- win java访问hadoop
//复制文件夹,配置环境变量//配置HADOOP_HOME为我们的路径 ,hadoop-3.3.0 ,记得JAVA_HOME不要带有空格,!!!默认java安装环境有空格C:\Program Files//要在cmd hadoop -fs 查看是否配置成功//%HADOOP_HOME%\bin到path//maven添加依赖hadoop3.1.0//创建目录@BeforeURI uri=new URI("hdfs://hadoop102:8020");new Configuration();String user="atguigu";FileSystem.get(uri,configuration,user);fs.mkdirs(new Path("xiyou/huaguoshan")); //ctrl+alt+f变私有变量,可以通用fs.close();//没有权限,不知道用户是atguigu//上传 删除源数据,是否覆盖,相当于 移动 复制fs.copyFromLocalFile(false,false,new Path("D:\\sun.txt"),new Path("hdfs://hadoop102/xiyou"));
2.!!!参数优先级
hdfs-default.xml(hadoop内部)(默认3) <hdfs-site.xml(hadoop内部)<在项目资源目录下的配置文件<代码里面的配置//在项目resources资源目录下的配置文件 创建hdfs-site.xml在resource,//代码里面的配置configuration.set("dfs.replication","2");
3.文件(/夹)下载
//源文件是否删除, hdfs路径, 目标地址路径win,是否开启本地文件校验(几乎不用)fs.copyToLocalFile(false,new Path("hdfs://hadoop102/xiyou/ngs.txt"),new Path("D:\\"),false);fs.copyToLocalFile(false,new Path("hdfs://hadoop102/xiyou"),new Path("D:\\"),false);
//crc是校验文件是否错误的文件,发生错误与远程crc文件不一样
4.文件删除
//递归删除,文件夹要使用递归删除,注意这里的/是指当前hadoop路径的文件fs.delete(new Path("/aaa.txt"),false)fs.delete(new Path("/xiyou"),true);
5.文件的更名和移动
//更名fs.rename(new Path("/input/nn.txt"),new Path("/input/ss.txt"));//文件移动fs.rename(new Path("/xiyou"),new Path("/xiyou1"));fs.rename(new Path("/input/ss.txt"),new Path("/ss.txt"));
6.得到 所有文件信息(权限,文件名,大小,组) 类似于 select * from xx
fs.listFiles(new Path("/"),true);while(listFiles.hasNext()){LocatedFileStatus fileStatus =listFiles.next();sout(fileStatus.getPermission());}
7.判断一个文件夹里面是文件还是目录
fs.listStates(new Path("/"));for(FileStatus status:listStatus){if(status.isFile()){sout("文件"+status.getPath().getName())}else{sout("文件夹"+status.getPath().getName())}}//代码public void listFile() throws IOException, URISyntaxException, InterruptedException {RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);while(listFiles.hasNext()){LocatedFileStatus fileStatus =listFiles.next();System.out.println("permission"+fileStatus);System.out.println("permission"+fileStatus.getPermission());System.out.println("getGroup"+fileStatus.getGroup());System.out.println("getOwner"+fileStatus.getOwner());System.out.println("getAccessTime"+fileStatus.getAccessTime());System.out.println("getBlockSize"+fileStatus.getBlockSize());System.out.println("getModificationTime"+fileStatus.getModificationTime());System.out.println("getReplication"+fileStatus.getReplication());if(fileStatus.isFile()){System.out.println( "文件"+fileStatus.getPath().getName());}else{System.out.println( "文件夹"+fileStatus.getPath().getName());}}
8.(重要面试题)写数据的流程
1.namenode检查是否有权限写操作,检查目录结构(目录是否存在)2.开始传数据3.namenode要存储到哪里? 1.本地节点 2.其他机架以后节点 3.其他机架另外一个节点4.传输packet(c数据512byte 校验4byte)(充满64k发送)(效率高)dataNode1--写数据时同时传给下一节点 建立通道->dataNode2-写数据时同时传给下一节点建立通道->dataNode3没有成功继续传
9.节点距离计算.,像服务器机架
从节点出发找共同祖先,如机架r1的n-0到机架r2的n-0//自己和自己 是0n-0 -->机架r1-->d1-->机架r2---> n-2 是4 r2的 n-0 -->d2的r4的n-1:()n-0 -->r2 -->d1-->祖先-->d2-->r4--->n-1 是6
10.机架感知(面试高频)
第一个节点在第一个机架上,第二个在第二个机架上rack(可靠性)第三个在第二个机架上的随便节点(性能高)//看源码 ctrl+n查找BlockPlacementPolicyDefault的chooseTargetOrder方法
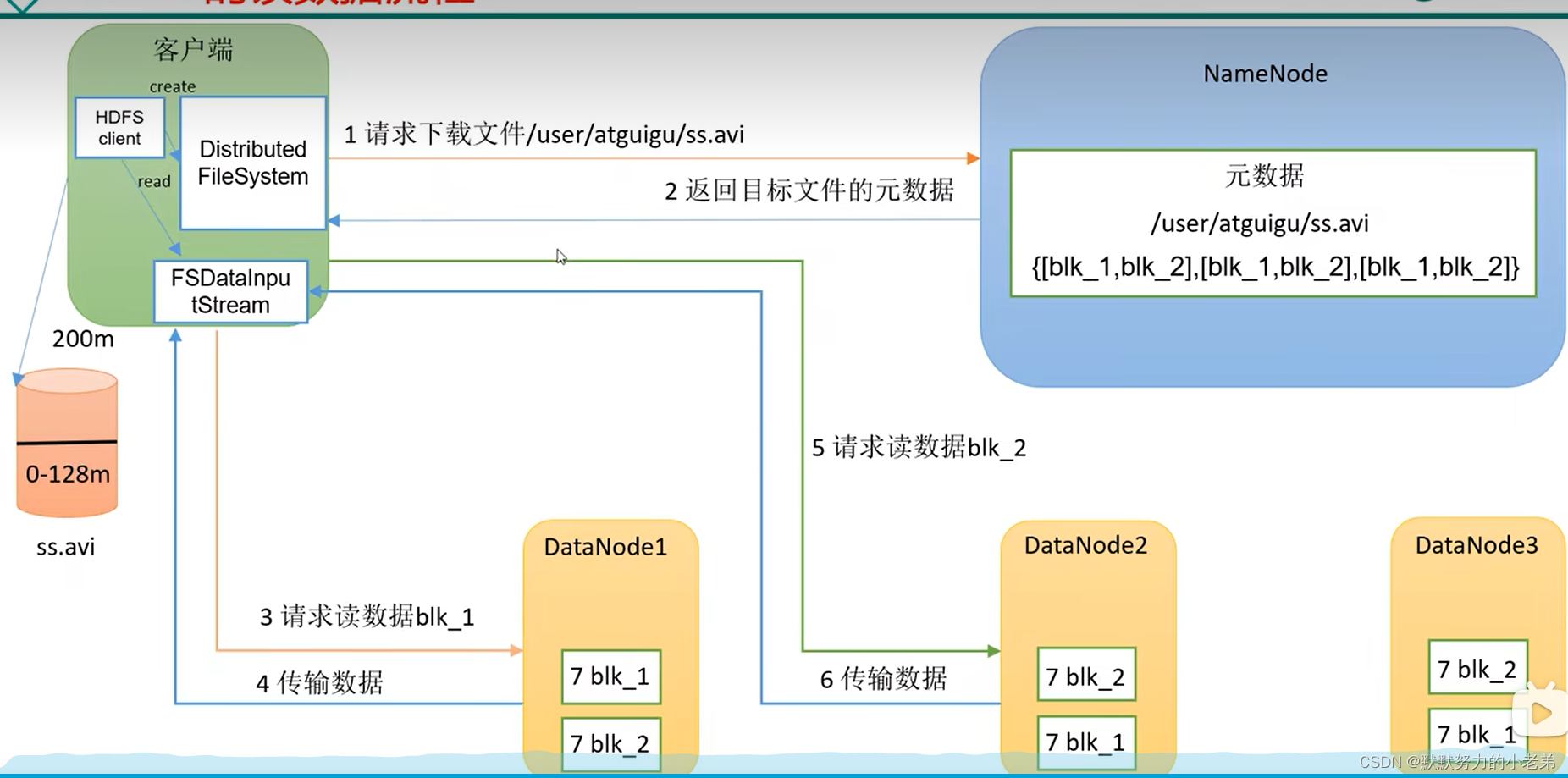
11.hdfs读数据的流程
0.客户端发起请求到NameNode,NameNode返回元数据,客户端创建FSDataInputStream1.选择节点距离最近的,如果这个节点负载太高,选择另外一个节点2.使用并行读,(如图dataNode会有两份备份)
如图hd5
12.NN和2NN工作机制
内存:好处快但是可靠性差磁盘:慢但是可靠性好内存+磁盘 效率低,fsimage存储数据 (2nn用内存辅助生成存储数据)Edits 追加数据a=10 a+10 a=20
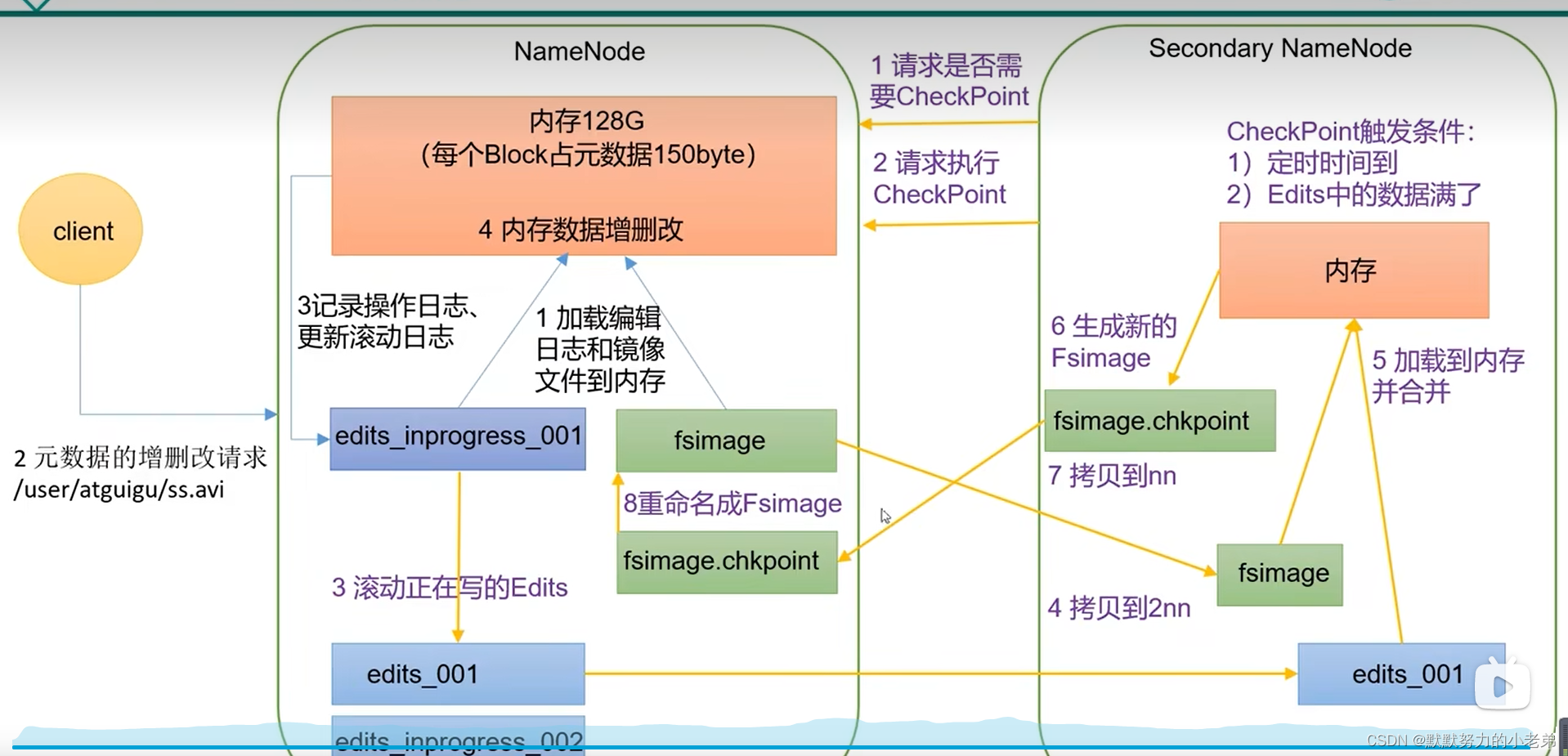
13.查看fsImage镜像文件
hdfs oiv -p XML -i fsimagexxx -o /opt/software/fsimage.xml//下载到win,可以查看目录的结构关系sz fsimage.xml //记录了块信息,和追加的过程hdfs oiv -p XML -i edit_inprogess_xxx -o /opt/software/fsimage.xml
14.CheckPoint基本不用
hdfs-default.xml设置更新数据的时间checkpint.txns, secondaryNameNode
checkpoint.che.period 检查数据时间和触发条件
15.dataNode
开机向nameNode通知存活 --->dn6小时上报块信息, -->dn 向nn3秒一次心跳 超过10分钟+10*3秒没有响应自动删除节点hdfs-default.xml的dfs.blockreport.intervalMsec的21600000 6小时 自己调整
16.数据完整性
//数据传输可能错误的元素代码奇偶校验码 : 二进制加起来是奇数加个1 偶数加个0//hdfs使用的crc校验位(后三位) hdfs传输过去有个crc文件,去crc循环校验验证结果,crc320100 1001 110 传输后 0100 1001 110 说明文件传输没有错误,错误的话会不同
17.掉线时限参数设置 有公式
nn和(dn掉线)10分钟才掉线
hdfs-default.xml的dfs.heartbeat.interval
//关闭hadoop104的datanode jps kill
//恢复hdfs --daemon start datanode
18.总结
1.hdfs块大小 面试重点根据硬盘读写速度挑选合适的才是最好的企业 128m小公司 256m大公司
2.hdfs shell操作开发重点
3.hdfs读写流程面试重点