mmdet3d预处理(下)—— train pipeline

文章目录
- mmdet3d预处理(下)—— train pipeline
- 基类 BaseTransform
- LoadPointsFromFile
- LoadAnnotations3D
- 标签信息:
- 源码
- ObjectSample
- 源码
- ObjectNoise
- 输入参数
- 源码
- RandomFlip3D
- 参数
- 源码
- GlobalRotScaleTrans
- 参数
- 源码
- PointsRangeFilter
- 源码
- ObjectRangeFilter
- 源码
- ObjectNameFilter
- 源码
- PointShuffle
- 源码
- Pack3DDetInputs
- 源码
- Reference
- >>>>> 欢迎关注公众号【三戒纪元】 <<<<<
本篇着重分析训练pipeline中各函数的作用及源码剖析
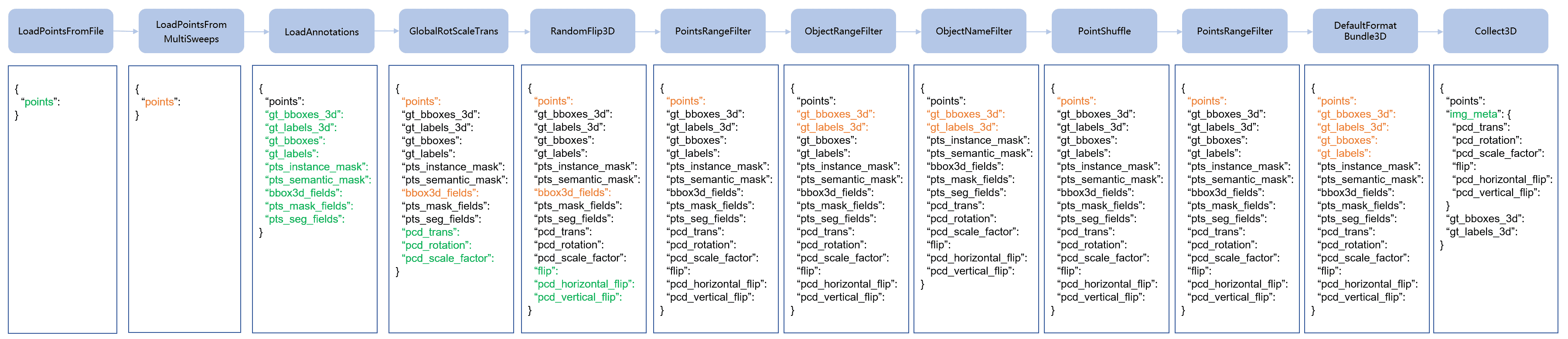
基类 BaseTransform
MMDet3D 1.1中的数据转换都继承自MMCV>=2.0.0 r0中的BaseTransform
- 一些数据转换的功能(例如,“Resize”)被分解成几个转换,以简化和澄清用法。
- 根据数据集的新数据结构,每次数据转换处理的数据字典格式都会发生变化。将一些低效的数据转换(如归一化normalization和填充padding)移到模型的数据预处理中,以改进数据加载和训练速度
LoadPointsFromFile
mmdet3d/datasets/transforms/loading.py
从点云文件加载点
@TRANSFORMS.register_module()
class LoadPointsFromFile(BaseTransform):"""Load Points From File.Required Keys:- lidar_points (dict)- lidar_path (str)Added Keys:- points (np.float32)Args:coord_type (str): The type of coordinates of points cloud.Available options includes:- 'LIDAR': Points in LiDAR coordinates.- 'DEPTH': Points in depth coordinates, usually for indoor dataset.- 'CAMERA': Points in camera coordinates.load_dim (int): The dimension of the loaded points. Defaults to 6.use_dim (list[int] | int): Which dimensions of the points to use.Defaults to [0, 1, 2]. For KITTI dataset, set use_dim=4or use_dim=[0, 1, 2, 3] to use the intensity dimension.shift_height (bool): Whether to use shifted height. Defaults to False.use_color (bool): Whether to use color features. Defaults to False.norm_intensity (bool): Whether to normlize the intensity. Defaults toFalse.backend_args (dict, optional): Arguments to instantiate thecorresponding backend. Defaults to None."""def __init__(self,coord_type: str,load_dim: int = 6,use_dim: Union[int, List[int]] = [0, 1, 2],shift_height: bool = False,use_color: bool = False,norm_intensity: bool = False,backend_args: Optional[dict] = None) -> None:self.shift_height = shift_heightself.use_color = use_colorif isinstance(use_dim, int):use_dim = list(range(use_dim))assert max(use_dim) < load_dim, \f'Expect all used dimensions < {load_dim}, got {use_dim}'assert coord_type in ['CAMERA', 'LIDAR', 'DEPTH']self.coord_type = coord_typeself.load_dim = load_dimself.use_dim = use_dimself.norm_intensity = norm_intensityself.backend_args = backend_argsdef _load_points(self, pts_filename: str) -> np.ndarray:"""Private function to load point clouds data.Args:pts_filename (str): Filename of point clouds data.Returns:np.ndarray: An array containing point clouds data."""try:pts_bytes = get(pts_filename, backend_args=self.backend_args)points = np.frombuffer(pts_bytes, dtype=np.float32)except ConnectionError:mmengine.check_file_exist(pts_filename)if pts_filename.endswith('.npy'):points = np.load(pts_filename)else:points = np.fromfile(pts_filename, dtype=np.float32)return pointsdef transform(self, results: dict) -> dict:"""Method to load points data from file.Args:results (dict): Result dict containing point clouds data.Returns:dict: The result dict containing the point clouds data.Added key and value are described below.- points (:obj:`BasePoints`): Point clouds data."""pts_file_path = results['lidar_points']['lidar_path']points = self._load_points(pts_file_path)points = points.reshape(-1, self.load_dim)points = points[:, self.use_dim]if self.norm_intensity:assert len(self.use_dim) >= 4, \f'When using intensity norm, expect used dimensions >= 4, got {len(self.use_dim)}' # noqa: E501points[:, 3] = np.tanh(points[:, 3])attribute_dims = Noneif self.shift_height:floor_height = np.percentile(points[:, 2], 0.99)height = points[:, 2] - floor_heightpoints = np.concatenate([points[:, :3],np.expand_dims(height, 1), points[:, 3:]], 1)attribute_dims = dict(height=3)if self.use_color:assert len(self.use_dim) >= 6if attribute_dims is None:attribute_dims = dict()attribute_dims.update(dict(color=[points.shape[1] - 3,points.shape[1] - 2,points.shape[1] - 1,]))points_class = get_points_type(self.coord_type)points = points_class(points, points_dim=points.shape[-1], attribute_dims=attribute_dims)results['points'] = pointsreturn results
_load_points:从文件中加载点云,转换为numpy格式
transform:
- 首先正常从文件加载点云
- 根据是否对强度值规范化 ,对强度值进行处理(tanh)
- 是否偏移高度,是否将点云高度减去地面高度
- 是否使用颜色
- 返回带点云数据的字典
LoadAnnotations3D
加载点的实例掩码和语义掩码,并将条目封装到相关字段中。
说白点就是加载GT框的相关信息。
标签信息:
| key | description |
|---|---|
gt_bboxes_3d (:obj:LiDARInstance3DBoxes |:obj:DepthInstance3DBoxes | :obj:CameraInstance3DBoxes) | gt 3d 包围盒。 仅当“with_bbox_3d”为 True 时 |
| gt_labels_3d (np.int64) | gt 3d 标签。仅当“with_label_3d”为 True 时。 |
| gt_bboxes (np.float32) | gt bboxes 包围盒。仅当“with_bbox”为 True 时。 |
| gt_labels (np.ndarray) | gt 标签。仅当“with_label”为 True 时。 |
| depths (np.ndarray) | 深度。仅当with_bbox_depth 为 True。 |
| center_2d (np.ndarray) | 2d中心。仅当with_bbox_depth 为 True。 |
| attr_labels (np.ndarray) | 实例的属性标签。仅当“with_attr_label”为 True 时。 |
源码
@TRANSFORMS.register_module()
class LoadAnnotations3D(LoadAnnotations):"""Load Annotations3D.Load instance mask and semantic mask of points andencapsulate the items into related fields.def _load_bboxes_3d(self, results: dict) -> dict:"""Private function to move the 3D bounding box annotation from`ann_info` field to the root of `results`.Args:results (dict): Result dict from :obj:`mmdet3d.CustomDataset`.Returns:dict: The dict containing loaded 3D bounding box annotations."""results['gt_bboxes_3d'] = results['ann_info']['gt_bboxes_3d']return resultsdef _load_bboxes_depth(self, results: dict) -> dict:"""Private function to load 2.5D bounding box annotations.Args:results (dict): Result dict from :obj:`mmdet3d.CustomDataset`.Returns:dict: The dict containing loaded 2.5D bounding box annotations."""results['depths'] = results['ann_info']['depths']results['centers_2d'] = results['ann_info']['centers_2d']return resultsdef _load_labels_3d(self, results: dict) -> dict:"""Private function to load label annotations.Args:results (dict): Result dict from :obj:`mmdet3d.CustomDataset`.Returns:dict: The dict containing loaded label annotations."""results['gt_labels_3d'] = results['ann_info']['gt_labels_3d']return resultsdef _load_attr_labels(self, results: dict) -> dict:"""Private function to load label annotations.Args:results (dict): Result dict from :obj:`mmdet3d.CustomDataset`.Returns:dict: The dict containing loaded label annotations."""results['attr_labels'] = results['ann_info']['attr_labels']return resultsdef _load_masks_3d(self, results: dict) -> dict:"""Private function to load 3D mask annotations.Args:results (dict): Result dict from :obj:`mmdet3d.CustomDataset`.Returns:dict: The dict containing loaded 3D mask annotations."""pts_instance_mask_path = results['pts_instance_mask_path']try:mask_bytes = get(pts_instance_mask_path, backend_args=self.backend_args)pts_instance_mask = np.frombuffer(mask_bytes, dtype=np.int64)except ConnectionError:mmengine.check_file_exist(pts_instance_mask_path)pts_instance_mask = np.fromfile(pts_instance_mask_path, dtype=np.int64)results['pts_instance_mask'] = pts_instance_mask# 'eval_ann_info' will be passed to evaluatorif 'eval_ann_info' in results:results['eval_ann_info']['pts_instance_mask'] = pts_instance_maskreturn resultsdef _load_semantic_seg_3d(self, results: dict) -> dict:"""Private function to load 3D semantic segmentation annotations.Args:results (dict): Result dict from :obj:`mmdet3d.CustomDataset`.Returns:dict: The dict containing the semantic segmentation annotations."""pts_semantic_mask_path = results['pts_semantic_mask_path']try:mask_bytes = get(pts_semantic_mask_path, backend_args=self.backend_args)# add .copy() to fix read-only bugpts_semantic_mask = np.frombuffer(mask_bytes, dtype=self.seg_3d_dtype).copy()except ConnectionError:mmengine.check_file_exist(pts_semantic_mask_path)pts_semantic_mask = np.fromfile(pts_semantic_mask_path, dtype=np.int64)if self.dataset_type == 'semantickitti':pts_semantic_mask = pts_semantic_mask.astype(np.int64)pts_semantic_mask = pts_semantic_mask % self.seg_offset# nuScenes loads semantic and panoptic labels from different files.results['pts_semantic_mask'] = pts_semantic_mask# 'eval_ann_info' will be passed to evaluatorif 'eval_ann_info' in results:results['eval_ann_info']['pts_semantic_mask'] = pts_semantic_maskreturn resultsdef _load_panoptic_3d(self, results: dict) -> dict:"""Private function to load 3D panoptic segmentation annotations.Args:results (dict): Result dict from :obj:`mmdet3d.CustomDataset`.Returns:dict: The dict containing the panoptic segmentation annotations."""pts_panoptic_mask_path = results['pts_panoptic_mask_path']try:mask_bytes = get(pts_panoptic_mask_path, backend_args=self.backend_args)# add .copy() to fix read-only bugpts_panoptic_mask = np.frombuffer(mask_bytes, dtype=self.seg_3d_dtype).copy()except ConnectionError:mmengine.check_file_exist(pts_panoptic_mask_path)pts_panoptic_mask = np.fromfile(pts_panoptic_mask_path, dtype=np.int64)if self.dataset_type == 'semantickitti':pts_semantic_mask = pts_panoptic_mask.astype(np.int64)pts_semantic_mask = pts_semantic_mask % self.seg_offsetelif self.dataset_type == 'nuscenes':pts_semantic_mask = pts_semantic_mask // self.seg_offsetresults['pts_semantic_mask'] = pts_semantic_mask# We can directly take panoptic labels as instance ids.pts_instance_mask = pts_panoptic_mask.astype(np.int64)results['pts_instance_mask'] = pts_instance_mask# 'eval_ann_info' will be passed to evaluatorif 'eval_ann_info' in results:results['eval_ann_info']['pts_semantic_mask'] = pts_semantic_maskresults['eval_ann_info']['pts_instance_mask'] = pts_instance_maskreturn resultsdef _load_bboxes(self, results: dict) -> None:"""Private function to load bounding box annotations.The only difference is it remove the proceess for`ignore_flag`Args:results (dict): Result dict from :obj:`mmcv.BaseDataset`.Returns:dict: The dict contains loaded bounding box annotations."""results['gt_bboxes'] = results['ann_info']['gt_bboxes']def _load_labels(self, results: dict) -> None:"""Private function to load label annotations.Args:results (dict): Result dict from :obj :obj:`mmcv.BaseDataset`.Returns:dict: The dict contains loaded label annotations."""results['gt_bboxes_labels'] = results['ann_info']['gt_bboxes_labels']def transform(self, results: dict) -> dict:"""Function to load multiple types annotations.Args:results (dict): Result dict from :obj:`mmdet3d.CustomDataset`.Returns:dict: The dict containing loaded 3D bounding box, label, mask andsemantic segmentation annotations."""results = super().transform(results)if self.with_bbox_3d:results = self._load_bboxes_3d(results)if self.with_bbox_depth:results = self._load_bboxes_depth(results)if self.with_label_3d:results = self._load_labels_3d(results)if self.with_attr_label:results = self._load_attr_labels(results)if self.with_panoptic_3d:results = self._load_panoptic_3d(results)if self.with_mask_3d:results = self._load_masks_3d(results)if self.with_seg_3d:results = self._load_semantic_seg_3d(results)return results
ObjectSample
数据增强。
create data步骤建立了一个关于数据集的gt object 库,即db_infos.pkl ,ObjectSample 在当前样本较少的情况下,从库里采样一些 gt object 填充到当前样本中。
mmdet3d/datasets/transforms/transforms_3d.py
源码
@TRANSFORMS.register_module()
class ObjectSample(BaseTransform):"""Sample GT objects to the data.Required Keys:- points- ann_info- gt_bboxes_3d- gt_labels_3d- img (optional)- gt_bboxes (optional)Modified Keys:- points- gt_bboxes_3d- gt_labels_3d- img (optional)- gt_bboxes (optional)Added Keys:- plane (optional)Args:db_sampler (dict): Config dict of the database sampler.sample_2d (bool): Whether to also paste 2D image patch to the images.This should be true when applying multi-modality cut-and-paste.Defaults to False.use_ground_plane (bool): Whether to use ground plane to adjust the3D labels. Defaults to False."""def __init__(self,db_sampler: dict,sample_2d: bool = False,use_ground_plane: bool = False) -> None:self.sampler_cfg = db_samplerself.sample_2d = sample_2dif 'type' not in db_sampler.keys():db_sampler['type'] = 'DataBaseSampler'self.db_sampler = TRANSFORMS.build(db_sampler)self.use_ground_plane = use_ground_planeself.disabled = False@staticmethoddef remove_points_in_boxes(points: BasePoints,boxes: np.ndarray) -> np.ndarray:"""Remove the points in the sampled bounding boxes.Args:points (:obj:`BasePoints`): Input point cloud array.boxes (np.ndarray): Sampled ground truth boxes.Returns:np.ndarray: Points with those in the boxes removed."""masks = box_np_ops.points_in_rbbox(points.coord.numpy(), boxes)points = points[np.logical_not(masks.any(-1))]return pointsdef transform(self, input_dict: dict) -> dict:"""Transform function to sample ground truth objects to the data.Args:input_dict (dict): Result dict from loading pipeline.Returns:dict: Results after object sampling augmentation,'points', 'gt_bboxes_3d', 'gt_labels_3d' keys are updatedin the result dict."""if self.disabled:return input_dictgt_bboxes_3d = input_dict['gt_bboxes_3d']gt_labels_3d = input_dict['gt_labels_3d']if self.use_ground_plane:ground_plane = input_dict.get('plane', None)assert ground_plane is not None, '`use_ground_plane` is True ' \'but find plane is None'else:ground_plane = None# change to float for blending operationpoints = input_dict['points']if self.sample_2d:img = input_dict['img']gt_bboxes_2d = input_dict['gt_bboxes']# Assume for now 3D & 2D bboxes are the samesampled_dict = self.db_sampler.sample_all(gt_bboxes_3d.numpy(),gt_labels_3d,gt_bboxes_2d=gt_bboxes_2d,img=img)else:sampled_dict = self.db_sampler.sample_all(gt_bboxes_3d.numpy(),gt_labels_3d,img=None,ground_plane=ground_plane)if sampled_dict is not None:sampled_gt_bboxes_3d = sampled_dict['gt_bboxes_3d']sampled_points = sampled_dict['points']sampled_gt_labels = sampled_dict['gt_labels_3d']gt_labels_3d = np.concatenate([gt_labels_3d, sampled_gt_labels],axis=0)gt_bboxes_3d = gt_bboxes_3d.new_box(np.concatenate([gt_bboxes_3d.numpy(), sampled_gt_bboxes_3d]))points = self.remove_points_in_boxes(points, sampled_gt_bboxes_3d)# check the points dimensionpoints = points.cat([sampled_points, points])if self.sample_2d:sampled_gt_bboxes_2d = sampled_dict['gt_bboxes_2d']gt_bboxes_2d = np.concatenate([gt_bboxes_2d, sampled_gt_bboxes_2d]).astype(np.float32)input_dict['gt_bboxes'] = gt_bboxes_2dinput_dict['img'] = sampled_dict['img']input_dict['gt_bboxes_3d'] = gt_bboxes_3dinput_dict['gt_labels_3d'] = gt_labels_3d.astype(np.int64)input_dict['points'] = pointsreturn input_dict
使用db_sample 类进行操作
sample_all:对所有种类的bbox进行采样:
sample_class_v2:对特定种类的包围盒进行采样
- 初始化 db_sampler ,在 db_sampler 初始化里面按照 difficulty 和 min_points 过滤掉 一些 gt object.
- 是否选择 sample_2d,调用相应的 db_sampler.sample_all
- db_sampler.sample_all() 的过程
- 计算每个类别需要 sample 的个数: 要求个数 减去 目前 gt label 中该类别个数
- 如果该类别的 gt objects 已经足够多,即需要 sample 的个数 <= 0,则不做任何 sample 操作,返回的 sample 结果为 None
- 如果该类别的 gt objects 比较少,则从 db_info 里面对应的类别 sample 所需数量的 object ,也就是从其他文件去 sample 一些 object 出来填充到当前文件的 gt 数据。比如用000005.bin 的一些 object 点云 补充到 000003.bin 去,并补充相应的 gt boxes.
- 得到 sample 结果之后,判断是否和已有的 gt boxes and sample boxes 冲突 (注意这里是将某类别的 sample 结果和目前所有类别的已有 boxes 判断冲突),保留那些没有冲突的 sample 结果作为该类别的 sample 结果
- concat sample 结果和原本的 gt labels and bboxes, 替换 gt point cloud 里面落在 sample boxes 里的 point 为 sample points
ObjectNoise
为每个场景的GT objects 增加一些噪声
输入参数
translation_std: List[float] = [0.25, 0.25, 0.25], # 平移标准差
global_rot_range: List[float] = [0.0, 0.0], # 旋转范围
rot_range: List[float] = [-0.15707963267, 0.15707963267], # 旋转角度范围
num_try: int = 100 # 个数
源码
ObjectNoise 调用 noise_per_object_v3_ 对每个 gt object 进行旋转、平移等操作,生成新的 gt object
def noise_per_object_v3_(gt_boxes,points=None,valid_mask=None,rotation_perturb=np.pi / 4,center_noise_std=1.0,global_random_rot_range=np.pi / 4,num_try=100)
RandomFlip3D
随机左右或前后翻转点云或者 bbox
参数
| args | description |
|---|---|
| sync_2d (bool) | 是否根据2D应用翻转图片。 如果为 True,它将应用与 2D 图像相同的翻转。如果为False,则会决定是否随机独立翻转到 2D 图像。 默认为 True。 |
| Flip_ratio_bev_horizontal (float) | 翻转概率在水平方向。 默认为 0.0。 |
| Flip_ratio_bev_vertical (float) | 翻转概率在垂直方向。 默认为 0.0。 |
| Flip_box3d (bool) | 是否翻转边界框。 在大多数情况下,盒子应该被翻转。 在基于凸轮的 bev 检测中,此设置为 False,因为 2D 图像的翻转不会影响 3D盒子。 默认为 True。 |
源码
def random_flip_data_3d(self,input_dict: dict,direction: str = 'horizontal') -> None:"""Flip 3D data randomly.`random_flip_data_3d` should take these situations into consideration:- 1. LIDAR-based 3d detection- 2. LIDAR-based 3d segmentation- 3. vision-only detection- 4. multi-modality 3d detection.Args:input_dict (dict): Result dict from loading pipeline.direction (str): Flip direction. Defaults to 'horizontal'.Returns:dict: Flipped results, 'points', 'bbox3d_fields' keys areupdated in the result dict."""assert direction in ['horizontal', 'vertical']if self.flip_box3d:if 'gt_bboxes_3d' in input_dict:if 'points' in input_dict:input_dict['points'] = input_dict['gt_bboxes_3d'].flip(direction, points=input_dict['points'])else:# vision-only detectioninput_dict['gt_bboxes_3d'].flip(direction)else:input_dict['points'].flip(direction)if 'centers_2d' in input_dict:assert self.sync_2d is True and direction == 'horizontal', \'Only support sync_2d=True and horizontal flip with images'w = input_dict['img_shape'][1]input_dict['centers_2d'][..., 0] = \w - input_dict['centers_2d'][..., 0]# need to modify the horizontal position of camera center# along u-axis in the image (flip like centers2d)# ['cam2img'][0][2] = c_u# see more details and examples at# https://github.com/open-mmlab/mmdetection3d/pull/744input_dict['cam2img'][0][2] = w - input_dict['cam2img'][0][2]def _flip_on_direction(self, results: dict) -> None:"""Function to flip images, bounding boxes, semantic segmentation mapand keypoints.Add the override feature that if 'flip' is already in results, use itto do the augmentation."""if 'flip' not in results:cur_dir = self._choose_direction()else:# `flip_direction` works only when `flip` is True.# For example, in `MultiScaleFlipAug3D`, `flip_direction` is# 'horizontal' but `flip` is False.if results['flip']:assert 'flip_direction' in results, 'flip and flip_direction ''must exist simultaneously'cur_dir = results['flip_direction']else:cur_dir = Noneif cur_dir is None:results['flip'] = Falseresults['flip_direction'] = Noneelse:results['flip'] = Trueresults['flip_direction'] = cur_dirself._flip(results)def transform(self, input_dict: dict) -> dict:"""Call function to flip points, values in the ``bbox3d_fields`` andalso flip 2D image and its annotations.Args:input_dict (dict): Result dict from loading pipeline.Returns:dict: Flipped results, 'flip', 'flip_direction','pcd_horizontal_flip' and 'pcd_vertical_flip' keys are addedinto result dict."""# flip 2D image and its annotationsif 'img' in input_dict:super(RandomFlip3D, self).transform(input_dict)if self.sync_2d and 'img' in input_dict:input_dict['pcd_horizontal_flip'] = input_dict['flip']input_dict['pcd_vertical_flip'] = Falseelse:if 'pcd_horizontal_flip' not in input_dict:flip_horizontal = True if np.random.rand() < self.flip_ratio_bev_horizontal else Falseinput_dict['pcd_horizontal_flip'] = flip_horizontalif 'pcd_vertical_flip' not in input_dict:flip_vertical = True if np.random.rand() < self.flip_ratio_bev_vertical else Falseinput_dict['pcd_vertical_flip'] = flip_verticalif 'transformation_3d_flow' not in input_dict:input_dict['transformation_3d_flow'] = []if input_dict['pcd_horizontal_flip']:self.random_flip_data_3d(input_dict, 'horizontal')input_dict['transformation_3d_flow'].extend(['HF'])if input_dict['pcd_vertical_flip']:self.random_flip_data_3d(input_dict, 'vertical')input_dict['transformation_3d_flow'].extend(['VF'])return input_dict
主要使用了flip 的方法进行取反颠倒操作
class LiDARPoints(BasePoints):"""Points of instances in LIDAR coordinates.# ...def flip(self, bev_direction: str = 'horizontal') -> None:"""Flip the points along given BEV direction.Args:bev_direction (str): Flip direction (horizontal or vertical).Defaults to 'horizontal'."""assert bev_direction in ('horizontal', 'vertical')if bev_direction == 'horizontal':self.tensor[:, 1] = -self.tensor[:, 1]elif bev_direction == 'vertical':self.tensor[:, 0] = -self.tensor[:, 0]
GlobalRotScaleTrans
数据增广的一种方式,对输入点云进行随机旋转和放缩变换
将全局旋转、缩放和平移应用于 3D 场景
参数
| args | description |
|---|---|
| rot_range (list[float]) | 旋转角度范围。默认为 [-0.78539816, 0.78539816](接近 [-pi/4, pi/4])。 |
| scale_ratio_range (list[float]) | 比例范围。默认为 [0.95, 1.05]。 |
| Translation_std (list[float]) | 标准差应用于场景的平移噪声,其中从高斯分布中采样,其标准差由“translation_std”设置。 默认 |
| shift_height (bool) | 是否移动高度。(室内点的第四维)缩放时。默认为 False。 |
源码
def _trans_bbox_points(self, input_dict: dict) -> None:"""Private function to translate bounding boxes and points.Args:input_dict (dict): Result dict from loading pipeline.Returns:dict: Results after translation, 'points', 'pcd_trans'and `gt_bboxes_3d` is updated in the result dict."""translation_std = np.array(self.translation_std, dtype=np.float32)trans_factor = np.random.normal(scale=translation_std, size=3).Tinput_dict['points'].translate(trans_factor)input_dict['pcd_trans'] = trans_factorif 'gt_bboxes_3d' in input_dict:input_dict['gt_bboxes_3d'].translate(trans_factor)def _rot_bbox_points(self, input_dict: dict) -> None:"""Private function to rotate bounding boxes and points.Args:input_dict (dict): Result dict from loading pipeline.Returns:dict: Results after rotation, 'points', 'pcd_rotation'and `gt_bboxes_3d` is updated in the result dict."""rotation = self.rot_rangenoise_rotation = np.random.uniform(rotation[0], rotation[1])if 'gt_bboxes_3d' in input_dict and \len(input_dict['gt_bboxes_3d'].tensor) != 0:# rotate points with bboxespoints, rot_mat_T = input_dict['gt_bboxes_3d'].rotate(noise_rotation, input_dict['points'])input_dict['points'] = pointselse:# if no bbox in input_dict, only rotate pointsrot_mat_T = input_dict['points'].rotate(noise_rotation)input_dict['pcd_rotation'] = rot_mat_Tinput_dict['pcd_rotation_angle'] = noise_rotationdef _scale_bbox_points(self, input_dict: dict) -> None:"""Private function to scale bounding boxes and points.Args:input_dict (dict): Result dict from loading pipeline.Returns:dict: Results after scaling, 'points' and`gt_bboxes_3d` is updated in the result dict."""scale = input_dict['pcd_scale_factor']points = input_dict['points']points.scale(scale)if self.shift_height:assert 'height' in points.attribute_dims.keys(), \'setting shift_height=True but points have no height attribute'points.tensor[:, points.attribute_dims['height']] *= scaleinput_dict['points'] = pointsif 'gt_bboxes_3d' in input_dict and \len(input_dict['gt_bboxes_3d'].tensor) != 0:input_dict['gt_bboxes_3d'].scale(scale)def _random_scale(self, input_dict: dict) -> None:"""Private function to randomly set the scale factor.Args:input_dict (dict): Result dict from loading pipeline.Returns:dict: Results after scaling, 'pcd_scale_factor'are updated in the result dict."""scale_factor = np.random.uniform(self.scale_ratio_range[0],self.scale_ratio_range[1])input_dict['pcd_scale_factor'] = scale_factordef transform(self, input_dict: dict) -> dict:"""Private function to rotate, scale and translate bounding boxes andpoints.Args:input_dict (dict): Result dict from loading pipeline.Returns:dict: Results after scaling, 'points', 'pcd_rotation','pcd_scale_factor', 'pcd_trans' and `gt_bboxes_3d` are updatedin the result dict."""if 'transformation_3d_flow' not in input_dict:input_dict['transformation_3d_flow'] = []self._rot_bbox_points(input_dict)if 'pcd_scale_factor' not in input_dict:self._random_scale(input_dict)self._scale_bbox_points(input_dict)self._trans_bbox_points(input_dict)input_dict['transformation_3d_flow'].extend(['R', 'S', 'T'])return input_dict
PointsRangeFilter
通过设置点云范围,PointsRangeFilter用于过滤点云及其掩模(语义和实例)
源码
def transform(self, input_dict: dict) -> dict:"""Transform function to filter points by the range.Args:input_dict (dict): Result dict from loading pipeline.Returns:dict: Results after filtering, 'points', 'pts_instance_mask'and 'pts_semantic_mask' keys are updated in the result dict."""points = input_dict['points']points_mask = points.in_range_3d(self.pcd_range)clean_points = points[points_mask]input_dict['points'] = clean_pointspoints_mask = points_mask.numpy()pts_instance_mask = input_dict.get('pts_instance_mask', None)pts_semantic_mask = input_dict.get('pts_semantic_mask', None)if pts_instance_mask is not None:input_dict['pts_instance_mask'] = pts_instance_mask[points_mask]if pts_semantic_mask is not None:input_dict['pts_semantic_mask'] = pts_semantic_mask[points_mask]return input_dict
通过获取范围内点云的mask,对点进行过滤。本质上还是通过范围比较进行
def in_range_3d(self, box_range: Union[Tensor, np.ndarray,Sequence[float]]) -> Tensor:"""Check whether the boxes are in the given range.Args:box_range (Tensor or np.ndarray or Sequence[float]): The range ofbox (x_min, y_min, z_min, x_max, y_max, z_max).Note:In the original implementation of SECOND, checking whether a box inthe range checks whether the points are in a convex polygon, we tryto reduce the burden for simpler cases.Returns:Tensor: A binary vector indicating whether each point is inside thereference range."""in_range_flags = ((self.tensor[:, 0] > box_range[0])& (self.tensor[:, 1] > box_range[1])& (self.tensor[:, 2] > box_range[2])& (self.tensor[:, 0] < box_range[3])& (self.tensor[:, 1] < box_range[4])& (self.tensor[:, 2] < box_range[5]))return in_range_flags
ObjectRangeFilter
ObjectRangeFilter用于过滤3D边界框。
源码
class ObjectRangeFilter(BaseTransform):"""Filter objects by the range.Required Keys:- gt_bboxes_3dModified Keys:- gt_bboxes_3dArgs:point_cloud_range (list[float]): Point cloud range."""def __init__(self, point_cloud_range: List[float]) -> None:self.pcd_range = np.array(point_cloud_range, dtype=np.float32)def transform(self, input_dict: dict) -> dict:"""Transform function to filter objects by the range.Args:input_dict (dict): Result dict from loading pipeline.Returns:dict: Results after filtering, 'gt_bboxes_3d', 'gt_labels_3d'keys are updated in the result dict."""# Check points instance type and initialise bev_rangeif isinstance(input_dict['gt_bboxes_3d'],(LiDARInstance3DBoxes, DepthInstance3DBoxes)):bev_range = self.pcd_range[[0, 1, 3, 4]]elif isinstance(input_dict['gt_bboxes_3d'], CameraInstance3DBoxes):bev_range = self.pcd_range[[0, 2, 3, 5]]gt_bboxes_3d = input_dict['gt_bboxes_3d']gt_labels_3d = input_dict['gt_labels_3d']mask = gt_bboxes_3d.in_range_bev(bev_range)gt_bboxes_3d = gt_bboxes_3d[mask]# mask is a torch tensor but gt_labels_3d is still numpy array# using mask to index gt_labels_3d will cause bug when# len(gt_labels_3d) == 1, where mask=1 will be interpreted# as gt_labels_3d[1] and cause out of index errorgt_labels_3d = gt_labels_3d[mask.numpy().astype(bool)]# limit rad to [-pi, pi]gt_bboxes_3d.limit_yaw(offset=0.5, period=2 * np.pi)input_dict['gt_bboxes_3d'] = gt_bboxes_3dinput_dict['gt_labels_3d'] = gt_labels_3dreturn input_dict
通过判断 gt_bboxes_3d是否在 bev的范围内对 box及label进行筛选
def in_range_bev(self, box_range: Union[Tensor, np.ndarray,Sequence[float]]) -> Tensor:"""Check whether the boxes are in the given range.Args:box_range (Tensor or np.ndarray or Sequence[float]): The range ofbox in order of (x_min, y_min, x_max, y_max).Note:The original implementation of SECOND checks whether boxes in arange by checking whether the points are in a convex polygon, wereduce the burden for simpler cases.Returns:Tensor: A binary vector indicating whether each box is inside thereference range."""in_range_flags = ((self.bev[:, 0] > box_range[0])& (self.bev[:, 1] > box_range[1])& (self.bev[:, 0] < box_range[2])& (self.bev[:, 1] < box_range[3]))return in_range_flags
ObjectNameFilter
通过名字对 GT objects 进行过滤。即通过输入为训练而保留的gt labels,对所有的输入的 gt 框进行过滤。
源码
@TRANSFORMS.register_module()
class ObjectNameFilter(BaseTransform):"""Filter GT objects by their names.Required Keys:- gt_labels_3dModified Keys:- gt_labels_3dArgs:classes (list[str]): List of class names to be kept for training."""def __init__(self, classes: List[str]) -> None:self.classes = classesself.labels = list(range(len(self.classes)))def transform(self, input_dict: dict) -> dict:"""Transform function to filter objects by their names.Args:input_dict (dict): Result dict from loading pipeline.Returns:dict: Results after filtering, 'gt_bboxes_3d', 'gt_labels_3d'keys are updated in the result dict."""gt_labels_3d = input_dict['gt_labels_3d']# 此处为对labels 进行过滤,生成maskgt_bboxes_mask = np.array([n in self.labels for n in gt_labels_3d],dtype=bool)input_dict['gt_bboxes_3d'] = input_dict['gt_bboxes_3d'][gt_bboxes_mask]input_dict['gt_labels_3d'] = input_dict['gt_labels_3d'][gt_bboxes_mask]return input_dict
PointShuffle
随机排列输入点
源码
@TRANSFORMS.register_module()
class PointShuffle(BaseTransform):"""Shuffle input points."""def transform(self, input_dict: dict) -> dict:"""Call function to shuffle points.Args:input_dict (dict): Result dict from loading pipeline.Returns:dict: Results after filtering, 'points', 'pts_instance_mask'and 'pts_semantic_mask' keys are updated in the result dict."""idx = input_dict['points'].shuffle()idx = idx.numpy()pts_instance_mask = input_dict.get('pts_instance_mask', None)pts_semantic_mask = input_dict.get('pts_semantic_mask', None)if pts_instance_mask is not None:input_dict['pts_instance_mask'] = pts_instance_mask[idx]if pts_semantic_mask is not None:input_dict['pts_semantic_mask'] = pts_semantic_mask[idx]return input_dict
通过调用 shuffle 函数实现
def shuffle(self) -> Tensor:"""Shuffle the points.Returns:Tensor: The shuffled index."""idx = torch.randperm(self.__len__(), device=self.tensor.device)self.tensor = self.tensor[idx]return idx
Pack3DDetInputs
打包输入数据的方法。 当字典中的值是一个列表时,表示该值通常应用在增强测试中
在最新版本代码中,DefaultFormatBundle3D 和 Collect3D 替换为 PackDet3DInputs,将数据打包为元素格式作为模型输入。
源码
def transform(self, results: Union[dict,List[dict]]) -> Union[dict, List[dict]]:"""Method to pack the input data. when the value in this dict is alist, it usually is in Augmentations Testing.Args:results (dict | list[dict]): Result dict from the data pipeline.Returns:dict | List[dict]:- 'inputs' (dict): The forward data of models. It usually containsfollowing keys:- points- img- 'data_samples' (:obj:`Det3DDataSample`): The annotation info ofthe sample."""# augtestif isinstance(results, list):if len(results) == 1:# simple testreturn self.pack_single_results(results[0])pack_results = []for single_result in results:pack_results.append(self.pack_single_results(single_result))return pack_results# norm training and simple testingelif isinstance(results, dict):return self.pack_single_results(results)else:raise NotImplementedErrordef pack_single_results(self, results: dict) -> dict:"""Method to pack the single input data. when the value in this dict isa list, it usually is in Augmentations Testing.Args:results (dict): Result dict from the data pipeline.Returns:dict: A dict contains- 'inputs' (dict): The forward data of models. It usually containsfollowing keys:- points- img- 'data_samples' (:obj:`Det3DDataSample`): The annotation infoof the sample."""# Format 3D dataif 'points' in results:if isinstance(results['points'], BasePoints):results['points'] = results['points'].tensorif 'img' in results:if isinstance(results['img'], list):# process multiple imgs in single frameimgs = np.stack(results['img'], axis=0)if imgs.flags.c_contiguous:imgs = to_tensor(imgs).permute(0, 3, 1, 2).contiguous()else:imgs = to_tensor(np.ascontiguousarray(imgs.transpose(0, 3, 1, 2)))results['img'] = imgselse:img = results['img']if len(img.shape) < 3:img = np.expand_dims(img, -1)# To improve the computational speed by by 3-5 times, apply:# `torch.permute()` rather than `np.transpose()`.# Refer to https://github.com/open-mmlab/mmdetection/pull/9533# for more detailsif img.flags.c_contiguous:img = to_tensor(img).permute(2, 0, 1).contiguous()else:img = to_tensor(np.ascontiguousarray(img.transpose(2, 0, 1)))results['img'] = imgfor key in ['proposals', 'gt_bboxes', 'gt_bboxes_ignore', 'gt_labels','gt_bboxes_labels', 'attr_labels', 'pts_instance_mask','pts_semantic_mask', 'centers_2d', 'depths', 'gt_labels_3d']:if key not in results:continueif isinstance(results[key], list):results[key] = [to_tensor(res) for res in results[key]]else:results[key] = to_tensor(results[key])if 'gt_bboxes_3d' in results:if not isinstance(results['gt_bboxes_3d'], BaseInstance3DBoxes):results['gt_bboxes_3d'] = to_tensor(results['gt_bboxes_3d'])if 'gt_semantic_seg' in results:results['gt_semantic_seg'] = to_tensor(results['gt_semantic_seg'][None])if 'gt_seg_map' in results:results['gt_seg_map'] = results['gt_seg_map'][None, ...]data_sample = Det3DDataSample()gt_instances_3d = InstanceData()gt_instances = InstanceData()gt_pts_seg = PointData()data_metas = {}for key in self.meta_keys:if key in results:data_metas[key] = results[key]elif 'images' in results:if len(results['images'].keys()) == 1:cam_type = list(results['images'].keys())[0]# single-view imageif key in results['images'][cam_type]:data_metas[key] = results['images'][cam_type][key]else:# multi-view imageimg_metas = []cam_types = list(results['images'].keys())for cam_type in cam_types:if key in results['images'][cam_type]:img_metas.append(results['images'][cam_type][key])if len(img_metas) > 0:data_metas[key] = img_metaselif 'lidar_points' in results:if key in results['lidar_points']:data_metas[key] = results['lidar_points'][key]data_sample.set_metainfo(data_metas)inputs = {}for key in self.keys:if key in results:if key in self.INPUTS_KEYS:inputs[key] = results[key]elif key in self.INSTANCEDATA_3D_KEYS:gt_instances_3d[self._remove_prefix(key)] = results[key]elif key in self.INSTANCEDATA_2D_KEYS:if key == 'gt_bboxes_labels':gt_instances['labels'] = results[key]else:gt_instances[self._remove_prefix(key)] = results[key]elif key in self.SEG_KEYS:gt_pts_seg[self._remove_prefix(key)] = results[key]else:raise NotImplementedError(f'Please modified 'f'`Pack3DDetInputs` 'f'to put {key} to 'f'corresponding field')data_sample.gt_instances_3d = gt_instances_3ddata_sample.gt_instances = gt_instancesdata_sample.gt_pts_seg = gt_pts_segif 'eval_ann_info' in results:data_sample.eval_ann_info = results['eval_ann_info']else:data_sample.eval_ann_info = Nonepacked_results = dict()packed_results['data_samples'] = data_samplepacked_results['inputs'] = inputsreturn packed_results
通过预先设定的keys 和 meta_keys ,整理结果数据,输出data pipeline 的字典结果
keys = ['proposals', 'gt_bboxes', 'gt_bboxes_ignore', 'gt_labels','gt_bboxes_labels', 'attr_labels', 'pts_instance_mask','pts_semantic_mask', 'centers_2d', 'depths', 'gt_labels_3d']meta_keys: tuple = ('img_path', 'ori_shape', 'img_shape', 'lidar2img','depth2img', 'cam2img', 'pad_shape','scale_factor', 'flip', 'pcd_horizontal_flip','pcd_vertical_flip', 'box_mode_3d', 'box_type_3d','img_norm_cfg', 'num_pts_feats', 'pcd_trans','sample_idx', 'pcd_scale_factor', 'pcd_rotation','pcd_rotation_angle', 'lidar_path','transformation_3d_flow', 'trans_mat','affine_aug', 'sweep_img_metas', 'ori_cam2img','cam2global', 'crop_offset', 'img_crop_offset','resize_img_shape', 'lidar2cam', 'ori_lidar2img','num_ref_frames', 'num_views', 'ego2global')
Reference
- [开源框架]mmdetection3d学习(三):数据加载