简介
SQL (Structured Query Language) 是具有数据操纵和数据定义等多种功能的数据库语言,这种语言具有交互性特点,能为用户提供极大的便利,数据库管理系统应充分利用SQL语言提高计算机应用系统的工作质量与效率。
以下介绍postgresql语法,SQL语法都按照国际标准定制,大部分语法可通用。
SQL语言定义
- DDL语言:用于数据定义。
- 数据库、表、视图、索引
- DML语言:用于数据操纵。
- 插入、删除、更新
- DQL语言:用于数据查询。
- 查询
- DCL语言:用于数据控制。
- 用户权限
- TCL语言:用于事务控制。
- 事务提交、事务回滚
目录
1. DDL语言
1.1. 数据库
1.2. 表
数据类型
约束类型
普通表
临时表
分区表
继承表
表空间
1.3. 视图
1.4. 索引
2. DML语言
2.1. 插入
基本语法
函数插入
2.2. 删除
2.3. 更新
3. DQL语言
3.1. 查询
基础语法
where子句
函数匹配
连接查询
子查询
实战练习
4. DCL语言
4.1. 用户
5. TCL语言
5.1. 事务
1. DDL语言
1.1. 数据库
创建库
--创建数据库
CREATE DATABASE [库名];--创建库时,指定该库拥有者
CREATE DATABASE[库名]
OWNER[用户名];--创建库时,指定表空间
CREATE DATABASE[库名]
TABLESPACE[表空间名];--创建数据库link对象
CREATE DATABASE LINK[link_name]
CONNECT TO'[user]'
IDENTIFIED BY'[password]'
USING'[oradb]';删除库
DROP DATABASE [库名];1.2. 表
数据类型
数据类型(整数类)
integer
- 整数类型:-2147483648 到 2147483647
bigint
- 大范围整数类型:-9223372036854775808 到 9223372036854775807
float
- 浮点数类型
serial
- 自增长整数:1 到 2147483647
数据类型(字符类)
char ( [num] ) | char ( [num] byte )
- 固定长度(最大8000)
varchar( [num] ) | varchar( [num] byte )
- 可变长度(最大8000)
text
- 可变长度(无限长)
数据类型(日期类)
date
- 显示日期
time
- 仅显示 时/分/秒
数据类型(布尔类)
boolean
- 真或假
数据类型(大对象类)
clob
- 字符大对象
blob
- 二进制大对象
bytea
- 可变二进制串
约束类型
主键约束(primary key)
- 唯一约束+非空约束:既不允许该列中有相同值,也不允许存在空值。
唯一约束(unique)
- 在相同列、多列中,不允许多个行具有相同的值。但允许一些值为空。
非空约束(not null)
- 该列不允许有空值。
外键约束(foreign key)
- 指定一个列作为外键,可以在主键和唯一键建立关系。
默认值(default)
- 该列未插入数据时,默认插入创建表指定的默认值。
普通表
====== 增 ======
--创建表
CREATE TABLE[表名]([字段名1] [数据类型1] [约束1],[字段名2] [数据类型2] [约束2],[字段名3] [数据类型3] [约束3]);--增加表字段
ALTER TABLE[表名]
ADD[字段名] [数据类型] [约束];--增加注释
COMMENT ON COLUMN[表名].[列名]
IS'[注释内容]';--创建表空间
CREATE TABLESPACE[表空间名]
LOCATION'[物理路径]'; --该表空间中的数据放入指定路径下====== 删 ======
--删除表
DROP TABLE [表名];--清空表
TRUNCATE [表名];
DELETE FROM [表名];--删除表字段
ALTER TABLE[表名]
DROP[字段名];--清理指定数据
DELETE FROM[表名]
WHERE[字段] = xxx;====== 改 ======
--修改表名
ALTER TABLE[表名]
RENAME TO[新表名];--修改表字段
ALTER TABLE[表名]
MODIFY[字段名] [数据类型] [约束];
临时表
- 临时表保存的数据仅在事务或会话期间存在(数据私有)。
- 临时表包含:全局临时、局部临时。
全局临时表
--创建全局临时表
CREATE GLOBAL TEMPORARY TABLE[表名] ([字段名] [数据类型] [约束]);--创建全局临时表,特定于事务
CREATE GLOBAL TEMPORARY TABLE[表名] ([字段名] [数据类型] [约束])
ON COMMIT DELETE ROWS;--创建全局临时表,特定于会话
CREATE GLOBAL TEMPORARY TABLE[表名] ([字段名] [数据类型] [约束])
ON COMMIT PRESERVE ROWS;局部临时表
--创建局部临时表
CREATE LOCAL TEMPORARY TABLE[表名] ([字段名] [数据类型] [约束]);--创建局部临时表,特定于事务
CREATE LOCAL TEMPORARY TABLE[表名] ([字段名] [数据类型] [约束])
ON COMMIT DELETE ROWS;--创建局部临时表,特定于会话
CREATE LOCAL TEMPORARY TABLE[表名] ([字段名] [数据类型] [约束])
ON COMMIT PRESERVE ROWS;分区表
- 分区表包含一个或多个分区,可以进行单独管理,且可以独立于其他分区进行操作。
- 作用:方便维护、数据转移,增强数据库可用性。
按键分区
CREATE TABLE[表名] ([字段名] [数据类型] [约束])
PARTITION BY RANGE( [列名] ) --指定该列名分区(PARTITION q1 VALUES LESS THAN ('2023-01-01'),PARTITION q2 VALUES LESS THAN ('2023-04-01'),PARTITION q3 VALUES LESS THAN ('2023-07-01'),PARTITION q4 VALUES LESS THAN ('2023-10-01') ); --按日期分区按间隔分区
CREATE TABLE[表名] ([字段名] [数据类型] [约束])
PARTITION BY RANGE( [列名] ) INTERVAL ('3 MONTH'::INTERVAL) --每3个月自动创建分区(PARTITION P1 VALUES LESS THAN ('2023-01-01')); 按固定值分区
CREATE TABLE[表名] ([字段名] [数据类型] [约束])
PARTITION BY LIST( [列名] ) --指定该列名分区(PARTITION c1 VALUES ('1'), --该列中,1放入此分区PARTITION c2 VALUES ('2'), --该列中,2放入此分区PARTITION c3 VALUES ('3'), --该列中,3放入此分区PARTITION c4 VALUES ('4') --该列中,4放入此分区); --按整数分区按区间值分区
CREATE TABLE[表名] ([字段名] [数据类型] [约束])
PARTITION BY RANGE( [列名] ) --指定该列名分区(PARTITION c1 VALUES LESS THAN (100), --小于100的值,放入此分区PARTITION c2 VALUES LESS THAN (200), --小于200的值,放入此分区PARTITION c3 VALUES LESS THAN (300), --小于300的值,放入此分区PARTITION c4 VALUES LESS THAN (400) --小于400的值,放入此分区PARTITION c5 VALUES LESS THAN (maxvalue) --超过指定值,放入此分区);将分区数据放入表空间
CREATE TABLE[表名] ([字段名] [数据类型] [约束])
PARTITION BY RANGE( [列名] ) --指定该列名分区(PARTITION c1 VALUES LESS THAN (100) TABLESPACE [表空间名], --小于100的值,放入指定表分区PARTITION c2 VALUES LESS THAN (200) TABLESPACE [表空间名], --小于200的值,放入指定表分区PARTITION c3 VALUES LESS THAN (300) TABLESPACE [表空间名], --小于300的值,放入指定表分区PARTITION c4 VALUES LESS THAN (400) TABLESPACE [表空间名] --小于400的值,放入指定表分区) TABLESPACE [表空间名] ; --其他值放入指定该表空间继承表
- 通过一个主表创建其他可用的继承表,在已是继承表的基础上,还可以继续往下继承

--创建一个父表
CREATE TABLEfather(id1 int primary key,name varchar(32));--创建一个继承表
CREATE TABLEson(id2 int)
INHERITS (father --指定继承的表名
);分别创建父表和继承表,结果:
- 继承表继承了父表字段和约束
- 继承表除了继承的字段外,也可以创建自己的字段
- 继承表无法继承索引

分别向父表和子表插入数据,结果:
- 向父表插入数据:子表不会继承数据
- 向子表插入数据:父表会获得数据

删除父表时,必须先删除子表

表空间
表空间多用于数据分磁盘存放,灵活调配资源。例如:
- HDD盘容量大、速度慢,可用于存放不常用的数据。
- SSD盘容量小、速度快,可用于存放经常使用的数据。
用法
创建表空间分为2步1、创建一个目录(用于放入表空间的数据)2、创建一个表空间,指定该目录--Linux创建指定目录
mkdir /data/db/tbs1--创建表空间
CREATE TABLESPACE [表空间名] LOCATION '/data/db/tbs1';--删除表空间
DROP TABLESPACE [表空间名];常用语法
--创建表空间
CREATE TABLESPACE [表空间名] LOCATION '[路径]';--创建表空间,指定拥有者
CREATE TABLESPACE [表空间名] OWNER [用户名] LOCATION '[路径]';--创建加密表空间
CREATE TABLESPACE [表空间名] OWNER [用户名] LOCATION '[路径]' WITH ( encryption = true, enckey = '[密码]' );--创建索引到表空间
CREATE INDEX ON [表名]( [列名] ) TABLESPACE [表空间名];--创建索引到表空间,可以加条件
CREATE INDEX ON [表名]( [列名] ) TABLESPACE [表空间名] WHERE [列名] < xxx;1.3. 视图
视图是一个虚拟的表,它不在数据库中以存储数据的形式保存,是在使用视图的时候动态生成。
- 视图由基本表产生的虚表
- 视图的更新、删除会影响基础表
- 基础表的更新和删除影响视图表
语法
--创建视图
CREATE VIEW [视图名] AS [SQL语句];--创建临时视图
CREATE TEMP VIEW [视图名] AS [SQL语句];--重新定义该视图
CREATE OR REPLACE VIEW [视图名] AS [SQL语句];--查询视图
\d+ 查询所有表和视图
SELECT * FROM [视图名]; --与一般SQL语句一致--删除视图
DROP VIEW [视图名];--视图重命名
ALTER VIEW [视图名] RENAME TO [新视图名];--指定某列的默认值
ALTER VIEW [视图名] ALTER COLUMN [列名] SET DEFAULT [默认值];--删除视图某列默认值
ALTER VIEW [视图名] ALTER COLUMN [列名] DROP DEFAULT;--修改该视图的模式
ALTER VIEW [视图名] SET SCHEMA [新模式];--修改该视图所属用户
ALTER VIEW [视图名] OWNER TO [用户名];示例
--创建一个基础表(学生表)
CREATE TABLEstudent(id int primary key,name varchar(32) not null,sex char(2) default '男',age int default null);--用这个基础表创建一个有意义的视图
--示例:显示男同学的年龄
CREATE VIEWv_male_classmate
ASSELECTname, ageFROMstudent WHEREsex = '男';--向基础表插入数据
INSERT INTOstudent
VALUES (1, '孙悟空', '男', 19 ),(2, '牛魔王', '男', 38 ),(3, '白骨精', '女', 16 ),(4, '沙和尚', '男', 21 ),(5, '紫霞 ', '女', 19 ),(6, '小白龙', '男', 18 ),(7, '张三三', '男', 24 );--查询基础表和视图表
SELECT * FROM student;
SELECT * FROM v_male_classmate;
1.4. 索引
什么情况下适合建索引?
- 列中的值相对比较唯一
- 取值范围大
- where常用的字段
- 经常排序、分组的字段
什么情况下不适合建索引?
- 该表频繁进行DML操作
- 重复值较多、无序的列
- 表数据小
- 该列用得少的情况
简单来说,经常读的表适合建索引,经常更新的表不适合建索引。创建索引本身会增加磁盘的使用,更新表时索引也会更新,存在一定的系统开销。且一张表中不适合建立多个索引,太多也会增加系统开销。
索引的类型
b-tree索引(默认)
- 所有索引中唯一的排序输出,默认升序。
Hash索引
- 只能处理简单等值比较(where xxx = xxx)。
GiST索引
- 可以实现很多不同索引策略。
SP-GiST索引
- 允许实现众多不同的非平衡的基于磁盘的数据结构,例如四叉树、k-d树和radix树。
GIN索引(倒排索引)
- 它适合于包含多个组成值的数据值。
BRIN 索引( 块范围索引的缩写)
- 存储有关存放在一个表的连续物理块范围上的值摘要信息BITMAP索引:以位图形式存储列中特定数据的出现位置信息。
全局索引和本地索引
- 与分区表和索引相关。
语法(这里没有指定某种索引,所以默认的是b-tree索引)
--创建索引
CREATE INDEX [索引名] ON [表名] ( [列名] );--创建多个列的索引
CREATE INDEX [索引名] ON [表名] ( [列名1], [列名2] );--重命名索引
ALTER INDEX [索引名] RENAME TO [新索引名];--创建索引到表空间
CREATE INDEX ON [表名]( [列名] ) TABLESPACE [表空间名];--创建索引到表空间,可以加条件
CREATE INDEX ON [表名]( [列名] ) TABLESPACE [表空间名] WHERE [列名] < xxx;--将索引移动到指定的表空间
ALTER INDEX [索引名] SET TABLESPACE [表空间名];--删除索引
DROP INDEX [索引名];b-tree索引的使用
--创建b-tree索引,指定升序(默认)
CREATE INDEX [索引名] ON [表名] ( [列名] ASC );--创建b-tree索引,指定升降序
CREATE INDEX [索引名] ON [表名] ( [列名] DESC );--创建b-tree索引,指定空值放在前面(若已指定降序,则此方法为默认)
CREATE INDEX [索引名] ON [表名] ( [列名] NULLS FIRST );--创建b-tree索引,指定空值放在后面
CREATE INDEX [索引名] ON [表名] ( [列名] NULLS LAST );--创建b-tree索引,指定升降序,且空值放在后面
CREATE INDEX [索引名] ON [表名] ( [列名] DESC NULLS LAST );hash索引的使用
CREATE INDEX [索引名] ON [表名] USING HASH ( [列名] );
CREATE INDEX [索引名] ON [表名] USING HASH ( [列名1], [列名2] );2. DML语言
2.1. 插入
基本语法
--插入全部字段数据
INSERT INTO [表名] VALUES ('数据');--指定字段插入数据
INSERT INTO [表名]([字段1], [字段2]) VALUES ('数据1', '数据2');--插入多条数据
INSERT INTO [表名] VALUES ('数据1'), ('数据2');函数插入
--快速插入1w行整数(1-1000)
INSERT INTO [表名] VALUES (generate_series(1, 10000));--快速插入0-1w偶数(5000行)
INSERT INTO [表名] VALUES (generate_series(0, 10000, 2));--快速插入日期
generate_series ( [开始日期]::timestamp , [结束日期] , [指定间隔时间] )
INSERT INTO [表名] VALUES (generate_series ( '2000-01-01 00:00:00'::timestamp , '2000-01-10 00:00:00' , '24 hours')) --间隔24小时--插入0-100的随机整数
INSERT INTO [表名] VALUES (floor( random() * 100 ));--插入随机9-10位正负正整数
INSERT INTO [表名] VALUES (hashtext(random()::text));--插入0-100的随机浮点数
INSERT INTO [表名] VALUES (random() * 100 );--插入一个随机大小字符串
INSERT INTO [表名] VALUES (chr( floor ( random() * 26)::integer + 65 ));--插入当前日期时间
INSERT INTO [表名] VALUES ( now() );2.2. 删除
--删除表中全部数据
TRUNCATE [表名];--删除表中全部数据
DELETE FROM [表名];--删除某列带空值的行
DELETE FROM [表名] WHERE [列名] IS NULL;--删除某列为10、20的行
DELETE FROM [表名] WHERE [列名] IN (10, 20);--删除某列不为10、20的行
DELETE FROM [表名] WHERE [列名] NOT IN (10, 20);2.3. 更新
--基础语法
UPDATE[表名]
SET[列名] = [新数据]
WHERE[列名] = [过滤条件];--修改当前列的值(将1修改为10)
UPDATE[表名]
SETid = 10
WHEREid = 1;--修改当前列的值(将小于10修改为12)
UPDATE[表名]
SETid = 12
WHEREid < 10;--将当前列的全部值+100(二元运算都可以用这种方法)
UPDATE[表名]
SET[列名] = [列名] + 100;--将某个部门的员工工资全部涨薪1.2倍
UPDATE[表名]
SET[工资列] = [工资列] * 1.2
WHERE[部门列] = '[某个部门]';3. DQL语言
3.1. 查询
- SELECT顺序示意图(红色线条表示使用全部方法顺序)

基础语法
--显示全部数据
SELECT * FROM [表名];--显示指定数据(id、name)
SELECT id, name FROM [表名];where子句
运算符过滤:大于、小于、等于、不等于、大于等于、小于等于
SELECT * FROM [表名] WHERE [列名] > [过滤数据];
SELECT * FROM [表名] WHERE [列名] < [过滤数据];
SELECT * FROM [表名] WHERE [列名] = [过滤数据];
SELECT * FROM [表名] WHERE [列名] != [过滤数据];
SELECT * FROM [表名] WHERE [列名] >= [过滤数据];
SELECT * FROM [表名] WHERE [列名] <= [过滤数据];空值过滤(注意:null代表不存在;' '代表存在,但值为空)
--查询为空的列
SELECT * FROM [表名] WHERE [列名] IS NULL;--查询为空的列(注意:这个列必须是字符类型,整数类型会报错)
SELECT * FROM [表名] WHERE [列名] == '';--查询不为空的列
SELECT * FROM [表名] WHERE [列名] IS NOT NULL;多个值过滤(in)
--过滤多个值
SELECT * FROM [表名] WHERE [列名] IN( [值1], [值2], [值3] );--不包含这些值
SELECT * FROM [表名] WHERE [列名] NOT IN( [值1], [值2], [值3] );逻辑操作符(and、or、not)
--AND:必须同时满足多个条件
SELECT * FROM [表名] WHERE [列名] < 10 AND [列名] > 1;--OR:任意条件都满足
SELECT * FROM [表名] WHERE [列名] < 10 OR [列名] = 100;--NOT:取反,查询该列不等于100的值
SELECT * FROM [表名] WHERE NOT [列名] = 100;模糊匹配(like)
两种模糊符号,用法一样,表示不一样% 表示该字符串可以出现任意次_ 表示该字符串可以出现1次--前模糊
SELECT * FROM [表名] WHERE [列名] LIKE '%[模糊字符串]';--后模糊
SELECT * FROM [表名] WHERE [列名] LIKE '[模糊字符串]%';--前后模糊
SELECT * FROM [表名] WHERE [列名] LIKE '%[模糊字符串]%';函数匹配
聚合函数
--统计行数
SELECT count(*) FROM [表名];--求和
SELECT sum([字段名]) FROM [表名];--求平均值
SELECT avg([字段名]) FROM [表名];--求最大值
SELECT max([字段名]) FROM [表名];--求最小值
SELECT min([字段名]) FROM [表名];--去重
SELECT distinct([字段名]) FROM [表名];分组(group by)
分组的作用:将某列的值去重后,再利用聚合函数统计他们的数量、最大值、最小值
--基础语法
SELECT [字段名], count([字段名]) FROM [表名] GROUP BY [字段名];--查看班级中男、女同学的数量(sex表示记录男女的字段名)
SELECT sex, count(sex) FROM [表名] GROUP BY sex;--查看班级中男、女同学的数量大于10的结果(sex表示记录男女的字段名)
SELECT sex, count(sex) FROM [表名] GROUP BY sex HAVING count(sex) > 1;--查看班级中男、女同学都大于20岁的数量(sex表示记录男女的字段名)
SELECT sex, count(sex) FROM [表名] GROUP BY sex HAVING age > 20;排序(order by)
--升序
SELECT * FROM [表名] ORDER BY [字段] ASC;--降序
SELECT * FROM [表名] ORDER BY [字段] DESC;分页(limit)
--查询前5行
SELECT * FROM [表名] LIMIT 5;--查询前5行,从下标为1开始(也就是第2行)
SELECT * FROM [表名] LIMIT 5 OFFSET 1;连接查询
全连接
匹配2张表都满足的列
SELECTd.[表1的列名],s.[表2的列名]
FROM[表1] AS d,[表2] AS s
WHERE[表1].[列名] = [表2].[列名];内连接(INNER JOIN)
匹配2张表都满足的列
SELECTd.[表1的列名],s.[表2的列名]
FROM[表1] AS d
INNER JOIN[表2] AS s
ON[表1].[列名] = [表2].[列名];左连接(LEFT JOIN)
显示左表全部信息,若没有匹配到右表数据,则显示为空
SELECTd.[表1的列名],s.[表2的列名]
FROM[表1] AS d
LEFT JOIN[表2] AS s
ON[表1].[列名] = [表2].[列名];右连接(RIGHT JOIN)
显示右表全部信息,若没有匹配到左表数据,则显示为空
SELECTd.[表1的列名],s.[表2的列名]
FROM[表1] AS d
RIGHT JOIN[表2] AS s
ON[表1].[列名] = [表2].[列名];子查询
- 一般子查询都跟在where或者having后面
- 若该子查询的数据使用2次以上,建议取个别名
多用于多表查询(将另一张表的数据查出后作用到当前表中)
SELECT*
FROM[表1]
WHERE[字段] = ( --条件:当前表某个字段 = 子查询得出的值,也可以是in、>、< ......SELECT[表2的字段]FROM[表2]WHERE[表2的字段] = '[过滤表2的值]') [取别名]; --一般需要多次用到这个子查询的值时,取一个别名更方便
实战练习
- 以下数据表纯属瞎设计,仅用于练习

准备数据(部门表)
--部门表
CREATE TABLE department(--部门名称dept_name varchar(32) not null,--部门领导dept_heads varchar(32) not null,--岗位名称position varchar(32) unique not null
);--插入数据
INSERT INTOdepartment
VALUES('人力资源部', '人力资源老大', '人力主管'),('人力资源部', '人力资源老大', '人力培训专员'),('人力资源部', '人力资源老大', '人力招聘专员'),('财务部', '财务老大', '总会计师'),('财务部', '财务老大', '出纳'),('财务部', '财务老大', '稽核'),('财务部', '财务老大', '资金核算'),('技术部', '技术老大', '软件开发'),('技术部', '技术老大', '软件测试'),('技术部', '技术老大', '架构师'),('技术部', '技术老大', '运维管理'),('技术部', '技术老大', '网络管理'),('技术部', '技术老大', '三线技术'),('客服部', '客服老大', '客服经理'),('客服部', '客服老大', '客服信息专员'),('客服部', '客服老大', '客服投诉专员'),('客服部', '客服老大', '客服接待'),('销售部', '销售老大', '销售经理'),('销售部', '销售老大', '一线销售'),('销售部', '销售老大', '二线销售'),('销售部', '销售老大', '三线销售');准备数据(薪资表)
--薪资表
CREATE TABLE pay_scale(--部门名称dept_name varchar(32) not null,--岗位名称position varchar(32) not null,--技术等级technical_grade integer default 1,--对应薪资salary integer not null
);--插入薪资信息,每个岗位设定级别和对应的薪资
INSERT INTOpay_scale
VALUES('财务部', '总会计师', 1, 5000),('财务部', '总会计师', 2, 7000),('财务部', '总会计师', 3, 10000),('财务部', '出纳', 1, 3000),('财务部', '出纳', 2, 3500),('财务部', '出纳', 3, 4000),('财务部', '稽核', 1, 4000),('财务部', '稽核', 2, 4500),('财务部', '资金核算', 1, 3000),('人力资源部', '人力主管', 1, 4000),('人力资源部', '人力主管', 2, 5000),('人力资源部', '人力主管', 3, 6000),('人力资源部', '人力培训专员', 1, 3000),('人力资源部', '人力培训专员', 2, 4000),('人力资源部', '人力招聘专员', 1, 2500),('人力资源部', '人力招聘专员', 2, 3500),('人力资源部', '人力招聘专员', 3, 4500),('技术部', '软件开发', 1, 5000),('技术部', '软件开发', 2, 7000),('技术部', '软件开发', 3, 10000),('技术部', '软件开发', 4, 13000),('技术部', '软件开发', 5, 16000),('技术部', '软件开发', 6, 20000),('技术部', '软件测试', 1, 4000),('技术部', '软件测试', 2, 6000),('技术部', '软件测试', 3, 9000),('技术部', '软件测试', 4, 12000),('技术部', '软件测试', 5, 15000),('技术部', '软件测试', 6, 20000),('技术部', '架构师', 1, 13000),('技术部', '架构师', 2, 15000),('技术部', '架构师', 3, 20000),('技术部', '运维管理', 1, 4000),('技术部', '运维管理', 2, 7000),('技术部', '运维管理', 3, 10000),('技术部', '网络管理', 1, 9000),('技术部', '网络管理', 2, 13000),('技术部', '三线技术', 1, 4500),('技术部', '三线技术', 2, 5500),('技术部', '三线技术', 3, 6500),('技术部', '三线技术', 4, 8000),('客服部', '客服经理', 1, 4000),('客服部', '客服经理', 2, 6000),('客服部', '客服信息专员', 1, 2800),('客服部', '客服信息专员', 2, 3600),('客服部', '客服投诉专员', 1, 2800),('客服部', '客服投诉专员', 2, 3600),('客服部', '客服接待', 1, 3000),('客服部', '客服接待', 2, 4200),('销售部', '销售经理', 1, 6000),('销售部', '销售经理', 2, 9000),('销售部', '一线销售', 1, 2600),('销售部', '一线销售', 2, 3200),('销售部', '一线销售', 3, 4000),('销售部', '二线销售', 1, 2800),('销售部', '二线销售', 2, 3500),('销售部', '二线销售', 3, 4000),('销售部', '三线销售', 1, 2500),('销售部', '三线销售', 2, 3000),('销售部', '三线销售', 3, 3500);准备数据(员工表)
--员工表
CREATE TABLE staff(--员工ID号(唯一)id integer primary key,--员工姓名name varchar(32) not null,--岗位名称position varchar(32) not null,--技术等级technical_grade integer default 1,--入职日期hiredate date not null
);准备一个生成插入员工表数据的shell,生成1000行
- 用法:sh [shell名] [员工数量]
table="staff"
num=$( awk "BEGIN{ print $1 + 0}" )if [ $# -eq 0 ];thenecho -e "用法:"echo -e "\t$0 [插入行数]"exit 1
elif [ ${num} -eq 0 ];thenecho "行数必须为大于1的正整数"exit 1
fiConf(){position="一线销售 三线技术 三线销售 二线销售 人力主管 人力培训专员 人力招聘专员 出纳 客服信息专员 客服投诉专员 客服接待 客服经理 总会计师 架构师 稽核 网络管理 资金核算 软件开发 软件测试 运维管理 销售经理"technical_grade6="软件开发 软件测试"technical_grade4="三线技术"technical_grade3="总会计师 出纳 人力主管 人力招聘专员 架构师 运维管理 一线销售 二线销售 三线销售"technical_grade2="稽核 人力培训专员 网络管理 客服经理 客服信息专员 客服投诉专员 客服接待 销售经理"technical_grade1="资金核算"}RandomPosition(){Confset -- ${position}shift $(expr $RANDOM % $#)position="$1"if [[ "${technical_grade6}" =~ "${position}" ]];thenposition="'${position}', `seq 1 6 |sort -R |head -1`"elif [[ "${technical_grade4}" =~ "${position}" ]];thenposition="'${position}', `seq 1 4 |sort -R |head -1`"elif [[ "${technical_grade3}" =~ "${position}" ]];thenposition="'${position}', `seq 1 3 |sort -R |head -1`"elif [[ "${technical_grade2}" =~ "${position}" ]];thenposition="'${position}', `seq 1 2 |sort -R |head -1`"elif [[ "${technical_grade1}" =~ "${position}" ]];thenposition="'${position}', 1"fi}RandomTime(){TIME=946713600TIME=$[ ${TIME} + $(seq 20 |sort -R |xargs |tr -d ' ' |cut -c -10) ]TIME="$(date -d @$TIME '+%Y-%m-%d')"}Main(){echo -e "INSERT INTO\n\t${table}\nVALUES"for (( i=1; i<=${num}; i++ ));doRandomPositionRandomTime[ ${i} -eq ${num} ] && symbol=";" || symbol=","echo -e "\t(${i}, '员工${i}号', ${position}, '${TIME}')${symbol}"done}
Main练习时可以参考多表示意图,连接线表示多表查询可用
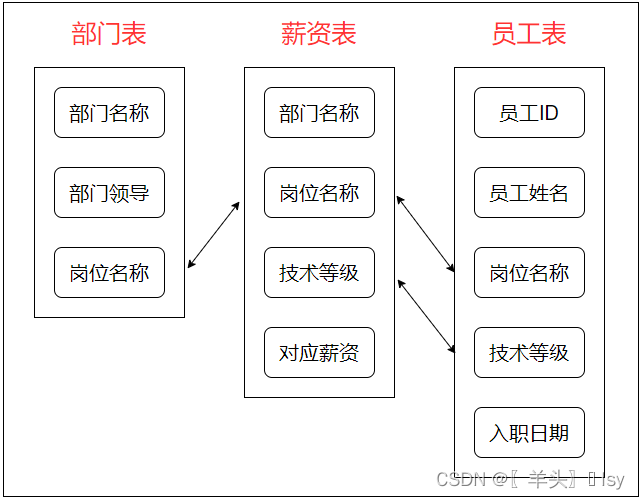
【例题1】查询工资大于1w的"员工姓名"、"薪资"、"所属领导"
SELECTs.name, p.salary, d.dept_heads
FROMdepartment AS d,pay_scale AS p,staff AS s
WHEREp.technical_grade = s.technical_grade
ANDs.position = p.position
ANDp.position = d.position
ANDp.salary > 10000;【例题2】查询"架构师"对应的薪资标准
SELECT*
FROMpay_scale
WHEREposition = '架构师';【例题3】查询"人力招聘专员"和"三线技术"工资在3000 - 7000的员工ID、员工姓名、薪资、岗位,按员工ID升序查看
SELECTs.id, s.name, p.salary, s.position
FROMpay_scale AS p,staff AS s
WHEREs.position = p.position
ANDs.technical_grade = p.technical_grade
ANDp.position in ( '人力招聘专员', '三线技术' )
ANDp.salary > 3000 AND p.salary < 7000
ORDER BY s.id;【例题4】查询"客服部"所有员工工资总和
SELECTsum(p.salary) --'客服部工资总和'
FROMpay_scale AS p,staff AS s
WHEREp.position = s.position
ANDp.technical_grade = s.technical_grade
ANDp.dept_name = '客服部';【例题5】查询"总会计师"和"软件开发"的人数
SELECTp.position, count(p.position)
FROMpay_scale AS p,staff AS s
WHEREp.position = s.position
ANDp.technical_grade = s.technical_grade
ANDp.position IN ('总会计师', '软件开发')
GROUP BYp.position;【例题6】查询"财务部"薪资大于4000的"员工名称"、"部门名称"
SELECTs.name, p.dept_name
FROMpay_scale AS p,staff AS s
WHEREp.position = s.position
ANDp.technical_grade = s.technical_grade
ANDp.dept_name = '财务部'
ANDp.salary > 4000;【例题7】降序查询"软件测试"和"网络管理"的"员工名称"、"薪资"
SELECTs.name, p.salary
FROMpay_scale AS p,staff AS s
WHEREp.position = s.position
ANDp.technical_grade = s.technical_grade
ANDp.position IN ('软件测试', '网络管理')
ORDER BYp.salary
DESC;【例题8】查询"一线销售"和"三线销售"的平均薪资
SELECTp.position, avg(p.salary)
FROMpay_scale AS p,staff AS s
WHEREp.position = s.position
ANDp.technical_grade = s.technical_grade
ANDp.position IN ('一线销售', '三线销售')
GROUP BYp.position;4. DCL语言
4.1. 用户
创建用户
--创建用户
CREATE USER [用户名] PASSWORD '[密码]';--创建用户,指定权限
CREATE ROLE [用户名]
WITHSUPERUSERCREATEDBCREATEROLEINHERITLOGINREPLICATIONBYPASSRLSPASSWORD '[密码]';权限说明:以下写法表示开启,不开启该权限在前面加NO即可(例如:不给SUPERUSER权限,则写为 NOSUPERUSER)
SUPERUSER
- 超级用户,越过数据库内的所有访问限制,是最强大的管理权限
CREATEDB
- 允许创建数据库
CREATEROLE
- 允许创建用户和角色
LOGIN
- 允许登录数据库
REPLICATION
- 是否为复制角色
BYPASSRLS
- 安全测试 RIS
ANY权限
- 允许用户操作所有的某种类型的数据库对象的某种操作,不包括系统对象
SYSBACKUP
- 允许执行物理备份操作
修改用户
--修改权限
ALTER USER [用户名] [新权限];--修改密码
ALTER USER [用户名] PASSWORD '[密码]';5. TCL语言
5.1. 事务
在SQL语句中可以手动的
- 开始一个事务
- 回滚一个事务
手动控制事务
BEGIN; --开始事务[在这个事务中执行的SQL语句] --直接手动结束才能提交该事务
COMMIT; --结束事务回滚事务
BEGIN; --开始事务[在这个事务中执行的SQL语句] --如果不想让这个事务执行,回滚即可
ROLLBACK; --回滚事务