一、泛型编程思想
- 首先我们来看一下下面这三个函数,如果学习过了 C++函数重载 和 C++引用 的话,就可以知道下面这三个函数是可以共存的,而且传值会很方便
-
void Swap(int& left, int& right) {int temp = left;left = right;right = temp; } void Swap(double& left, double& right) {double temp = left;left = right;right = temp; } void Swap(char& left, char& right) {char temp = left;left = right;right = temp; }
但是真的很方便吗?这里只有三种类型的数据需要交换,若是我们需要增加交换的数据呢?再CV然后写一个函数吗?
这肯定是不现实的,所以很明显函数重载虽然可以实现,但是有一下几个不好的地方:
- 重载的函数仅仅是类型不同,代码复用率比较低,只要有新类型出现时,就需要用户自己增加对应的函数
- 代码的可维护性比较低,一个出错可能所有的重载均出错
那是否能做到这么一点,告诉编译器一个模子,让编译器根据不同的类型利用该模子来生成代码
这样,我们先通过一个案例来做引入
- 才高八斗的魏武帝之子【曹植】曾经写过一首《洛神赋》,被后人誉为“千古第一绝世神仙诗”,因此在那个时候被很多文人所抄录、传唱,其共1089个字,想要一字不落地抄录下来还是需要时间,那古代还有一些更长的诗赋,例如:《离骚》,足足有2500多字,若也是一个一个地抄录下来的话,那会变得极为麻烦

- 于是呢古人又发明了一种东西叫做【活字印刷术】,有了此技术之后,人们不再需要每次去手抄一些诗赋书籍,只需要作一份模版字体,然后在其上刷上水,刷上墨,然后拿纸这么一印,就可以得到一份工整的印刷体了

💬 所以,总结上面的这么一个技术,C++的祖师爷呢就想到了【模版】这个东西,告诉编译器一个模子,然后其余的工作交给它来完成,根据不同的需求生成不同的代码
这就是👉泛型编程:编写与类型无关的通用代码,是代码复用的一种手段。模板是泛型编程的基础
二、函数模版
知晓了模版的基本概念后,首先我们要来看的就是【函数模版】
1、函数模板概念
函数模板代表了一个函数家族,该函数模板与类型无关,在使用时被参数化,根据实参类型产生函数的特定类型版本
通过函数模板,可以编写一种通用的函数定义,使其能够适用于多种数据类型,从而提高代码的复用性和灵活性。
2、函数模板格式
- 然后正式来声明一个函数模版,这里我们要学一个新的关键字叫template,接下去加一个<>尖括号,内部就是模版的参数了,可以使用typename或者class来进行类型的声明(不可以用struct),若是只有一个类型的话我们一般会叫做【T】,不过这个没有强制要求
template<typename T1, typename T2,......,typename Tn>
- 接下去就可以使用上面所声明的模版参数了,即上面的这个【T】,它和我们普通的函数参数可不一样,后者是定义的是对象,而前者定义的是类型
返回值类型 函数名(参数列表){}马上,我们就来为上面的
swap()函数写一个通用的函数模版把template<typename T> void Swap(T& left, T& right) {T temp = left;left = right;right = temp; } - 然后来用一用这个函数模版,分别传入不同数据类型的参数,通过结果的观察可以发现这个函数模版可以根据不同的类型去做一个自动推导,继而去起到一个交换的功能

- 我们可以通过调试来进一步观察,发现无论是对于【整型】还是【浮点型】,都会去走这个
Swap()函数,函数模版都可以进行自动的识别
那我现在想问一个问题,请问它们调用的真的是同一个函数吗?
- 相信很多同学都说是的,上面不是演示过了吗?但是看完下面这一小节你就不会这么说了👇
3、函数模板的原理
接下去我们来说说这个函数模版的原理,带你理清编译器内部究竟做了什么事情
- 对于函数模板而言其实是一个【蓝图】,它本身并不是函数,是编译器用使用方式产生特定具体类型函数的模具。所以其实模板就是将本来应该我们做的重复的事情交给了编译器,让我们来看看编译器做了什么

- 可以发现,在进行汇编代码查看的时候,被调用的函数模版生成了两个不同的函数,它们有着不同的函数地址,因此可以回答上一小节所提出的问题了,两次所调用的函数是不一样的,是根据函数模版所生成的
还是不太懂的老铁可以看看下面这张图,就能明白了
- 在编译器编译阶段,对于模板函数的使用,编译器需要根据传入的实参类型来推演生成对应类型的函数以供调用。比如:当用int类型使用函数模板时,编译器通过对实参类型的推演,将T确定为int类型,然后产生一份专门处理int类型的代码,对于浮点类型、字符型也是如此

💬 那我现在还想问,如果我使用的是两个日期类Date的对象呢,能不能对它们进行交换
- 答案是可以的,int、double、char这些都是内置类型,Date呢是自定义类型,很明显它们都是类型,我们所定义的模版参数也是类型,那为何不可去做一个接受呢?从运行结果可以来看,确实是可以发现它们也发生了一个交换

💬 那如果是指针呢?也会去调用吗?
- 如何你学的扎实得话,立马就能反应过来了,对于指针而言也是内置类型,那既然是类型的话为何不能调用呢?

既然谈到了这个【Swap】交换函数,我们就顺便来说说库里的这个【swap】
- 仔细观察下图可以发现我将Swap前面大写S改成了小写s,它就是std标准库的里面的一个函数,也包含在STL的基本算法中

- 进到文档里面进行查看我们可以发现这个函数确实已经实现了【函数模版】,因此可以接收任何类型的数据,所以在学习了函数模版后我们就不需要自己再去写
swap()函数了,直接用库里的即可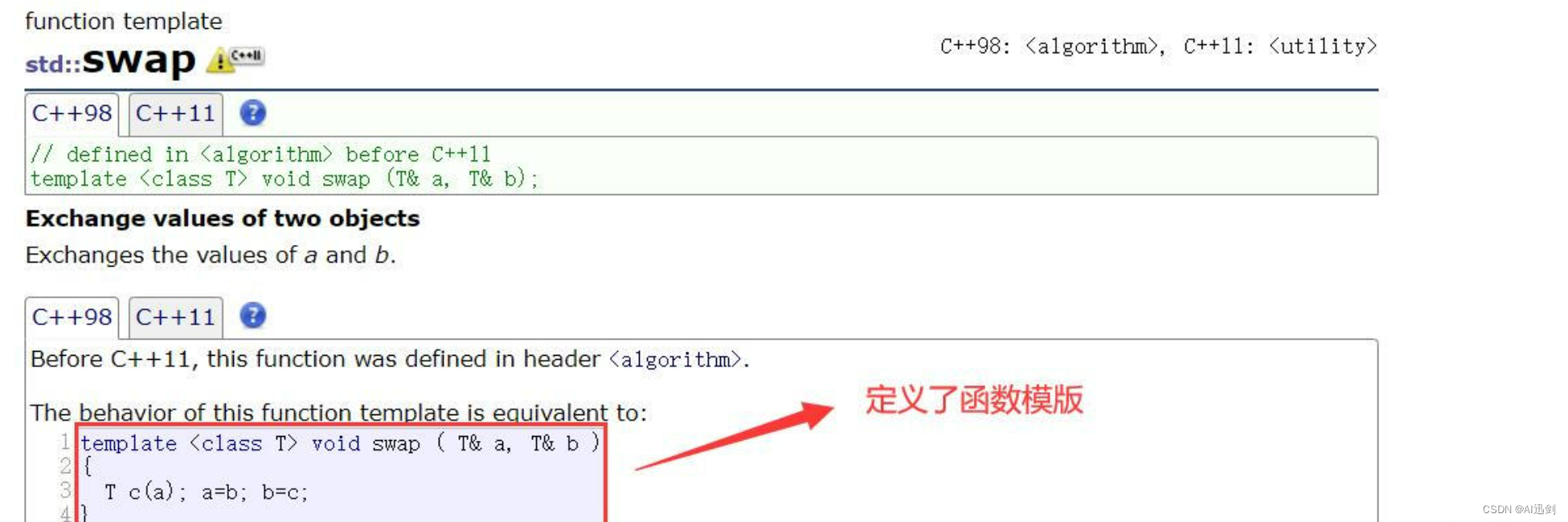
4、函数模板的实例化
上面我们所定义的都是单个模版参数,那多个模版参数是否可以定义呢?
- 这个当然是可以的,我们立马来试试看吧
template<typename T1, typename T2> T1 Func(const T1& x, const T2& y) {cout << x << " " << y << endl; } - 通过运行可以发现,是完全可以做到的,去定义多个模版参数,这个特性本文就不做距离了,等我们学习了一些STL之后再【模版进阶】一文中详解

然后我们来讲讲【函数模板的实例化】
👉 用不同类型的参数使用函数模板时,称为函数模板的实例化。模板参数实例化分为:隐式实例化和显式实例化
- 隐式实例化:让编译器根据实参推演模板参数的实际类型
- 知道模版可以定义多个参数之后,其返回值也可以是模版参数
template<class T> T Add(const T& left, const T& right) {return left + right; } - 下面这种就是【隐式实例化】,让编译器根据实参自动去推导模板参数的实际类型,然后返回返回不同类型的数据
int main() {int a1 = 10, a2 = 20;double d1 = 10.0, d2 = 20.0;// 根据实参传递的类型,推演T的类型cout << Add(a1, a2) << endl;cout << Add(d1, d2) << endl; }
-
但是呢像下面这种就不可以了,因为a1是【int】类型,d1是【double】类型,在编译期间,当编译器看到该实例化时,需要推演其实参类型 通过实参a1将T推演为int类型,通过实参d1将T推演为double类型,但模板参数列表中只有一个T, 编译器无法确定此处到底该将T确定为int 或者 double类型而报错。此时在函数调用完后进行返回时,编译器也识别不出是哪个类型了,它们两个就像在打架一样,很难一绝高下
cout << Add(a1, d2) << endl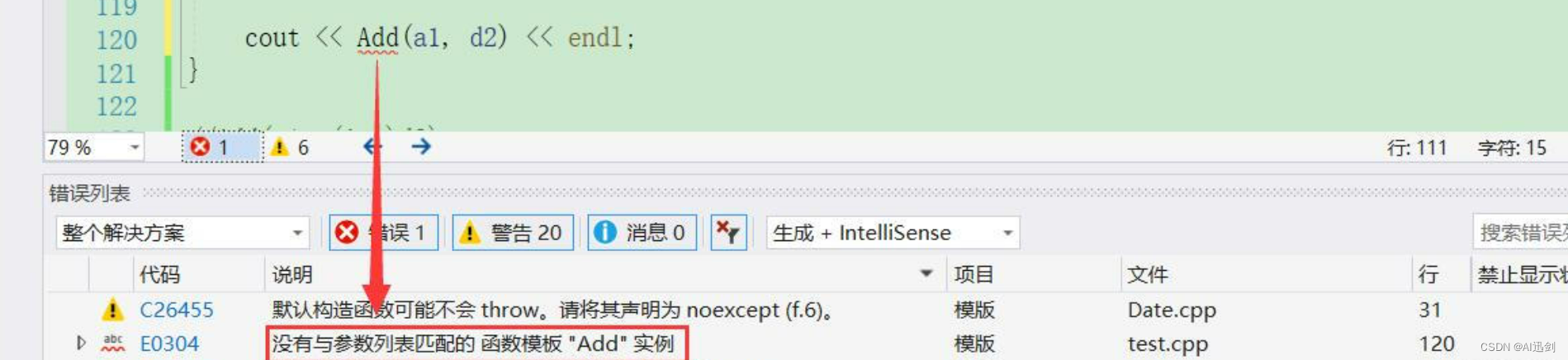
好比你做错事了,你爸爸让你罚站,不让你吃饭,此时呢你妈妈回来了,让你赶紧过来吃饭,那此时你该听谁的呢?
- 那此时呢就需要爸爸妈妈回房间商量一下了,到底是以谁说的话为主呢

那当他们商量好了之后,就会有下面这两种情况
- 这一种改法便是听爸爸的,后者d1强转为
int类型然后再传递进去,此时就不会出现类型冲突的问题了cout << Add(a1, (int)d2) << endl; - 这种改法便是听妈妈的,前者a1强转为
double类型然后再传递进去,也不会出现类型冲突的问题cout << Add((double)a1, d2) << endl;
- 显式实例化:在函数名后的<>中指定模板参数的实际类型
- 除了上面这种手动强转的措施,还有一种办法就是我们自己进行【显式实例化】,如何你还有印象的话,可以翻上看看汇编,其实编译器在底层就是转换为了这种形式
// 显式实例化,用指定类型实例化
cout << Add<int>(a1, d2) << endl;
cout << Add<double>(a1, d2) << endl;

虽然上面我们介绍了两种处理方式,但是对于某些场景来说,却只能进行【显式实例化】
- 例如我在下面写了一个函数模版,形参部分并不是模版参数,而是普通的自定义类型,之后返回值才是,那此时我们就无法通过传参来指定这个【T】的类型,只能有外部在调用这个模版的时候显示指定
template<class T> T* Alloc(int n) {return new T[n]; } - 例如下面的这些,我们想开什么数据类型的空间,只需要显示指定类型即可
// 有些函数无法自动推,只能显示实例化 double* p1 = Alloc<double>(10); float* p1 = Alloc<float>(20); int* p2 = Alloc<int>(30);5、模板参数的匹配原则
① 一个非模板函数可以和一个同名的函数模板同时存在,而且该函数模板还可以被实例化为这个非模板函数
- 可以看到,我在下面写了一个专门处理int的加法函数,为普通的函数,又写了一个函数模版,它们是可以进行共存的,在进行普通传参的时候,就会去调用这个普通的Add函数;若是显式指明了类型的话,就会去调用这个函数模版让编译器生成对应的函数
// 专门处理int的加法函数 int Add(int left, int right) {return left + right; }// 通用加法函数 template<class T> T Add(T left, T right) {return left + right; }int main(void) {Add(1, 2);Add<int>(1, 2);return 0; }
② 对于非模板函数和同名函数模板,如果其他条件都相同,在调动时会优先调用非模板函数而不会从该模板产生出一个实例。如果模板可以产生一个具有更好匹配的函数, 那么将选择模板
- 也是和上面类似的代码,不过对于函数模版这一块我使用到了两个模版参数,就是为了匹配多种数据类型
// 专门处理int的加法函数
int Add(int left, int right)
{return left + right;
}// 通用加法函数
template<class T1, class T2>
T1 Add(T1 left, T2 right)
{return left + right;
}int main(void)
{Add(1, 2);Add(1, 2.2);return 0;
}
- 观察调试结果我们可以发现Add(1, 2)优先去调了普通的加法函数,因为传递进去的是两个【int】类型的参数,完全吻合;但是呢对于第二个Add(1, 2.2)来说,却去调用了函数模版,因为第二个参数是【double】类型,普通的函数它也接不住呀,此时模版参数就可以根据这个类型来进行一个自动推导

③ 模板函数不允许自动类型转换,但普通函数可以进行自动类型转换
- 首先对于普通函数而言很好理解,看到print函数的形参所给的类型为【int】,但是在外界传入了一个【double】类型的数值,如果你学习过 隐式类型转换 的话,就可以知道这个浮点数传入的话会发生一个转换,这就叫做【自动类型转换】
// 普通函数,允许自动类型转换 void print(int value) {std::cout << "Integer: " << value << std::endl; }int main() {print(3); print(3.14); return 0; } - 但是呢,对于模版函数来说是无法进行自动类型转换的,例如下面这个,我为这个函数模版定义了一个模版参数,但是在外界进行传递的时候却传递进来两种数据类型,为【int】或【double】,那么一个模版参数T就使得编译器无法去进行自动推导
template <class T> void print(T a, T b) {cout << a << " " << b << endl; }int a = 1; double b = 1.11;print(a, b);
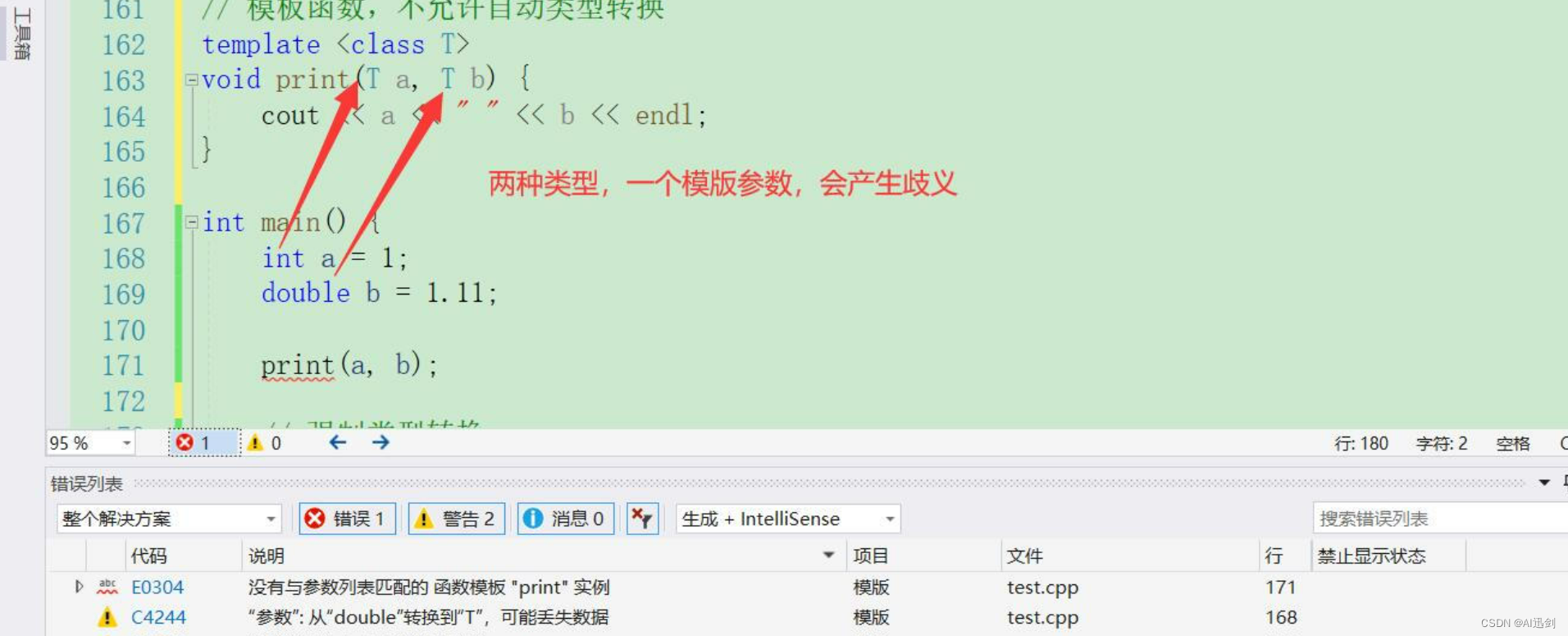
- 这个其实我们在上面也讲到过,再来回顾一下,改进的方法有两种,一个是【强制类型转换】,还记得罚站的事情吗;另一个则是【显式实例化】,还记得我们看的汇编吗
// 强制类型转换 print(a, (int)b); print((double)a, b); // 显式实例化 print<int>(a, b); print<double>(a, b); - 其实还有一种改进的方法,那就是增加模版参数,因为一个模版参数接收两种类型是无法进行自动推导的,此时若是有两个模版参数的话就可以接收两种类型了,不会出现错误

三、类模版
讲完了函数模版后,我们再来说说类模版,也就是对一个类来说,也是可以定义为一个模版的
1、类模板的定义格式
- 首先来看到的就是其定义格式,函数模版加在函数上,那对于类模版的话就是加在类上
template<class T1, class T2, ..., class Tn> class 类模板名 {// 类内成员定义 };我们以下面这个Stack类为例来进行讲解
- 如果你学习了模版的相关知识后,一定会觉得这个类的限制性太大了,只能初始化一个具有整型数据的栈,如果此时我想要放一些浮点型的数据进来的话也做不到
typedef int DataType; class Stack { public:Stack(size_t capacity = 3){_array = (DataType*)malloc(sizeof(DataType) * capacity);if (NULL == _array){perror("malloc申请空间失败!!!");return;}_capacity = capacity;_size = 0;}void Push(DataType data){// CheckCapacity();_array[_size] = data;_size++;}// 其他方法...~Stack(){if (_array){free(_array);_array = NULL;_capacity = 0;_size = 0;}} private:DataType* _array;int _capacity;int _size; };💬 如果没有模版技术的话你会如何去解决这个问题呢?很简单那就是定义多个类
- 这是我们同学最擅长的事,CV一下两个栈就有了,
StackInt存放整型数据,StackDouble存放浮点型数据
但是本文我们重点要讲解的就是【模版技术】,技术界有一句话说得好 “不要重复造轮子”
- 下面就是使用模版去定义的一个类,简称【模板类】,不限制死数据类型,将所有的DataType都改为【T】
template<class T> class Stack { public:Stack(size_t capacity = 3){_array = (DataType*)malloc(sizeof(DataType) * capacity);if (NULL == _array){perror("malloc申请空间失败!!!");return;}_capacity = capacity;_size = 0;}void Push(T data){// CheckCapacity();_array[_size] = data;_size++;}// 其他方法...~Stack(){if (_array){free(_array);_array = NULL;_capacity = 0;_size = 0;}} private:T* _array;int _capacity;int _size; }; - 但是呢就上面这样其实并不是最规范的写法,还记得我们在学习C++类和对象讲到过一个类要声明和定义分离,那对于模板类也同样适用,我们马上来看看
template<class T> // 类模版 class Stack { public:Stack(size_t capacity = 3);void Push(T data);~Stack(); private:T* _array;int _capacity;int _size; }; - 不过呢可以看到直接像我们之前那样去进行类外定义似乎行不通,说
缺少类模版“Stack”的参数列表,因为这个成员函数内部也使用到了模版参数T,那么这个函数也要变为函数模版才行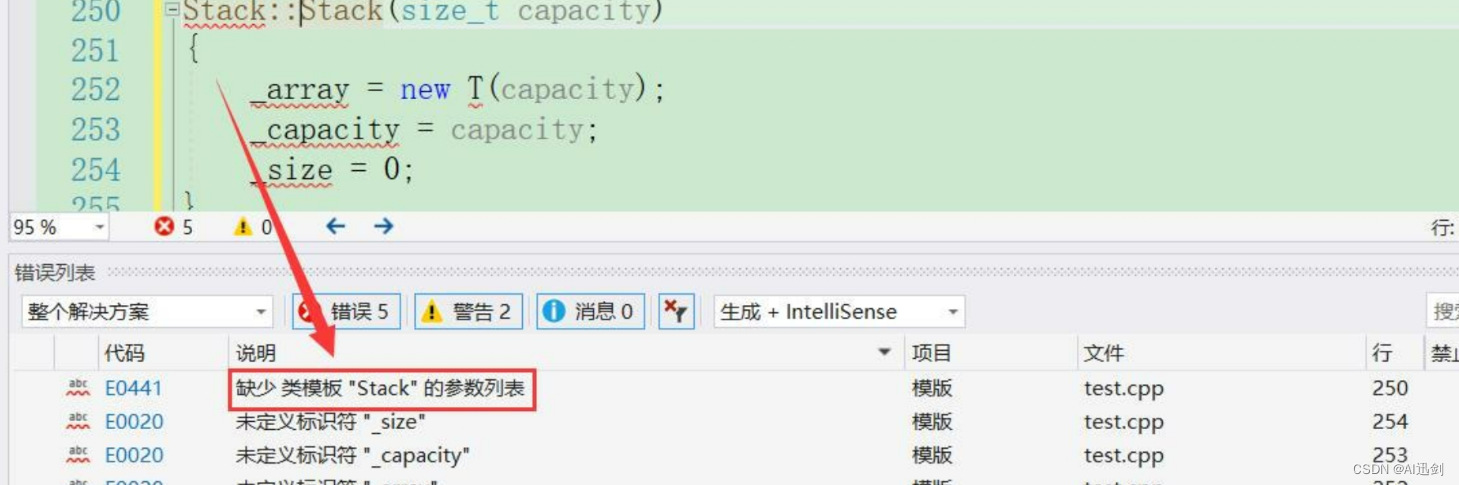
- 但是在加上这个模版参数后,似乎还是有问题,::这个操作符我们在C++命名空间中有提到过,叫做【域作用限定符】,是我们使用命名空间去访问特定成员变量或成员函数时使用的,对于类来说它一定要是一个类名
- 这里要强调一点的是对于普通类来说类名和类型是一样的, 像构造函数,它的函数名就是类名;可是对于模板类来说是不一样,类名和类型不一样,这里Stack只是这个模版类的类名罢了,但我们现在需要的是类型,此处就想到了我们在上面所学的【显式实例化】,这个模板类的类型即为Stack<T>
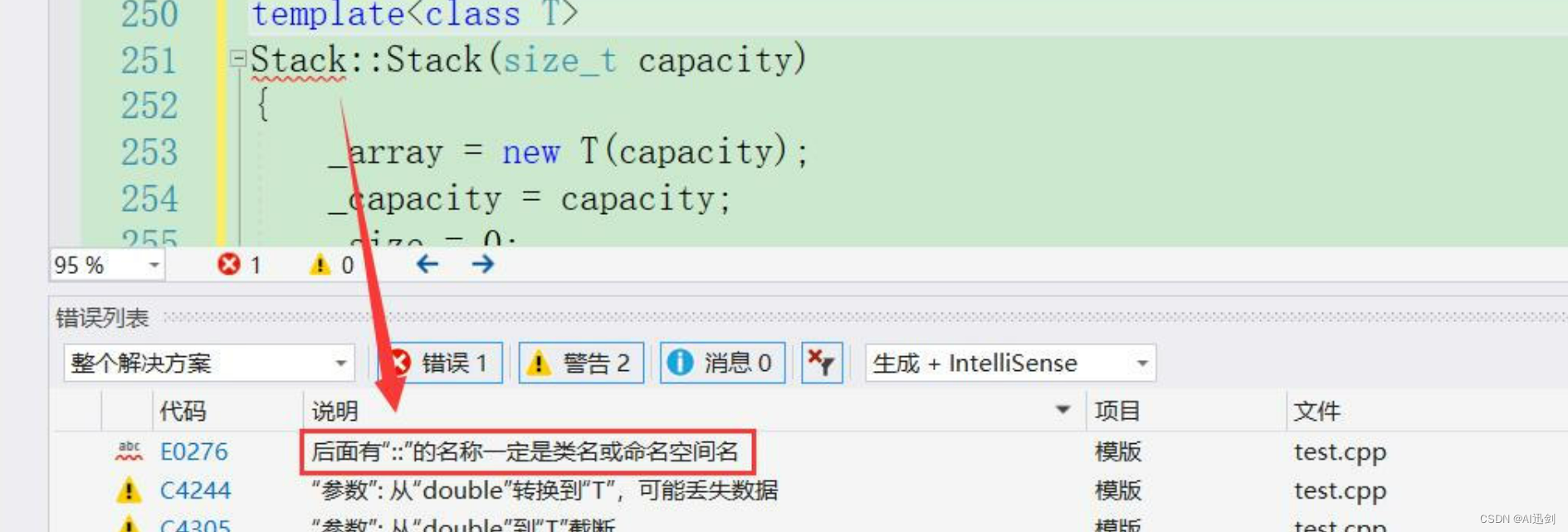
- 以下即是对这个模版类中的成员函数在类外实现所需要变化成的模版函数
template<class T>
Stack<T>::Stack(size_t capacity)
{_array = new T(capacity);_capacity = capacity;_size = 0;
}
- 那对于其他函数也是一致,均需要将它们定义为模版函数,此时我们可以意识到一点的是对于模版函数来说,其模版参数的作用域就在这个函数内部,出了这个函数就无法使用了, 所以可以看到每个函数前面都需要其对应的模版参数;而且对于模版类来说也是同理,只在这个类内起作用,即到收括号};为止,我们知道对于一个类来说也算是一个独立的空间,成员函数是不包含在类内的,所以其在类外进行定义的时候就需要再重新定义模版参数
template<class T> // 每个函数或类前都要加上其对应的模版参数 void Stack<T>::Push(T data) {// CheckCapacity();_array[_size] = data;_size++; }template<class T> Stack<T>::~Stack() {if (_array){free(_array);_array = NULL;_capacity = 0;_size = 0;} }2、类模板的实例化
清楚了什么是类模版之后,我们就将上面的这个Stack类模版给实例化出来吧
👉 类模板实例化与函数模板实例化不同,类模板实例化需要在类模板名字后跟<>,然后将实例化的类型放在<>中即可,类模板名字不是真正的类,而实例化的结果才是真正的类
- 可以看到因为我们将这个类定义为了类模版,此时便可以去初始化不同数据类型的栈了,上面说到过Stack是类名,但是像Stack<int>、Stack<double>这些都是它的类型
int main(void) {Stack<int> s1; // intStack<double> s2; // doubleStack<char> s3; // charreturn 0; }四、总结与提炼
最后我们来总结一下本文所学习的内容📖
- 首先我们了解了什么是泛型编程的思想,通过曹植的《洛神赋》到【活字印刷术】,我们体会到了有一个通用模版的重要性,于是就引申出了C++中的模版这一个概念,对于模版呢,其分为 函数模版 和 类模版
- 首先呢我们介绍了什么是【函数模版】,新学习了一个关键字叫做template,用它再配合模版参数就可以去定义出一个函数模版,有了它,我们在写一些相同类型函数的时候就无需去进行重复的CV操作了,在通过汇编观察函数模版的原理后,清楚了我们只需要传入不同的类型,此时模版参数就会去进行一个自动类型推导,从而产生不同的函数。函数模版定义好后还要对其实例化才能继续使用,但此时要注意的一点是如果传递进去的类型个数与模版参数的个数不匹配的话,其就无法完成自动类型推导,因为这会产生一个歧义。所以想要真正学好模版,这点是一定要搞清楚的!!!
- 接下去呢我们又学习了【类模版】,没想到吧,类也可以变成一个模版,以Stack类为例,对于类模版而言,其类名和类型与普通类是不一样的,这点要注意了,尤其体现在类的成员函数放在类外进行定义的时候,也要将其定义为函数模版,函数名前面指明其类型,这才不会出问题。有了类模版之后,我们去显式实例化不同的数据类型后也可以让模版参数去做一个自动类型推导从而得到不同数据类型的栈
总而言之,模版是C++的一个亮点所在,也是学习STL的基础,望读者扎实掌握👊
以上就是本文要介绍的所有内容,感谢您的阅读🌹
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
此文借鉴与https://blog.csdn.net/Fire_Cloud_1/article/details/131611593