- 本文介绍如何用 REINFORCE 和 Actor-Critic 这两个策略梯度方法解二维滚球问题
- 参考:《动手学强化学习》
- 完整代码下载:6_[Gym Custom] RollingBall (REINFORCE and Actor-Critic)
文章目录
- 1. 二维滚球环境
- 2. 策略梯度方法
- 2.1 策略学习目标
- 2.2 策略梯度定理
- 2.3 近似策略梯度
- 3. REINFORCE 方法
- 3.1 伪代码
- 3.2 用 REINFORCE 方法解决二维滚球问题
- 3.3 性能
- 4. Actor-Cirtic 方法
- 4.1 伪代码
- 4.2 用 Actor-Critic 方法解决二维滚球问题
- 4.3 性能
- 5. 总结
1. 二维滚球环境
-
想象二维平面上的一个滚球,对它施加水平和竖直方向的两个力,滚球就会在加速度作用下运动起来,当球碰到平面边缘时会发生完全弹性碰撞,我们希望滚球在力的作用下尽快到达目标位置

-
此环境的状态空间为
维度 意义 取值范围 0 滚球 x 轴坐标 [ 0 , width ] [0,\space \text{width}] [0, width] 1 滚球 y 轴坐标 [ 0 , height ] [0,\space \text{height}] [0, height] 2 滚球 x 轴速度 [ − 5.0 , 5.0 ] [-5.0,\space 5.0] [−5.0, 5.0] 3 滚球 y 轴速度 [ − 5.0 , 5.0 ] [-5.0,\space 5.0] [−5.0, 5.0] 动作空间为
维度 意义 取值范围 0 施加在滚球 x 轴方向的力 [ − 1.0 , 1.0 ] [-1.0,\space 1.0] [−1.0, 1.0] 1 施加在滚球 y 轴方向的力 [ − 1.0 , 1.0 ] [-1.0,\space 1.0] [−1.0, 1.0] 奖励函数为
事件 奖励值 到达目标位置 300.0 300.0 300.0 发生反弹 − 10.0 -10.0 −10.0 移动一步 − 2.0 -2.0 −2.0 再增加一种 “密集奖励” 模式,除了以上奖励外,每一步运动都基于 “当前位置和目标位置的欧式距离 d d d” 设置辅助奖励 exp ( 1 / d ) \exp(1/d) exp(1/d),这可以给予 agent 更强的指导
-
环境完整代码如下
import gym from gym import spaces import numpy as np import pygame import timeclass RollingBall(gym.Env):metadata = {"render_modes": ["human", "rgb_array"], # 支持的渲染模式,'rgb_array' 仅用于手动交互"render_fps": 500,} # 渲染帧率def __init__(self, render_mode="human", width=10, height=10, show_epi=False, reward_type='sparse'):self.max_speed = 5.0self.width = widthself.height = heightself.show_epi = show_epiself.action_space = spaces.Box(low=-1.0, high=1.0, shape=(2,), dtype=np.float64)self.observation_space = spaces.Box(low=np.array([0.0, 0.0, -self.max_speed, -self.max_speed]), high=np.array([width, height, self.max_speed, self.max_speed]),dtype=np.float64)self.velocity = np.zeros(2, dtype=np.float64)self.mass = 0.005self.time_step = 0.01# 奖励参数self.reward_type = reward_type # dense or sparseself.rewards = {'step':-2.0, 'bounce':-10.0, 'goal':300.0}# 起止位置self.target_position = np.array([self.width*0.8, self.height*0.8], dtype=np.float32)self.start_position = np.array([width*0.2, height*0.2], dtype=np.float64)self.position = self.start_position.copy()# 渲染相关self.render_width = 300self.render_height = 300self.scale = self.render_width / self.widthself.window = None# 用于存储滚球经过的轨迹self.trajectory = []# 渲染模式支持 'human' 或 'rgb_array'assert render_mode is None or render_mode in self.metadata["render_modes"]self.render_mode = render_mode# 渲染模式为 render_mode == 'human' 时用于渲染窗口的组件self.window = Noneself.clock = Nonedef _get_obs(self):return np.hstack((self.position, self.velocity))def _get_info(self):return {}def step(self, action):# 计算加速度#force = action * self.massacceleration = action / self.mass# 更新速度和位置self.velocity += acceleration * self.time_stepself.velocity = np.clip(self.velocity, -self.max_speed, self.max_speed)self.position += self.velocity * self.time_step# 计算奖励assert self.reward_type in ['sparse', 'dense']reward = self.rewards['step']if self.reward_type == 'dense':distance = np.linalg.norm(self.position - self.target_position)reward += np.exp(1.0/distance)# 处理边界碰撞reward = self._handle_boundary_collision(reward)# 检查是否到达目标状态terminated, truncated = False, Falseif self._is_goal_reached():terminated = Truereward += self.rewards['goal'] # 到达目标状态的奖励obs, info = self._get_obs(), self._get_info()self.trajectory.append(obs.copy()) # 记录滚球轨迹return obs, reward, terminated, truncated, infodef reset(self, seed=None, options=None):# 通过 super 初始化并使用基类的 self.np_random 随机数生成器super().reset(seed=seed)# 重置滚球位置、速度、轨迹self.position = self.start_position.copy()self.velocity = np.zeros(2, dtype=np.float64)self.trajectory = []return self._get_obs(), self._get_info()def _handle_boundary_collision(self, reward):if self.position[0] <= 0:self.position[0] = 0self.velocity[0] *= -1reward += self.rewards['bounce']elif self.position[0] >= self.width:self.position[0] = self.widthself.velocity[0] *= -1reward += self.rewards['bounce']if self.position[1] <= 0:self.position[1] = 0self.velocity[1] *= -1reward += self.rewards['bounce']elif self.position[1] >= self.height:self.position[1] = self.heightself.velocity[1] *= -1reward += self.rewards['bounce']return rewarddef _is_goal_reached(self):# 检查是否到达目标状态(例如,滚球到达特定位置)distance = np.linalg.norm(self.position - self.target_position)return distance < 1.0 # 判断距离是否小于阈值def render(self):if self.render_mode not in ["rgb_array", "human"]:raise Falseself._render_frame()def _render_frame(self):canvas = pygame.Surface((self.render_width, self.render_height))canvas.fill((255, 255, 255)) # 背景白色if self.window is None and self.render_mode == "human":pygame.init()pygame.display.init()self.window = pygame.display.set_mode((self.render_width, self.render_height))if self.clock is None and self.render_mode == "human":self.clock = pygame.time.Clock()# 绘制目标位置target_position_render = self._convert_to_render_coordinate(self.target_position)pygame.draw.circle(canvas, (100, 100, 200), target_position_render, 20)# 绘制球的位置ball_position_render = self._convert_to_render_coordinate(self.position)pygame.draw.circle(canvas, (0, 0, 255), ball_position_render, 10)# 绘制滚球轨迹if self.show_epi:for i in range(len(self.trajectory)-1):position_from = self.trajectory[i]position_to = self.trajectory[i+1]position_from = self._convert_to_render_coordinate(position_from)position_to = self._convert_to_render_coordinate(position_to)color = int(230 * (i / len(self.trajectory))) # 根据轨迹时间确定颜色深浅pygame.draw.lines(canvas, (color, color, color), False, [position_from, position_to], width=3)# 'human' 渲染模式下会弹出窗口if self.render_mode == "human":# The following line copies our drawings from `canvas` to the visible windowself.window.blit(canvas, canvas.get_rect())pygame.event.pump()pygame.display.update()# We need to ensure that human-rendering occurs at the predefined framerate.# The following line will automatically add a delay to keep the framerate stable.self.clock.tick(self.metadata["render_fps"])# 'rgb_array' 渲染模式下画面会转换为像素 ndarray 形式返回,适用于用 CNN 进行状态观测的情况,为避免影响观测不要渲染价值颜色和策略else:return np.transpose(np.array(pygame.surfarray.pixels3d(canvas)), axes=(1, 0, 2))def close(self):if self.window is not None:pygame.quit()def _convert_to_render_coordinate(self, position):return int(position[0] * self.scale), int(self.render_height - position[1] * self.scale) -
本文讨论的 REINFORCE 和基础 Actor-Critic 方法都只能用于离散动作空间,我们进一步编写动作包装类,将原生的二维连续动作离散化并拉平为一维离散动作空间
class DiscreteActionWrapper(gym.ActionWrapper):''' 将 RollingBall 环境的二维连续动作空间离散化为二维离散动作空间 '''def __init__(self, env, bins):super().__init__(env)bin_width = 2.0 / binsself.action_space = spaces.MultiDiscrete([bins, bins]) self.action_mapping = {i : -1+(i+0.5)*bin_width for i in range(bins)}def action(self, action):# 用向量化函数实现高效 action 映射vectorized_func = np.vectorize(lambda x: self.action_mapping[x]) result = vectorized_func(action)action = np.array(result)return actionclass FlattenActionSpaceWrapper(gym.ActionWrapper):''' 将多维离散动作空间拉平成一维动作空间 '''def __init__(self, env):super(FlattenActionSpaceWrapper, self).__init__(env)new_size = 1for dim in self.env.action_space.nvec:new_size *= dimself.action_space = spaces.Discrete(new_size)def action(self, action):orig_action = []for dim in reversed(self.env.action_space.nvec):orig_action.append(action % dim)action //= dimorig_action.reverse()return np.array(orig_action) -
随机策略测试代码
import os import sys base_path = os.path.abspath(os.path.join(os.path.dirname(__file__), '..')) sys.path.append(base_path)import numpy as np import time from gym.utils.env_checker import check_env from environment.Env_RollingBall import RollingBall, DiscreteActionWrapper, FlattenActionSpaceWrapper from gym.wrappers import TimeLimit env = RollingBall(render_mode='human', width=5, height=5, show_epi=True) env = FlattenActionSpaceWrapper(DiscreteActionWrapper(env, 5)) env = TimeLimit(env, 100) check_env(env.unwrapped) # 检查环境是否符合 gym 规范 env.action_space.seed(10) observation, _ = env.reset(seed=10)# 测试环境 for i in range(100):while True:action = env.action_space.sample()#action = 19state, reward, terminated, truncated, _ = env.step(action)if terminated or truncated:env.reset()breaktime.sleep(0.01)env.render()# 关闭环境渲染 env.close()
2. 策略梯度方法
-
强化学习方法总体上可以分成 Value-based 和 policy-based 两类

Value-based 类方法的基本思想都是学习价值函数,然后从中导出一个策略,学习过程中并不存在一个显式的策略。我们已经实践了很多Value-base类方法,包括- policy iteration & value iteration:RL 实践(2)—— 杰克租车问题【策略迭代 & 价值迭代】
- Q-Learning系列 & Sarsa系列:RL 实践(3)—— 悬崖漫步【QLearning & Sarsa & 各种变体】
- DQN系列:RL 实践(4)—— 二维滚球环境【DQN & Double DQN & Dueling DQN】
-
从本文开始我们把重点放在
Policy-Gradient类方法上,这类方法会显式地学习一个目标策略,其基本思想是把策略学习描述成一个最优化问题,然后通过梯度下降(梯度上升)求解。这里的梯度就是所谓的策略梯度,策略梯度无法精确求解,两种近似方案分别衍生出REINFORCE算法和Actor-Critic类算法,其中后者成为了一个经典的算法框架,在 RL 的各个分支中都得到了广泛应用
2.1 策略学习目标
- 我们先把策略学习转换为一个优化问题。注意我们现在要学习一个显示的策略网络 π θ \pi_\theta πθ,根据状态价值函数定义有
V π θ ( s ) = E A ∼ π θ ( ⋅ ∣ s ) [ Q π θ ( s , A ) ] V_{\pi_\theta}(s) = \mathbb{E}_{A\sim \pi_\theta(·|s)}\left[Q_{\pi_\theta}(s,A)\right] Vπθ(s)=EA∼πθ(⋅∣s)[Qπθ(s,A)] 注意到一个状态 s s s 的好坏程度,一方面依赖于状态 s s s 本身,另一方面依赖于策略 π θ \pi_\theta πθ。如果一个策略很好,那么状态价值 V π θ ( s ) V_{\pi_\theta}(s) Vπθ(s) 的均值应当很大。因此我们定义目标函数为
J ( θ ) = E s [ V π θ ( s ) ] J(\theta) = \mathbb{E}_s[V_{\pi_\theta}(s)] J(θ)=Es[Vπθ(s)] 这也可以理解为通过对 s s s 取期望来消除这个随机变量,则好坏程度仅与策略有关。这样处理后的优化目标为
max θ J ( θ ) \max_{\theta} J(\theta) θmaxJ(θ) - 可以用梯度上升方法来解这个优化问题,即
θ new ← θ now + β ⋅ ▽ θ J ( θ now ) \theta_\text{new} \leftarrow \theta_\text{now} + \beta ·\triangledown_{\theta}J(\theta_{\text{now}}) θnew←θnow+β⋅▽θJ(θnow) 其中 β \beta β 是学习率,而所谓的策略梯度就是
∇ θ J ( θ now ) ≜ ∂ J ( θ ) ∂ θ ∣ θ = θ now \left.\nabla_{\boldsymbol{\theta}} J\left(\boldsymbol{\theta}_{\text {now }}\right) \triangleq \frac{\partial J(\boldsymbol{\theta})}{\partial \boldsymbol{\theta}}\right|_{\boldsymbol{\theta}=\boldsymbol{\theta}_{\text {now }}} ∇θJ(θnow )≜∂θ∂J(θ) θ=θnow
2.2 策略梯度定理
- 策略梯度可以根据如下
策略梯度定理计算
∇ θ J ( θ ) = ∂ J ( θ ) ∂ θ = ( 1 + γ + γ 2 + . . . + γ n − 1 ) ⋅ E S ∼ d ( ⋅ ) [ E A ∼ π θ ( ⋅ ∣ S ) [ ∂ ln π θ ( A ∣ S ) ∂ θ ⋅ Q π θ ( S , A ) ] ] = 1 − γ n 1 − γ ⋅ E S ∼ d ( ⋅ ) [ E A ∼ π θ ( ⋅ ∣ S ) [ ∂ ln π θ ( A ∣ S ) ∂ θ ⋅ Q π θ ( S , A ) ] ] ∝ E π θ [ Q π θ ( s , a ) ∇ θ log π θ ( a ∣ s ) ] \begin{aligned} \nabla_{\boldsymbol{\theta}}J(\boldsymbol{\theta}) = \frac{\partial J(\boldsymbol{\theta})}{\partial \boldsymbol{\theta}} &=(1+\gamma+\gamma^2+...+\gamma^{n-1}) \cdot \mathbb{E}_{S \sim d(\cdot)}\left[\mathbb{E}_{A \sim \pi_\theta(\cdot \mid S)}\left[\frac{\partial \ln \pi_\theta(A \mid S)}{\partial \boldsymbol{\theta}} \cdot Q_{\pi_\theta}(S, A)\right]\right] \\ &=\frac{1-\gamma^{n}}{1-\gamma} \cdot \mathbb{E}_{S \sim d(\cdot)}\left[\mathbb{E}_{A \sim \pi_\theta(\cdot \mid S)}\left[\frac{\partial \ln \pi_\theta(A \mid S)}{\partial \boldsymbol{\theta}} \cdot Q_{\pi_\theta}(S, A)\right]\right] \\ & \propto \mathbb{E}_{\pi_{\theta}}\left[Q_{\pi_{\theta}}(s, a) \nabla_{\theta} \log \pi_{\theta}(a \mid s)\right] \end{aligned} ∇θJ(θ)=∂θ∂J(θ)=(1+γ+γ2+...+γn−1)⋅ES∼d(⋅)[EA∼πθ(⋅∣S)[∂θ∂lnπθ(A∣S)⋅Qπθ(S,A)]]=1−γ1−γn⋅ES∼d(⋅)[EA∼πθ(⋅∣S)[∂θ∂lnπθ(A∣S)⋅Qπθ(S,A)]]∝Eπθ[Qπθ(s,a)∇θlogπθ(a∣s)] 注意此定理仅在“状态 S S S 服从马尔科夫链的稳态分布 d d d” 这个假设下才成立。另外由于系数 1 − γ n 1 − γ \frac{1-\gamma^{n}}{1-\gamma} 1−γ1−γn 可以在梯度上升时被学习率 β \beta β 吸收,通常我们都忽略这个系数,直接用最后一行的式子进行梯度上升计算下面进行证明,从状态价值函数的推导开始
∇ θ V π θ ( s ) = ∇ θ ( ∑ a ∈ A π θ ( a ∣ s ) Q π θ ( s , a ) ) = ∑ a ∈ A ( ∇ θ π θ ( a ∣ s ) Q π θ ( s , a ) + π θ ( a ∣ s ) ∇ θ Q π θ ( s , a ) ) = ∑ a ∈ A ( ∇ θ π θ ( a ∣ s ) Q π θ ( s , a ) + π θ ( a ∣ s ) ∇ θ ∑ s ′ , r p ( s ′ , r ∣ s , a ) ( r + γ V π θ ( s ′ ) ) ) . = ∑ a ∈ A ( ∇ θ π θ ( a ∣ s ) Q π θ ( s , a ) + γ π θ ( a ∣ s ) ∑ s ′ , r p ( s ′ , r ∣ s , a ) ∇ θ V π θ ( s ′ ) ) = ∑ a ∈ A ( ∇ θ π θ ( a ∣ s ) Q π θ ( s , a ) + γ π θ ( a ∣ s ) ∑ s ′ p ( s ′ ∣ s , a ) ∇ θ V π θ ( s ′ ) ) \begin{aligned} \nabla_{\theta} V_{\pi_{\theta}}(s) & =\nabla_{\theta}\left(\sum_{a \in A} \pi_{\theta}(a \mid s) Q_{\pi_{\theta}}(s, a)\right) \\ & =\sum_{a \in A}\left(\nabla_{\theta} \pi_{\theta}(a \mid s) Q_{\pi_{\theta}}(s, a)+\pi_{\theta}(a \mid s) \nabla_{\theta} Q_{\pi_{\theta}}(s, a)\right) \\ & =\sum_{a \in A}\left(\nabla_{\theta} \pi_{\theta}(a \mid s) Q_{\pi_{\theta}}(s, a)+\pi_{\theta}(a \mid s) \nabla_{\theta} \sum_{s^{\prime}, r} p\left(s^{\prime}, r \mid s, a\right)\left(r+\gamma V_{\pi_{\theta}}\left(s^{\prime}\right)\right)\right). \\ & =\sum_{a \in A}\left(\nabla_{\theta} \pi_{\theta}(a \mid s) Q_{\pi_{\theta}}(s, a)+\gamma \pi_{\theta}(a \mid s) \sum_{s^{\prime}, r} p\left(s^{\prime}, r \mid s, a\right) \nabla_{\theta} V_{\pi_{\theta}}\left(s^{\prime}\right)\right) \\ & =\sum_{a \in A}\left(\nabla_{\theta} \pi_{\theta}(a \mid s) Q_{\pi_{\theta}}(s, a)+\gamma \pi_{\theta}(a \mid s) \sum_{s^{\prime}} p\left(s^{\prime} \mid s, a\right) \nabla_{\theta} V_{\pi_{\theta}}\left(s^{\prime}\right)\right) \end{aligned} ∇θVπθ(s)=∇θ(a∈A∑πθ(a∣s)Qπθ(s,a))=a∈A∑(∇θπθ(a∣s)Qπθ(s,a)+πθ(a∣s)∇θQπθ(s,a))=a∈A∑ ∇θπθ(a∣s)Qπθ(s,a)+πθ(a∣s)∇θs′,r∑p(s′,r∣s,a)(r+γVπθ(s′)) .=a∈A∑ ∇θπθ(a∣s)Qπθ(s,a)+γπθ(a∣s)s′,r∑p(s′,r∣s,a)∇θVπθ(s′) =a∈A∑(∇θπθ(a∣s)Qπθ(s,a)+γπθ(a∣s)s′∑p(s′∣s,a)∇θVπθ(s′)) 为了简化表示,我们让 ϕ ( s ) = ∑ a ∈ A ∇ θ π θ ( a ∣ s ) Q π θ ( s , a ) \phi(s)=\sum_{a \in A} \nabla_{\theta} \pi_{\theta}(a \mid s) Q_{\pi_{\theta}}(s, a) ϕ(s)=∑a∈A∇θπθ(a∣s)Qπθ(s,a),定义 d π θ ( s → x ; k ) d_{\pi_\theta}(s\to x;k) dπθ(s→x;k) 为策略 π \pi π 从状态 x x x 出发步后经过 k k k 步到达状态 x x x 的概率(这里要求马尔科夫链具有稳态分布)。继续推导
∇ θ V π θ ( s ) = ϕ ( s ) + γ ∑ a π θ ( a ∣ s ) ∑ s ′ P ( s ′ ∣ s , a ) ∇ θ V π θ ( s ′ ) = ϕ ( s ) + γ ∑ a ∑ s ′ π θ ( a ∣ s ) P ( s ′ ∣ s , a ) ∇ θ V π θ ( s ′ ) = ϕ ( s ) + γ ∑ s ′ d π θ ( s → s ′ , 1 ) ∇ θ V π θ ( s ′ ) = ϕ ( s ) + γ ∑ s ′ s ′ d π θ ( s → s ′ , 1 ) [ ϕ ( s ′ ) + γ ∑ s ′ ′ d π θ ( s ′ → s ′ ′ , 1 ) ∇ θ V π θ ( s ′ ′ ) ] = ϕ ( s ) + γ ∑ s ′ s π θ ( s → s ′ , 1 ) ϕ ( s ′ ) + γ 2 ∑ s ′ ′ d π θ ( s → s ′ ′ , 2 ) ∇ θ V π θ ( s ′ ′ ) = ϕ ( s ) + γ ∑ s ′ π ′ ( s → s ′ , 1 ) ϕ ( s ′ ) + γ 2 ∑ s ′ ′ d π θ ( s ′ → s ′ ′ , 2 ) ϕ ( s ′ ′ ) + γ 3 ∑ s ′ ′ ′ d π θ ( s → s ′ ′ ′ , 3 ) ∇ θ V π θ ( s ′ ′ ′ ) = ⋯ = ∑ x ∈ S ∑ k = 0 ∞ γ k d π θ ( s → x , k ) ϕ ( x ) \begin{aligned} \nabla_{\theta} V_{\pi_{\theta}}(s) & =\phi(s)+\gamma \sum_{a} \pi_{\theta}(a \mid s) \sum_{s^{\prime}} P\left(s^{\prime} \mid s, a\right) \nabla_{\theta} V_{\pi_{\theta}}\left(s^{\prime}\right) \\ & =\phi(s)+\gamma \sum_{a} \sum_{s^{\prime}} \pi_{\theta}(a \mid s) P\left(s^{\prime} \mid s, a\right) \nabla_{\theta} V_{\pi_{\theta}}\left(s^{\prime}\right) \\ & =\phi(s)+\gamma \sum_{s^{\prime}} d_{\pi_{\theta}}\left(s \rightarrow s^{\prime}, 1\right) \nabla_{\theta} V_{\pi_{\theta}}\left(s^{\prime}\right) \\ & =\phi(s)+\gamma \sum_{s^{\prime}}^{s^{\prime}} d_{\pi_{\theta}}\left(s \rightarrow s^{\prime}, 1\right)\left[\phi\left(s^{\prime}\right)+\gamma \sum_{s^{\prime \prime}} d_{\pi_{\theta}}\left(s^{\prime} \rightarrow s^{\prime \prime}, 1\right) \nabla_{\theta} V_{\pi_{\theta}}\left(s^{\prime \prime}\right)\right] \\ & =\phi(s)+\gamma \sum_{s^{\prime}}^{s_{\pi_{\theta}}}\left(s \rightarrow s^{\prime}, 1\right) \phi\left(s^{\prime}\right)+\gamma^{2} \sum_{s^{\prime \prime}} d_{\pi_{\theta}}\left(s \rightarrow s^{\prime \prime}, 2\right) \nabla_{\theta} V_{\pi_{\theta}}\left(s^{\prime \prime}\right) \\ & =\phi(s)+\gamma \sum_{s^{\prime}}^{\pi^{\prime}}\left(s \rightarrow s^{\prime}, 1\right) \phi\left(s^{\prime}\right)+\gamma^{2} \sum_{s^{\prime \prime}} d_{\pi_{\theta}}\left(s^{\prime} \rightarrow s^{\prime \prime}, 2\right) \phi\left(s^{\prime \prime}\right)+\gamma^{3} \sum_{s^{\prime \prime \prime}} d_{\pi_{\theta}}\left(s \rightarrow s^{\prime \prime \prime}, 3\right) \nabla_{\theta} V_{\pi_{\theta}}\left(s^{\prime \prime \prime}\right) \\ & =\cdots \\ & =\sum_{x \in S} \sum_{k=0}^{\infty} \gamma^{k} d_{\pi_{\theta}}(s \rightarrow x, k) \phi(x) \end{aligned} ∇θVπθ(s)=ϕ(s)+γa∑πθ(a∣s)s′∑P(s′∣s,a)∇θVπθ(s′)=ϕ(s)+γa∑s′∑πθ(a∣s)P(s′∣s,a)∇θVπθ(s′)=ϕ(s)+γs′∑dπθ(s→s′,1)∇θVπθ(s′)=ϕ(s)+γs′∑s′dπθ(s→s′,1)[ϕ(s′)+γs′′∑dπθ(s′→s′′,1)∇θVπθ(s′′)]=ϕ(s)+γs′∑sπθ(s→s′,1)ϕ(s′)+γ2s′′∑dπθ(s→s′′,2)∇θVπθ(s′′)=ϕ(s)+γs′∑π′(s→s′,1)ϕ(s′)+γ2s′′∑dπθ(s′→s′′,2)ϕ(s′′)+γ3s′′′∑dπθ(s→s′′′,3)∇θVπθ(s′′′)=⋯=x∈S∑k=0∑∞γkdπθ(s→x,k)ϕ(x) 定义 “策略 π θ \pi_\theta πθ 诱导的一条无限长轨迹中状态 s s s 出现的次数的期望” 为 η ( s ) = E s 0 [ ∑ k = 0 ∞ γ k d π θ ( s 0 → s , k ) ] \eta(s)=\mathbb{E}_{s_{0}}\left[\sum_{k=0}^{\infty} \gamma^{k} d_{\pi_{\theta}}\left(s_{0} \rightarrow s, k\right)\right] η(s)=Es0[∑k=0∞γkdπθ(s0→s,k)]
∇ θ J ( θ ) = ∇ θ E s 0 [ V π θ ( s 0 ) ] = ∑ s E s 0 [ ∑ k = 0 ∞ γ k d π θ ( s 0 → s , k ) ] ϕ ( s ) = ∑ s η ( s ) ϕ ( s ) = ( ∑ s η ( s ) ) ∑ s η ( s ) ∑ s η ( s ) ϕ ( s ) ∝ ∑ s η ( s ) ∑ s η ( s ) ϕ ( s ) = ∑ s ν π θ ( s ) ∑ a Q π θ ( s , a ) ∇ θ π θ ( a ∣ s ) \begin{aligned} \nabla_{\theta} J(\theta) & =\nabla_{\theta} \mathbb{E}_{s_{0}}\left[V_{\pi_{\theta}}\left(s_{0}\right)\right] \\ & =\sum_{s} \mathbb{E}_{s_{0}}\left[\sum_{k=0}^{\infty} \gamma^{k} d_{\pi_{\theta}}\left(s_{0} \rightarrow s, k\right)\right] \phi(s) \\ & =\sum_{s} \eta(s) \phi(s) \\ & =\left(\sum_{s} \eta(s)\right) \sum_{s} \frac{\eta(s)}{\sum_{s} \eta(s)} \phi(s) \\ & \propto \sum_{s} \frac{\eta(s)}{\sum_{s} \eta(s)} \phi(s) \\ & =\sum_{s} \nu_{\pi_{\theta}}(s) \sum_{a} Q_{\pi_{\theta}}(s, a) \nabla_{\theta} \pi_{\theta}(a \mid s) \end{aligned} ∇θJ(θ)=∇θEs0[Vπθ(s0)]=s∑Es0[k=0∑∞γkdπθ(s0→s,k)]ϕ(s)=s∑η(s)ϕ(s)=(s∑η(s))s∑∑sη(s)η(s)ϕ(s)∝s∑∑sη(s)η(s)ϕ(s)=s∑νπθ(s)a∑Qπθ(s,a)∇θπθ(a∣s) 其中 ν π θ ( s ) \nu_{\pi_{\theta}}(s) νπθ(s) 是策略的状态访问分布。最后简单转换一下形式即证明完毕
∇ θ J ( θ ) ∝ ∑ s ∈ S ν π θ ( s ) ∑ a ∈ A Q π θ ( s , a ) ∇ θ π θ ( a ∣ s ) = ∑ s ∈ S ν π θ ( s ) ∑ a ∈ A π θ ( a ∣ s ) Q π θ ( s , a ) ∇ θ π θ ( a ∣ s ) π θ ( a ∣ s ) = E π θ [ Q π θ ( s , a ) ∇ θ log π θ ( a ∣ s ) ] \begin{aligned} \nabla_{\theta} J(\theta) & \propto \sum_{s \in S} \nu_{\pi_{\theta}}(s) \sum_{a \in A} Q_{\pi_{\theta}}(s, a) \nabla_{\theta} \pi_{\theta}(a \mid s) \\ & =\sum_{s \in S} \nu_{\pi_{\theta}}(s) \sum_{a \in A} \pi_{\theta}(a \mid s) Q_{\pi_{\theta}}(s, a) \frac{\nabla_{\theta} \pi_{\theta}(a \mid s)}{\pi_{\theta}(a \mid s)} \\ & =\mathbb{E}_{\pi_{\theta}}\left[Q_{\pi_{\theta}}(s, a) \nabla_{\theta} \log \pi_{\theta}(a \mid s)\right] \end{aligned} ∇θJ(θ)∝s∈S∑νπθ(s)a∈A∑Qπθ(s,a)∇θπθ(a∣s)=s∈S∑νπθ(s)a∈A∑πθ(a∣s)Qπθ(s,a)πθ(a∣s)∇θπθ(a∣s)=Eπθ[Qπθ(s,a)∇θlogπθ(a∣s)] - 我们常用梯度 E π θ [ Q π θ ( s , a ) ∇ θ log π θ ( a ∣ s ) ] \mathbb{E}_{\pi_{\theta}}\left[Q_{\pi_{\theta}}(s, a) \nabla_{\theta} \log \pi_{\theta}(a \mid s)\right] Eπθ[Qπθ(s,a)∇θlogπθ(a∣s)] 更新策略,注意式中期望的下标是 π θ \pi_\theta πθ,所以策略梯度算法为 on-policy 算法,必须使用当前策略采样得到的数据来计算梯度。直观理解一下策略梯度这个公式,可以发现在每一个状态 s s s 下,每个动作 a a a 的梯度会被价值 Q π θ ( s , a ) Q_{\pi_\theta}(s,a) Qπθ(s,a) 加权,这样梯度更新时就能让策略更多地去采样到带来较高值的动作,更少地去采样到带来较低值的动作

2.3 近似策略梯度
- 总结一下前两节,策略学习可以转换为如下优化问题
max θ { J ( θ ) = △ E s [ V π θ ( s ) ] } \max_\theta \left\{J(\theta) \stackrel{\triangle}{=} \mathbb{E}_s[V_{\pi_\theta}(s)] \right\} θmax{J(θ)=△Es[Vπθ(s)]} 用梯度上升来解这个优化问题
θ ← θ + β ⋅ ▽ θ J ( θ ) \theta \leftarrow \theta + \beta ·\triangledown_{\theta}J(\theta) θ←θ+β⋅▽θJ(θ) 其中策略梯度可以用策略梯度定理计算
▽ θ J ( θ ) ∝ E S ∼ d ( ⋅ ) [ E A ∼ π θ ( ⋅ ∣ S ) [ ▽ θ ln π θ ( A ∣ S ) ⋅ Q π θ ( S , A ) ] ] \triangledown_{\theta}J(\theta)\propto \mathbb{E}_{S \sim d(\cdot)}\Big[\mathbb{E}_{A \sim \pi_\theta(\cdot \mid S)}\left[\triangledown_{\theta}\ln \pi_\theta(A \mid S) \cdot Q_{\pi_\theta}(S, A)\right]\Big] ▽θJ(θ)∝ES∼d(⋅)[EA∼πθ(⋅∣S)[▽θlnπθ(A∣S)⋅Qπθ(S,A)]] 这里要计算两个期望,但是我们并不知道状态 S S S 概率密度函数 d d d;即使我们知道 d d d,能够通过连加或者定积分求出期望,我们也不愿意这样做,因为连加或者定积分的计算量非常大 - 为了解决这个问题,我们可以做两次 MC 近似,每次从环境中观测到一个状态 s s s,再根据当前的策略网络随机抽样得出一个动作 a ∼ π θ ( ⋅ ∣ s ) a\sim \pi_\theta(·|s) a∼πθ(⋅∣s),计算随机梯度
g θ ( s , a ) = △ ▽ θ ln π θ ( a ∣ s ) ⋅ Q π θ ( s , a ) g_\theta(s,a) \stackrel{\triangle}{=} \triangledown_{\theta}\ln \pi_\theta(a|s) \cdot Q_{\pi_\theta}(s,a) gθ(s,a)=△▽θlnπθ(a∣s)⋅Qπθ(s,a) 显然 g θ ( s , a ) g_\theta(s,a) gθ(s,a) 是 E π θ [ Q π θ ( s , a ) ∇ θ log π θ ( a ∣ s ) ] \mathbb{E}_{\pi_{\theta}}\left[Q_{\pi_{\theta}}(s, a) \nabla_{\theta} \log \pi_{\theta}(a \mid s)\right] Eπθ[Qπθ(s,a)∇θlogπθ(a∣s)] 的无偏估计,下面做随机梯度上升就能解原优化问题了
θ ← θ + β ⋅ g θ ( s , a ) \theta \leftarrow \theta + \beta ·g_\theta(s,a) θ←θ+β⋅gθ(s,a) - 这里还有一个问题,就是动作价值函数 Q π ( s , a ) Q_\pi(s, a) Qπ(s,a) 不知道,它的两种近似方案引出了两种策略梯度方法:
REINFORCE:用实际 return u u u MC 近似 Q π ( s , a ) Q_\pi(s, a) Qπ(s,a)Actor-Critic:用神经网络(Critic) q w ( s , a ) q_w(s, a) qw(s,a) 近似 Q π ( s , a ) Q_\pi(s, a) Qπ(s,a)
3. REINFORCE 方法
3.1 伪代码
- 如 2.3 节所述进行策略梯度优化,用实际 return u u u 做 MC 估计来近似 Q π ( s , a ) Q_\pi(s, a) Qπ(s,a)。算法伪代码如下
初始化策略参数 θ f o r e p i s o d e e = 1 → E d o : 用当前策略 π θ 采样轨迹 { s 1 , a 1 , r 1 , s 2 , a 2 , r 2 , … s T , a T , r T } 计算当前轨迹每个时刻 t 往后的 ψ t = ∑ t ′ = t T γ t ′ − t r t ′ 对 θ 进行更新 , θ = θ + α ∑ t = 1 T ψ t ∇ θ log π θ ( a t ∣ s t ) e n d f o r \begin{aligned} &初始化策略参数 \theta \\ &for \space\space episode \space\space e=1 \rightarrow E \space\space do :\\ &\quad\quad 用当前策略 \pi_{\theta} 采样轨迹 \left\{s_{1}, a_{1}, r_{1}, s_{2}, a_{2}, r_{2}, \ldots s_{T}, a_{T}, r_{T}\right\} \\ &\quad\quad 计算当前轨迹每个时刻 t 往后的\space \psi_t = \sum_{t'=t}^T \gamma^{t'-t}r_{t'}\\ &\quad\quad 对 \theta 进行更新,\space \theta=\theta+\alpha \sum_{t=1}^{T} \psi_{t} \nabla_{\theta} \log \pi_{\theta}\left(a_{t} \mid s_{t}\right) \\ &end \space\space for \end{aligned} 初始化策略参数θfor episode e=1→E do:用当前策略πθ采样轨迹{s1,a1,r1,s2,a2,r2,…sT,aT,rT}计算当前轨迹每个时刻t往后的 ψt=t′=t∑Tγt′−trt′对θ进行更新, θ=θ+αt=1∑Tψt∇θlogπθ(at∣st)end for
3.2 用 REINFORCE 方法解决二维滚球问题
- 定义策略网络,用一个简单的两层 MLP 即可
class PolicyNet(torch.nn.Module):''' 策略网络是一个两层 MLP '''def __init__(self, input_dim, hidden_dim, output_dim):super(PolicyNet, self).__init__()self.fc1 = torch.nn.Linear(input_dim, hidden_dim)self.fc2 = torch.nn.Linear(hidden_dim, output_dim)def forward(self, x):x = F.relu(self.fc1(x)) # (1, hidden_dim)x = F.softmax(self.fc2(x), dim=1) # (1, output_dim)return x - 定义 REINFORCE agent,我们用离散动作空间上的
softmax()函数实现一个可学习的多项分布,并从中采样 action。在更新过程中,我们按算法将损失函数写为策略回报的负数,这样对 loss 求导后就可以通过梯度下降来更新策略。class REINFORCE(torch.nn.Module):def __init__(self, state_dim, hidden_dim, action_range, learning_rate, gamma, device):super().__init__()self.policy_net = PolicyNet(state_dim, hidden_dim, action_range).to(device)self.optimizer = torch.optim.Adam(self.policy_net.parameters(), lr=learning_rate) # 使用Adam优化器self.gamma = gammaself.device = devicedef take_action(self, state): # 根据动作概率分布随机采样state = torch.tensor(state, dtype=torch.float).to(self.device)state = state.unsqueeze(0)probs = self.policy_net(state).squeeze()action_dist = torch.distributions.Categorical(probs)action = action_dist.sample()return action.item()def update(self, transition_dict):reward_list = transition_dict['rewards']state_list = transition_dict['states']action_list = transition_dict['actions']G = 0self.optimizer.zero_grad()# 从轨迹最后一步起往前计算 return,每步回传累计梯度for i in reversed(range(len(reward_list))): reward = reward_list[i]state = torch.tensor(state_list[i], dtype=torch.float).to(self.device) # (state_dim, )probs = self.policy_net(state.unsqueeze(0)).squeeze() # (action_range, )action = action_list[i]log_prob = torch.log(probs[action])G = self.gamma * G + rewardloss = -log_prob * G loss.backward() # 梯度下降更新参数self.optimizer.step() - 进行训练并绘制性能曲线
if __name__ == "__main__":def moving_average(a, window_size):''' 生成序列 a 的滑动平均序列 '''cumulative_sum = np.cumsum(np.insert(a, 0, 0)) middle = (cumulative_sum[window_size:] - cumulative_sum[:-window_size]) / window_sizer = np.arange(1, window_size-1, 2)begin = np.cumsum(a[:window_size-1])[::2] / rend = (np.cumsum(a[:-window_size:-1])[::2] / r)[::-1]return np.concatenate((begin, middle, end))def set_seed(env, seed=42):''' 设置随机种子 '''env.action_space.seed(seed)env.reset(seed=seed)random.seed(seed)np.random.seed(seed)torch.manual_seed(seed)state_dim = 4 # 环境观测维度action_dim = 1 # 环境动作维度action_bins = 5 # 动作离散 bins 数量action_range = action_bins * action_bins # 环境动作空间大小reward_type = 'sparse' # sparse or denselearning_rate = 1e-4num_episodes = 500hidden_dim = 64gamma = 0.98device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")# build environmentenv = RollingBall(render_mode='human', width=5, height=5, show_epi=True, reward_type=reward_type) env = FlattenActionSpaceWrapper(DiscreteActionWrapper(env, action_bins))env = TimeLimit(env, 100)check_env(env.unwrapped) # 检查环境是否符合 gym 规范set_seed(env, 42)# build agentagent = REINFORCE(state_dim, hidden_dim, action_range, learning_rate, gamma, device)# start trainingreturn_list = []for i in range(10):with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:for i_episode in range(int(num_episodes / 10)):episode_return = 0transition_dict = {'states': [],'actions': [],'next_states': [],'rewards': [],'dones': []}state, _ = env.reset()# 以当前策略交互得到一条轨迹while True:action = agent.take_action(state)next_state, reward, terminated, truncated, _ = env.step(action)transition_dict['states'].append(state)transition_dict['actions'].append(action)transition_dict['next_states'].append(next_state)transition_dict['rewards'].append(reward)transition_dict['dones'].append(terminated or truncated)state = next_stateepisode_return += rewardif terminated or truncated:env.render()break#env.render()# 用当前策略收集的数据进行 on-policy 更新agent.update(transition_dict) # 更新进度条return_list.append(episode_return)pbar.set_postfix({'episode':'%d' % (num_episodes / 10 * i + i_episode + 1),'return':'%.3f' % episode_return,'ave return':'%.3f' % np.mean(return_list[-10:])})pbar.update(1)# show policy performencemv_return_list = moving_average(return_list, 29)episodes_list = list(range(len(return_list)))plt.figure(figsize=(12,8))plt.plot(episodes_list, return_list, label='raw', alpha=0.5)plt.plot(episodes_list, mv_return_list, label='moving ave')plt.xlabel('Episodes')plt.ylabel('Returns')plt.title(f'{agent._get_name()} on RollingBall with {reward_type} reward')plt.legend()plt.savefig(f'./result/{agent._get_name()}({reward_type}).png')plt.show()
3.3 性能
- 以上 Agent 在 sparse 和 dense 奖励下的 return 变化曲线为

可见 REINFORCE 方法在密集奖励环境中表现良好,在稀疏奖励情况下则不太稳定。REINFORCE 的缺点在于- 作为一种 on-policy 方法,之前收集到的轨迹数据无法像 DQN 那样被再次利用,无法成 batch 训练,样本效率低
- 算法性能有一定程度的波动,这主要是因为每条采样轨迹的回报值波动比较大,这也是 REINFORCE 算法主要的不足
- 密集奖励环境下更容易收敛,收敛后也更稳定
4. Actor-Cirtic 方法
- 如 2.3 节所述进行策略梯度优化,用一个价值神经网络来近似 Q π ( s , a ) Q_\pi(s, a) Qπ(s,a)。这个价值网络和我们之前实现的 DQN 结构完全一致,二者区别在于
- DQN 网络是对于最优状态动作价值函数 Q ∗ ( s , a ) Q_*(s,a) Q∗(s,a) 的估计,而 Critic 网络是对给定策略(当前策略)状态动作价值函数 Q π θ ( s , a ) Q_{\pi_\theta}(s,a) Qπθ(s,a) 的估计
- DQN 网络本质是使用函数估计的 Q-Learning 算法,属于 off-policy 方法,可以用经验重放;Critic 网络本质是使用函数估计的 Sarsa 算法,属于 on-policy 方法,不能用经验重放
- Actor-Critic 的训练框架图如下所示

- Actor 本质是一个策略 π θ \pi_\theta πθ ,它要做的是与环境交互,并在 Critic 价值函数的指导下用策略梯度更新参数 θ \theta θ。Actor 的更新方向会迎合 Critic 的喜好,即尝试最大化 Critic 给出的价值估计
- Critic 本质是一个价值网络 Q ω Q_\omega Qω,它要做的是利用 Actor 与环境交互收集的数据学习当前策略 π θ \pi_\theta πθ 的价值函数,它的更新方向会使 Critic 对策略真实价值 Q π θ Q_{\pi_\theta} Qπθ 的估计更准确,进而帮助 Actor 进行策略更新
- 两个网络训练时使用的损失函数如下
- Actor 使用 2.3 节得到的近似策略梯度进行更新。具体而言,先利用 Critic 得到近似策略梯度,然后做梯度上升更新
g ^ θ ( s , a ) = ▽ θ ln π θ ( a ∣ s ) ⋅ Q ω ( s , a ) θ ← θ + β ⋅ g θ ( s , a ) \begin{aligned} &\hat{g}_\theta(s,a) = \triangledown_{\theta}\ln \pi_\theta(a|s) \cdot Q_\omega(s,a) \\ &\theta \leftarrow \theta + \beta ·g_\theta(s,a) \end{aligned} g^θ(s,a)=▽θlnπθ(a∣s)⋅Qω(s,a)θ←θ+β⋅gθ(s,a) - Critic 使用类似 DQN 的 mse 损失,减小 Sarsa 迭代的 TD error。具体而言,对于每个 transition ( s , a , r , s ′ , a ′ ) (s,a,r,s',a') (s,a,r,s′,a′),如下得到优化损失(transition 中 a ∼ π θ ( ⋅ ∣ s ) , a ′ ∼ π θ ( ⋅ ∣ s ′ ) a\sim \pi_\theta(\cdot|s), a'\sim \pi_\theta(\cdot|s') a∼πθ(⋅∣s),a′∼πθ(⋅∣s′))
l ω = 1 2 [ Q ω ( s , a ) − ( r + Q ω ( s ′ , a ′ ) ) ] 2 l_\omega = \frac{1}{2}\Big[Q_\omega(s,a) - \big(r+Q_\omega(s',a')\big) \Big]^2 lω=21[Qω(s,a)−(r+Qω(s′,a′))]2
- Actor 使用 2.3 节得到的近似策略梯度进行更新。具体而言,先利用 Critic 得到近似策略梯度,然后做梯度上升更新
4.1 伪代码
- 注意 Actor-Critic 是 on-policy 方法,我们每次固定 Actor 网络交互一段时间(这里设为一条轨迹),然后用采集到的数据更新 Critic 网络和 Actor 网络。这样更新都可以用 batch 形式进行,效率较高
初始化 A c t o r 参数 θ 和 C r i t i c 参数 ω f o r e p i s o d e e = 1 → E d o : 用当前策略 π θ 交互一条轨迹,构造数据集 { ( s i , a i , r i , s i , a i ′ ) ∣ i = 1 , . . . , m } ,其中 a i ′ 不执行 更新 C r i t i c 参数 l ω = 1 2 [ Q ω ( s , a ) − ( r + Q ω ( s ′ , a ′ ) ) ] 2 更新 A c t o r 参数 θ ← θ + β ⋅ ▽ θ ln π θ ( a ∣ s ) ⋅ Q ω ( s , a ) e n d f o r \begin{aligned} &初始化 \space Actor \space参数 \space \theta 和\space Critic \space参数 \space \omega \\ &for \space\space episode \space\space e=1 \rightarrow E \space\space do :\\ &\quad\quad 用当前策略 \pi_{\theta} 交互一条轨迹,构造数据集 \{(s_i,a_i,r_i,s_i,a_i')|i=1,...,m\},其中 a'_i 不执行\\ &\quad\quad 更新\space Critic \space参数 \space l_\omega = \frac{1}{2}\Big[Q_\omega(s,a) - \big(r+Q_\omega(s',a')\big) \Big]^2\\ &\quad\quad更新 \space Actor \space参数\space \theta \leftarrow \theta + \beta ·\triangledown_{\theta}\ln \pi_\theta(a|s) \cdot Q_\omega(s,a) \\ &end \space\space for \end{aligned} 初始化 Actor 参数 θ和 Critic 参数 ωfor episode e=1→E do:用当前策略πθ交互一条轨迹,构造数据集{(si,ai,ri,si,ai′)∣i=1,...,m},其中ai′不执行更新 Critic 参数 lω=21[Qω(s,a)−(r+Qω(s′,a′))]2更新 Actor 参数 θ←θ+β⋅▽θlnπθ(a∣s)⋅Qω(s,a)end for
4.2 用 Actor-Critic 方法解决二维滚球问题
- 定义 Actor 和 Critic 网络
class PolicyNet(torch.nn.Module):''' 策略网络是一个两层 MLP '''def __init__(self, input_dim, hidden_dim, output_dim):super(PolicyNet, self).__init__()self.fc1 = torch.nn.Linear(input_dim, hidden_dim)self.fc2 = torch.nn.Linear(hidden_dim, output_dim)def forward(self, x):x = F.relu(self.fc1(x)) # (1, hidden_dim)x = F.softmax(self.fc2(x), dim=1) # (1, output_dim)return xclass QNet(torch.nn.Module):''' 价值网络是一个两层 MLP '''def __init__(self, input_dim, hidden_dim, output_dim):super(QNet, self).__init__()self.fc1 = torch.nn.Linear(input_dim, hidden_dim)self.fc2 = torch.nn.Linear(hidden_dim, output_dim)def forward(self, x):x = F.relu(self.fc1(x))x = self.fc2(x)return x - 定义 Actor-Critic Agent,注意其中的 update 方法
class ActorCritic(torch.nn.Module):def __init__(self, state_dim, hidden_dim, action_range, actor_lr, critic_lr, gamma, device):super().__init__()self.gamma = gammaself.device = deviceself.actor = PolicyNet(state_dim, hidden_dim, action_range).to(device)self.critic = QNet(state_dim, hidden_dim, action_range).to(device) self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=actor_lr)self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=critic_lr)def take_action(self, state):state = torch.tensor(state, dtype=torch.float).to(self.device)state = state.unsqueeze(0)probs = self.actor(state)action_dist = torch.distributions.Categorical(probs)action = action_dist.sample()return action.item()def update_actor_cirtic(self, transition_dict):states = torch.tensor(np.array(transition_dict['states']), dtype=torch.float).to(self.device) # (bsz, state_dim)next_states = torch.tensor(np.array(transition_dict['next_states']), dtype=torch.float).to(self.device) # (bsz, state_dim)actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(self.device) # (bsz, action_dim)next_actions = torch.tensor(transition_dict['next_actions']).view(-1, 1).to(self.device) # (bsz, action_dim)rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1, 1).to(self.device).squeeze() # (bsz, )dones = torch.tensor(transition_dict['dones'], dtype=torch.float).view(-1, 1).to(self.device).squeeze() # (bsz, )# Cirtic loss q_values = self.critic(states).gather(dim=1, index=actions).squeeze() # (bsz, )next_q_values = self.critic(next_states).gather(dim=1, index=next_actions).squeeze() # (bsz, ) td_targets = rewards + self.gamma * next_q_values * (1 - dones) # (bsz, )critic_loss = torch.mean(F.mse_loss(q_values, td_targets.detach())) # td_targets 中包含 actor 给出的 next_action,将其 detach 以确保只更新 cirtic 参数# Actor loss probs = self.actor(states).gather(dim=1, index=actions).squeeze() # (bsz, )log_probs = torch.log(probs) # (bsz, )actor_loss = torch.mean(-log_probs * q_values.detach()) # q_values 是 critic 给出的,将其 detach 以确保只更新 actor 参数# 更新网络参数self.actor_optimizer.zero_grad()self.critic_optimizer.zero_grad()actor_loss.backward() critic_loss.backward() self.actor_optimizer.step() self.critic_optimizer.step() - 训练主函数
if __name__ == "__main__":def moving_average(a, window_size):''' 生成序列 a 的滑动平均序列 '''cumulative_sum = np.cumsum(np.insert(a, 0, 0)) middle = (cumulative_sum[window_size:] - cumulative_sum[:-window_size]) / window_sizer = np.arange(1, window_size-1, 2)begin = np.cumsum(a[:window_size-1])[::2] / rend = (np.cumsum(a[:-window_size:-1])[::2] / r)[::-1]return np.concatenate((begin, middle, end))def set_seed(env, seed=42):''' 设置随机种子 '''env.action_space.seed(seed)env.reset(seed=seed)random.seed(seed)np.random.seed(seed)torch.manual_seed(seed)state_dim = 4 # 环境观测维度action_dim = 1 # 环境动作维度action_bins = 5 # 动作离散 bins 数量action_range = action_bins * action_bins # 环境动作空间大小reward_type = 'sparse' # sparse or denseactor_lr = 1e-2 critic_lr = 5e-3 num_episodes = 500hidden_dim = 64gamma = 0.98device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")# build environmentenv = RollingBall(render_mode='human', width=5, height=5, show_epi=True, reward_type=reward_type) env = FlattenActionSpaceWrapper(DiscreteActionWrapper(env, action_bins))env = TimeLimit(env, 100)check_env(env.unwrapped) # 检查环境是否符合 gym 规范set_seed(env, 42)# build agentagent = ActorCritic(state_dim, hidden_dim, action_range, actor_lr, critic_lr, gamma, device)# start trainingreturn_list = []for i in range(10):with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:for i_episode in range(int(num_episodes / 10)):episode_return = 0transition_dict = {'states': [],'actions': [],'next_states': [],'next_actions': [],'rewards': [],'dones': []}state, _ = env.reset()# 以当前策略交互得到一条轨迹while True:action = agent.take_action(state)next_state, reward, terminated, truncated, _ = env.step(action)next_action = agent.take_action(next_state)transition_dict['states'].append(state)transition_dict['actions'].append(action)transition_dict['next_states'].append(next_state)transition_dict['next_actions'].append(next_action)transition_dict['rewards'].append(reward)transition_dict['dones'].append(terminated or truncated)state = next_stateepisode_return += rewardif terminated or truncated:env.render()break#env.render()# 用当前策略收集的数据进行 on-policy 更新agent.update_actor_cirtic(transition_dict)# 更新进度条return_list.append(episode_return)pbar.set_postfix({'episode':'%d' % (num_episodes / 10 * i + i_episode + 1),'return':'%.3f' % episode_return,'ave return':'%.3f' % np.mean(return_list[-10:])})pbar.update(1)# show policy performencemv_return_list = moving_average(return_list, 29)episodes_list = list(range(len(return_list)))plt.figure(figsize=(12,8))plt.plot(episodes_list, return_list, label='raw', alpha=0.5)plt.plot(episodes_list, mv_return_list, label='moving ave')plt.xlabel('Episodes')plt.ylabel('Returns')plt.title(f'{agent._get_name()} on RollingBall with {reward_type} reward')plt.legend()plt.savefig(f'./result/{agent._get_name()}({reward_type}).png')plt.show()
4.3 性能
- 以上 Agent 在 sparse 和 dense 奖励下的 return 变化曲线为
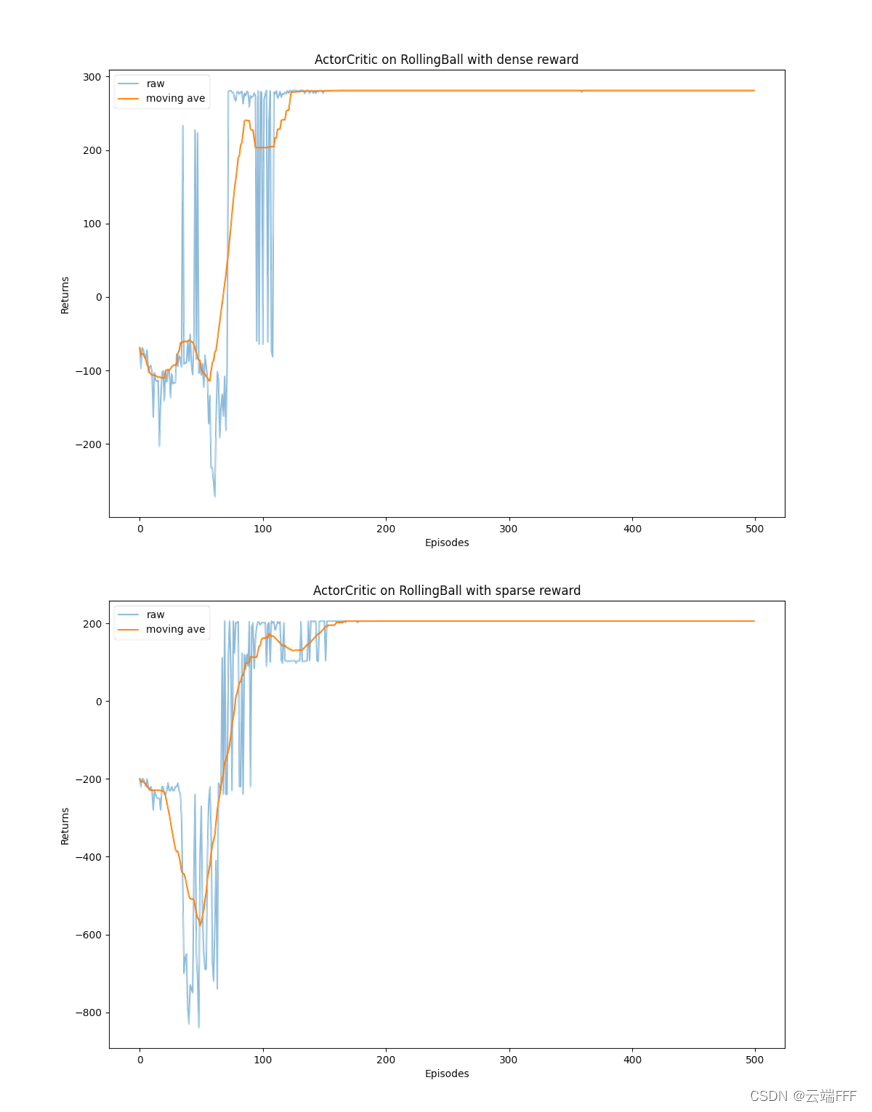
可见 Actor-Critic 算法很快便能收敛到最优策略,并且训练过程非常稳定,抖动情况相比 REINFORCE 算法有了明显的改进,这说明价值函数的引入减小了方差。不过训练过程中我发现 Actor-Critic 方法对超参数(如学习率)比较敏感,有时候会收敛到次优策略。极端情况下 Actor 网络可能认为某个动作远远优于其他动作,这会导致 agent 收集到的轨迹数据一直不变,使得 Critic 只能一直用这些固定的数据进行更新,由于数据多样性太低,可能很难扭转 Actor 对这个固定动作的偏好,导致 agent 陷入次优策略无法脱离 - 另外,在实践 DQN 时我们提到 Q-Learning 迭代中的 bootstrap 会传播价值估计误差,SARSA 迭代中也存在 bootstrap,这时我们同样可以引入 target network 来计算 TD target,从而缓解偏差
5. 总结
- 本文讲解了策略梯度方法的思想,对策略梯度公式进行了推导,对策略梯段公式中 Q Q Q 价值的两种近似方法得到了两个 on-policy RL 方法
- REINFORCE 方法使用 MC 方法估计 Q 价值,该算法是策略梯度乃至强化学习的典型代表,agent 根据当前策略直接和环境交互,通过采样得到的轨迹数据直接计算出策略参数的梯度,进而更新当前策略,使其向最大化策略期望回报的目标靠近。这种学习方式是典型的从交互中学习,并且其优化的目标(即策略期望回报)正是最终所使用策略的性能,这比基于价值的强化学习算法的优化目标(一般是时序差分误差的最小化)要更加直接。 REINFORCE 算法理论上是能保证局部最优的,它实际上是借助蒙特卡洛方法采样轨迹来估计动作价值,这种做法的一大优点是可以得到无偏的梯度。但是,正是因为使用了蒙特卡洛方法,REINFORCE 算法的梯度估计的方差很大,可能会造成一定程度上的不稳定
- Actor-Critic 方法使用 sarsa 迭代的神经网络估计 Q 价值,该算法是 value-based 方法和 policy-based 方法的叠加。价值模块 Critic 在策略模块 Actor 采样的数据中学习分辨什么是好的动作,什么不是好的动作,进而指导 Actor 进行策略更新。随着 Actor 的训练的进行,其与环境交互所产生的数据分布也发生改变,这需要 Critic 尽快适应新的数据分布并给出好的判别。Actor-Critic 算法非常实用,后续的 TRPO、PPO、DDPG、SAC 等深度强化学习算法都是在 Actor-Critic 框架下进行发展的。深入了解 Actor-Critic 算法对读懂目前深度强化学习的研究热点大有裨益







![R语言无法调用stats.dll的问题解决方案[补充]](https://img-blog.csdnimg.cn/img_convert/4f03963b6716440cf661480ad574ce37.png)