机器学习笔记之生成模型综述——重参数化技巧[随机反向传播]
- 引言
- 回顾
- 神经网络的执行过程
- 变分推断——重参数化技巧
- 重参数化技巧(随机反向传播)介绍
- 示例描述——联合概率分布
- 示例描述——条件概率分布
- 总结
引言
本节将系统介绍重参数化技巧。
回顾
神经网络的执行过程
上一节比较了概率图模型与神经网络结构,介绍了它们的各自特点。神经网络(这里指前馈神经网络结构)本质上是一个 函数逼近器:
- 基于一个复杂函数Y=f(X)\mathcal Y = f(\mathcal X)Y=f(X),可通过神经网络进行学习,并对该函数进行近似描述。

- 根据具体任务以及输出信息Y\mathcal YY的性质,去构建对应策略(目标函数/损失函数):
例如线性回归(Linear Regression\text{Linear Regression}Linear Regression)任务中,使用最小二乘估计对预测结果WTx(i)\mathcal W^Tx^{(i)}WTx(i)和真实标签y(i)y^{(i)}y(i)之间的关联关系进行描述:
这里省略了偏置信息bbb,并且(x(i),y(i))(x^{(i)},y^{(i)})(x(i),y(i))是数据集合中的一个样本。
L(W)=∑i=1N∣∣WTx(i)−y(i)∣∣2\mathcal L(\mathcal W) = \sum_{i=1}^N ||\mathcal W^Tx^{(i)} - y^{(i)}||^2L(W)=i=1∑N∣∣WTx(i)−y(i)∣∣2 - 在确定目标函数后,使用梯度下降(Gradient Descent,GD\text{Gradient Descent,GD}Gradient Descent,GD)方法配合反向传播算法(Backward Propagation,BP\text{Backward Propagation,BP}Backward Propagation,BP)对神经网络内部权重、偏置参数进行学习与更新。
变分推断——重参数化技巧
在变分推断——重参数化技巧中,我们同样介绍过重参数化技巧:
- 针对难求解的(Intractable\text{Intractable}Intractable)关于隐变量Z\mathcal ZZ的后验概率分布P(Z∣X)\mathcal P(\mathcal Z \mid \mathcal X)P(Z∣X),通过变分推断(Variational Inference,VI\text{Variational Inference,VI}Variational Inference,VI)的手段,人为定义一个概率分布Q(Z)\mathcal Q(\mathcal Z)Q(Z)去近似P(Z∣X)\mathcal P(\mathcal Z \mid \mathcal X)P(Z∣X):
需要注意的是,这里的Q(Z)\mathcal Q(\mathcal Z)Q(Z)并非指的关于隐变量Z\mathcal ZZ‘边缘概率分布’,而是条件概率分布Q(Z∣X)\mathcal Q(\mathcal Z \mid \mathcal X)Q(Z∣X)缩写而成。
logP(X)=∫ZQ(Z)⋅[P(X,Z)Q(Z)]dZ−∫ZQ(Z)⋅[P(Z∣X)Q(Z)]dZ=ELBO+KL[Q(Z)∣∣P(Z∣X)]\begin{aligned} \log \mathcal P(\mathcal X) & = \int_{\mathcal Z} \mathcal Q(\mathcal Z) \cdot \left[\frac{\mathcal P(\mathcal X,\mathcal Z)}{\mathcal Q(\mathcal Z)}\right] d\mathcal Z - \int_{\mathcal Z} \mathcal Q(\mathcal Z) \cdot \left[\frac{\mathcal P(\mathcal Z \mid \mathcal X)}{\mathcal Q(\mathcal Z)}\right] d\mathcal Z \\ & = \text{ELBO} + \text{KL} [\mathcal Q(\mathcal Z)||\mathcal P(\mathcal Z \mid \mathcal X)] \\ \end{aligned}logP(X)=∫ZQ(Z)⋅[Q(Z)P(X,Z)]dZ−∫ZQ(Z)⋅[Q(Z)P(Z∣X)]dZ=ELBO+KL[Q(Z)∣∣P(Z∣X)] - 将证据下界(Evidence of Lower Bound,ELBO\text{Evidence of Lower Bound,ELBO}Evidence of Lower Bound,ELBO)看作关于Q(Z)\mathcal Q(\mathcal Z)Q(Z)的一个函数。称作Q(Z)\mathcal Q(\mathcal Z)Q(Z)的变分(Variation\text{Variation}Variation)。记作L[Q(Z)]\mathcal L[\mathcal Q(\mathcal Z)]L[Q(Z)]:
ELBO=∫ZQ(Z)⋅[P(X,Z)Q(Z)]dZ=L[Q(Z)]\begin{aligned} \text{ELBO} = \int_{\mathcal Z} \mathcal Q(\mathcal Z) \cdot \left[\frac{\mathcal P(\mathcal X,\mathcal Z)}{\mathcal Q(\mathcal Z)}\right] d\mathcal Z = \mathcal L[\mathcal Q(\mathcal Z)] \end{aligned}ELBO=∫ZQ(Z)⋅[Q(Z)P(X,Z)]dZ=L[Q(Z)] - 在随机梯度变分推断(Stochastic Gradient Variational Inference, SGVI\text{Stochastic Gradient Variational Inference, SGVI}Stochastic Gradient Variational Inference, SGVI)的思路中,将条件概率分布Q(Z)\mathcal Q(\mathcal Z)Q(Z)视作一个关于参数ϕ\phiϕ的函数形式Q(Z;ϕ)\mathcal Q(\mathcal Z;\phi)Q(Z;ϕ),那么对应变分L[Q(Z)]\mathcal L[\mathcal Q(\mathcal Z)]L[Q(Z)]也可描述成关于ϕ\phiϕ的函数形式:
此时将求解分布Q(Z)\mathcal Q(\mathcal Z)Q(Z)的问题转化为求解最优参数ϕ^\hat \phiϕ^的问题。
L[Q(Z)]=L[Q(Z;ϕ)]⇒L(ϕ)\mathcal L[\mathcal Q(\mathcal Z)] = \mathcal L[\mathcal Q(\mathcal Z;\phi)] \Rightarrow \mathcal L(\phi)L[Q(Z)]=L[Q(Z;ϕ)]⇒L(ϕ)
基于L(ϕ)\mathcal L(\phi)L(ϕ)求解最大值,使用梯度上升(Gradient Ascent,GA\text{Gradient Ascent,GA}Gradient Ascent,GA)方法近似求解。对应函数梯度表示如下:
{ϕ(t+1)⇐ϕ(t)+η∇ϕL(ϕ)∇ϕL(ϕ)=EQ(Z;ϕ){∇ϕlogQ(Z;ϕ)⋅[logP(X,Z)−logQ(Z;ϕ)]}\begin{cases} \phi^{(t+1)} \Leftarrow \phi^{(t)} + \eta \nabla_{\phi} \mathcal L(\phi) \\ \nabla_{\phi} \mathcal L(\phi) = \mathbb E_{\mathcal Q(\mathcal Z;\phi)} \left\{\nabla_{\phi}\log \mathcal Q(\mathcal Z;\phi) \cdot [\log \mathcal P(\mathcal X,\mathcal Z) - \log \mathcal Q(\mathcal Z;\phi)] \right\} \end{cases}{ϕ(t+1)⇐ϕ(t)+η∇ϕL(ϕ)∇ϕL(ϕ)=EQ(Z;ϕ){∇ϕlogQ(Z;ϕ)⋅[logP(X,Z)−logQ(Z;ϕ)]} - 在使用蒙特卡洛方法进行采样近似过程中,关于∇ϕlogQ(Z;ϕ)\nabla_{\phi}\log \mathcal Q(\mathcal Z;\phi)∇ϕlogQ(Z;ϕ)极容易出现高方差现象(High Variance\text{High Variance}High Variance),导致采样出的梯度结果∇ϕL(ϕ)\nabla_{\phi} \mathcal L(\phi)∇ϕL(ϕ)极不稳定:
∇ϕL(ϕ)≈1N∑n=1N{∇ϕlogQ(z(n);ϕ)⏟High Variance[logP(X,z(n))−logQ(z(n);ϕ)]}\nabla_{\phi}\mathcal L(\phi) \approx \frac{1}{N} \sum_{n=1}^N \left\{\underbrace{\nabla_{\phi} \log \mathcal Q(z^{(n)};\phi)}_{\text{High Variance}} \left[\log \mathcal P(\mathcal X,z^{(n)}) - \log \mathcal Q(z^{(n)};\phi)\right]\right\}∇ϕL(ϕ)≈N1n=1∑N⎩⎨⎧High Variance∇ϕlogQ(z(n);ϕ)[logP(X,z(n))−logQ(z(n);ϕ)]⎭⎬⎫
针对已经被视作函数的Q(Z;ϕ)\mathcal Q(\mathcal Z;\phi)Q(Z;ϕ),通过重参数化技巧,通过构建一个 随机变量ϵ\epsilonϵ,使得ϵ\epsilonϵ与隐变量Z\mathcal ZZ之间存在如下函数关系:
Z=G(ϵ,X;ϕ)\mathcal Z = \mathcal G(\epsilon,\mathcal X ;\phi)Z=G(ϵ,X;ϕ)
从而使得ϵ\epsilonϵ对应的概率分布P(ϵ)\mathcal P(\epsilon)P(ϵ)与分布Q(Z;ϕ)\mathcal Q(\mathcal Z;\phi)Q(Z;ϕ)之间存在如下关系:
EQ(Z;ϕ)[f(Z)]=EP(ϵ){f[G(ϵ,X;ϕ)]}\mathbb E_{\mathcal Q(\mathcal Z;\phi)} \left[f(\mathcal Z)\right] = \mathbb E_{\mathcal P(\epsilon)} \left\{f[\mathcal G(\epsilon,\mathcal X;\phi)]\right\}EQ(Z;ϕ)[f(Z)]=EP(ϵ){f[G(ϵ,X;ϕ)]}
将上述关系带回原式,通过链式求导法则,可以表示成如下形式:将期望形式化简回积分形式。牛顿-莱布尼兹公式,将∇ϕ\nabla_{\phi}∇ϕ提到积分号前,后面再带回去。将Z=G(ϵ,X;ϕ)\mathcal Z = \mathcal G(\epsilon,\mathcal X;\phi)Z=G(ϵ,X;ϕ)代入,并将采样分布Q(Z;ϕ)\mathcal Q(\mathcal Z;\phi)Q(Z;ϕ)替换为P(ϵ)\mathcal P(\epsilon)P(ϵ).
∇ϕL(ϕ)=EQ(Z;ϕ){∇ϕlogQ(Z;ϕ)⋅[logP(X,Z)−logQ(Z;ϕ)]}=∇ϕ∫ZQ(Z;ϕ)⋅[logP(X,Z)−logQ(Z;ϕ)]dZ=EP(ϵ)[∇ϕ(logP(X,Z)−logQ(Z;ϕ))]=EP(ϵ)[∇Z(logP(X,Z)−logQ(Z;ϕ))⋅∇ϕG(ϵ,X;ϕ)]\begin{aligned} \nabla_{\phi}\mathcal L(\phi) & = \mathbb E_{\mathcal Q(\mathcal Z;\phi)} \left\{\nabla_{\phi}\log \mathcal Q(\mathcal Z;\phi) \cdot [\log \mathcal P(\mathcal X,\mathcal Z) - \log \mathcal Q(\mathcal Z;\phi)] \right\} \\ & = \nabla_{\phi} \int_{\mathcal Z} \mathcal Q(\mathcal Z;\phi) \cdot \left[\log \mathcal P(\mathcal X,\mathcal Z) - \log \mathcal Q(\mathcal Z;\phi)\right] d\mathcal Z \\ & = \mathbb E_{\mathcal P(\epsilon)} \left[\nabla_{\phi}(\log \mathcal P(\mathcal X,\mathcal Z) - \log \mathcal Q(\mathcal Z;\phi))\right] \\ & = \mathbb E_{\mathcal P(\epsilon)} [\nabla_{\mathcal Z}(\log \mathcal P(\mathcal X,\mathcal Z) - \log \mathcal Q(\mathcal Z;\phi)) \cdot \nabla_{\phi}\mathcal G(\epsilon,\mathcal X;\phi)] \end{aligned}∇ϕL(ϕ)=EQ(Z;ϕ){∇ϕlogQ(Z;ϕ)⋅[logP(X,Z)−logQ(Z;ϕ)]}=∇ϕ∫ZQ(Z;ϕ)⋅[logP(X,Z)−logQ(Z;ϕ)]dZ=EP(ϵ)[∇ϕ(logP(X,Z)−logQ(Z;ϕ))]=EP(ϵ)[∇Z(logP(X,Z)−logQ(Z;ϕ))⋅∇ϕG(ϵ,X;ϕ)]
通过这种重参数化技巧——将 变量Z\mathcal ZZ 与 简单分布对应变量ϵ\epsilonϵ 之间构建关联关系的方式,仅需要从简单分布P(ϵ)\mathcal P(\epsilon)P(ϵ)中进行采样,也可以采集出∇ϕL(ϕ)\nabla_{\phi}\mathcal L(\phi)∇ϕL(ϕ)中的样本。
重参数化技巧(随机反向传播)介绍
关于神经网络,可以通过通用逼近定理(Universal Approximation Theorem\text{Universal Approximation Theorem}Universal Approximation Theorem)来逼近任意函数。那么神经网络是否也可以用来 逼近概率分布 呢?
从概率图模型的视角,概率分布P(X)\mathcal P(\mathcal X)P(X)就是概率图模型结构的表示(Representation\text{Representation}Representation)。如果能够直接使用神经网络直接将P(X)\mathcal P(\mathcal X)P(X)描述出来,就称之为随机反向传播(Stochastic Backward Propagation\text{Stochastic Backward Propagation}Stochastic Backward Propagation),也称重参数化技巧(Reparametrization Trick\text{Reparametrization Trick}Reparametrization Trick)。
在上面关于变分推断——重参数化技巧的过程中,关于Z=G(ϵ,X;ϕ)\mathcal Z = \mathcal G(\epsilon,\mathcal X;\phi)Z=G(ϵ,X;ϕ)中的函数G\mathcal GG,同样可以描述成如下结构:
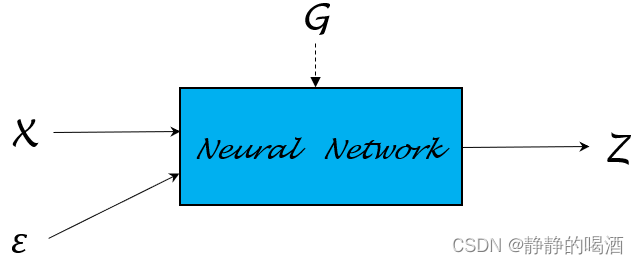
这里从简单的概率分布开始,观察如何使用重参数化技巧对概率分布进行描述的。
示例描述——联合概率分布
假设某随机变量Y\mathcal YY服从均值为μ\muμ,方差为σ2\sigma^2σ2的一维正态分布:
P(Y)=N(μ,σ2)\mathcal P(\mathcal Y) = \mathcal N(\mu,\sigma^2)P(Y)=N(μ,σ2)
如果直接从这个分布中进行采样,可能是复杂的。但是如果可以假定一个变量Z\mathcal ZZ服从标准正态分布N(0,1)\mathcal N(0,1)N(0,1),并且Y,Z\mathcal Y,\mathcal ZY,Z之间满足如下关系:
Y=μ+σ×Z\mathcal Y = \mu + \sigma \times \mathcal ZY=μ+σ×Z
那么则有:
该部分推导过程详见:变分推断——重参数化技巧
EP(Y)[f(Y)]=EP(Z)[f(μ+σ×Z)]\mathbb E_{\mathcal P(\mathcal Y)} [f(\mathcal Y)] = \mathbb E_{\mathcal P(\mathcal Z)} [f(\mu + \sigma \times \mathcal Z)]EP(Y)[f(Y)]=EP(Z)[f(μ+σ×Z)]
这种替换采样分布的操作意味着:在给定Z\mathcal ZZ分布的条件下,完全可以通过采样Z\mathcal ZZ分布,得到Y\mathcal YY分布的样本:
这里的Z(i),Y(i)\mathcal Z^{(i)},\mathcal Y^{(i)}Z(i),Y(i)分别表示概率分布P(Z),P(Y)\mathcal P(\mathcal Z),\mathcal P(\mathcal Y)P(Z),P(Y)中采集的样本。
{Z(i)∼N(0,1)Y(i)=μ+σ×Z(i)\begin{cases} \mathcal Z^{(i)} \sim \mathcal N(0,1) \\ \mathcal Y^{(i)} = \mu + \sigma \times \mathcal Z^{(i)} \end{cases}{Z(i)∼N(0,1)Y(i)=μ+σ×Z(i)
重新观察Y=μ+σ×Z\mathcal Y = \mu + \sigma \times \mathcal ZY=μ+σ×Z,这明显就是一个简单的一次函数。从广义的角度观察,可以将Y,Z\mathcal Y,\mathcal ZY,Z之间满足如下函数关系:
其中Z\mathcal ZZ在函数中表示变量;μ,σ\mu,\sigmaμ,σ在函数中表示权重参数。
Y=f(Z;μ,σ)\mathcal Y = f(\mathcal Z;\mu,\sigma)Y=f(Z;μ,σ)
这意味着:我们不否认变量Y\mathcal YY具有随机性,只不过变量Y\mathcal YY的随机性由变量Z\mathcal ZZ决定。也就是说,除了Z\mathcal ZZ的随机性,其他变量(这里指的Y\mathcal YY)都是确定性变换,那么完全可以使用神经网络对函数f(Z;μ,σ)f(\mathcal Z;\mu,\sigma)f(Z;μ,σ)进行逼近:
这里的‘确定性变换’是指:当变量Z\mathcal ZZ确定的条件下,那么变量Y\mathcal YY根据函数f(Z;μ,σ)f(\mathcal Z;\mu,\sigma)f(Z;μ,σ)也跟着确定。也就是说Z,Y\mathcal Z,\mathcal YZ,Y之间存在明确的映射关系。使用神经网络逼近函数,完全不用担心原始函数中的参数μ,σ\mu,\sigmaμ,σ,因为被替代的神经网络权重参数θ\thetaθ本身没有实际意义。
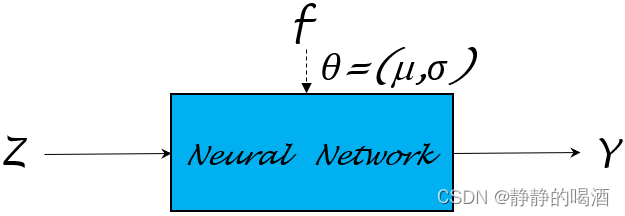
如果定义J(Y)\mathcal J(\mathcal Y)J(Y)为目标函数,在对目标函数求解极值的过程中,对模型参数θ\thetaθ求解梯度。根据链式求导法则,梯度∇θJ(Y)\nabla_{\theta}\mathcal J(\mathcal Y)∇θJ(Y) 可表示为如下形式:
{J(Y)=J[f(Z;μ,σ)]∇θJ(Y)=∇YJ(Y)⋅∇θf(Z;μ,σ)\begin{cases} \mathcal J(\mathcal Y) = \mathcal J[f(\mathcal Z;\mu,\sigma)] \\ \nabla_{\theta} \mathcal J(\mathcal Y) = \nabla_{\mathcal Y} \mathcal J(\mathcal Y) \cdot \nabla_{\theta}f(\mathcal Z;\mu,\sigma) \end{cases}{J(Y)=J[f(Z;μ,σ)]∇θJ(Y)=∇YJ(Y)⋅∇θf(Z;μ,σ)
示例描述——条件概率分布
假设给定随机变量X\mathcal XX条件下,随机变量Y\mathcal YY的条件概率分布满足如下关系:
P(Y∣X)=N(μ,σ2∣X)\mathcal P(\mathcal Y \mid \mathcal X) = \mathcal N(\mu,\sigma^2 \mid \mathcal X)P(Y∣X)=N(μ,σ2∣X)
与上面描述对应,可以根据分布N(μ,σ2∣X)\mathcal N(\mu,\sigma^2 \mid \mathcal X)N(μ,σ2∣X),可以将随机变量Y\mathcal YY与随机变量X\mathcal XX之间描述成如下函数关系:
{Z∼N(0,1)Y=μ(X)+σ(X)×Z\begin{cases} \mathcal Z \sim \mathcal N(0,1) \\ \mathcal Y = \mu(\mathcal X) + \sigma(\mathcal X) \times \mathcal Z \end{cases}{Z∼N(0,1)Y=μ(X)+σ(X)×Z
同样可以使用上述方法,对随机变量Y\mathcal YY与随机变量Z\mathcal ZZ之间的关系进行验证:
关键点1:从概率密度函数的角度观察,由于X\mathcal XX是条件,是已知量。因而可以将N(μ,σ2∣X)\mathcal N(\mu,\sigma^2 \mid \mathcal X)N(μ,σ2∣X)看作是随机变量X\mathcal XX参与的概率密度函数:N[μ(X),σ2(X)]\mathcal N[\mu(\mathcal X),\sigma^2(\mathcal X)]N[μ(X),σ2(X)]证明期望EP(Y∣X)[f(Y)]\mathbb E_{\mathcal P(\mathcal Y \mid \mathcal X)} [f(\mathcal Y)]EP(Y∣X)[f(Y)]转换成期望EP(Z){f[μ(X)+σ(X)×Z]}\mathbb E_{\mathcal P(\mathcal Z)} \{f[\mu(\mathcal X) + \sigma(\mathcal X) \times \mathcal Z]\}EP(Z){f[μ(X)+σ(X)×Z]}的过程实际上是描述Y\mathcal YY被替换成μ(X)+σ(X)×Z\mu(\mathcal X) + \sigma(\mathcal X) \times \mathcal Zμ(X)+σ(X)×Z后,其采样分布也会由P(Y∣X)\mathcal P(\mathcal Y \mid \mathcal X)P(Y∣X)转换成P(Z)\mathcal P(\mathcal Z)P(Z),而不仅仅是单纯意义上的替换。关键点2:将Y=μ(X)+σ(X)×Z\mathcal Y = \mu(\mathcal X) + \sigma(\mathcal X) \times \mathcal ZY=μ(X)+σ(X)×Z代入的过程中,由于是对Z\mathcal ZZ求解偏导,因而有dY=d[μ(X)+σ(X)×Z]=σ(X)dZd\mathcal Y = d[\mu(\mathcal X) + \sigma(\mathcal X) \times \mathcal Z] = \sigma(\mathcal X) d\mathcal ZdY=d[μ(X)+σ(X)×Z]=σ(X)dZ
EP(Y∣X)[f(Y)]=∫YP(Y∣X)⋅f(Y)dY=∫Y1σ(X)⋅2πexp{−[Y−μ(X)]22σ2(X)}⏟N[μ(X),σ2(X)]⋅f(Y)dY=∫Z1σ(X)⋅2πexp{−[μ(X)+σ(X)×Z−μ(X)]22σ2(X)}⋅f[μ(X)+σ(X)×Z]⋅σ(X)dZ⏟d[μ(X)+σ(X)×Z]=∫Z12π⋅exp(−Z22)⏟P(Z)=N(0,1)⋅f[μ(X)+σ(X)×Z]dZ=∫ZP(Z)⋅f[μ(X)+σ(X)×Z]dZ=EP(Z){f[μ(X)+σ(X)×Z]}\begin{aligned} \mathbb E_{\mathcal P(\mathcal Y \mid \mathcal X)} [f(\mathcal Y)] & = \int_{\mathcal Y} \mathcal P(\mathcal Y \mid \mathcal X) \cdot f(\mathcal Y) d\mathcal Y \\ & = \int_{\mathcal Y} \underbrace{\frac{1}{\sigma(\mathcal X) \cdot \sqrt{2\pi}}\exp \left\{-\frac{[\mathcal Y - \mu(\mathcal X)]^2}{2\sigma^2(\mathcal X)}\right\}}_{\mathcal N[\mu(\mathcal X),\sigma^2(\mathcal X)]} \cdot f(\mathcal Y) d\mathcal Y \\ & = \int_\mathcal Z \frac{1}{\sigma(\mathcal X) \cdot \sqrt{2\pi}} \exp \left\{-\frac{[\mu(\mathcal X) + \sigma(\mathcal X) \times \mathcal Z - \mu(\mathcal X)]^2}{2\sigma^2(\mathcal X)}\right\} \cdot f[\mu(\mathcal X) + \sigma(\mathcal X) \times \mathcal Z] \cdot \underbrace{\sigma(\mathcal X) d\mathcal Z}_{d[\mu(\mathcal X) + \sigma(\mathcal X) \times \mathcal Z]} \\ & = \int_{\mathcal Z} \underbrace{\frac{1}{\sqrt{2\pi}} \cdot \exp \left(-\frac{\mathcal Z^2}{2}\right)}_{\mathcal P(\mathcal Z) = \mathcal N(0,1)} \cdot f[\mu(\mathcal X) + \sigma(\mathcal X) \times \mathcal Z] d\mathcal Z \\ & = \int_{\mathcal Z}\mathcal P(\mathcal Z) \cdot f[\mu(\mathcal X) + \sigma(\mathcal X) \times \mathcal Z] d\mathcal Z \\ & = \mathbb E_{\mathcal P(\mathcal Z)} \{f[\mu(\mathcal X) +\sigma(\mathcal X) \times \mathcal Z]\} \end{aligned}EP(Y∣X)[f(Y)]=∫YP(Y∣X)⋅f(Y)dY=∫YN[μ(X),σ2(X)]σ(X)⋅2π1exp{−2σ2(X)[Y−μ(X)]2}⋅f(Y)dY=∫Zσ(X)⋅2π1exp{−2σ2(X)[μ(X)+σ(X)×Z−μ(X)]2}⋅f[μ(X)+σ(X)×Z]⋅d[μ(X)+σ(X)×Z]σ(X)dZ=∫ZP(Z)=N(0,1)2π1⋅exp(−2Z2)⋅f[μ(X)+σ(X)×Z]dZ=∫ZP(Z)⋅f[μ(X)+σ(X)×Z]dZ=EP(Z){f[μ(X)+σ(X)×Z]}
同理,基于上述的神经网络描述,同样也可以随机变量X,Z∼N(0,1)\mathcal X,\mathcal Z \sim \mathcal N(0,1)X,Z∼N(0,1)为输入,Y\mathcal YY作为输出,学习并逼近函数Y=μ(X)+σ(X)×Z\mathcal Y = \mu(\mathcal X) + \sigma(\mathcal X) \times \mathcal ZY=μ(X)+σ(X)×Z:
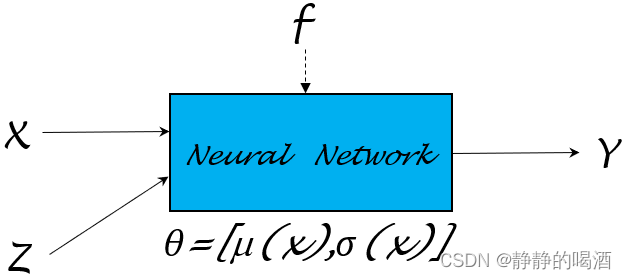
继续向下观察。从Y=μ(X)+σ(X)×Z\mathcal Y = \mu(\mathcal X) + \sigma(\mathcal X) \times \mathcal ZY=μ(X)+σ(X)×Z中可以观察到:
- Y\mathcal YY是关于Z\mathcal ZZ的函数,其中参数是μ(X),σ(X)\mu(\mathcal X),\sigma(\mathcal X)μ(X),σ(X);
- 而μ,σ\mu,\sigmaμ,σ均是关于X\mathcal XX的函数。
既然μ,σ\mu,\sigmaμ,σ函数均以随机变量X\mathcal XX作为输入,这里将这两个函数的参数统一描述成θ\thetaθ。即:μ(X;θ),σ(X;θ)\mu(\mathcal X;\theta),\sigma(\mathcal X;\theta)μ(X;θ),σ(X;θ)。这种变换意味着:仅通过学习模型参数θ\thetaθ,就可以将μ(X),σ(X)\mu(\mathcal X),\sigma(\mathcal X)μ(X),σ(X)均给表示出来。上述神经网络结构可细化成如下形式:
其中⊙\odot⊙表示点乘;⊕\oplus⊕表示数学加法。
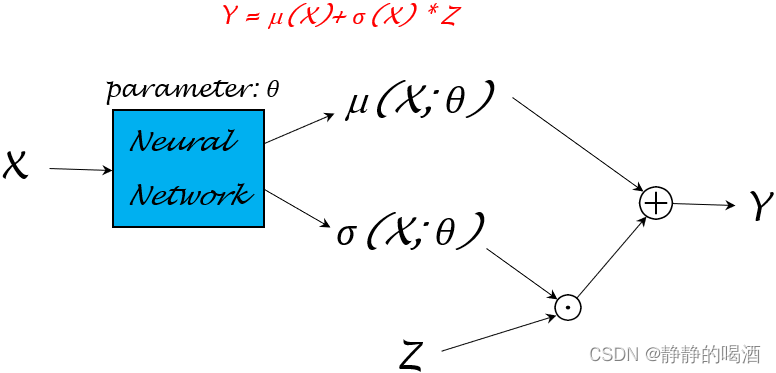
关于模型参数θ\thetaθ的参数学习过程可以很灵活。关于函数μ(X),σ(X)\mu(\mathcal X),\sigma(\mathcal X)μ(X),σ(X)可以再详细分成不同的模型参数μ(X;θ),σ(X;ϕ)\mu(\mathcal X;\theta),\sigma(\mathcal X;\phi)μ(X;θ),σ(X;ϕ)进行学习:
神经网络仅是一个‘函数逼近器’的作用,如何将模型参数学习的更好,可以有很深的挖掘空间。只不过这里我们事先知道Y\mathcal YY的分布是N(μ,σ∣X)\mathcal N(\mu,\sigma\mid \mathcal X)N(μ,σ∣X),这里的μ,σ\mu,\sigmaμ,σ被赋予了实际意义。但真实情况是,这个条件概率分布Y\mathcal YY可能非常复杂。我们对模型参数组成可能一无所知。
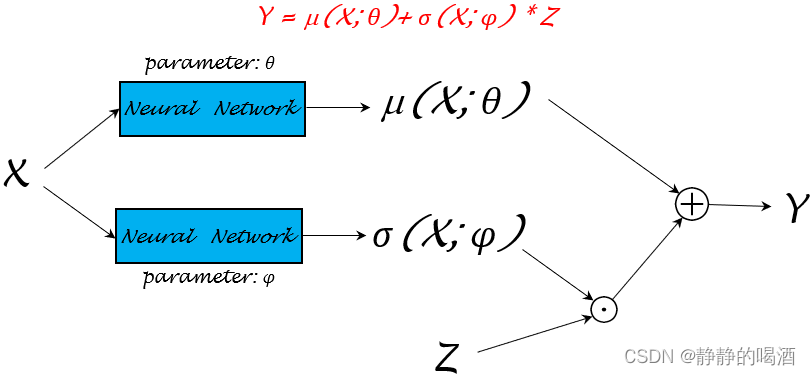
同样可以构建一个目标函数J(Y)\mathcal J(\mathcal Y)J(Y),通过链式求导法则,将对应的模型参数梯度进行求解。
示例:如果通过重参数化技巧产生样本所代表的概率分布Ypred\mathcal Y_{pred}Ypred与真实分布Y\mathcal YY之间的差距(可以看成一个基于分布的回归任务),可以通过最小二乘估计对差距进行描述:
这里以第一种模型结构为例。其中Ygene(i)\mathcal Y_{gene}^{(i)}Ygene(i)就是图中Y\mathcal YY通过上述模型结构产生的一个样本(幻想粒子),与对应真实分布中的Y(i)\mathcal Y^{(i)}Y(i)样本进行比较。
J(Ygene;θ)=∑i=1N∣∣Ygene(i)−Y(i)∣∣2\mathcal J(\mathcal Y_{gene};\theta) = \sum_{i=1}^N ||\mathcal Y_{gene}^{(i)} - \mathcal Y^{(i)}||^2J(Ygene;θ)=i=1∑N∣∣Ygene(i)−Y(i)∣∣2
对应梯度∇θJ(Ygene;θ)\nabla_{\theta}\mathcal J(\mathcal Y_{gene};\theta)∇θJ(Ygene;θ)可表示为:
∇θJ(Ygene;θ)=∂J(Ygene;θ)∂Ygene⋅∂Ygene∂μ(X;θ)⋅∂μ(X;θ)∂θ+∂J(Ygene;θ)∂Ygene⋅∂Ygene∂σ(X;θ)⋅∂σ(X;θ)∂θ\nabla_{\theta} \mathcal J(\mathcal Y_{gene};\theta) = \begin{aligned} \frac{\partial \mathcal J(\mathcal Y_{gene};\theta)}{\partial \mathcal Y_{gene}} \cdot \frac{\partial \mathcal Y_{gene}}{\partial \mu(\mathcal X;\theta)} \cdot \frac{\partial \mu(\mathcal X;\theta)}{\partial \theta} + \frac{\partial \mathcal J(\mathcal Y_{gene};\theta)}{\partial \mathcal Y_{gene}} \cdot \frac{\partial \mathcal Y_{gene}}{\partial \sigma(\mathcal X;\theta)} \cdot \frac{\partial \sigma(\mathcal X;\theta)}{\partial \theta} \end{aligned} ∇θJ(Ygene;θ)=∂Ygene∂J(Ygene;θ)⋅∂μ(X;θ)∂Ygene⋅∂θ∂μ(X;θ)+∂Ygene∂J(Ygene;θ)⋅∂σ(X;θ)∂Ygene⋅∂θ∂σ(X;θ)
总结
通过上面的描述,通过重参数化技巧构造神经网络去逼近联合概率分布、条件概率分布。关于这种表示方式,对于生成分布Y\mathcal YY是存在约束条件的。即:Y\mathcal YY是一个 连续分布。这才能使∂Ygene∂μ(X;θ),∂Ygene∂σ(X;θ)\frac{\partial \mathcal Y_{gene}}{\partial \mu(\mathcal X;\theta)},\frac{\partial \mathcal Y_{gene}}{\partial \sigma(\mathcal X;\theta)}∂μ(X;θ)∂Ygene,∂σ(X;θ)∂Ygene有解。
至此,生成模型部分介绍结束,下一节将介绍流模型(Flow-based Model\text{Flow-based Model}Flow-based Model)。
相关参考:
生成模型6-重参数化技巧(随机后向传播)