Jenkins为您提供了两种开发Pipeline的方式:脚本式和声明式。
- 脚本式流水线(也称为“传统”流水线)基于Groovy作为其特定于域的语言。
- 而声明式流水线提供了简化且更友好的语法,并带有用于定义它们的特定语句,而无需学习Groovy。声明式流水线语法错误在脚本开始时报告。这是一个很好的功能,因为您不会浪费时间,直到某个步骤未能意识到拼写错误或拼写错误。如前所述,流水线可以以声明式或脚本式编写。而且,声明式方法建立在脚本式方法的基础之上,通过添加”script”步骤,可以很容易地进行扩展。
声明式流水线 vs 脚本式流水线
共同点:
- 两者都是pipeline代码的持久实现,都能够使用pipeline内置的插件或者插件提供的steps,两者都可以利用共享库扩展。
区别:
- 两者不同之处在于语法和灵活性。
- Declarative pipeline对用户来说,语法更严格,有固定的组织结构,更容易生成代码段,使其成为用户更理想的选择。
- 但是Scripted pipeline更加灵活,因为Groovy本身只能对结构和语法进行限制,对于更复杂的pipeline来说,用户可以根据自己的业务进行灵活的实现和扩展
声明式流水线#
必须使用pipeline语句定义有效的声明式流水线,并包括以下必需的部分:
- agent
- stages
- stage
- steps
另外,还有这些可用的指令:
- environment (在流水线或阶段级别定义)
- input (阶段级别定义)
- options (在流水线或阶段级别定义)
- parallel
- parameters
- post
- dcript
- tools
- triggers
- when
现在,我们将从所需的指令/部分开始,对列出的每个指令/部分进行描述。
agent#
| agent | agent部分指定整个Pipeline或特定阶段将在Jenkins环境中执行的位置,具体取决于该agent 部分的放置位置 |
|---|---|
| 需要 | 必须存在,agent必须在pipeline块内的顶层定义,但是stage内是否使用为可选 |
| 参数 | - any:在任何可用的agent 上执行Pipeline或stage。例如:agent any - none:当在pipeline块的顶层使用none时,将不会为整个Pipeline运行分配全局agent ,每个stage部分将需要包含其自己的agent部分。 - label:使用提供的label标签,在Jenkins环境中可用的代理上执行Pipeline或stage。例如:agent { label 'my-defined-label' } - node:agent { node { label 'labelName' } },等同于 agent { label 'labelName' },但node允许其他选项(如customWorkspace) - docker:定义此参数时,执行Pipeline或stage时会动态供应一个docker节点去接受Docker-based的Pipelines。 docker还可以接受一个args,直接传递给docker - dockerfile:使用从Dockerfile源存储库中包含的容器来构建执行Pipeline或stage 。 |
| 常用参数 | 这些是可以应用于两个或多个agent的选项。除非明确定义,否则不需要。 label:一个字符串。标记在哪里运行pipeline或stage。此选项适用于node,docker和dockerfile,并且 node是必需的。 customWorkspace:一个字符串。自定义运行的工作空间内。它可以是相对路径,在这种情况下,自定义工作区将位于节点上的工作空间根目录下,也可以是绝对路径。例如: reuseNode:一个布尔值,默认为false。如果为true,则在同一工作空间中。此选项适用于docker和dockerfile,并且仅在 individual stage中使用agent才有效。 |
agent { label 'this k8s-api-label'}
agent {node{label ' this is k8sapi-label'customWorkspace '/some/other/path'}
}
agent {docker {image 'im-web'label 'this is k8sapi-label'args '-v /tmp:/tmp'}
}pipeline {agent nonestages {stage('Example Build') {agent { docker 'maven:3-alpine' }steps {echo 'Hello, Maven'sh 'mvn --version'}}stage('Example Test') {agent { docker 'openjdk:8-jre' }steps {echo 'Hello, JDK'sh 'java -version'}}}
}pipeline {//Execute all the steps defined in this Pipeline within a newly created container of the given name and tag (maven:3-alpine).agent { docker 'maven:3-alpine' }stages {stage('Example Build') {steps {sh 'mvn -B clean verify'}}}
}
options#
| options | options指令允许在Pipeline本身内配置Pipeline专用选项 |
|---|---|
| 需要 | 否,预定义pipeline专有的配置信息,仅可定义一次 |
| 参数 | 无 |
| 说明 | 在流水线级别定义,此指令将对整个流水线的特定选项进行分组。可用的选项有: - buildDiscarder - pipeline保持构建的最大个数。例如:options { buildDiscarder(logRotator(numToKeepStr: '1')) } |
| disableConcurrentBuilds - 不允许并行执行Pipeline,可用于防止同时访问共享资源等。例如:options { disableConcurrentBuilds() } | |
| skipDefaultCheckout - 默认跳过来自源代码控制的代码。例如:options { skipDefaultCheckout() } | |
| skipStagesAfterUnstable 一旦构建状态进入了“Unstable”状态,就跳过此stage。例如:options { skipStagesAfterUnstable() } timeout - 设置Pipeline运行的超时时间。例如:options { timeout(time: 1, unit: 'HOURS') } | |
| retry - 失败后,重试整个Pipeline的次数。例如:options { retry(3) } | |
| timestamps - 预定义由Pipeline生成的所有控制台输出时间。例如:options { timestamps() } |
pipeline {agent anyoptions {retry(3) //将流水线配置为在失败前重试3次:}stages {echo 'do something'}
}
parameters#
parameters指令提供用户在触发Pipeline时的参数列表。这些参数值通过该params对象可用于Pipeline步骤
目前只支持[booleanParam, choice, credentials, file, text, password, run, string]这几种参数类型,其他高级参数化类型还需等待社区支持。
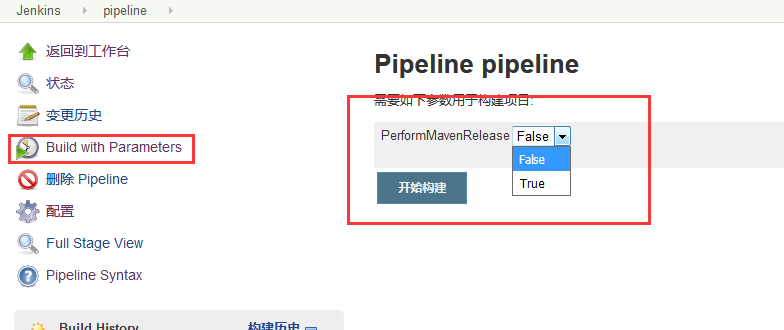
| parameters | |
|---|---|
| 需要 | 否,定义参数化构建的参数 |
| 参数 | 无 |
| 说明 | Only once, inside the pipeline block |
pipeline {agent anyparameters {string(name: 'user', defaultValue: 'John', description: 'A user that triggers the pipeline')}stages {stage('Trigger pipeline') {steps {echo "Pipeline triggered by ${params.USER}"}}}
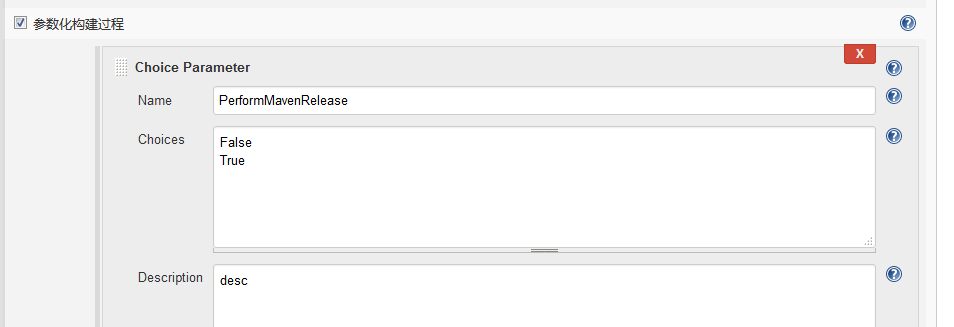
}pipeline {agent anyoptions {timeout(time:1, unit: 'HOURS')}parameters {choice(name:'PerformMavenRelease',choices:'False\nTrue',description:'desc')// password(name:'CredsToUse',defaultValue:'',description:'A password to build with')}environment {SONAR_SERVER = 'http://172.16.230.171:9000'JAVA_HOME='/data/jdk'}stages {stage('sonarserver') {steps {echo "${SONAR_SERVER}"}}stage('javahome') {steps {echo "${JAVA_HOME}"}}stage('get parameters') {steps {echo "${params.PerformMavenRelease}"}} }
}pipeline {agent anyparameters {string(name: 'PERSON', defaultValue: 'Mr Jenkins', description: 'Who should I say hello to?')}stages {stage('Example') {steps {echo "Hello ${params.PERSON}"}}}
}
stages#
| stages | 包含一个或多个stage的序列,Pipeline的大部分工作在此执行。建议stages至少包含至少一个stage指令,用于连接各个交付过程,如构建,测试和部署等 |
|---|---|
| 需要 | 是 |
| 参数 | 无 |
| 常用选项 | 构建后操作的内置判定条件 always, changed, failure, sucess,unstable,aborted |
pipeline {agent anystages {stage('Example') {steps {echo 'Hello World'}}}stage('echo') {steps {echo 'I will ........!'}}
}
steps#
| steps | |
|---|---|
| 需要 | 是,steps位于stage指令块内部,包括一个或者多个step |
| 参数 | 无 |
| 说明 | 仅有一个step的情况下可以忽略关键字step及其{} |
pipeline {agent anystages {stage('Example') {steps {sh 'echo "A one line step"'sh '''echo "A multiline step"'cd /tests/resultsls -lrt'''
}}}stage('echo') {steps { bat "mvn clean test -Dsuite=SMOKE_TEST -Denvironment=QA"powershell ".\funcional_tests.ps1"
}}
}
environment#
environment指令指定一系列键值对,这些键值对将被定义为所有step或stage-specific step的环境变量,具体取决于environment指令在Pipeline中的位置。
该指令支持一种特殊的方法credentials(),可以通过其在Jenkins环境中的标识符来访问预定义的凭据。
对于类型为“Secret Text”的凭据,该 credentials()方法将确保指定的环境变量包含Secret Text内容;对于“标准用户名和密码”类型的凭证,
指定的环境变量将被设置为username:password。
| environment | |
|---|---|
| 需要 | 是,environment 定义了一组全局的环境变量键值对 |
| 参数 | 无 |
| 说明 | 存在于pipeline{} 或者stage指令内,注意特殊方法credentials() ,可以获取jenkins中预定义的凭证明文内容 |
//在“pipeline”级别:
pipeline {agent anyenvironment {SONAR_SERVER = 'http://172.16.230.171:9000'}stages {stage('Example') {steps {echo "${SONAR_SERVER}"}}}
}//在”stage”级别:pipeline {agent anystages {stage ('build') {environment {OUTPUT_PATH = './outputs/'}...}...}
}input#
“input”指令在阶段级别定义,提供提示输入的功能。该阶段将被暂停,直到用户手动确认为止。
以下配置选项可用于此指令:
- message:这是必需的选项,其中指定了要显示给用户的消息。
- id:可选标识符。默认情况下,使用“阶段”名称。
- ok:“确定”按钮的可选文本。
- submitter:允许提交输入的用户或外部组名的可选列表。默认情况下,允许任何用户。
- submitterParameter:要使用提交者名称设置的环境变量的可选名称(如果存在)。
- parameters:提交者将提供的可选参数列表。
这是包含此指令的示例流水线:
pipeline {agent anystages {stage ('build') {input{message "Press Ok to continue"submitter "user1,user2"parameters {string(name:'username', defaultValue: 'user', description: 'Username of the user pressing Ok')}}steps { echo "User: ${username} said Ok."}}}
}
parallel#
Jenkins流水线阶段可以在内部嵌套其他阶段,这些阶段将并行执行。这是通过在脚本中添加“parallel”指令来完成的。使用示例:
stage('run-parallel-branches') {steps {parallel(a: {echo "Tests on Linux"},b: {echo "Tests on Windows"})}
}
从声明式流水线1.2版开始,引入了一种新语法,使并行语法的使用更像声明式的。
使用此新语法重写的先前脚本如下所示:
pipeline {agent nonestages {stage('Run Tests') {parallel {stage('Test On Windows') {agent {label "windows"}steps {bat "run-tests.bat"}}stage('Test On Linux') {agent {label "linux"}steps {sh "run-tests.sh"}}}}}
}
上述的任何一个流水线都将如下所示:
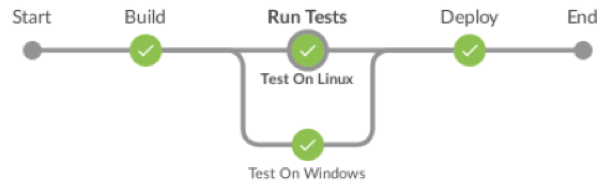
由于两个脚本都运行特定的平台测试,因此它们将在不同的节点上运行测试。如果您的Jenkins服务器具有足够的CPU,则还可以通过使用多线程将并行用于在同一节点上同时运行阶段。
使用并行阶段时有一些限制:
- stage指令可以具有parallel指令或steps指令,但不能同时具有两者。
- parallel指令中的一个stage指令不能嵌套另一个parallel指令,仅允许steps。
- 在内部具有parallel指令的stage指令不能定义“agent”或“tools”指令。
post#
| post | 定义Pipeline或stage运行结束时的操作。post-condition块支持post部件:always,changed,failure,success,unstable,和aborted。这些块允许在Pipeline或stage运行结束时执行步骤,具体取决于Pipeline的状态 |
|---|---|
| 需要 | 否,用于pipeline的最外层或者stage{}中 |
| 参数 | 无 |
| 常用选项 | always 运行,无论Pipeline运行的完成状态如何。 changed 只有当前Pipeline运行的状态与先前完成的Pipeline的状态不同时,才能运行。 failure 仅当当前Pipeline处于“失败”状态时才运行,通常在Web UI中用红色指示表示。 success 仅当当前Pipeline具有“成功”状态时才运行,通常在具有蓝色或绿色指示的Web UI中表示。 unstable 只有当前Pipeline具有“不稳定”状态,通常由测试失败,代码违例等引起,才能运行。通常在具有黄色指示的Web UI中表示。 aborted 只有当前Pipeline处于“中止”状态时,才会运行,通常是由于Pipeline被手动中止。通常在具有灰色指示的Web UI中表示。 |
pipeline {agent anystages {stage('Example') {steps {echo 'Hello World'}}}post {always {echo 'I will always say Hello again!'}}
}
script#
此步骤用于将脚本化流水线语句添加到声明式流水线中,从而提供更多功能。此步骤必须包括在“stage”级别。
脚本块可以多次用于不同的项目。这些块使您可以扩展Jenkins功能,并可以实现为共享库。可以在Jenkins共享库中找到有关此内容的更多信息。同样,可以将共享库导入并使用到“script”中,从而扩展了流水线功能。
接下来,我们将提供示例流水线。第一个只有一个包含一段脚本化流水线代码的块,而第二个将展示如何导入和使用共享库:
pipeline {agent anystages {stage('Sample') {steps {echo "Scripted block"script {}}}}
}
tools#
可以在流水线级别或阶段级别添加“tools”指令。它允许您指定要在脚本上使用的Maven,JDK或Gradle版本。必须在“全局工具配置”Jenkins菜单上配置这些工具中的任何一个,在撰写本文时,这三个工具都受支持。
另外,Jenkins将尝试安装列出的工具(如果尚未安装)。通过使用此指令,可以确保安装了项目所需的特定版本。
pipeline {agent anytools {maven 'apache-maven-3.0.1' 工具名称必须在Jenkins 管理Jenkins → 全局工具配置中预配置。}stages {echo 'do something'}
}
triggers#
触发器允许Jenkins通过使用以下任何一个可用的方式自动触发流水线:
- cron:通过使用cron语法,它可以定义何时重新触发管道。
- pollSCM:通过使用cron语法,它允许您定义Jenkins何时检查新的源存储库更新。如果检测到更改,则将重新触发流水线。(从Jenkins 2.22开始可用)。
- upstream:将Jenkins任务和阈值条件作为输入。当列表中的任何任务符合阈值条件时,将触发流水线。
带有可用触发器的示例流水线如下所示:
pipeline {agent anytriggers {//Execute weekdays every four hours starting at minute 0cron('0 */4 * * 1-5')}stages {...}
}pipeline {agent anytriggers {//Query repository weekdays every four hours starting at minute 0pollSCM('0 */4 * * 1-5')}stages {...}
}pipeline {agent anytriggers {//Execute when either job1 or job2 are successfulupstream(upstreamProjects: 'job1, job2', threshold: hudson.model.Result.SUCCESS)}stages {...}
}
when#
when指令允许Pipeline根据给定的条件确定是否执行该阶段。该when指令必须至少包含一个条件。如果when指令包含多个条件,则所有子条件必须为stage执行返回true。这与子条件嵌套在一个allOf条件中相同
更复杂的条件结构可使用嵌套条件建:not,allOf或anyOf。嵌套条件可以嵌套到任意深度
| 内置条件
branch:
- 当正在构建的分支与给出的分支模式匹配时执行,例如:when { branch 'master' }。请注意,这仅适用于多分支Pipeline。
environment
- 当指定的环境变量设置为给定值时执行,例如: when { environment name: 'DEPLOY_TO', value: 'production' }
expression
- 当指定的Groovy表达式求值为true时执行,例如: when { expression { return params.DEBUG_BUILD } }
not
- 当嵌套条件为false时执行。必须包含一个条件。例如:when { not { branch 'master' } }
allOf
- 当所有嵌套条件都为真时执行。必须至少包含一个条件。例如:when { allOf { branch 'master'; environment name: 'DEPLOY_TO', value: 'production' } }
使用方法:
1.when 仅用于stage内部
2. when 的内置条件
- when {branch 'master'} #当是master的时候,才执行某些事情
- when {envionment name:'DEPLOY_TO',value:'production'} #当环境变量name 的值是production的时候,才执行某些事情
- when {expression {return params.DEBUG_BUILD}} #表达式的返回值是真的情况下,才执行
- when {not {branch 'master'}}#不是master的情况下,执行
- when {allOf {branch 'master'; environment name: 'DEPLOY_TO',value:'production'}} #当大括号中所有的项都成立,才去做某些事情
- when {anyOf {branch 'master'; branch 'staging'}} #只要满足大括号里面的某一个条件,才去做某些事情
例如,流水线使您可以在具有多个分支的项目上执行任务。这被称为多分支流水线,其中可以根据分支名称(例如“master”,“ feature*”,“development”等)采取特定的操作。这是一个示例流水线,它将运行master分支的步骤:
pipeline {agent anystages {stage('Deploy stage') {when {branch 'master'}steps {echo 'Deploy master to stage'}}}
}
脚本式流水线#
Groovy脚本不一定适合所有使用者,因此jenkins创建了Declarative pipeline,为编写Jenkins管道提供了一种更简单、更有主见的语法。
但是不可否认,由于脚本化的pipeline是基于groovy的一种DSL语言,所以与声明式 pipeline相比为jenkins用户提供了更巨大的灵活性和可扩展性。
流程控制if/else条件#
pipeline脚本同其它脚本语言一样,从上至下顺序执行,它的流程控制取决于Groovy表达式,如if/else条件语句
node {stage('Example'){if(env.BRANCH_NAME == 'master'){echo 'I only execute on the master branch'}else {echo 'Iexecute elsewhere'}}
}
异常处理try/catch/finally#
pipeline脚本流程控制的另一种方式是Groovy的异常处理机制。当任何一个步骤因各种原因而出现异常时,都必须在Groovy中使用try/catch/finally语句块进行处理
node{stage('Example'){try{sh 'exit 1'}catch (exc) {echo 'something failed,I should sound the klaxons!'throw}}
}
循环#
for循环仅存在域脚本式pipeline中,但是可以通过在声明式pipeline中调用script step来执行
pipeline {agent anystages {stage('Example'){steps{echo 'Hello world!'script {def browsers = ['chrome','firefox']for (int i = 0;i < browers.size();++i){echo "Testing the ${browsers[i]} browser"}}}}}
}
于大多数用例,script在Declarative Pipeline中的步骤不是必须的,但它可以提供一个有用的加强