alluxio简单使用
本文是基于alluxio官网和自己实践整理。
- Alluxio版本:1.8.1
- CDH 1.15.2
1、介绍
以内存为中心的分布式虚拟存储系统。Alluxio在上层计算框架和底层存储系统之间架起了桥梁,应用层只需要访问Alluxio即可以访问底层对接了的任意存储系统的数据。作者是李浩源/范斌,都是中国人,所以官网 也提供了中文的文档。
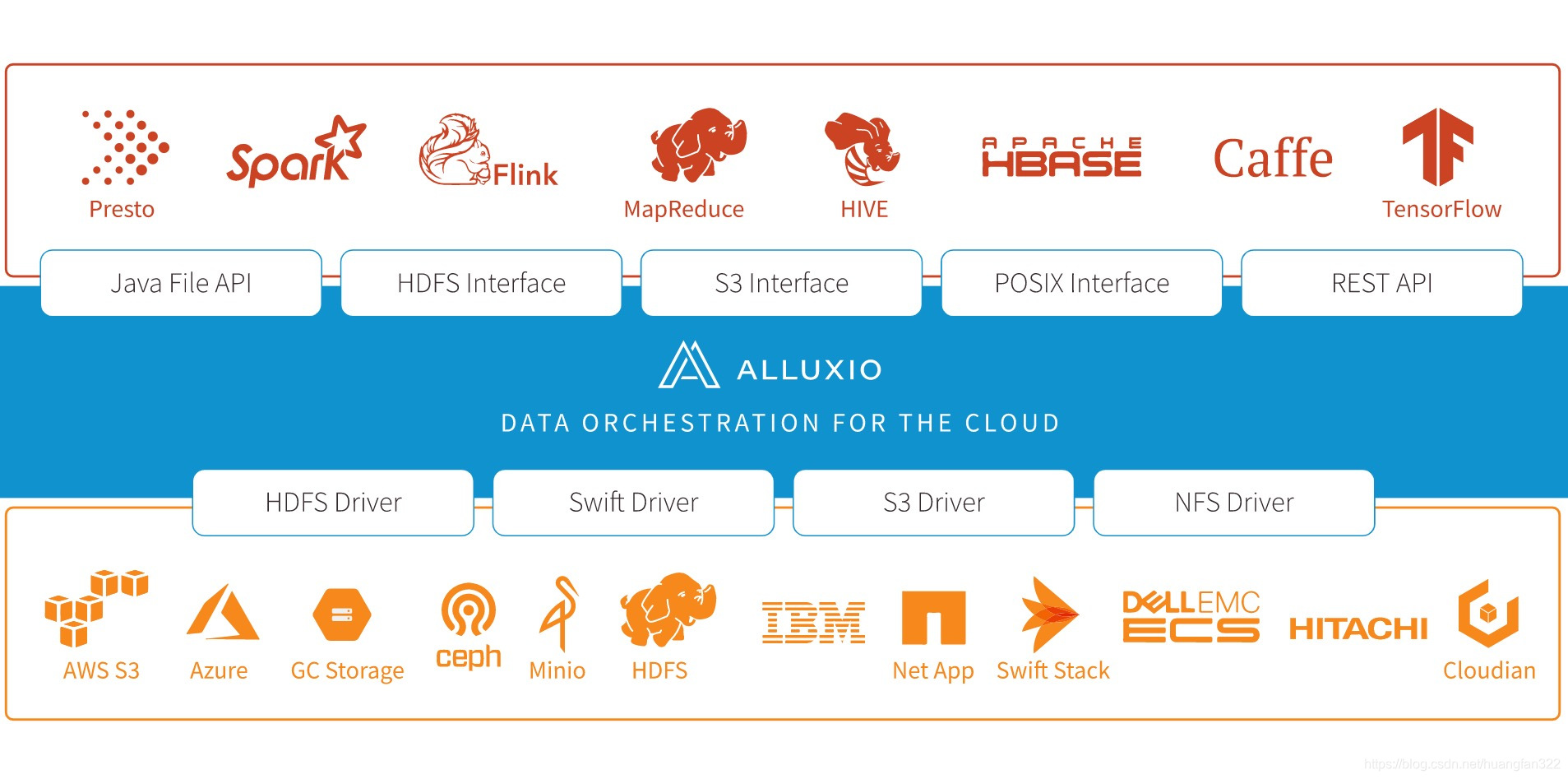
2、功能简介
- 灵活的API
- 兼容Haddop 的HDFS文件系统接口
- 分级存储,自定义分配和回收策略
- 统一命名空间
- 完整的命令行
- Web UI
3、下载编译
默认从官网下载的执行包,支持的Hadoop 2.2.x,一般我们需要自己编译源码。从gitHub上下载下来,通过以下命令构建适合自己的版本
-
mvn -T 2C install -Phadoop-2 -Dhadoop.version=2.6.0-cdh5.15.2 -DskipTests -Dmaven.javadoc.skip -Dfindbugs.skip -Dcheckstyle.skip -Dlicense.skip -
说明
- -T 2C:开启多线程编译,每个核cpu开启2个线程
- -P:hadoop-2 为haddop大版本,可以是hadoop-1、hadoop-3
- -D:具体细分版本号,我们这里是cdh版本
4、搭建和部署
部署一般建议和计算框架同置(co-locate)部署。本次以3台做个集群,其中p1机器是alluxio主节点,若要做高可用可引入zk(2.0版本会使用masters自身做高可用,不需要zk),这里没有做高可用配置。
-
下载/编译出适合自己的执行包
-
上传到服务器上(3台都要),我将源码文件放在
/usr/local/git并软链接到/opt下,后续我就直接在/opt下操作 -
选取其中一台机器作为主节点master,hostname是p1
-
在
${ALLUXIO_HOME}/conf下cp conf/alluxio-site.properties.template conf/alluxio-site.propertiesalluxio.master.hostname=p1(主节点的主机名)alluxio.underfs.address=hdfs://p1:8020/alluxio/home(namenode地址,即将hdfs跟路径挂载到alluxio下)workers文件里面添加woker主机名字,例如我这里是p2、p3masters文件里面添加master主机名字,例如我这里是p1- 利用alluxio提供拷贝命令到其他集群机器
-
在hdfs 上新建
/alluxio/home目录,hdfs dfs -mkdir /alluxio/home -
启动Alluxio
- 用启动hadoop同一用户来启动,例如hdfs
cd ${ALLUXIO_HOME}/bin,然后运行 ./alluxio format,只是第一次需要运行,会清空alluxio里面的数据cd ${ALLUXIO_HOME}/bin,然后运行 ./alluxio-start.sh all SudoMount,过程需要输入几次启动用户的密码- SudoMount 只是在第一次启动需要加,目的是挂载
/mnt/ramdisk给alluxio作为默认的存储,若是一直hang住,检查启动用户是否配置了免密,我是将hdfs ALL=(ALL) NOPASSWD: ALL加入了/etc/sudoers里面。 ${ALLUXIO_HOME}/bin ./alluxio runTests测试集群,其实就是上传一些文件到/alluxio/home- 到web UI查看:
http://p1:19999/home,其中p1是你master主机的ip - 执行命令查看集群信息:
cd ${ALLUXIO_HOME}/bin然后./alluxio fsadmin report
5、系统架构与原理
5.1 与操作系统文件系统对比
5.2 系统组件
集群组成:master、worker、client、UFS(底层存储)
master
-
管理集群的元数据
- 文件inode树
- 文件到数据块block的映射
- 数据快block到woker位置的映射
- woker元数据(worker的状态)
-
被动响应客户端RPC请求
- client的对请求文件的操作
- woker汇报状态心跳
-
记录文件系统日志(集群重启后可以准确恢复)
secondary master
高可用模式下,集群可以有多个master节点,其中只有一个会被选举为primary mater,其余均为standby状态,称为secondary master,它不接受任何Alluxio组件的请求,只是将文件系统的日志持久化存储,在多个master间共享。
worker
- 管理本机的存储资源(RAM、SSD、HDD)
- 和底层存储(UFS)交互,缓存数据
- 根据配置的缓存替换策略分配保存缓存数据
client
- 向master发起操作文件的RPC请求
- 从worker读取写入数据
- client的jar包在编译后的源码文件
${ALLUXIO_HOME}/client中 - client jar 不能单独使用,需要与应用程序在同一个JVM里面,否则会抛异常
- woker与client在一台机器,会短路读取数据(绕过请求worker的RPC请求,直接用本地文件系统读取woker里数据)
5.3、读写
5.3.1 读
关键配置参数:alluxio.user.file.readtype.default
值
说明
CACHE_PROMOTE(默认)
将数据块移动到worker最顶层,且缓存一个副本到本机worker
CACHE
将一个副本添加到本地worker中
NO_CACHE
不会创建副本
1.命中worker
命中本地worker(“短路读取”)
此时client直接通过本地文件系统读取存储在worker上的数据,称作为“短路读取”。
- 此时需要获取本地文件的操作权限
- 容器化容器里面运行alluxio client 和woker,可以通过 Unix domain socket 方式访问。
Unix domain socket 又叫 IPC(inter-process communication 进程间通信) 主要用于同一主机上的进程间通信。与主机间的进程通信不同,它不是通过 "IP地址:端口号"的方式进程通信,不需要经过网络协议栈,不需要打包拆包、计算校验和、维护序号和应答等,只是将应用层数据从一个进程拷贝到另一个进程,使用 socket 类型的文件来完成通信。
命中远程worker
- client 通过RPC连接远程的worker,woker 处理请求返回client数据
- 并缓存一个副本在本地(发起rpc的机器的worker),这样可以加快下一次访问,但是副本数会增多,引起数据爆炸(但是这也是alluxio的特点,不像hdfs那样设置副本后就是固定死了)我们可以通过设置ReadType为NO_CACHE不缓存副本。
- 2.0版本里面会有针对某个文件设置缓存的副本数量(但是没有全局的设置副本数量)
2.未命worker
- 1.8 之前版本,alluxio client 会承担缓存任务,还需要配置读取的数据是部分还是整个,采取缓存/不缓存
- 1.8 之后,缓存数据的任务交给woker异步执行,不需要关心读取的数据是完整的还是部分,因为所有的动作都在woker这边,默认woker工作机制是这样
- 客户端顺序完整读取文件,则woker顺便缓存整个文件副本
- 客户端不是顺序/完整读取,则woker会放弃读取时候顺便缓存,但是客户端会在读取完成后向woker发送异步缓存命令,worker 会继续缓存整个文件。
- woker节点线程池大小:
alluxio.worker.network.netty.async.cache.manager.threads.max默认大小8。
5.3.2 写
关键配置参数:alluxio.user.file.writetype.default
- 写类型
值
说明
MUST_CACHE(默认)
同步将数据存储在Alluxio中(不怕丢), 本地有worker,“短路写”,本地无worker,写入远程woker
THROUGH
同步将数据存储在UFS中(怕丢,但是数据不会立即用到)
CACHE_THROUGH
同步将数据存储在Alluxio中和UFS中(怕丢,且数据会立即用到)
ASYNC_THROUGH(异步)
同步将数据写入到alluxio,所有数据块block会驻留在一个woker上,然后异步地写入底层存储系统。实验性写类型,2.0 版本会稳定些
- 写定位策略
值
说明
LocalFirstPolicy(默认)
优先使用本地worker,若本地Worker没有足够的容量,从有效的worker列表中随机选择一个
MostAvailableFirstPolicy
使用拥有最多可用容量的worker
RoundRobinPolicy
循环选取存储下一个数据块的worker,若该worker没有足够的容量,跳过
SpecificHostPolicy
返回指定主机名的Worker
6、与HDFS集成
6.1 前提
- HDFS 集群启动
- Alluxio编译打包成对应的HDFS版本(参考上述下载编译)
- 上传Alluxio编译后的源码包到集群机器上,我的位置为
/opt/alluxio - 确定好namenode的地址,我的cdh版本这里是:
hdfs://p1:8020,p1为我namenode主机的ip
6.2 集成配置
配置方式
- 普通模式:参考上面,搭建和部署目录
- 高可用模式
- 将Hadoop目录下的
hds-site.xml、core-site.xml软链接到${ALLUXIO_HOME}/conf下 - 更改
{ALLUXIO_HOME}/conf下的alluxio-site.properties里面的属性alluxio.underfs.address=nameservice,其中nameservice为core-site.xml文件里面配置的HDFS服务名称。
- 将Hadoop目录下的
权限
alluxio文件系统实现了类似POSIX文件系统的用户和权限验证,所以我们需要确保HDFS上的用户、组和访问模式等文件的权限信息与Alluxio里面一致。alluxio提供了用户模拟功能,我们在{ALLUXIO_HOME}/conf里的alluxio-site.properties添加:
alluxio.master.security.impersonation.hdfs.users=*
alluxio.master.security.impersonation.yarn.users=*
alluxio.master.security.impersonation.hive.users=*
alluxio.master.security.impersonation.root.users=*
7、常用命令
通过上述的步骤,基本的一个基于HDFS存储的Alluxio集群搭建好了,我们一起来试试常用的命令感受下。首先cd {ALLUXIO_HOME}/alluxio/bin下。
7.1 管理员命令(fsadmin)
[hdfs@p1 bin]$ ./alluxio fsadmin
Usage: alluxio fsadmin [generic options][backup [directory] [--local]][doctor [category]][report [category] [category args]][ufs [--mode <noAccess/readOnly/readWrite>] <ufsPath>]
[hdfs@p1 bin]$
-
backup 备份元数据
// 备份到hdfs中
[hdfs@p1 bin]$ ./alluxio fsadmin backup /meta
Successfully backed up journal to hdfs://p1:8020/meta/alluxio-backup-2019-11-13-1573636945711.gz
// 备份到本地文件中
[hdfs@p1 bin]$ ./alluxio fsadmin backup /opt/ --local
Successfully backed up journal to file:///opt/alluxio-backup-2019-11-13-1573637112922.gz on master p1
// 从备份文件中恢复元数据
hdfs@p1 bin]$ ./alluxio-start.sh -i /opt/alluxio-backup-2019-11-13-1573637112922.gz masters
Executing the following command on all master nodes and logging to /usr/local/git/alluxio/logs/task.log: /usr/local/git/alluxio/bin/alluxio-stop.sh master
Waiting for tasks to finish…
All tasks finished
Executing the following command on all master nodes and logging to /usr/local/git/alluxio/logs/task.log: /usr/local/git/alluxio/bin/alluxio-start.sh -i /opt/alluxio-backup-2019-11-13-1573637112922.gz master
Waiting for tasks to finish…
All tasks finished -
doctor 检查alluxio的配置
[hdfs@p1 bin]$ ./alluxio fsadmin doctor
No server-side configuration errors or warnings. -
report 报告集群信息
// 有4个可选项,默认集群信息摘要,如:web界面地址,端口,woker数目等
[hdfs@p1 bin]$ ./alluxio fsadmin report -h
report [category] [category args]
Report Alluxio running cluster information.
Where [category] is an optional argument. If no arguments are passed in, summary information will be printed out.
[category] can be one of the following:
capacity worker capacity information
metrics metrics information
summary cluster summary(默认)
ufs under filesystem information// capacity, wokers的容量信息汇总
[hdfs@p1 bin]$ ./alluxio fsadmin report capacity
Capacity information for all workers:
Total Capacity: 20.68GB
Tier: MEM Size: 20.68GB
Used Capacity: 0B
Tier: MEM Size: 0B
Used Percentage: 0%
Free Percentage: 100%Worker Name Last Heartbeat Storage MEM
p2 0 capacity 10.34GB
used 0B (0%)
p3 0 capacity 10.34GB
used 0B (0%)
// ufs 集群配置底层存储系统信息
[hdfs@p1 bin]$ ./alluxio fsadmin report ufs
Alluxio under filesystem information:
hdfs://p1:8020/alluxio/home on / (hdfs, capacity=70.64GB, used=1197.66MB(1%), not read-only, not shared, properties={}) -
ufs 存储层文件系统
// 有一个 --mode 可选择项目,下面可以跟三个参数
[hdfs@p1 bin]$ ./alluxio fsadmin ufs -h
Usage: ufs [–mode <noAccess/readOnly/readWrite>]
7.1 普通用户命令(fs)
[hdfs@p1 bin]$ ./alluxio fs
Usage: alluxio fs [generic options][cat <path>][checkConsistency [-r] <Alluxio path>][checksum <Alluxio path>][chgrp [-R] <group> <path>][chmod [-R] <mode> <path>][chown [-R] <owner>[:<group>] <path>][copyFromLocal <src> <remoteDst>][copyToLocal <src> <localDst>][count <path>][cp [-R] <src> <dst>][createLineage <inputFile1,...> <outputFile1,...> [<cmd_arg1> <cmd_arg2> ...]][deleteLineage <lineageId> <cascade(true|false)>][du <path>][fileInfo <path>][free [-f] <path>][getCapacityBytes][getUsedBytes][head [-c <bytes>] <path>][help [<command>]][leader][listLineages][load [--local] <path>][loadMetadata <path>][location <path>][ls [-d|-f|-p|-R|-h|--sort=option|-r] <path>][masterInfo][mkdir <path1> [path2] ... [pathn]][mount [--readonly] [--shared] [--option <key=val>] <alluxioPath> <ufsURI>][mv <src> <dst>][persist <path> [<path> ...]][pin <path>][report <path>][rm [-R] [-U] [--alluxioOnly] <path>][setTtl [--action delete|free] <path> <time to live>][stat [-f <format>] <path>][tail [-c <bytes>] <path>][test [-d|-f|-e|-s|-z] <path>][touch <path>][unmount <alluxioPath>][unpin <path>][unsetTtl <path>]
命令很多,如果熟悉Linux命令的话,掌握起来不难。我们重点看几个命令
-
checkConsistency
对比某个给定路径下Allluxio及底层存储系统的元数据。给出的路径是目录,会比较所有子内容。检查的是目录子树的读锁,在命令完成之前,无法对目录子树文件/目录进行更新或者写操作。
-
copyFromLocal
// 将本地文件/目录 拷贝到alluxio里面
[hdfs@p1 bin]$ ./alluxio fs copyFromLocal /opt/fm.text /123
Copied file:///opt/fm.text to /123 -
free
将文件从释放中释放,前提是这个文件已经持久化到UFS了,不然是没办法释放的。
[hdfs@p1 bin]$ ./alluxio fs free /123
Cannot free file /123 which is not persisted
- location
显示文件所在的worker
[hdfs@p1 bin]$ ./alluxio fs location /123
/123 with file id 16810770431 is on nodes:
p3
-
mount
//显示所有挂载点
[hdfs@p1 bin]$ ./alluxio fs mount
hdfs://p1:8020 on / (hdfs, capacity=70.64GB, used=1191.04MB(1%), not read-only, not shared, properties={})
// 挂载hdfs://p1:8020/meta 到/meta下
[root@p1 bin]# ./alluxio fs mount /meta hdfs://p1:8020/meta
Mounted hdfs://p1:8020/meta at /meta -
unMount
取消挂载点
[root@p1 bin]# ./alluxio fs unmount /meta
Unmounted /meta
-
persist
// 将aluxio的/1234目录持久化到hdfs中
[root@p1 bin]# ./alluxio fs persist /1234
persisted file /1234 with size 46// 查看hdfs是否持久化了,我们初始化时候是挂载hdfs目录/alluxio/home到alluxio中的
[root@p1 bin]# hdfs dfs -ls /alluxio/home
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-5.15.2-1.cdh5.15.2.p0.3/jars/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-5.15.2-1.cdh5.15.2.p0.3/lib/hadoop/lib/alluxio-1.8.1-client.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Found 2 items
-rw-r–r-- 2 hdfs supergroup 46 2019-11-14 11:36 /alluxio/home/1234
drwxr-xr-x - 0 2019-11-14 10:20 /alluxio/home/default_tests_files -
setTtl
- –action deltele 参数(alluxio和ufs里面都会删除)
// 设置5秒后删除(alluxio和hdfs里面都会删除)
[root@p1 bin]# ./alluxio fs setTtl --action delete /1234 5000
TTL of path ‘/1234’ was successfully set to 5000 milliseconds, with expiry action set to DELETE//5秒后,查看alluxio(/1234 没了)
[root@p1 bin]# ./alluxio fs ls /
46 NOT_PERSISTED 11-14-2019 10:46:46:775 100% /123
46 NOT_PERSISTED 11-14-2019 10:47:18:184 100% /12345
12 PERSISTED 11-14-2019 10:20:41:992 DIR /default_tests_files
46 NOT_PERSISTED 11-14-2019 10:44:37:127 100% /fm.text// 5秒后,查看hdfs(/1234 没了)
[root@p1 bin]# hdfs dfs -ls /alluxio/home
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-5.15.2-1.cdh5.15.2.p0.3/jars/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-5.15.2-1.cdh5.15.2.p0.3/lib/hadoop/lib/alluxio-1.8.1-client.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Found 1 items
drwxr-xr-x - 0 2019-11-14 10:20 /alluxio/home/default_tests_files
7.3通过hadoop命令来操作Alluxio
Alluxio提供了兼容HDFS的接口,因此我们可以在执行hdfs命令时候,通过alluxio client 传递给allxuio 实现操作alluxio的目的。
- 在cm控制台,修改hadoop-env.sh
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wfGMhSB5-1574129851147)(/Users/huangfan/Desktop/hadoop-env.png)]
-
操作alluxio里面文件
// 查看allxuio全部文件
[root@p1 bin]# hdfs dfs -ls alluxio://localhost:19998/
Found 4 items
-rw-r–r-- 3 46 2019-11-14 10:46 alluxio://localhost:19998/123
-rw-r–r-- 3 46 2019-11-14 10:47 alluxio://localhost:19998/12345
drwxr-xr-x - 12 2019-11-14 11:49 alluxio://localhost:19998/default_tests_files
-rw-r–r-- 3 46 2019-11-14 11:54 alluxio://localhost:19998/fm.text
// 创建文件并查看
[root@p1 bin]# hdfs dfs -mkdir alluxio://localhost:19998/from-hdfs
[root@p1 bin]# hdfs dfs -ls alluxio://localhost:19998/
Found 5 items
-rw-r–r-- 3 46 2019-11-14 10:46 alluxio://localhost:19998/123
-rw-r–r-- 3 46 2019-11-14 10:47 alluxio://localhost:19998/12345
drwxr-xr-x - 12 2019-11-14 11:49 alluxio://localhost:19998/default_tests_files
-rw-r–r-- 3 46 2019-11-14 11:54 alluxio://localhost:19998/fm.text
drwxrwxrwx - 0 2019-11-14 12:08 alluxio://localhost:19998/from-hdfs
8、与计算框架整合
计算框架使用alluxio client需要在同一个JVM里面,且在classpath下能够找到alluxio client。
编译打包后alluxio client在${ALLUXIO_HOME}/client下。
8.1 与MapReduce整合
8.1.1 整合方式
-
-libjars命令,它会把alluxio client放到Hadoop的Distributed Cache中,所有节点均可以访问到。 -
手动将
alluxio client放到每个MapReduce的${HADOOP_HOME}/lib下,对于我的CDH是在/opt/cloudera/parcels/CDH/lib/hadoop/lib下。
8.1.2 验证
命令验证
[hdfs@p1 bin]$ pwd
/opt/alluxio/integration/checker/bin
[hdfs@p1 bin]$ ./alluxio-checker.sh mapreduce
... 省略 ...
***** Integration test passed. *****
wordcount验证
-
准备被统计的文件
// 将ALLUXIOHOME下的LICENSE文件拷贝到alluxio中[hdfs@p1lib]{ALLUXIO_HOME}下的LICENSE文件拷贝到alluxio中 [hdfs@p1 lib]ALLUXIOHOME下的LICENSE文件拷贝到alluxio中[hdfs@p1lib] /opt/alluxio/bin/alluxio fs copyFromLocal /opt/alluxio/LICENSE /input
-
wordcount
// 我的 cdh 的hadoop 安装目录在 /opt/cloudera/parcels/CDH/lib
[hdfs@p1 opt]$ cd /opt/cloudera/parcels/CDH/lib
// 执行 wordcount
[hdfs@p1 lib]$ hadoop jar hadoop-mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.15.2.jar wordcount -libjars /opt/alluxio/client/alluxio-1.8.1-client.jar alluxio://p1:19998/input alluxio://p1:19998/output -
到alluxio的Web UI统计信息
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MhB1n816-1574129851147)(/Users/huangfan/Desktop/wordcount.png)]
8.2 与Hive整合
前提:alluxio与MapReduce整合成功。
我在cm控制台修改hive.env.sh 文件,其他方式请自行找到hive-env.sh 文件修改
添加:
HIVE_AUX_JARS_PATH=/usr/local/git/alluxio/client/alluxio-1.8.1-client.jar:${HIVE_AUX_JARS_PATH}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-S7BksU1N-1574129851147)(/Users/huangfan/Desktop/hive.env.png)]
8.2.1 存储部分Hive表
场景:常用的表存储在Alluxio中,获取高吞吐量和低延迟。
准备:下载文件 下载ml-100k.zip 文件,上传到服务器上,例如我上传到p1 /opt下,解压。拷贝到Alluxios上
[hdfs@p1 opt]$ alluxio/bin/alluxio fs mkdir /ml-100
[hdfs@p1 opt]$ alluxio/bin/alluxio fs copyFromLocal /opt/ml-100k/u.user alluxio://localhost:19998/ml-100
-
存储内部表
CREATE TABLE u_user (
userid INT,
age INT,
gender CHAR(1),
occupation STRING,
zipcode STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘|’
LOCATION ‘alluxio://p1:19998/ml-100’; -
存储外部表
CREATE EXTERNAL TABLE hive_hdfs (
userid INT,
age INT,
gender CHAR(1),
occupation STRING,
zipcode STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘|’;
LOCATION ‘alluxio://p1:19998/ml-100’;
此时hive内部表的存储位置变成了ml-100目录下,不是在默认的hdfs下面了。内部表,在hive里面删除表u_user时候,alluxio里存储的/ml-100也会被删除。外部表,在hive里面删除表u_user时候,alluxio里面的/ml-100不会被删除。
-
使用hdfs里面的表
hive> alter table u_user set location “alluxio://127.0.0.1:19998/tables/u_user”;
OK
Time taken: 3.572 seconds -
恢复到hdfs里面
hive> alter table u_user set location “hdfs://127.0.0.1:8020/alluxio/home”;
OK
Time taken: 1.554 seconds
8.2.1 存储全部Hive表
这种情况是Hive使用Alluxio作为默认文件系统替代hdfs。
-
修改
fs.defaultFS alluxio://localhost:19998hive-siet.xml
案例就不演示了,因为hive底层还是用hdfs好些,节省空间。
8.3 与Presto整合
版本:presto-server-0.228
Prest是从HiveMetaStore里面获取元数据信息,然后通过元数据信息来获取底层ufs(这里是hdfs),它查询数据不是像hive那样提交MapReduce,而是直接操作底层ufs。
8.3.1 下载配置presto
presto下载配置移步
其他基本配置可以参照官网,其中catalog配置是关键,我这hive.properties配置如下:
connector.name=hive-hadoop2
hive.metastore.uri=thrift://p1:9083
// 保证presto可以访问到hdfs
hive.config.resources=/etc/hive/conf/core-site.xml,/etc/hive/conf/hdfs-site.xml
hive.allow-drop-table=false
hive.allow-rename-table=false
hive.allow-add-column=false
hive.allow-rename-column=false
hive.force-local-scheduling=true
将${ALLUXIO_HOME}/conf下的alluxio-site.properties文件路径加到presto的jvm.config中,这样在allxuio里面设置的属性会应用到presto
-Xbootclasspath/p:/opt/alluxio/conf
做以下几个配置
-
读写超时配置(
alluxio-site.properties)// sec、min、hour、day结尾的配置都可以,从源码看到,代码层做了自适应
alluxio.user.network.netty.timeout=10min -
启用Presto中数据本地性(
${PRESTO_HOME/etc/catalog/hive.properties})
一般 Presto worker 与 Alluxio worker 同置部署,开启这个属性后,pesto处理分片的工作可以被调度到有该分片的机器上。
hive.force-local-scheduling=true
注意:网上很多说,presto调度是基于Alluxio worker的文件块地址与Presto worker地址之间的字符串匹配进行的(没看pesto源码我不确定)
-
设置Presto分布式查询粒度(
${PRESTO_HOME/etc/catalog/hive.properties})// 默认 alluxio.user.block.size.bytes.default=512M,我们需要将查询分割设置>512MB,减少presto在同一个块上多次并行查询带来相互阻塞。 hive.max-split-size=600MB -
更改读写类型(
alluxio-site.properties)//默认读,首先将数据块从SSD或者HDD移动到MEM,然后再读取MEM中的数据块alluxio.user.file.readtype.default=CACHE_PROMOTE// 双写(内存和ufs),默认写是MUST_CACHE,只写内存alluxio.user.file.writetype.default=CACHE_THROUGH
8、配置使用
8.1 服务端配置
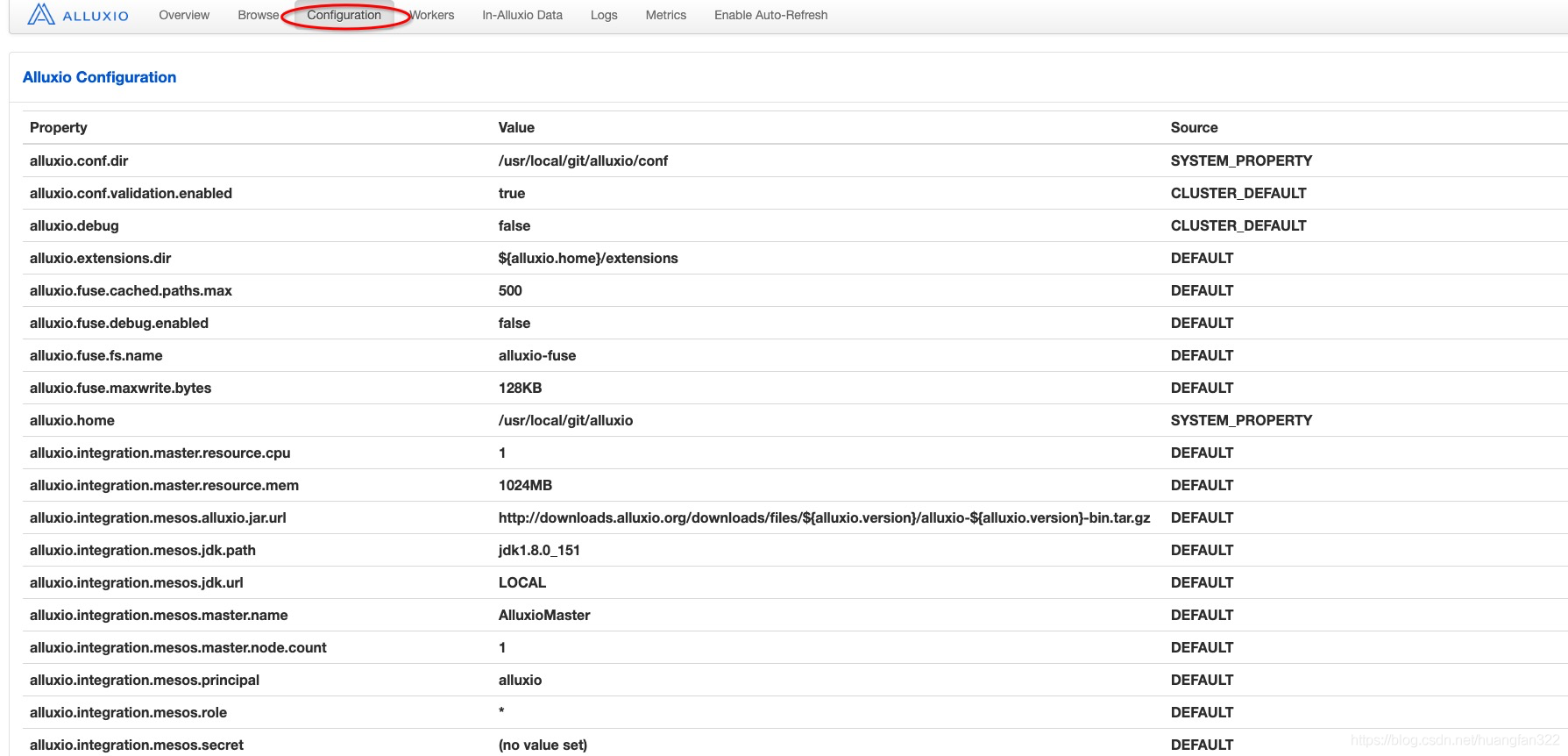
主要配置都是在${ALLUXIO_HOME}/conf下的alluxio-site.properties配置里面,集群内所有的机器上都需要设置。可以在alluxio的Web UI 界面看每个属性配置的值/默认值。
8.2 客户端配置
alluxio客户端的初始化是以集群master配置新来初始化的,也就是在${ALLUXIO_CONF}/conf下 alluxio-site.properties里面配置的信息会应用到客户端的初始化。例如设置写类型:alluxio.user.file.writetype.default=CACHE_THROUGH。
当然这样一刀切的配置肯定不是最优的,可以通过在客户端设置:alluxio.user.conf.cluster.default.enable=false来忽略或者覆盖集群范围内默认值,客户端的配置一般是通过设置JVM参数"-D",或者通过api在代码里面设置。
8.3 配置工具
alluxi 提供了一些在配置时候提高效率的小工具,说到底就是shell脚本来,具体可以看${ALLUXIO_HOME}/conf/alluxio这个脚本内容。
-
copyDir
//同步配置到所有worker机器上,不用再傻傻scp了。
./alluxio copyDir [path to alluxio’s conf dir] -
getConf
// 查看属性值
[hdfs@p1 bin]# ./alluxio getConf alluxio.user.file.writetype.default
CACHE_THROUGH
// 查看属性配置来源
[hdfs@p1 bin]# ./alluxio getConf --source alluxio.user.file.writetype.default
SITE_PROPERTY (/usr/local/git/alluxio/conf/alluxio-site.properties)
// 查看集群默认配置
[root@p1 bin]# ./alluxio getConf --masteralluxio.conf.dir=/usr/local/git/alluxio/conf
alluxio.conf.validation.enabled=true
alluxio.debug=false
alluxio.extensions.dir=/usr/local/git/alluxio/extensions
alluxio.fuse.cached.paths.max=500
alluxio.fuse.debug.enabled=false
alluxio.fuse.fs.name=alluxio-fuse
alluxio.fuse.maxwrite.bytes=128KB
alluxio.home=/usr/local/git/alluxio
alluxio.integration.master.resource.cpu=1
alluxio.integration.master.resource.mem=1024MB
alluxio.integration.mesos.alluxio.jar.url=http://downloads.alluxio.org/downloads/files/1.8.1/alluxio-1.8.1-bin.tar.gz
alluxio.integration.mesos.jdk.path=jdk1.8.0_151
alluxio.integration.mesos.jdk.url=LOCAL
alluxio.integration.mesos.master.name=AlluxioMaster
alluxio.integration.mesos.master.node.count=1
alluxio.integration.mesos.principal=alluxio
alluxio.integration.mesos.role=*
alluxio.integration.mesos.secret=(no value set)
alluxio.integration.mesos.user=(no value set)
alluxio.integration.mesos.worker.name=AlluxioWorker
alluxio.integration.worker.resource.cpu=1
alluxio.integration.worker.resource.mem=1024MB
alluxio.integration.yarn.workers.per.host.max=1
…
9、存储管理
9.1 单层模式
不需要设置,默认在集群启动时候,alluxio会为wokers分配ramdisk,
alluxio与ufs元数据同步
- 客户端
alluxio1.7 之后支持
客户端调用时候,增加参数:alluxio.user.file.metadata.sync.interval=int,int<0 永远不同步,int>0 在间隔时间内不同步,int=0 操作之前,代理总是会同步路径的元数据
alluxio fs ls -R -Dalluxio.user.file.metadata.sync.interval=0 /dirpath
- 服务端异步
alluxio 2.0 + HDFS 2.7 以上版本
// 启动
./alluxio fs startSync /syncedDirPath// 关闭
./alluxio fs stopSync /syncedDir
10、异常诊断和调试
10.1 日志
在${ALLUXIO_HOME}/logs下,*.log为log4j 生成的,*.out是标准的输出和错误流重定向文件。一般我们查看master.log 、worker.log、user_${USER}.log来排查问题。
10.2 远程调试
在 ${ALLUXIO_HOME}/conf下的alluxio-env.sh配置调试的环境变量:
export ALLUXIO_WORKER_JAVA_OPTS="$ALLUXIO_JAVA_OPTS -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=6606"
export ALLUXIO_MASTER_JAVA_OPTS="$ALLUXIO_JAVA_OPTS -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=6607"
export ALLUXIO_USER_DEBUG_JAVA_OPTS="-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=6609"
然后我们就可以在 IntelliJ IDEA 或者Eclipse里面开启Remote Debug 调试了。