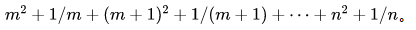并发编程详解
在学习之前,如果多线程的理解足够,可以往下学习,否则的话,建议先看看26章博客(只是建议),注意:可能有些字的字体不对,那么一般是复制粘贴来的,但并不影响阅读,忽略这个问题即可
synchronized ( new 类( ) ) { }
public synchronized void 方法名称( ) { }
synchronized ( this ) { }
public static synchronized void syncFunction ( ) { }
synchronized ( 当前类. class ) { }
synchronized ( 类. class ) { }
第一部分:多线程&并发设计原理 :package com ;
public class MyThread extends Thread { @Override public void run ( ) { System . out. println ( Thread . currentThread ( ) . getName ( ) + "运行了" ) ; System . out. println ( getName ( ) ) ; try { Thread . sleep ( 800 ) ; } catch ( InterruptedException e) { e. printStackTrace ( ) ; } } public MyThread ( ) { } public MyThread ( String name) { super ( name) ; } public static void main ( String [ ] args) { MyThread m = new MyThread ( ) ; m. start ( ) ; Thread mm = new MyThread ( "22" ) ; mm. start ( ) ; System . out. println ( Thread . currentThread ( ) . getName ( ) ) ; }
} package com ;
public class MyRunnable implements Runnable { @Override public void run ( ) { System . out. println ( Thread . currentThread ( ) . getName ( ) + "运行了" ) ; try { Thread . sleep ( 800 ) ; } catch ( InterruptedException e) { e. printStackTrace ( ) ; } } public static void main ( String [ ] args) { Thread thread = new Thread ( new MyRunnable ( ) ) ; thread. start ( ) ; }
}
Thread . setDefaultUncaughtExceptionHandler ( ( t, e) -> {
} ) ;
package com ;
public class a extends Thread { public void run ( ) { System . out. println ( 1 ) ; int i = 1 / 0 ; } public static void main ( String [ ] args) { Thread . setDefaultUncaughtExceptionHandler ( ( t, e) -> { System . out. println ( 2 ) ; } ) ; Thread tt = new a ( ) ; tt. start ( ) ; Thread . setDefaultUncaughtExceptionHandler ( ( t, e) -> { System . out. println ( 3 ) ; } ) ; }
} package com ;
public class MyThread1 extends Thread { public void run ( ) { for ( int i = 0 ; i < 10 ; i++ ) { System . out. println ( "MyThread线程:" + i) ; } } public static void main ( String [ ] args) throws InterruptedException { MyThread1 myThread = new MyThread1 ( ) ; myThread. start ( ) ; myThread. join ( ) ; System . out. println ( "main线程 - 执行完成" ) ; } } package com ; import java. util. concurrent. Callable ;
public class MyCallable implements Callable < String > { @Override public String call ( ) throws Exception { Thread . sleep ( 5000 ) ; return "hello world call() invoked!" ; }
} package com ; import java. util. concurrent. ExecutionException ;
import java. util. concurrent. FutureTask ;
public class Main { public static void main ( String [ ] args) throws ExecutionException , InterruptedException { MyCallable myCallable = new MyCallable ( ) ; FutureTask < String > = new FutureTask < String > ( myCallable) ; new Thread ( futureTask) . start ( ) ; String result = futureTask. get ( ) ; System . out. println ( result) ; } } package com ; import java. util. concurrent. * ;
public class Main2 { public static void main ( String [ ] args) throws ExecutionException , InterruptedException { ThreadPoolExecutor executor = new ThreadPoolExecutor ( 5 , 5 , 1 , TimeUnit . SECONDS , new ArrayBlockingQueue < > ( 10 ) ) { protected void afterExecute ( Runnable r, Throwable t) {
System . out. println ( r) ; System . out. println ( "任务执行完毕" + t) ; } } ; Future < String > = executor. submit ( new MyCallable ( ) ) ; String s = future. get ( ) ; System . out. println ( s) ; executor. shutdown ( ) ; } }
public Class MyClass { public void synchronized method1 ( ) { } public static void synchronized method2 ( ) { }
}
public class MyClass { public void method1 ( ) { synchronized ( this ) { } } public static void method2 ( ) { synchronized ( MyClass . class ) { } }
} 资源可以是一个变量、一个对象或一个文件等等数据
package com. My ;
public class MyQueue { private String [ ] data = new String [ 10 ] ; private int getIndex = 0 ; private int putIndex = 0 ; private int size = 0 ; public synchronized void put ( String element) { if ( size == data. length) { try { wait ( ) ; } catch ( InterruptedException e) { e. printStackTrace ( ) ; } } data[ putIndex] = element; ++ putIndex; if ( putIndex == data. length) putIndex = 0 ; ++ size; notify ( ) ; } public synchronized String get ( ) { if ( size == 0 ) { try { wait ( ) ; } catch ( InterruptedException e) { e. printStackTrace ( ) ; } } String result = data[ getIndex] ; ++ getIndex; if ( getIndex == data. length) getIndex = 0 ; -- size; notify ( ) ; return result; } } package com. My ; import java. util. Random ;
public class ProducerThread extends Thread { private final MyQueue myQueue; private final Random random = new Random ( ) ; private int index = 0 ; public ProducerThread ( MyQueue myQueue) { this . myQueue = myQueue; } @Override public void run ( ) { while ( true ) { String tmp = "ele-" + index; myQueue. put ( tmp) ; System . out. println ( "添加元素:" + tmp) ; index++ ; try { Thread . sleep ( random. nextInt ( 1000 ) ) ; } catch ( InterruptedException e) { e. printStackTrace ( ) ; } } }
} package com. My ; import java. util. Random ;
public class ConsumerThread extends Thread { private final MyQueue myQueue; private final Random random = new Random ( ) ; public ConsumerThread ( MyQueue myQueue) { this . myQueue = myQueue; } @Override public void run ( ) { while ( true ) { String s = myQueue. get ( ) ; System . out. println ( "\t\t消费元素:" + s) ; try { Thread . sleep ( random. nextInt ( 1000 ) ) ; } catch ( InterruptedException e) { e. printStackTrace ( ) ; } } } } package com. My ;
public class Main { public static void main ( String [ ] args) { MyQueue myQueue = new MyQueue ( ) ; ProducerThread producerThread = new ProducerThread ( myQueue) ; ConsumerThread consumerThread = new ConsumerThread ( myQueue) ; producerThread. start ( ) ; consumerThread. start ( ) ; }
}
package com. My ;
public class MyQueue2 extends MyQueue { private String [ ] data = new String [ 10 ] ; private int getIndex = 0 ; private int putIndex = 0 ; private int size = 0 ; @Override public synchronized void put ( String element) { if ( size == data. length) { try { wait ( ) ; } catch ( InterruptedException e) { e. printStackTrace ( ) ; } put ( element) ; } else { put0 ( element) ; notify ( ) ; } } private void put0 ( String element) { data[ putIndex] = element; ++ putIndex; if ( putIndex == data. length) putIndex = 0 ; ++ size; } @Override public synchronized String get ( ) { if ( size == 0 ) { try { wait ( ) ; } catch ( InterruptedException e) { e. printStackTrace ( ) ; } return get ( ) ; } else { String result = get0 ( ) ; notify ( ) ; return result; } } private String get0 ( ) { String result = data[ getIndex] ; ++ getIndex; if ( getIndex == data. length) getIndex = 0 ; -- size; return result; } } package com. My ;
public class Main2 { public static void main ( String [ ] args) { MyQueue2 myQueue = new MyQueue2 ( ) ; for ( int i = 0 ; i < 3 ; i++ ) { new ConsumerThread ( myQueue) . start ( ) ; } for ( int i = 0 ; i < 5 ; i++ ) { new ProducerThread ( myQueue) . start ( ) ; } try { Thread . sleep ( 10000 ) ; } catch ( InterruptedException e) { e. printStackTrace ( ) ; } System . exit ( 0 ) ; } } public class MyClass1 { private Object obj1 = new Object ( ) ; public void method1 ( ) { synchronized ( obj1) { obj1. wait ( ) ; } } public void method2 ( ) { synchronized ( obj1) { obj1. notify ( ) ; } }
} public class MyClass1 { public void synchronized method1 ( ) { this . wait ( ) ; } public void synchronized method2 ( ) { this . notify ( ) ; }
}
并会使得线程直接退出而不执行 ,但是也会看错误的捕获,比如InterruptedException会使得他的线程进行直接退出(notify不用捕获,他使用InterruptedException是检查报错的,因为他没有抛出),而Exception会使得他们进行继续操作,就单纯的报错而已(那么自然对应的如wait不会进行阻塞,但不会起作用,因为报错了)wait ( ) { }
public void enqueue ( ) { synchronized ( queue) { while ( queue. full ( ) ) { queue. wait ( ) ; } queue. notify ( ) ; }
} public void dequeue ( ) { synchronized ( queue) { while ( queue. empty ( ) ) { queue. wait ( ) ; } queue. notify ( ) ; }
} package com. my1 ; public class MyThread extends Thread { @Override public void run ( ) { System . out. println ( this ) ; while ( true ) { boolean interrupted = isInterrupted ( ) ; System . out. println ( "中断标记:" + interrupted) ; } } public static void main ( String [ ] args) { Thread a = new MyThread ( ) ; System . out. println ( a) ; a. start ( ) ; }
}
public static void main ( String [ ] args) throws InterruptedException { Thread a = new MyThread ( ) ; System . out. println ( a) ; a. start ( ) ; Thread . sleep ( 10 ) ; a. interrupt ( ) ; Thread . sleep ( 100 ) ; System . exit ( 0 ) ; }
public static native void sleep ( long millis) throws InterruptedException { . . . } public final void wait ( ) throws InterruptedException { . . . } public final void join ( ) throws InterruptedException { . . . }
这里说成唤醒还不够完善 ,最好是称为解除轻量级阻塞,因为唤醒基本都只是针对于wait来说的,而解除则都能说明),而不是字面意思"中断一个线程"package com. my2 ; import com. my1. MyThread ;
public class Main extends Thread { public void run ( ) { int i = 0 ; while ( true ) { boolean interrupted = isInterrupted ( ) ; System . out. println ( "中断标记:" + interrupted) ; ++ i; if ( i > 200 ) { boolean interrupted1 = Thread . interrupted ( ) ; System . out. println ( "重置中断状态:" + interrupted1) ; interrupted1 = Thread . interrupted ( ) ; System . out. println ( "重置中断状态:" + interrupted1) ; interrupted = isInterrupted ( ) ; System . out. println ( "中断标记:" + interrupted) ; break ; } } } public static void main ( String [ ] args) throws InterruptedException { Main myThread = new Main ( ) ; myThread. start ( ) ; Thread . sleep ( 10 ) ; myThread. interrupt ( ) ; Thread . sleep ( 7 ) ; System . out. println ( "main中断状态检查-1:" + myThread. isInterrupted ( ) ) ; System . out. println ( "main中断状态检查-2:" + myThread. isInterrupted ( ) ) ; } }
package com. my2 ;
public class Main1 extends Thread { public void run ( ) { int i = 0 ; while ( true ) { boolean interrupted = isInterrupted ( ) ; System . out. println ( "中断状态" + interrupted) ; if ( interrupted == true ) { System . out. println ( "退出了" ) ; break ; } } } public static void main ( String [ ] args) throws InterruptedException { Main1 myThread = new Main1 ( ) ; myThread. start ( ) ; myThread. interrupt ( ) ; }
} package com. my2 ;
public class a extends Thread { static a a = new a ( ) ; @Override public void run ( ) { while ( true ) { boolean interrupted = isInterrupted ( ) ; System . out. println ( "中断状态" + interrupted) ; interrupt ( ) ; System . out. println ( 66 ) ; break ; } }
} package com. my2 ;
public class b extends Thread { @Override public void run ( ) { synchronized ( a. a) { while ( true ) { if ( a. a. isInterrupted ( ) ) { System . out. println ( "退出了" ) ; break ; } } } }
} package com. my2 ;
public class c { public static void main ( String [ ] args) { b b = new b ( ) ; a. a. start ( ) ; b. start ( ) ; }
} package com. my1 ;
public class kk extends Thread { @Override public synchronized void run ( ) { int i = 0 ; while ( i == 0 ) { System . out. println ( 1 ) ; try { wait ( ) ; } catch ( InterruptedException e) { e. printStackTrace ( ) ; i = 1 ; } } } public static void main ( String [ ] args) { kk kk = new kk ( ) ; kk. start ( ) ; kk. interrupt ( ) ; }
} package com. my3 ;
public class main extends Thread { @Override public void run ( ) { while ( true ) { System . out. println ( 1 ) ; System . out. println ( Thread . currentThread ( ) . getName ( ) ) ; try { Thread . sleep ( 500 ) ; } catch ( InterruptedException e) { e. printStackTrace ( ) ; } } } public static void main ( String [ ] args) { main myDaemonThread = new main ( ) ; myDaemonThread. setDaemon ( true ) ; myDaemonThread. start ( ) ; new MyThread ( ) . start ( ) ; } public static class MyThread extends Thread { public void run ( ) { for ( int i = 0 ; i < 10 ; i++ ) { System . out. println ( "非Daemon线程" ) ; try { Thread . sleep ( 500 ) ; } catch ( InterruptedException e) { e. printStackTrace ( ) ; } } } }
}
package com. my3 ;
public class MyThread extends Thread { private boolean running = true ; public void run ( ) { while ( running) { System . out. println ( "线程正在运行。。。" ) ; try { Thread . sleep ( 1000 ) ; } catch ( InterruptedException e) { e. printStackTrace ( ) ; } } } public void stopRunning ( ) { this . running = false ; } public static void main ( String [ ] args) throws InterruptedException { MyThread myThread = new MyThread ( ) ; myThread. start ( ) ; Thread . sleep ( 5000 ) ; myThread. stopRunning ( ) ; myThread. join ( ) ; } }
优雅的关闭 package com. my3 ;
public class MyThread extends Thread { private boolean running = true ; public synchronized void run ( ) { while ( running) { System . out. println ( "线程正在运行。。。" ) ; try { wait ( ) ; Thread . sleep ( 1000 ) ; } catch ( InterruptedException e) { e. printStackTrace ( ) ; } } } public void stopRunning ( ) { this . running = false ; } public static void main ( String [ ] args) throws InterruptedException { MyThread myThread = new MyThread ( ) ; myThread. start ( ) ; Thread . sleep ( 5000 ) ; myThread. stopRunning ( ) ; myThread. interrupt ( ) ; myThread. join ( ) ; } } 并行是并发的极致 (即并行也可以称为并发,只是极致而已),但基本不会相同,因为核心不是无限多的上面是对资源的利用或者任务 来说明的,在一般生活操作中或者某些业务需求 ,我们会认为进行分开操作说明,即同时进行为并行,不同时进行为并发public synchronized void set ( Object a) {
}
public void set ( Object a) {
synchronized ( this ) {
}
}
大致的 (虽然并不是)认为wait或者notify是信号量的一种操作,其他具体解释可以百度查看这里概念只需要了解即可 这里概念也只需要了解即可 ) :package com. my4 ;
public class Data { private float myFloat; public void modify ( float diff) { float value = myFloat; System . out. println ( Thread . currentThread ( ) . getName ( ) + "before-" + value) ; myFloat = value + diff; System . out. println ( Thread . currentThread ( ) . getName ( ) + "after-" + myFloat) ; }
} package com. my4 ;
public class MyThread extends Thread { private final Data data; public MyThread ( Data data) { this . data = data; } public void run ( ) { data. modify ( 1 ) ; } public static void main ( String [ ] args) { Data data = new Data ( ) ; new MyThread ( data) . start ( ) ; new MyThread ( data) . start ( ) ; new MyThread ( data) . start ( ) ; }
} public void run ( ) { for ( int i = 0 ; i < 10 ; i++ ) { data. modify ( i) ; } }
package com. my4 ;
public class a extends Thread { static int i = 100000 ; @Override public void run ( ) { while ( i > 0 ) { i-- ; System . out. println ( "a:" + i) ; } } public static class b extends Thread { @Override public void run ( ) { while ( i < 200000 ) { i++ ; System . out. println ( "b:" + i) ; } } } public static void main ( String [ ] args) { a a = new a ( ) ; b b = new b ( ) ; a. start ( ) ; b. start ( ) ; }
} 假设可以这样 ),只有资源都访问了,才不会使得继续循环操作,这种 情况可以无限地持续下去(因为必然是得不到对方的资源的,因为有锁了,必须等待,只是这里假设可以操作了循环,所以并不认为是死锁),所以这两个任务都不会结束自己的执行过程,当然,这只是一个例子
上面的"内存可见性"的问题的概念了解即可 ,即内存可见性就是他进行操作改变数据了,但是我们看到的却是没有改变数据的结果,即改变的数据在当时是不可见的,即内存可见性问题,即内存可见性就是对应的当时对数据的操作的改变是否可见的意思,而对应的问题就是对改变不可见,那么就是只能看到原来的数据,而单纯的内存可见性,我们会认为是依次的,即可见改变的,所以若在后面说明了对某某可见,那么就是说明改变直接的可见的,即没有出现这个内存可见性的问题,比如在后面说明的"意味着A的执行结果必须对B可见"就是这样的例子接下来就是比较重要的说明了 ):我们认为后面的是理论情况 ,但是如果出现,那么通常Buffer的cpu操作资源太慢了,因为是异步,所以对应的两个操作是不同的获取资源的操作,这是一般来说都很快,即再0.01的情况下,赋值完毕(比上面的0.0001秒多很多,所以时间片的切换一般可以使得认为同时运行),并操作内存,但是既然是两个操作,如果前面一个是0.1才操作完毕,那么就会出现这种两个都是0的情况,一般当电脑卡顿时,可能会出现,否则基本不会出现,但还是可能的)public final class Unsafe { public native void loadFence ( ) ; public native void storeFence ( ) ; public native void fullFence ( ) ; } public void fa ( ) { int i = 0 ; int d = 0 ; while ( d < 1 ) { d++ ; i = 9 ; break ; } }
public void fa ( ) { int i = 0 ; i = 9 ; int d = 0 ; while ( d < 1 ) { d++ ; break ; } }
重排序只是对应的顺序发生改变的说明(通常指令没有改变,只是对应的写入或者操作内存变慢了,在内存里面认为是重排序了,即重排序是相对于正常流程顺序发生改变的说明),或者操作的说明(手动改变顺序,我们一般认为是正常流程顺序发生改变的说明,而不是这里的手动改变顺序) class A { private volatile int a = 0 ; private volatile int c = 0 ; public void set ( ) { a = 5 ; c = 1 ; } public int get ( ) { int d = c; return a; }
} 相当于 对应的Buffer操作该关键字的资源时,会等待写入操作完毕(上一层阻塞 ,而使得认为Buffer阻塞了),而不会直接的操作了,即就算是你操作的慢,但是我也要等等,这样就解决了对应的重排序的问题,但是要注意,只要你操作写入完毕后,他的阻塞立马解除,那么如果对应的写入操作的方法有多个写入,可能只会是其中一个获取,但一般是最前面的几个,之所以是最前面的几个,是因为他的阻塞立马解除也是需要时间的,也就是说,如果a=5后面有a=6,那么返回的可能就是6,且基本是6,因为阻塞解除需要时间,然后若你在a=5和a=6中加上延时,比如设置为1000秒钟的延时阻塞,那么对应的结果是5了,因为他当前读取的也就是5,因为6还没有在读取之前进行设置,但是他是一开始就等待的吗,答:不是,而是操作了写入后,才会进行等待,即写入开始(等待)到写入结束(解除等待),所以如果先让读取执行,那么他还是会先读取的(并且对应写入阻塞),在这里好像并不会出现读取先进行操作,这是因为对应的对象初始化需要时间,而该时间导致后来的操作了缓存,使得先操作的与后操作的时间基本类似(可以认为是0.001的时间,前面也说明过),在这个情况下,由于return也需要时间(少于普通打印的1,认为是0.5),所以如果要进行测试该情况出现,可以在a=5前面加上打印"System.out.println(1);"来进行延时,即可进行测试,因为对于0.5的时间来说,对应打印1的时间是非常大的时间的,自然使得后操作class A { private int a = 0 ; private int c = 0 ; public synchronized void set ( ) { a = 5 ; c = 1 ; } public synchronized int get ( ) { return a; }
}
注意是假设他先调用的或者执行快点 ),设置了a=5,之后线程B调用了get,注意他们是相同的锁(因为可以操作相同的A对象,这里就是这样的认为),那么返回值也一定是a=5线程A :加锁; a = 5 ; c = 1 ; 解锁;
线程B :加锁; 读取a; 解锁;
public class MyClass { private long a = 0 ; public void set ( long a) { this . a = a; } public long get ( ) { return this . a; }
}
public class Singleton { private static Singleton instance; public static Singleton getInstance ( ) { if ( instance == null ) { synchronized ( Singleton . class ) { if ( instance == null ) { instance = new Singleton ( ) ; } } } return instance; }
} 上一层 的阻塞的原因(所以在前面我也说明"相当于 对应的Buffer操作该关键字的资源"但也只是相当于)public class MyClass { private int num1; private int num2; private static MyClass myClass; public MyClass ( ) { num1 = 1 ; num2 = 2 ; } public static void write ( ) { myClass = new MyClass ( ) ; } public static void read ( ) { if ( myClass != null ) { int num3 = myClass. num1; int num4 = myClass. num2; } }
}
第⼆部分:JUC (JUC是java.util.concurrent包的简称,所以在后面我们主要说明JUC):即这里了解即可(可以大致的过一遍) package com ; import java. util. concurrent. locks. Condition ;
import java. util. concurrent. locks. Lock ;
import java. util. concurrent. locks. ReentrantLock ;
public class my5 extends Thread { private ReentrantLock lock = new ReentrantLock ( ) ; Condition cd = lock. newCondition ( ) ; private Lock lockk = new ReentrantLock ( ) ; public void run ( ) { lock. lock ( ) ; try { cd. await ( ) ; } catch ( InterruptedException e) { e. printStackTrace ( ) ; } cd. signal ( ) ; System . out. println ( 1 ) ; lock. unlock ( ) ; } public static void main ( String [ ] args) { my5 m = new my5 ( ) ; m. start ( ) ; }
}
可能不同版本的jdk对应的类的部分代码与对应我给出的类的部分代码可能会有所不同,即发生了改变 ,但变化不大,基本是不会出现问题的,如果不同,一般也能根据作用来理解意思,具体还是要看自己的能力了
public interface BlockingQueue < E > extends Queue < E > { boolean add ( E e) ; boolean offer ( E e) ; void put ( E e) throws InterruptedException ; boolean remove ( Object o) ; E take ( ) throws InterruptedException ; E poll ( long timeout, TimeUnit unit) throws InterruptedException ; } public ArrayBlockingQueue ( int capacity) { this ( capacity, false ) ;
} public ArrayBlockingQueue ( int capacity, boolean fair) { } public ArrayBlockingQueue ( int capacity, boolean fair, Collection < ? extends E > ) { this ( capacity, fair) ; } public class ArrayBlockingQueue < E > extends AbstractQueue < E > implements BlockingQueue < E > , java. io. Serializable{
final Object [ ] items; int takeIndex; int putIndex; int count; final ReentrantLock lock; private final Condition notEmpty; private final Condition notFull; }
public void put ( E e) throws InterruptedException { Objects . requireNonNull ( e) ; final ReentrantLock lock = this . lock; lock. lockInterruptibly ( ) ; try { while ( count == items. length) notFull. await ( ) ; enqueue ( e) ; } finally { lock. unlock ( ) ; } }
private void enqueue ( E e) { final Object [ ] items = this . items; items[ putIndex] = e; if ( ++ putIndex == items. length) putIndex = 0 ; count++ ; notEmpty. signal ( ) ; }
public E take ( ) throws InterruptedException { final ReentrantLock lock = this . lock; lock. lockInterruptibly ( ) ; try { while ( count == 0 ) notEmpty. await ( ) ; return dequeue ( ) ; } finally { lock. unlock ( ) ; } }
private E dequeue ( ) { final Object [ ] items = this . items; @SuppressWarnings ( "unchecked" ) E e = ( E ) items[ takeIndex] ; items[ takeIndex] = null ; if ( ++ takeIndex == items. length) takeIndex = 0 ; count-- ; if ( itrs != null ) itrs. elementDequeued ( ) ; notFull. signal ( ) ; return e; } public class LinkedBlockingQueue < E > extends AbstractQueue < E > implements BlockingQueue < E > , java. io. Serializable{ private final int capacity; private final AtomicInteger count = new AtomicInteger ( 0 ) ; private transient Node < E > ;
private transient Node < E > ; private final ReentrantLock takeLock = new ReentrantLock ( ) ; private final Condition notEmpty = takeLock. newCondition ( ) ; private final ReentrantLock putLock = new ReentrantLock ( ) ; private final Condition notFUll = putLock. newCondition ( ) ;
} public LinkedBlockingQueue ( ) { this ( Integer . MAX_VALUE ) ; } @Native public static final int MAX_VALUE = 0x7fffffff ;
public LinkedBlockingQueue ( int capacity) { if ( capacity <= 0 ) throw new IllegalArgumentException ( ) ; this . capacity = capacity; last = head = new Node < E > ( null ) ; }
public E take ( ) throws InterruptedException { final E x; final int c; final AtomicInteger count = this . count; final ReentrantLock takeLock = this . takeLock; takeLock. lockInterruptibly ( ) ; try { while ( count. get ( ) == 0 ) { notEmpty. await ( ) ; } x = dequeue ( ) ; c = count. getAndDecrement ( ) ; if ( c > 1 ) notEmpty. signal ( ) ; } finally { takeLock. unlock ( ) ; } if ( c == capacity) signalNotFull ( ) ; return x; } private void signalNotFull ( ) { final ReentrantLock putLock = this . putLock; putLock. lock ( ) ; try { notFull. signal ( ) ; } finally { putLock. unlock ( ) ; } }
public void put ( E e) throws InterruptedException { if ( e == null ) throw new NullPointerException ( ) ; final int c; final Node < E > = new Node < E > ( e) ; final ReentrantLock putLock = this . putLock; final AtomicInteger count = this . count; putLock. lockInterruptibly ( ) ; try { while ( count. get ( ) == capacity) { notFull. await ( ) ; } enqueue ( node) ; c = count. getAndIncrement ( ) ; if ( c + 1 < capacity) notFull. signal ( ) ; } finally { putLock. unlock ( ) ; } if ( c == 0 ) signalNotEmpty ( ) ; } private void signalNotEmpty ( ) { final ReentrantLock takeLock = this . takeLock; takeLock. lock ( ) ; try { notEmpty. signal ( ) ; } finally { takeLock. unlock ( ) ; } }
我们一般将这种优化称为边界通知 ,那么还有一个重要问题,为什么他的中间会操作唤醒自身呢,但是前面已经是阻塞的,为什么还要进行呢,这是为了当多个线程一起操作时来唤醒另外一个线程的,因为他是定向的操作,所以他也只会唤醒对应自己的消费者或者生产者的线程(因为其他多个线程可以都被阻塞,因为阻塞是会释放锁的,前提是该阻塞会释放锁,比如sleep虽然阻塞了,但并没有释放锁,而await和wait都会释放锁),而不会操作对立的线程,但他们直接的唤醒也仍然是随机的(如多个await的唤醒,但是是同一个Condition),至此我们说明完毕 private void signalNotEmpty ( ) { final ReentrantLock takeLock = this . takeLock; takeLock. lock ( ) ; try { notEmpty. signal ( ) ; } finally { takeLock. unlock ( ) ; } } private void signalNotFull ( ) { final ReentrantLock putLock = this . putLock; putLock. lock ( ) ; try { notFull. signal ( ) ; } finally { putLock. unlock ( ) ; } }
public class PriorityBlockingQueue < E > extends AbstractQueue < E > implements BlockingQueue < E > , java. io. Serializable{ private transient Object [ ] queue; private transient int size; private transient Comparator < ? super E > ; private final ReentrantLock lock; private final Condition notEmpty; }
public PriorityBlockingQueue ( ) { this ( DEFAULT_INITIAL_CAPACITY , null ) ; private static final int DEFAULT_INITIAL_CAPACITY = 11 ; } public PriorityBlockingQueue ( int initialCapacity, Comparator < ? super E > ) { if ( initialCapacity < 1 ) throw new IllegalArgumentException ( ) ; this . comparator = comparator; this . queue = new Object [ Math . max ( 1 , initialCapacity) ] ; } public void put ( E e) { offer ( e) ; } public boolean offer ( E e) { if ( e == null ) throw new NullPointerException ( ) ; final ReentrantLock lock = this . lock; lock. lock ( ) ; int n, cap; Object [ ] es; while ( ( n = size) >= ( cap = ( es = queue) . length) ) tryGrow ( es, cap) ; try { final Comparator < ? super E > ; if ( ( cmp = comparator) == null ) siftUpComparable ( n, e, es) ; else siftUpUsingComparator ( n, e, es, cmp) ; size = n + 1 ; notEmpty. signal ( ) ; } finally { lock. unlock ( ) ; } return true ; }
public E take ( ) throws InterruptedException { final ReentrantLock lock = this . lock; lock. lockInterruptibly ( ) ; E result; try { while ( ( result = dequeue ( ) ) == null ) notEmpty. await ( ) ; } finally { lock. unlock ( ) ; } return result; } private E dequeue ( ) { final Object [ ] es; final E result; if ( ( result = ( E ) ( ( es = queue) [ 0 ] ) ) != null ) { final int n; final E x = ( E ) es[ ( n = -- size) ] ; es[ n] = null ; if ( n > 0 ) { final Comparator < ? super E > ; if ( ( cmp = comparator) == null ) siftDownComparable ( 0 , x, es, n) ; else siftDownUsingComparator ( 0 , x, es, n, cmp) ; } } return result; }
public class DelayQueue < E extends Delayed > extends AbstractQueue < E > implements BlockingQueue < E > { public interface Delayed extends Comparable < Delayed > { long getDelay ( TimeUnit unit) ;
} public class DelayQueue < E extends Delayed > extends AbstractQueue < E > implements BlockingQueue < E > { private final transient ReentrantLock lock = new ReentrantLock ( ) ; private final Condition available = lock. newCondition ( ) ; private final PriorityQueue < E > = new PriorityQueue < E > ( ) ; } public E take ( ) throws InterruptedException { final ReentrantLock lock = this . lock; lock. lockInterruptibly ( ) ; try { for ( ; ; ) { E first = q. peek ( ) ; if ( first == null ) available. await ( ) ; else { long delay = first. getDelay ( NANOSECONDS ) ; if ( delay <= 0L ) return q. poll ( ) ; first = null ; if ( leader != null ) available. await ( ) ; else { Thread thisThread = Thread . currentThread ( ) ; leader = thisThread; try { available. awaitNanos ( delay) ; } finally { if ( leader == thisThread) leader = null ; } } } } } finally { if ( leader == null && q. peek ( ) != null ) available. signal ( ) ; lock. unlock ( ) ; } } public void put ( E e) { offer ( e) ; } public boolean offer ( E e) { final ReentrantLock lock = this . lock; lock. lock ( ) ; try { q. offer ( e) ; if ( q. peek ( ) == e) { leader = null ; available. signal ( ) ; } return true ; } finally { lock. unlock ( ) ; } }
public class SynchronousQueue < E > extends AbstractQueue < E > implements BlockingQueue < E > , java. io. Serializable{ public SynchronousQueue ( boolean fair) { transferer = fair ? new TransferQueue < E > ( ) : new TransferStack < E > ( ) ; } public SynchronousQueue ( ) { this ( false ) ; }
public void put ( E e) throws InterruptedException { if ( e == null ) throw new NullPointerException ( ) ; if ( transferer. transfer ( e, false , 0 ) == null ) { Thread . interrupted ( ) ; throw new InterruptedException ( ) ; } } public E take ( ) throws InterruptedException { E e = transferer. transfer ( null , false , 0 ) ; if ( e != null ) return e; Thread . interrupted ( ) ; throw new InterruptedException ( ) ; }
如下所示 ,如果是put(…),则第1个参数就是对应的元素,如果是take(),则第1个参数为null,否则(put)代表传递的值abstract static class Transferer < E > { abstract E transfer ( E e, boolean timed, long nanos) ; }
public class SynchronousQueue < E > extends AbstractQueue < E > implements BlockingQueue < E > , java. io. Serializable{ static final class TransferQueue < E > extends Transferer < E > { static final class QNode { volatile QNode next; volatile Object item; volatile Thread waiter; final boolean isData; } transient volatile QNode head; transient volatile QNode tail; }
}
TransferQueue ( ) { QNode h = new QNode ( null , false ) ; head = h; tail = h; }
E transfer ( E e, boolean timed, long nanos) { QNode s = null ; boolean isData = ( e != null ) ; for ( ; ; ) { QNode t = tail; QNode h = head; if ( t == null || h == null ) continue ; if ( h == t || t. isData == isData) { QNode tn = t. next; if ( t != tail) continue ; if ( tn != null ) { advanceTail ( t, tn) ; continue ; } if ( timed && nanos <= 0L ) return null ; if ( s == null ) s = new QNode ( e, isData) ; if ( ! t. casNext ( null , s) ) continue ; advanceTail ( t, s) ; Object x = awaitFulfill ( s, e, timed, nanos) ; if ( x == s) { clean ( t, s) ; return null ; } if ( ! s. isOffList ( ) ) { advanceHead ( t, s) ; if ( x != null ) s. item = s; s. waiter = null ; } return ( x != null ) ? ( E ) x : e; } else { QNode m = h. next; if ( t != tail || m == null || h != head) continue ; Object x = m. item; if ( isData == ( x != null ) || x == m || ! m. casItem ( x, e) ) { advanceHead ( h, m) ; continue ; } advanceHead ( h, m) ; LockSupport . unpark ( m. waiter) ; return ( x != null ) ? ( E ) x : e; } } }
static final class TransferStack extends Transferer { static final int REQUEST = 0 ; static final int DATA = 1 ; static final int FULFILLING = 2 ; static final class SNode { volatile SNode next; volatile SNode match; volatile Thread waiter; Object item; int mode; } volatile SNode head;
}
E transfer ( E e, boolean timed, long nanos) { SNode s = null ; int mode = ( e == null ) ? REQUEST : DATA ; for ( ; ; ) { SNode h = head; if ( h == null || h. mode == mode) { if ( timed && nanos <= 0L ) { if ( h != null && h. isCancelled ( ) ) casHead ( h, h. next) ; else return null ; } else if ( casHead ( h, s = snode ( s, e, h, mode) ) ) { SNode m = awaitFulfill ( s, timed, nanos) ; if ( m == s) { clean ( s) ; return null ; } if ( ( h = head) != null && h. next == s) casHead ( h, s. next) ; return ( E ) ( ( mode == REQUEST ) ? m. item : s. item) ; } } else if ( ! isFulfilling ( h. mode) ) { if ( h. isCancelled ( ) ) casHead ( h, h. next) ; else if ( casHead ( h, s= snode ( s, e, h, FULFILLING | mode) ) ) { for ( ; ; ) { SNode m = s. next; if ( m == null ) { casHead ( s, null ) ; s = null ; break ; } SNode mn = m. next; if ( m. tryMatch ( s) ) { casHead ( s, mn) ; return ( E ) ( ( mode == REQUEST ) ? m. item : s. item) ; } else s. casNext ( m, mn) ; } } } else { SNode m = h. next; if ( m == null ) casHead ( h, null ) ; else { SNode mn = m. next; if ( m. tryMatch ( h) ) casHead ( h, mn) ; else h. casNext ( m, mn) ; } } } }
public interface BlockingDeque < E > extends BlockingQueue < E > , Deque < E > { void putFirst ( E e) throws InterruptedException ; void putLast ( E e) throws InterruptedException ; E takeFirst ( ) throws InterruptedException ; E takeLast ( ) throws InterruptedException ; } public class LinkedBlockingDeque < E > extends AbstractQueue < E > implements BlockingDeque < E > , java. io. Serializable{ static final class Node < E > { E item; Node < E > ; Node < E > ; Node ( E x) { item = x; } } transient Node < E > ; transient Node < E > ; private transient int count; private final int capacity; final ReentrantLock lock = new ReentrantLock ( ) ; private final Condition notEmpty = lock. netCondition ( ) ; private final Condition notFull = lock. newCondition ( ) ; } public E takeFirst ( ) throws InterruptedException { final ReentrantLock lock = this . lock; lock. lock ( ) ; try { E x; while ( ( x = unlinkFirst ( ) ) == null ) notEmpty. await ( ) ; return x; } finally { lock. unlock ( ) ; } } public E takeLast ( ) throws InterruptedException { final ReentrantLock lock = this . lock; lock. lock ( ) ; try { E x; while ( ( x = unlinkLast ( ) ) == null ) notEmpty. await ( ) ; return x; } finally { lock. unlock ( ) ; } } public void putFirst ( E e) throws InterruptedException { if ( e == null ) throw new NullPointerException ( ) ; Node < E > = new Node < E > ( e) ; final ReentrantLock lock = this . lock; lock. lock ( ) ; try { while ( ! linkFirst ( node) ) notFull. await ( ) ; } finally { lock. unlock ( ) ; } } public void putLast ( E e) throws InterruptedException { if ( e == null ) throw new NullPointerException ( ) ; Node < E > = new Node < E > ( e) ; final ReentrantLock lock = this . lock; lock. lock ( ) ; try { while ( ! linkLast ( node) ) notFull. await ( ) ; } finally { lock. unlock ( ) ; } }
public class CopyOnWriteArrayList < E > implements List < E > , RandomAccess , Cloneable , java. io. Serializable{ private volatile transient Object [ ] array;
}
final Object [ ] getArray ( ) { return array; } public E get ( int index) { return elementAt ( getArray ( ) , index) ; } public boolean isEmpty ( ) { return size ( ) == 0 ; } public boolean contains ( Object o) { return indexOf ( o) >= 0 ; } public int indexOf ( Object o) { Object [ ] es = getArray ( ) ; return indexOfRange ( o, es, 0 , es. length) ; } private static int indexOfRange ( Object o, Object [ ] es, int from, int to ) { if ( o == null ) { for ( int i = from; i < to ; i++ ) if ( es[ i] == null ) return i; } else { for ( int i = from; i < to ; i++ ) if ( o. equals ( es[ i] ) ) return i; } return - 1 ; }
public class CopyOnWriteArrayList < E > implements List < E > , RandomAccess , Cloneable , java. io. Serializable{ final transient Object lock = new Object ( ) ; public boolean add ( E e) { synchronized ( lock) { Object [ ] es = getArray ( ) ; int len = es. length; es = Arrays . copyOf ( es, len + 1 ) ; es[ len] = e; setArray ( es) ; return true ; } } public void add ( int index, E element) { synchronized ( lock) { Object [ ] es = getArray ( ) ; int len = es. length; if ( index > len || index < 0 ) throw new IndexOutOfBoundsException ( outOfBounds ( index, len) ) ; Object [ ] newElements; int numMoved = len - index; if ( numMoved == 0 ) newElements = Arrays . copyOf ( es, len + 1 ) ; else { newElements = new Object [ len + 1 ] ; System . arraycopy ( es, 0 , newElements, 0 , index) ; System . arraycopy ( es, index, newElements, index + 1 , numMoved) ; } newElements[ index] = element; setArray ( newElements) ; } }
public class CopyOnWriteArraySet < E > extends AbstractSet < E > implements java. io. Serializable{ private final CopyOnWriteArrayList < E > ; public CopyOnWriteArraySet ( ) { al = new CopyOnWriteArrayList < E > ( ) ; } public boolean add ( E e) { return al. addIfAbsent ( e) ; }
} 这个了解即可 :public class ConcurrentLinkedQueue < E > extends AbstractQueue < E > implements Queue < E > , java. io. Serializable{ private static class Node < E > { volatile E item; volatile Node < E > ; } private transient volatile Node < E > ; private transient volatile Node < E > ; } public ConcurrentLinkedQueue ( ) { head = tail = new Node < E > ( null ) ;
}
public boolean offer ( E e) { final Node < E > = new Node < E > ( Objects . requireNonNull ( e) ) ; for ( Node < E > = tail, p = t; ; ) { Node < E > = p. next; if ( q == null ) { if ( NEXT . compareAndSet ( p, null , newNode) ) { if ( p != t) TAIL . weakCompareAndSet ( this , t, newNode) ; return true ; } } else if ( p == q) p = ( t != ( t = tail) ) ? t : head; else p = ( p != t && t != ( t = tail) ) ? t : q; } }
public E poll ( ) { restartFromHead: for ( ; ; ) { for ( Node < E > = head, p = h, q; ; p = q) { final E item; if ( ( item = p. item) != null && p. casItem ( item, null ) ) { if ( p != h) updateHead ( h, ( ( q = p. next) != null ) ? q : p) ; return item; } else if ( ( q = p. next) == null ) { updateHead ( h, p) ; return null ; } else if ( p == q) continue restartFromHead; } } }
public boolean isEmpty ( ) { return first ( ) == null ; } Node < E > first ( ) { restartFromHead: for ( ; ; ) { for ( Node < E > = head, p = h, q; ; p = q) { boolean hasItem = ( p. item != null ) ; if ( hasItem || ( q = p. next) == null ) { updateHead ( h, p) ; return hasItem ? p : null ; } else if ( p == q) continue restartFromHead; } } }
public ConcurrentHashMap ( ) { } public ConcurrentHashMap ( int initialCapacity) { this ( initialCapacity, LOAD_FACTOR , 1 ) ; } public ConcurrentHashMap ( int initialCapacity, float loadFactor, int concurrencyLevel) { if ( ! ( loadFactor > 0.0f ) || initialCapacity < 0 || concurrencyLevel <= 0 ) throw new IllegalArgumentException ( ) ; if ( initialCapacity < concurrencyLevel) initialCapacity = concurrencyLevel; long size = ( long ) ( 1.0 + ( long ) initialCapacity / loadFactor) ; int cap = ( size >= ( long ) MAXIMUM_CAPACITY ) ? MAXIMUM_CAPACITY : tableSizeFor ( ( int ) size) ; this . sizeCtl = cap; }
private final Node < K , V > [ ] initTable ( ) { Node < K , V > [ ] tab; int sc; while ( ( tab = table) == null || tab. length == 0 ) { if ( ( sc = sizeCtl) < 0 ) Thread . yield ( ) ; else if ( U . compareAndSetInt ( this , SIZECTL , sc, - 1 ) ) { try { if ( ( tab = table) == null || tab. length == 0 ) { int n = ( sc > 0 ) ? sc : DEFAULT_CAPACITY ; @SuppressWarnings ( "unchecked" ) Node < K , V > [ ] nt = ( Node < K , V > [ ] ) new Node < ? , ? > [ n] ; table = tab = nt; sc = n - ( n >>> 2 ) ; } } finally { sizeCtl = sc; } break ; } } return tab; }
public V put ( K key, V value) { return putVal ( key, value, false ) ; } final V putVal ( K key, V value, boolean onlyIfAbsent) { if ( key == null || value == null ) throw new NullPointerException ( ) ; int hash = spread ( key. hashCode ( ) ) ; int binCount = 0 ; for ( Node < K , V > [ ] tab = table; ; ) { Node < K , V > ; int n, i, fh; K fk; V fv; if ( tab == null || ( n = tab. length) == 0 ) tab = initTable ( ) ; else if ( ( f = tabAt ( tab, i = ( n - 1 ) & hash) ) == null ) { if ( casTabAt ( tab, i, null , new Node < K , V > ( hash, key, value) ) ) break ; } else if ( ( fh = f. hash) == MOVED ) tab = helpTransfer ( tab, f) ; else if ( onlyIfAbsent && fh == hash&& ( ( fk = f. key) == key || ( fk != null && key. equals ( fk) ) ) && ( fv = f. val) != null ) return fv; else { V oldVal = null ; synchronized ( f) { if ( tabAt ( tab, i) == f) { if ( fh >= 0 ) { binCount = 1 ; for ( Node < K , V > = f; ; ++ binCount) { K ek; if ( e. hash == hash && ( ( ek = e. key) == key || ( ek != null && key. equals ( ek) ) ) ) { oldVal = e. val; if ( ! onlyIfAbsent) e. val = value; break ; } Node < K , V > = e; if ( ( e = e. next) == null ) { pred. next = new Node < K , V > ( hash, key, value) ; break ; } } } else if ( f instanceof TreeBin ) { Node < K , V > ; binCount = 2 ; if ( ( p = ( ( TreeBin < K , V > ) f) . putTreeVal ( hash, key, value) ) != null ) { oldVal = p. val; if ( ! onlyIfAbsent) p. val = value; } } else if ( f instanceof ReservationNode ) throw new IllegalStateException ( "Recursive update" ) ; } } if ( binCount != 0 ) { if ( binCount >= TREEIFY_THRESHOLD ) treeifyBin ( tab, i) ; if ( oldVal != null ) return oldVal; break ; } } } addCount ( 1L , binCount) ; return null ; } static final int TREEIFY_THRESHOLD = 8 ;
private final void treeifyBin ( Node < K , V > [ ] tab, int index) { Node < K , V > ; int n; if ( tab != null ) { if ( ( n = tab. length) < MIN_TREEIFY_CAPACITY ) tryPresize ( n << 1 ) ; else if ( ( b = tabAt ( tab, index) ) != null && b. hash >= 0 ) { synchronized ( b) { if ( tabAt ( tab, index) == b) { TreeNode < K , V > = null , tl = null ; for ( Node < K , V > = b; e != null ; e = e. next) { TreeNode < K , V > = new TreeNode < K , V > ( e. hash, e. key, e. val, null , null ) ; if ( ( p. prev = tl) == null ) hd = p; else tl. next = p; tl = p; } setTabAt ( tab, index, new TreeBin < K , V > ( hd) ) ; } } } } } static final int MIN_TREEIFY_CAPACITY = 64 ; 实际上HashMap也是这样 ,这里进行补充),那么为什么这样呢,这是因为总数据太少了,单纯的操作可以进行处理(扩容处理),而只有总数据变大时,变成红黑树效率才会明显提高,而64就是对应的操作系统的一个阈值(一般操作系统都是64位,所以是64),刚好需要多操作了,所以这时才会变成红黑树来进行提高效率static final int MIN_TREEIFY_CAPACITY = 64 ;
private final void tryPresize ( int size) { int c = ( size >= ( MAXIMUM_CAPACITY >>> 1 ) ) ? MAXIMUM_CAPACITY : tableSizeFor ( size + ( size >>> 1 ) + 1 ) ; int sc; while ( ( sc = sizeCtl) >= 0 ) { Node < K , V > [ ] tab = table; int n; if ( tab == null || ( n = tab. length) == 0 ) { n = ( sc > c) ? sc : c; if ( U . compareAndSetInt ( this , SIZECTL , sc, - 1 ) ) { try { if ( table == tab) { @SuppressWarnings ( "unchecked" ) Node < K , V > [ ] nt = ( Node < K , V > [ ] ) new Node < ? , ? > [ n] ; table = nt; sc = n - ( n >>> 2 ) ; } } finally { sizeCtl = sc; } } } else if ( c <= sc || n >= MAXIMUM_CAPACITY ) break ; else if ( tab == table) { int rs = resizeStamp ( n) ; if ( U . compareAndSetInt ( this , SIZECTL , sc, ( rs << RESIZE_STAMP_SHIFT ) + 2 ) ) transfer ( tab, null ) ; } } } private static final int MIN_TRANSFER_STRIDE = 16 ;
private transient volatile int transferIndex; private final void transfer ( Node < K , V > [ ] tab, Node < K , V > [ ] nextTab) { int n = tab. length, stride; if ( ( stride = ( NCPU > 1 ) ? ( n >>> 3 ) / NCPU : n) < MIN_TRANSFER_STRIDE ) stride = MIN_TRANSFER_STRIDE ; if ( nextTab == null ) { try { @SuppressWarnings ( "unchecked" ) Node < K , V > [ ] nt = ( Node < K , V > [ ] ) new Node < ? , ? > [ n << 1 ] ; nextTab = nt; } catch ( Throwable ex) { sizeCtl = Integer . MAX_VALUE ; return ; } nextTable = nextTab; transferIndex = n; } int nextn = nextTab. length; ForwardingNode < K , V > = new ForwardingNode < K , V > ( nextTab) ; boolean advance = true ; boolean finishing = false ; for ( int i = 0 , bound = 0 ; ; ) { Node < K , V > ; int fh; while ( advance) { int nextIndex, nextBound; if ( -- i >= bound || finishing) advance = false ; else if ( ( nextIndex = transferIndex) <= 0 ) { i = - 1 ; advance = false ; } else if ( U . compareAndSetInt( this , TRANSFERINDEX , nextIndex, nextBound = ( nextIndex > stride ? nextIndex - stride : 0 ) ) ) { bound = nextBound; i = nextIndex - 1 ; advance = false ; } } if ( i < 0 || i >= n || i + n >= nextn) { int sc; if ( finishing) { nextTable = null ; table = nextTab; sizeCtl = ( n << 1 ) - ( n >>> 1 ) ; return ; } if ( U . compareAndSetInt ( this , SIZECTL , sc = sizeCtl, sc - 1 ) ) { if ( ( sc - 2 ) != resizeStamp ( n) << RESIZE_STAMP_SHIFT ) return ; finishing = advance = true ; i = n; } } else if ( ( f = tabAt ( tab, i) ) == null ) advance = casTabAt ( tab, i, null , fwd) ; else if ( ( fh = f. hash) == MOVED ) advance = true ; else { synchronized ( f) { if ( tabAt ( tab, i) == f) { Node < K , V > , hn; if ( fh >= 0 ) { int runBit = fh & n; Node < K , V > = f; for ( Node < K , V > = f. next; p != null ; p = p. next) { int b = p. hash & n; if ( b != runBit) { runBit = b; lastRun = p; } } if ( runBit == 0 ) { ln = lastRun; hn = null ; } else { hn = lastRun; ln = null ; } for ( Node < K , V > = f; p != lastRun; p = p. next) { int ph = p. hash; K pk = p. key; V pv = p. val; if ( ( ph & n) == 0 ) ln = new Node < K , V > ( ph, pk, pv, ln) ; else hn = new Node < K , V > ( ph, pk, pv, hn) ; } setTabAt ( nextTab, i, ln) ; setTabAt ( nextTab, i + n, hn) ; setTabAt ( tab, i, fwd) ; advance = true ; } else if ( f instanceof TreeBin ) { TreeBin < K , V > = ( TreeBin < K , V > ) f; TreeNode < K , V > = null , loTail = null ; TreeNode < K , V > = null , hiTail = null ; int lc = 0 , hc = 0 ; for ( Node < K , V > = t. first; e != null ; e = e. next) { int h = e. hash; TreeNode < K , V > = new TreeNode < K , V > ( h, e. key, e. val, null , null ) ; if ( ( h & n) == 0 ) { if ( ( p. prev = loTail) == null ) lo = p; else loTail. next = p; loTail = p; ++ lc; } else { if ( ( p. prev = hiTail) == null ) hi = p; else hiTail. next = p; hiTail = p; ++ hc; } } ln = ( lc <= UNTREEIFY_THRESHOLD ) ? untreeify ( lo) : ( hc != 0 ) ? new TreeBin < K , V > ( lo) : t; hn = ( hc <= UNTREEIFY_THRESHOLD ) ? untreeify ( hi) : ( lc != 0 ) ? new TreeBin < K , V > ( hi) : t; setTabAt ( nextTab, i, ln) ; setTabAt ( nextTab, i + n, hn) ; setTabAt ( tab, i, fwd) ; advance = true ; } } } } } }
int n = tab. length, stride; if ( ( stride = ( NCPU > 1 ) ? ( n >>> 3 ) / NCPU : n) < MIN_TRANSFER_STRIDE ) stride = MIN_TRANSFER_STRIDE ;
static final int NCPU = Runtime . getRuntime ( ) . availableProcessors ( ) ;
else if ( U . compareAndSetInt( this , TRANSFERINDEX , nextIndex, nextBound = ( nextIndex > stride ? nextIndex - stride : 0 ) ) ) { bound = nextBound; i = nextIndex - 1 ; advance = false ; }
ln = ( lc <= UNTREEIFY_THRESHOLD ) ? untreeify ( lo) : ( hc != 0 ) ? new TreeBin < K , V > ( lo) : t; hn = ( hc <= UNTREEIFY_THRESHOLD ) ? untreeify ( hi) : ( lc != 0 ) ? new TreeBin < K , V > ( hi) : t; setTabAt ( nextTab, i, ln) ; setTabAt ( nextTab, i + n, hn) ; setTabAt ( tab, i, fwd) ;
private final void tryPresize ( int size) { int c = ( size >= ( MAXIMUM_CAPACITY >>> 1 ) ) ? MAXIMUM_CAPACITY : tableSizeFor ( size + ( size >>> 1 ) + 1 ) ; int sc; while ( ( sc = sizeCtl) >= 0 ) { Node < K , V > [ ] tab = table; int n; if ( tab == null || ( n = tab. length) == 0 ) { n = ( sc > c) ? sc : c; if ( U . compareAndSetInt ( this , SIZECTL , sc, - 1 ) ) { try { if ( table == tab) { @SuppressWarnings ( "unchecked" ) Node < K , V > [ ] nt = ( Node < K , V > [ ] ) new Node < ? , ? > [ n] ; table = nt; sc = n - ( n >>> 2 ) ; } } finally { sizeCtl = sc; } } } else if ( c <= sc || n >= MAXIMUM_CAPACITY ) break ; else if ( tab == table) { int rs = resizeStamp ( n) ; if ( U . compareAndSetInt ( this , SIZECTL , sc, ( rs << RESIZE_STAMP_SHIFT ) + 2 ) ) transfer ( tab, null ) ; } } }
The reason is that there are no known efficient lock0free insertion and deletion
algorithms for search trees.
但效率会大大减低的 ,因为其中的操作竟然受其他操作影响),此时可能就会出现问题,如下图所示,删除节点10,会同时把新插入的节点20也删除掉(因为这个时候,可能头节点指向30了),这个问题超出了CAS的解决范围
public class ConcurrentSkipListMap < K , V > extends AbstractMap < K , V > implements ConcurrentNavigableMap < K , V > , Cloneable , Serializable {
static final class Node < K , V > { final K key; V val; Node < K , V > ; Node ( K key, V value, Node < K , V > ) { this . key = key; this . val = value; this . next = next; } }
static final class Index < K , V > { final Node < K , V > ; final Index < K , V > ; Index < K , V > ; Index ( Node < K , V > , Index < K , V > , Index < K , V > ) { this . node = node; this . down = down; this . right = right; } } public class ConcurrentSkipListMap < K , V > extends AbstractMap < K , V > implements ConcurrentNavigableMap < K , V > , Cloneable , Serializable { private transient Index < K , V > ; }
public V put ( K key, V value) { if ( value == null ) throw new NullPointerException ( ) ; return doPut ( key, value, false ) ; } private V doPut ( K key, V value, boolean onlyIfAbsent) { if ( key == null ) throw new NullPointerException ( ) ; Comparator < ? super K > = comparator; for ( ; ; ) { Index < K , V > ; Node < K , V > ; VarHandle . acquireFence ( ) ; int levels = 0 ; if ( ( h = head) == null ) { Node < K , V > = new Node < K , V > ( null , null , null ) ; h = new Index < K , V > ( base, null , null ) ; b = ( HEAD . compareAndSet ( this , null , h) ) ? base : null ; } else { for ( Index < K , V > = h, r, d; ; ) { while ( ( r = q. right) != null ) { Node < K , V > ; K k; if ( ( p = r. node) == null || ( k = p. key) == null || p. val == null ) RIGHT . compareAndSet ( q, r, r. right) ; else if ( cpr ( cmp, key, k) > 0 ) q = r; else break ; } if ( ( d = q. down) != null ) { ++ levels; q = d; } else { b = q. node; break ; } } } if ( b != null ) { Node < K , V > = null ; for ( ; ; ) { Node < K , V > , p; K k; V v; int c; if ( ( n = b. next) == null ) { if ( b. key == null ) cpr ( cmp, key, key) ; c = - 1 ; } else if ( ( k = n. key) == null ) break ; else if ( ( v = n. val) == null ) { unlinkNode ( b, n) ; c = 1 ; } else if ( ( c = cpr ( cmp, key, k) ) > 0 ) b = n; else if ( c == 0 && ( onlyIfAbsent || VAL . compareAndSet ( n, v, value) ) ) return v; if ( c < 0 && NEXT . compareAndSet ( b, n, p = new Node < K , V > ( key, value, n) ) ) { z = p; break ; } } if ( z != null ) { int lr = ThreadLocalRandom . nextSecondarySeed ( ) ; if ( ( lr & 0x3 ) == 0 ) { int hr = ThreadLocalRandom . nextSecondarySeed ( ) ; long rnd = ( ( long ) hr << 32 ) | ( ( long ) lr & 0 xffffffffL) ; int skips = levels; Index < K , V > = null ; for ( ; ; ) { x = new Index < K , V > ( z, x, null ) ; if ( rnd >= 0L || -- skips < 0 ) break ; else rnd <<= 1 ; } if ( addIndices ( h, skips, x, cmp) && skips < 0 && head == h) { Index < K , V > = new Index < K , V > ( z, x, null ) ; Index < K , V > = new Index < K , V > ( h. node, h, hx) ; HEAD . compareAndSet ( this , h, nh) ; } if ( z. val == null ) findPredecessor ( key, cmp) ; } addCount ( 1L ) ; return null ; } } } }
public V remove ( Object key) { return doRemove ( key, null ) ; } final V doRemove ( Object key, Object value) { if ( key == null ) throw new NullPointerException ( ) ; Comparator < ? super K > = comparator; V result = null ; Node < K , V > ; outer: while ( ( b = findPredecessor ( key, cmp) ) != null && result == null ) { for ( ; ; ) { Node < K , V > ; K k; V v; int c; if ( ( n = b. next) == null ) break outer; else if ( ( k = n. key) == null ) break ; else if ( ( v = n. val) == null ) unlinkNode ( b, n) ; else if ( ( c = cpr ( cmp, key, k) ) > 0 ) b = n; else if ( c < 0 ) break outer; else if ( value != null && ! value. equals ( v) ) break outer; else if ( VAL . compareAndSet ( n, v, null ) ) { result = v; unlinkNode ( b, n) ; break ; } } } if ( result != null ) { tryReduceLevel ( ) ; addCount ( - 1L ) ; } return result; }
public V get ( Object key) { return doGet ( key) ; } private V doGet ( Object key) { Index < K , V > ; VarHandle . acquireFence ( ) ; if ( key == null ) throw new NullPointerException ( ) ; Comparator < ? super K > = comparator; V result = null ; if ( ( q = head) != null ) { outer: for ( Index < K , V > , d; ; ) { while ( ( r = q. right) != null ) { Node < K , V > ; K k; V v; int c; if ( ( p = r. node) == null || ( k = p. key) == null || ( v = p. val) == null ) RIGHT . compareAndSet ( q, r, r. right) ; else if ( ( c = cpr ( cmp, key, k) ) > 0 ) q = r; else if ( c == 0 ) { result = v; break outer; } else break ; } if ( ( d = q. down) != null ) q = d; else { Node < K , V > , n; if ( ( b = q. node) != null ) { while ( ( n = b. next) != null ) { V v; int c; K k = n. key; if ( ( v = n. val) == null || k == null || ( c = cpr ( cmp, key, k) ) > 0 ) b = n; else { if ( c == 0 ) result = v; break ; } } } break ; } } } return result; } public class ConcurrentSkipListSet < E > extends AbstractSet < E > implements NavigableSet < E > , Cloneable , java. io. Serializable{
private final ConcurrentNavigableMap < E , Object > ; public ConcurrentSkipListSet ( ) { m = new ConcurrentSkipListMap < E , Object > ( ) ; } public boolean add ( E e) { return m. putIfAbsent ( e, Boolean . TRUE ) == null ; } }
Semaphore myResources = new Semaphore ( 5 , true ) ;
myResources. acquire ( ) ;
myResources. release ( ) ;
semaphore. release ( 2 ) ; semaphore. acquire ( 3 ) ; package main ; import java. util. Random ;
import java. util. concurrent. Semaphore ;
public class MyThread extends Thread { private final Semaphore semaphore; private final Random random = new Random ( ) ; public MyThread ( String name, Semaphore semaphore) { super ( name) ; this . semaphore = semaphore; } @Override public void run ( ) { try { semaphore. acquire ( ) ; System . out. println ( Thread . currentThread ( ) . getName ( ) + " - 抢座成功,开始写作业" ) ; Thread . sleep ( random. nextInt ( 1000 ) ) ; System . out. println ( Thread . currentThread ( ) . getName ( ) + " - 作业完成,腾出座位" ) ; } catch ( InterruptedException e) { e. printStackTrace ( ) ; } semaphore. release ( ) ; }
} package main ; import java. util. concurrent. Semaphore ;
public class Demo { public static void main ( String [ ] args) { Semaphore semaphore = new Semaphore ( 2 ) ; for ( int i = 0 ; i < 5 ; i++ ) { new MyThread ( "学⽣-" + ( i + 1 ) , semaphore) . start ( ) ; } }
}
public class Semaphore implements java. io. Serializable{
public void acquire ( ) throws InterruptedException { sync. acquireSharedInterruptibly ( 1 ) ;
} public void release ( ) { sync. releaseShared ( 1 ) ;
}
而其他的锁基本都是使用CAS来实现的(通常包括Lock,即一般是ReentrantLock) ,CAS一般在JVM的基础上实现或者CPU基础上(本质上都是这个)实现的,即CAS是利用系统的阻塞来实现原子操作,而synchronized是利用JVM的阻塞来实现原子操作(最终操作系统的阻塞),很明显,CAS比较底层,那么自然效率大,因为他并没有像synchronized一样的阻塞导致系统阻塞(因为这里中间的"导致"自然是需要时间的),因为最终的阻塞是系统的阻塞也就是线程的阻塞,而synchronized比较上层,那么需要中间的操作多,而不是我CAS直接的阻塞,这里解释之前的"没有直接的使用锁,在后面会具体说明的"public abstract class AbstractQueuedSynchronizer extends AbstractOwnableSynchronizer implements java. io. Serializable{
public final void acquireSharedInterruptibly ( int arg) throws InterruptedException { if ( Thread . interrupted ( ) ) throw new InterruptedException ( ) ; if ( tryAcquireShared ( arg) < 0 ) doAcquireSharedInterruptibly ( arg) ; } public final boolean releaseShared ( int arg) { if ( tryReleaseShared ( arg) ) { doReleaseShared ( ) ; return true ; } return false ; } } public class Semaphore implements java. io. Serializable{ abstract static class Sync extends AbstractQueuedSynchronizer { protected final boolean tryReleaseShared ( int releases) { for ( ; ; ) { int current = getState ( ) ; int next = current + releases; if ( next < current) throw new Error ( "Maximum permit count exceeded" ) ; if ( compareAndSetState ( current, next) ) return true ; } }
} static final class FairSync extends Sync {
FairSync ( int permits ) { super ( permits ) ; } protected int tryAcquireShared ( int acquires) { for ( ; ; ) { if ( hasQueuedPredecessors ( ) ) return - 1 ; int available = getState ( ) ; int remaining = available - acquires; if ( remaining < 0 || compareAndSetState ( available, remaining) ) return remaining; } } } }
package java. lang. invoke ; public abstract class VarHandle { public final native @MethodHandle.PolymorphicSignature @HotSpotIntrinsicCandidate boolean compareAndSet ( Object . . . args) ; } package main1 ; import java. util. Random ;
import java. util. concurrent. CountDownLatch ;
public class MyThread extends Thread { private final CountDownLatch latch; private final Random random = new Random ( ) ; public MyThread ( String name, CountDownLatch latch) { super ( name) ; this . latch = latch; } @Override public void run ( ) { try { Thread . sleep ( random. nextInt ( 2000 ) ) ; } catch ( InterruptedException e) { e. printStackTrace ( ) ; } System . out. println ( Thread . currentThread ( ) . getName ( ) + "运行结束" ) ; latch. countDown ( ) ; }
} package main1 ; import java. util. concurrent. CountDownLatch ;
public class Main { public static void main ( String [ ] args) throws InterruptedException { CountDownLatch latch = new CountDownLatch ( 5 ) ; new MyThread ( "线程1" , latch) . start ( ) ; new MyThread ( "线程2" , latch) . start ( ) ; new MyThread ( "线程3" , latch) . start ( ) ; new MyThread ( "线程4" , latch) . start ( ) ;
latch. await ( ) ; System . out. println ( "程序运行结束" ) ; }
}
public void await ( ) throws InterruptedException { sync. acquireSharedInterruptibly ( 1 ) ;
} public void acquire ( ) throws InterruptedException { sync. acquireSharedInterruptibly ( 1 ) ;
} public final void acquireSharedInterruptibly ( int arg) throws InterruptedException { if ( Thread . interrupted ( ) ) throw new InterruptedException ( ) ; if ( tryAcquireShared ( arg) < 0 ) doAcquireSharedInterruptibly ( arg) ;
} protected int tryAcquireShared ( int acquires) { return ( getState ( ) == 0 ) ? 1 : - 1 ; } public void countDown ( ) { sync. releaseShared ( 1 ) ;
}
public final boolean releaseShared ( int arg) { if ( tryReleaseShared ( arg) ) { doReleaseShared ( ) ; return true ; } return false ;
} protected boolean tryReleaseShared ( int releases) { for ( ; ; ) { int c = getState ( ) ; if ( c == 0 ) return false ; int nextc = c - 1 ; if ( compareAndSetState ( c, nextc) ) return nextc == 0 ; } } }
CyclicBarrier barrier = new CyclicBarrier ( 5 ) ; barrier. await ( ) ;
package main2 ; import java. util. Random ;
import java. util. concurrent. BrokenBarrierException ;
import java. util. concurrent. CyclicBarrier ;
public class MyThread extends Thread { private final CyclicBarrier barrier; private final Random random = new Random ( ) ; public MyThread ( String name, CyclicBarrier barrier) { super ( name) ; this . barrier = barrier; } @Override public void run ( ) { try { Thread . sleep ( random. nextInt ( 2000 ) ) ; System . out. println ( Thread . currentThread ( ) . getName ( ) + " - 已经到达公司" ) ; barrier. await ( ) ; Thread . sleep ( random. nextInt ( 2000 ) ) ; System . out. println ( Thread . currentThread ( ) . getName ( ) + " - 已经笔试结束" ) ; barrier. await ( ) ; Thread . sleep ( random. nextInt ( 2000 ) ) ; System . out. println ( Thread . currentThread ( ) . getName ( ) + " - 已经⾯试结束" ) ; } catch ( InterruptedException e) { e. printStackTrace ( ) ; } catch ( BrokenBarrierException e) { e. printStackTrace ( ) ; }
}
} package main2 ; import java. util. concurrent. CyclicBarrier ;
public class Main { public static void main ( String [ ] args) { CyclicBarrier barrier = new CyclicBarrier ( 5 ) ; for ( int i = 0 ; i < 5 ; i++ ) { new MyThread ( "线程-" + ( i + 1 ) , barrier) . start ( ) ; } }
} public class CyclicBarrier { private final ReentrantLock lock = new ReentrantLock ( ) ; private final Condition trip = lock. newCondition ( ) ; private final int parties; private int count; private Generation generation = new Generation ( ) ; } public CyclicBarrier ( int parties, Runnable barrierAction) { if ( parties <= 0 ) throw new IllegalArgumentException ( ) ; this . parties = parties; this . count = parties; this . barrierCommand = barrierAction;
} public CyclicBarrier ( int parties) { this ( parties, null ) ; }
public int await ( ) throws InterruptedException , BrokenBarrierException { try { return dowait ( false , 0L ) ; } catch ( TimeoutException toe) { throw new Error ( toe) ; }
} private int dowait ( boolean timed, long nanos) throws InterruptedException , BrokenBarrierException , TimeoutException { final ReentrantLock lock = this . lock; lock. lock ( ) ; try { final Generation g = generation; if ( g. broken) throw new BrokenBarrierException ( ) ; if ( Thread . interrupted ( ) ) { breakBarrier ( ) ; throw new InterruptedException ( ) ; } int index = -- count; if ( index == 0 ) { boolean ranAction = false ; try { final Runnable command = barrierCommand; if ( command != null ) command. run ( ) ; ranAction = true ; nextGeneration ( ) ; return 0 ; } finally { if ( ! ranAction) breakBarrier ( ) ; } } for ( ; ; ) { try { if ( ! timed) trip. await ( ) ; else if ( nanos > 0L ) nanos = trip. awaitNanos ( nanos) ; } catch ( InterruptedException ie) { if ( g == generation && ! g. broken) { breakBarrier ( ) ; throw ie; } else { Thread . currentThread ( ) . interrupt ( ) ; } } if ( g. broken) throw new BrokenBarrierException ( ) ; if ( g != generation) return index; if ( timed && nanos <= 0L ) { breakBarrier ( ) ; throw new TimeoutException ( ) ; } } } finally { lock. unlock ( ) ; } }
private void breakBarrier ( ) { generation. broken = true ; count = parties; trip. signalAll ( ) ;
}
private void nextGeneration ( ) { trip. signalAll ( ) ; count = parties; generation = new Generation ( ) ;
} package main3 ; import java. util. Random ;
import java. util. concurrent. Exchanger ;
public class Main { private static final Random random = new Random ( ) ; public static void main ( String [ ] args) { Exchanger < String > = new Exchanger < > ( ) ; new Thread ( "线程1" ) { @Override public void run ( ) { while ( true ) { try { String otherData = exchanger. exchange ( "交换数据1" ) ; System . out. println ( Thread . currentThread ( ) . getName ( ) + "得到 <==" + otherData) ; Thread . sleep ( random. nextInt ( 2000 ) ) ; } catch ( InterruptedException e) { e. printStackTrace ( ) ; } } } } . start ( ) ; new Thread ( "线程2" ) { @Override public void run ( ) { while ( true ) { try { String otherData = exchanger. exchange ( "交换数据2" ) ; System . out. println ( Thread . currentThread ( ) . getName ( ) + "得到 <==" + otherData) ; Thread . sleep ( random. nextInt ( 2000 ) ) ; } catch ( InterruptedException e) { e. printStackTrace ( ) ; } } } } . start ( ) ; new Thread ( "线程3" ) { @Override public void run ( ) { while ( true ) { try { String otherData = exchanger. exchange ( "交换数据3" ) ; System . out. println ( Thread . currentThread ( ) . getName ( ) + "得到 <==" + otherData) ; Thread . sleep ( random. nextInt ( 2000 ) ) ; } catch ( InterruptedException e) { e. printStackTrace ( ) ; } } } } . start ( ) ; }
} public class Exchanger < V > { public Exchanger ( ) { participant = new Participant ( ) ; } @jdk.internal.vm.annotation.Contended static final class Node { int index; int bound; int collides; int hash; Object item; volatile Object match; volatile Thread parked; } static final class Participant extends ThreadLocal < Node > { public Node initialValue ( ) { return new Node ( ) ; } }
private final Participant participant;
} private volatile Node [ ] arena;
public V exchange ( V x) throws InterruptedException { Object v; Node [ ] a; Object item = ( x == null ) ? NULL_ITEM : x; if ( ( ( a = arena) != null || ( v = slotExchange ( item, false , 0L ) ) == null ) && ( ( Thread . interrupted ( ) || ( v = arenaExchange ( item, false , 0L ) ) == null ) ) ) throw new InterruptedException ( ) ; return ( v == NULL_ITEM ) ? null : ( V ) v; }
private final Object slotExchange ( Object item, boolean timed, long ns) { Node p = participant. get ( ) ; Thread t = Thread . currentThread ( ) ; if ( t. isInterrupted ( ) ) return null ; for ( Node q; ; ) { if ( ( q = slot) != null ) { if ( SLOT . compareAndSet ( this , q, null ) ) { Object v = q. item; q. match = item; Thread w = q. parked; if ( w != null ) LockSupport . unpark ( w) ; return v; } if ( NCPU > 1 && bound == 0 && BOUND . compareAndSet ( this , 0 , SEQ ) ) arena = new Node [ ( FULL + 2 ) << ASHIFT ] ; } else if ( arena != null ) return null ; else { p. item = item; if ( SLOT . compareAndSet ( this , null , p) ) break ; p. item = null ; } } int h = p. hash; long end = timed ? System . nanoTime ( ) + ns : 0L ; int spins = ( NCPU > 1 ) ? SPINS : 1 ; Object v; while ( ( v = p. match) == null ) { if ( spins > 0 ) { h ^= h << 1 ; h ^= h >>> 3 ; h ^= h << 10 ; if ( h == 0 ) h = SPINS | ( int ) t. getId ( ) ; else if ( h < 0 && ( -- spins & ( ( SPINS >>> 1 ) - 1 ) ) == 0 ) Thread . yield ( ) ; } else if ( slot != p) spins = SPINS ; else if ( ! t. isInterrupted ( ) && arena == null && ( ! timed || ( ns = end - System . nanoTime ( ) ) > 0L ) ) { p. parked = t; if ( slot == p) { if ( ns == 0L ) LockSupport . park ( this ) ; else LockSupport . parkNanos ( this , ns) ; } p. parked = null ; } else if ( SLOT . compareAndSet ( this , p, null ) ) { v = timed && ns <= 0L && ! t. isInterrupted ( ) ? TIMED_OUT : null ; break ; } } MATCH . setRelease ( p, null ) ; p. item = null ; p. hash = h; return v; } public T get ( ) { Thread t = Thread . currentThread ( ) ; ThreadLocalMap map = getMap ( t) ; if ( map != null ) { ThreadLocalMap. Entry e = map. getEntry ( this ) ; if ( e != null ) { @SuppressWarnings ( "unchecked" ) T result = ( T ) e. value; return result; } } return setInitialValue ( ) ; } private T setInitialValue ( ) { T value = initialValue ( ) ; Thread t = Thread . currentThread ( ) ; ThreadLocalMap map = getMap ( t) ; if ( map != null ) { map. set ( this , value) ; } else { createMap ( t, value) ; } if ( this instanceof TerminatingThreadLocal ) { TerminatingThreadLocal . register ( ( TerminatingThreadLocal < ? > ) this ) ; } return value; }
private final Object arenaExchange ( Object item, boolean timed, long ns) { Node [ ] a = arena; int alen = a. length; Node p = participant. get ( ) ; for ( int i = p. index; ; ) { int b, m, c; int j = ( i << ASHIFT ) + ( ( 1 << ASHIFT ) - 1 ) ; if ( j < 0 || j >= alen) j = alen - 1 ; Node q = ( Node ) AA . getAcquire ( a, j) ; if ( q != null && AA . compareAndSet ( a, j, q, null ) ) { Object v = q. item; q. match = item; Thread w = q. parked; if ( w != null ) LockSupport . unpark ( w) ; return v; } else if ( i <= ( m = ( b = bound) & MMASK ) && q == null ) { p. item = item; if ( AA . compareAndSet ( a, j, null , p) ) { long end = ( timed && m == 0 ) ? System . nanoTime ( ) + ns : 0L ; Thread t = Thread . currentThread ( ) ; for ( int h = p. hash, spins = SPINS ; ; ) { Object v = p. match; if ( v != null ) { MATCH . setRelease ( p, null ) ; p. item = null ; p. hash = h; return v; } else if ( spins > 0 ) { h ^= h << 1 ; h ^= h >>> 3 ; h ^= h << 10 ; if ( h == 0 ) h = SPINS | ( int ) t. getId ( ) ; else if ( h < 0 && ( -- spins & ( ( SPINS >>> 1 ) - 1 ) ) == 0 ) Thread . yield ( ) ; } else if ( AA . getAcquire ( a, j) != p) spins = SPINS ; else if ( ! t. isInterrupted ( ) && m == 0 && ( ! timed || ( ns = end - System . nanoTime ( ) ) > 0L ) ) { p. parked = t; if ( AA . getAcquire ( a, j) == p) { if ( ns == 0L ) LockSupport . park ( this ) ; else LockSupport . parkNanos ( this , ns) ; } p. parked = null ; } else if ( AA . getAcquire ( a, j) == p && AA . compareAndSet ( a, j, p, null ) ) { if ( m != 0 ) BOUND . compareAndSet ( this , b, b + SEQ - 1 ) ; p. item = null ; p. hash = h; i = p. index >>>= 1 ; if ( Thread . interrupted ( ) ) return null ; if ( timed && m == 0 && ns <= 0L ) return TIMED_OUT ; break ; } } } else p. item = null ; } else { if ( p. bound != b) { p. bound = b; p. collides = 0 ; i = ( i != m || m == 0 ) ? m : m - 1 ; } else if ( ( c = p. collides) < m || m == FULL || ! BOUND . compareAndSet ( this , b, b + SEQ + 1 ) ) { p. collides = c + 1 ; i = ( i == 0 ) ? m : i - 1 ; } else i = m + 1 ; p. index = i; } } }
package main4 ; import java. util. Random ;
import java. util. concurrent. Phaser ;
public class Main { public static void main ( String [ ] args) { Phaser phaser = new Phaser ( 5 ) ; for ( int i = 0 ; i < 5 ; i++ ) { new Thread ( "线程-" + ( i + 1 ) ) { private final Random random = new Random ( ) ; @Override public void run ( ) { System . out. println ( getName ( ) + " - 开始运行" ) ; try { Thread . sleep ( random. nextInt ( 1000 ) ) ; } catch ( InterruptedException e) { e. printStackTrace ( ) ; } System . out. println ( getName ( ) + " - 运行结束" ) ; phaser. arrive ( ) ; } } . start ( ) ; } System . out. println ( "线程启动完毕" ) ; phaser. awaitAdvance ( phaser. getPhase ( ) ) ; System . out. println ( "线程运行结束" ) ; }
} package main5 ; import java. util. Random ;
import java. util. concurrent. Phaser ;
public class MyThread extends Thread { private final Phaser phaser; private final Random random = new Random ( ) ; public MyThread ( String name, Phaser phaser) { super ( name) ; this . phaser = phaser; } @Override public void run ( ) { System . out. println ( getName ( ) + " - 开始向公司出发" ) ; slowly ( ) ; System . out. println ( getName ( ) + " - 已经到达公司" ) ; phaser. arriveAndAwaitAdvance ( ) ; System . out. println ( getName ( ) + " - 开始笔试" ) ; slowly ( ) ; System . out. println ( getName ( ) + " - 笔试结束" ) ; phaser. arriveAndAwaitAdvance ( ) ; System . out. println ( getName ( ) + " - 开始⾯试" ) ; slowly ( ) ; System . out. println ( getName ( ) + " - ⾯试结束" ) ; } private void slowly ( ) { try { Thread . sleep ( random. nextInt ( 1000 ) ) ; } catch ( InterruptedException e) { e. printStackTrace ( ) ; } } } package main5 ; import java. util. concurrent. Phaser ;
public class Main { public static void main ( String [ ] args) { Phaser phaser = new Phaser ( 5 ) ; for ( int i = 0 ; i < 5 ; i++ ) { new MyThread ( "线程-" + ( i + 1 ) , phaser) . start ( ) ; } phaser. awaitAdvance ( phaser. getPhase ( ) ) ; System . out. println ( 1 ) ; }
}