一开始 batch size设为 64,之后改为 16
-
最终版本使用了更大的网络和更长时间的训练使得网络收敛,其生成效果至少可以与SOA相比较
-
使用渐进式训练一方面可以提升生成质量,一方面可以减少训练的总时间
-
可以把渐进式的网络加深看做是一种隐式的课程学习,从而来理解生成质量的提升

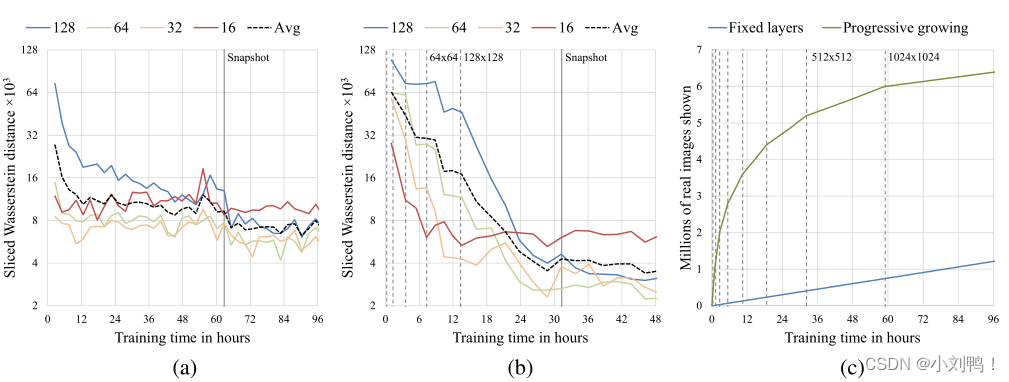
6.2训练速度:
- 使用渐进式训练后,低分辨率的SWD值很快的就收敛了,并在之后的训练中保持大致稳定
- 在生成1024分辨率的高清图像时,当训练量达到640万张图像时,渐进式训练要花费96个小时,而非渐进式训练经推断,大概需要520个小时,是渐进式训练的5.4倍






![[附源码]Java计算机毕业设计SSM高校创新学分申报管理系统](https://img-blog.csdnimg.cn/187ef0d2c96043d581c83311c0a72aa2.png)