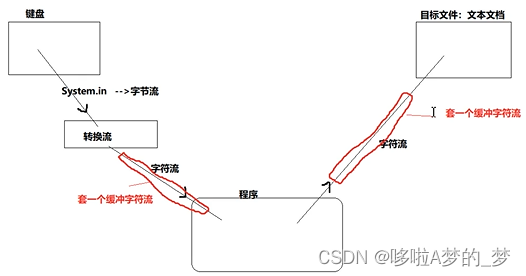
🍓个人主页:个人主页
💬推荐一款模拟面试、刷题神器,从基础到大厂面试题:点击跳转进入网站
📩如果你想学习算法,以及一些语言基础的知识,那就来这里:刷题网站 跟我一起来学习刷题吧!
前言
I will, in fact, claim that the difference between a bad programmer and a good one is whether he considers his code or his data structures more important. Bad programmers worry about the code. Good programmers worry about data structures and their relationships.
— Linus Torvalds
基本的数学知识
首先我们需要复习一些在初高中可能学过的基础数学知识。
集合
集合 (Set) 是基本的数学概念,指具体的某种性质的事物的总体,集合中的事物称之为 元素 (element)。
element 通常使用小写字母表示,而 set 通常使用大写字母表示。若 x 是集合 A 中的元素,记作 x∈Ax;反之不在集合中记作 x∉Ax。当两个 set 中所包含的 element 完全一样时,就称这两个 set 相等,记作 A=B 。
集合中的所有元素地位相同,元素间是无序的。这些元素是唯一的,即在同一个集合中对一个元素只包含一次。而元素只有存在或不存在于这个集合两种状态。而我们常用的集合有以下几种:

使用上角标 ∗ 表示去零之后的集合,而上角标 + 和 − 分别表示只包含正数部分与负数部分的集合。如果希望包含零 (比如非负数集合) 则可以在使用上角标的同时使用下角标 0 。
运算
模运算 简单的说就是 取余数 ,在数学上被称为 同余 (congruent),记作 A≡B(mod N)。这意味着无论 A 还是 B 被 N 除,其余数都是相同的,即 81≡61≡1(mod 10)。同余在 programming 中用的还是比较多的,大部分语言中使用 % 代表同余运算。这里我们着重列一些同余的性质,至于证明亲请放过我!
传递性
当有 3 个数,其中 a 与 b 同余 N、b 与 a 同余 N,则 a、c 同余 N a≡b(mod N),b≡c(mod N)⟹a≡c(mod N)
保持运算
a≡b(mod N),c≡d(mod N)⟹a±c≡b±d(mod N), ac≡bd(mod N)
可以引申该性质:
a≡b(mod N)⟹an≡bn(mod N)(∀n∈Z), an≡bn(mod N)(∀n∈N0)
放大缩小底数
k∈Z,n∈Z+⟹(kN±a)n≡(±a)n(mod N)
放大缩小模数
k∈N∗,a≡b(mod N)⟹∃! ka≡kb(mod kN)
除法原理
ka≡kb(mod N),k⊥N⟹a≡b(mod N)
费马小定理
p∈P⟹ap−1≡1(mod p)
欧拉定理
N∈Z+,a∈Z+,gcd(a,N)=1⟹aφ(N)≡1(mod N)
下来说一下运算法则,最不成问题的应该是幂运算,其次是幂的逆运算 – 对数。最后的级数,嗯,就不说了。

算法分析
数学基础
算法 (Algorithm) 是为求解一个问题所需要遵循的、被清楚地指定的简单指令集合。对于一个问题,一旦某种算法给定并且被确定是正确的,那么重要的一步是确定该算法将需要多少如时间或空间等资源量的问题。首先介绍以下四个定义:
-
大 O 符号 (big O notation),又称
渐近符号,用于描述一个函数的数量级渐近上界,记作 T(N)=O(f(N))。∃c∈N∗,∃n0∈N∗,N≥n0⟹T(N)≤cf(N)
例如有 T(n)=4n^2−2n+2T(n) = 4n^{2} - 2n + 2T(n)=4n^2−2n+2 ,写作 T(n)∈O(n^2)

-
大 Ω\OmegaΩ 符号 (big Omega notation),与 big O notation 类似,big O 表示函数增长到一定程度时总小于一个特定函数的常数倍,big Omega 则表示总大于一个特定函数的常数倍。记作 T(N)=Ω(f(N)) 。
∃c∈N∗, ∃n0∈N∗,N≥n0⟹N≥cf(N)
- 大 Θ 符号 (big Theta notation),是 big O 与 big Omega 的结合,由 Knuth 教授于 1970 年提出。这是在教科书上容易被误用的符号,可能会将 Θ 误用为 O 。
∃! T(N)=O(f(N)), ∃! T(N)=Ω(f(N))⟹T(N)=Θ(f(N))
- 小 o 符号 ,如果说 bit O 是无穷大渐近,那么小 o 符号则表示的是无穷小渐近,记作 T(N)=o(f(N))。
∀c∈N∗, ∃n0, N>n0⟹T(N)<cf(N)
T(N)=o(f(N)) 或者用 big O 与 big Theta 来理解小 o 符号:
T(N)=O(f(N))∧T(N)≠Θ(f(N))⟹T(N)=o(f(N))
可以发现,在使用 O 时常常可以忽略低阶项或常数项,当然也会忽略高阶项的系数。因此 O 是一种精度较低的估计。
我们可以通过计算极限 limN→∞(f(N)/g(N)) 来确定函数 f(N) 与 g(N) 的相对增长率。最终我们可以求解 (比如说洛必达法则) 出四种可能性:
- lim=0 ,即 f(N) 是 g(N) 的高阶无穷小,这意味着 f(N)=o(g(N))
- lim=c(c≠0),即 f(N) 是 g(N)的同阶无穷小,这意味着 f(N)=Θ(g(N))
- lim=∞ ,即 f(N) 是 g(N) 的低阶无穷小,这意味着 g(N)=o(f(N))
- lim=∄ ,即极限不存在,这意味着二者无关
需要注意的是,我们不要说 f(N)≤O(g(N)) ,因为 O 定义中已经蕴含了不等式;写作 f(N)≥O(g(N)) 则是错误的,因为其没有意义。
要分析的问题
一般需要分析的最重要的资源是运行时间,有多个因素影响程序的运行时间。除了编译器与计算机等超出理论模型的范畴,主要因素是使用的 算法 以及对该算法的 输入。
我们需要明白,虽然实现方面我们可以使用不同编程语言,但是我们往往忽略编程语言的细节所带来的影响,虽然不同语言的实现存在着运行时间的差异。
典型情况下,输入的大小是主要的讨论因素。我们定义函数 Tavg(N) 与 Tworst(N) 分别表示对于输入 N 所花费的平均情形与最坏情形的运行时间,显然 Tavg(N)≤Tworst(N)。一般最好结果不在分析范围内,因为其不代表典型结果。平均情形性能往往可以反应出该算法的典型结果,而最坏情形的性能则是算法对于任何输入在性能上的保证。
一般来说,在无特殊说明时,所需要的量就是最坏情况的运行时间,因为它对所有输出提供了一个界限,而平均情形并不提供这样的界。
运行时间计算
为了让我们更有效的分析算法,我们约定 不存在 特定的时间单位,因此我们只需要计算 O 运行时间。由于 O 是上界,我们不能低估程序的运行时间,这是对程序运行时间的保证。
一般法则
- 顺序语句的运行时间是各个语句运行时间求和
- 选择语句的运行时间是判断与分支中的最长运行时间之和
- 循环语句其运行时间至多是该 for 循环内语句的运行时间乘以迭代的次数
不过我们需要注意一点,就是 递归 (recursion),虽然其中可能只使用到顺序与选择语句,但其是隐含的循环结构。如果你对递归的认识并不是很好,可以学习 SICP 的第一章 ~ 构造过程的抽象~ ,使用 Scheme 进行学习与构造的过程中是十分愉快的。
使用 SICP 中的例子,递归可以分为 线性递归 与 树形递归,在 recursion 应用中,前者的典型示例是阶乘,而后者的典型示例是 Fibonacci 数列。
以阶乘为示例,翻译为简单的数学表达式 n!=n⋅[(n−1)⋅(n−2)⋯3⋅2⋅1]=n⋅(n−1)!,递归的进行阶乘的求解,构造起一个 推迟进行的操作 所形成的链条,收缩阶段表现为这些运算的实际执行。忽略程序运行时进行的函数调用开销,这个程序的时间复杂度为 O(N) ,保证对于任何输入都可以在关于 N 的线性时间完成。
(define (factorial n)(if (or (= n 1) (= n 0))1(* n (factorial (- n 1)))))
以 Fibonacci 数列 F(n)=F(n−1)+F(n−2),F(0)=F(1)=1 为示例,在求解第 n 个 fibonacci 数时,我们需要对第 n−1 个和第 n−2 个数进行分别求解,然后对第 n−1 个数也如此求解。最终我们的递归构造起一个树形的推迟计算结构,并在收缩时进行了很多冗余计算。对于示例程序,其运行时间为 T(N)=T(N−1)+T(N−2)+2 ,利用数学归纳法可以得知 fibN<(5/3)^N 并且 FN≥(3/2)^N,这个运算的时间将随着 N 的增加而指数级增加。
(define (fib n)(cond ((= n 0) 1)((= n 1) 1)(else (+ (fib (- n 1))(fib (- n 2))))))
示例:最大子数组和问题

对于该问题有四种差异极大的解决方法,其时间复杂度分别为 ON^3 、 ON^2、 ONlogN 以及 ON 。对于小输入来说,无论选取哪种方式,计算机总能很快完成其给定输入;但数据输入到达一定大的数量级时,其前两种算法的时间复杂度实在太大了,以至于它们十分缓慢,不再适合解决该问题。

1. 朴素算法,时间复杂度为 O(N3)
int max_subarray_sum(const int arr[], const int len) {int ans = 0;for (int i = 0; i < len; i++) {for (int j = i; j < len; j++) {int sum = 0;for (int k = i; k <= j; k++) {sum += arr[k];}if (sum > ans) {ans = sum;}}}return ans;
}
该算法在 6 ~ 8 行由一个隐含于三层 for 循环中的 O(1) 语句组成,循环大小为 N (虽然它们是 N−i和 j−i+1 ,但最坏情况为 N),总开销为 O(1⋅N⋅N⋅N)=O(N3) 。第 9 ~ 11 行语句开销 O(N2) 。因此我们可以忽略低阶表达式带来的影响,其最终的分析答案为 Θ(N3) 。
2. 优化算法到 O(N2)

int max_subarray_sum(const int arr[], const int len) {int ans = 0;for (int i = 0; i < len; i++) {int sum = 0;for (int j = i; j < len; j++) {sum += arr[j];if (sum > ans) {ans = sum;}}}return ans;
}
3. 时间复杂度为 O(N) 的 Recursion 解法 (分治算法)

struct State { int lsum, rsum, msum, sum; };
struct State push_up(struct State l, struct State r) {return (struct State) {.lsum = fmax(l.lsum, l.sum + r.lsum),.rsum = fmax(r.rsum, r.sum + l.rsum),.msum = fmax(fmax(l.msum, r.msum), l.rsum + r.lsum),.sum = fmax(l.sum, r.sum),};
}
struct State get(const int arr[], const int l, const int r) {if (l == r) {return (struct State){arr[l], arr[l], arr[l], arr[l]};}int m = (l + r) >> 1;return push_up(get(arr, l, m), get(arr, m + 1, r));
}
int max_subarray_sum(const int arr[], const int len) {return get(arr, 0, len - 1);
}
对数级增长
对数级增长通常发生在分治算法中,或者其他算法中。如果一个算法用 常数时间 (O(1) 将问题的大小削减为其一部分 (通常为 1/2),则该算法就是 O(logN) 的。比如说在二分算法、欧几里得算法 (迭代法求最大公因数) 或快速幂算法。
抽象数据类型
抽象数据类型 (Abstract Data Type, ADT) 是带有一组操作的一些对象的集合。ADT 是数学抽象,在 ADT 的定义中根本又有提到这组操作是如何实现的。对于不同的数据结构,其存储的数据都是抽象数据,可以是整数、浮点数、布尔数或其他符合 ADT 要求的数据类型。对于不同的 ADT 也有不同的操作,比如线性 ADT 可以有 insert (插入)、移除 (remove)、大小 (size) 等等,集合 ADT 还可以有其他操作,比如 并 (union)、查找 (find) 等。
对于适当地隐藏实现细节,如此程序中需要对 ADT 实施操作的任何其他部分可以通过调用适当的方法来进行。如果出于某些原因需要更改实现细节,那么通过仅仅改变执行这些 ADT 操作的例程是十分轻松的,而这些修改对于程序的其他部分是 透明的 (transparent)。
ADT 并不是必须实现这些操作,而是一种 设计决策 。错误处理和结构调整一般取决于程序的设计者。比如说 C++ 的 STL,标准中只定义了每种容器的接口,和每个接口的时间复杂度和要求。
容器与迭代器
容器 (Container) 是一类特殊的类型,它是存放数据的集合,不同类型的 Container 有着不同的适用场景。容器主要分为四大类:
- 顺序容器 (sequence container):实现能按顺序访问的数据结构
- 关联容器 (associative container):实现能快速查找 (O(logN)) 的数据结构
- 无序关联容器 (unordered associative container):实现能快速查找 (Oavg(1),Oworst(N)) 的无序数据结构
- 容器适配器 (container adaptor):提供顺序容器的不同接口
容器其实是一组特殊的数据结构,为编程过程中提供便利。其中 associative container 主要使用 红黑树 (red-black tree) 作为底层实现,这是我们之后需要学习的树的一种; unordered associative container 底层使用 Hash (散列) 进行实现;container adaptor 则是对 sequence container 的接口进行再封装,所实现的一种受限容器。
为了更轻松的访问容器,实现容器元素的遍历 (traverse),从而无需关心容器对象的内存分配的实现细节,从而引入 迭代器 (iterator) 的概念。iterator 依据功能的不同被分为了不同的种类,且约束 (constraint) 逐渐增强。

虽然上述这些关于 Container 与 Iterator 的概念从 C++ 而来,但在不同编程语言中差别不大,是一种较为通用的概念。
概念与约束
这是一个 C++ 20 中添加的特性,可以与 constraint 关联,它指定对模板实参的一些要求,这些要求可被用于选择最恰当的函数重载和模板特化。这与 Haskell 的类型类相似,限制可以接受的对象的类型,并对其进行 constraint。在不同语言中有不同的类似概念,如果你想了解更多关于它们区别的内容,可以移步 这里。 对不住了,我能力有限啊!
迭代器
首先介绍 iterator 的 concept,你可以将 iterator 想象成一个指向元素的指针。 container 的 concept 依赖于 iterator,但 iterator 的具体实现依赖于 container。
1. LegacyIterator
template <class I>
concept iterator = requires(I i) {{ *i } -> Referenceable; // 1{ ++i } -> std::same_as<I&>; // 2{ *i++ } -> Referenceable; // 3
} && std::copyable<I>; // 4
LegacyIterator 要求:
- 对于 I 类型的对象 i 可以解引用并返回对数据的引用
- 对于 I 类型的对象 i 可以自增且返回的是对自身的引用
- 对于 I 类型的对象 i 可以返回对数据的引用并使其自增
- 必须是可复制的
2. ForwardIterator
template <class I>
concept forward_iterator = input_iterator<I> && // 1std::constructible_from<I> && // 2std::is_lvalue_reference_v<std::iter_reference_t<I>> && // 3std::same_as<std::remove_cvref_t<std::iter_reference_t<I>>, // 4typename std::indirectly_readable_traits<I>::value_type> &&requires(I i) {{ i++ } -> std::convertible_to<const I&>;{ *i++ } -> std::same_as<std::iter_reference_t<I>>;};
ForwardIterator 要求:
- I 是一个 LegacyInputIterator
- 可以从 I 构造
- I 的引用的元素类型可被左值引用
- I 的引用的元素类型可被读
3. BidirectionalIterator
template <class I>
concept bidirectional_iterator = forward_iterator<I> && // 1requires(I i) {{ --i } -> std::same_as<I&>; // 2{ i-- } -> std::convertible_to<const I&>;{ *i-- } -> std::same_as<std::iter_reference_t<I>>;};
BidirectionalIterator 要求:
- I 是一个 ForwordIterator
- 对于 I 类型的对象 i 可以自减并返回自身的引用
4. RandomAccessIterator
template <class I>
concept random_access_iterator = bidirectional_iterator<I> && // 1std::totally_ordered<I> && // 2requires(I i, typename std::incrementable_traits<I>::difference_type n) { // 3{ i += n } -> std::same_as<I&>; // 3.1{ i -= n } -> std::same_as<I&>; // 3.2{ i + n } -> std::same_as<I>; // 3.3{ n + i } -> std::same_as<I>; // 3.4{ i - n } -> std::same_as<I>; // 3.5{ i - i } -> std::same_as<decltype(n)>; // 3.6{ i[n] } -> std::convertible_to<std::iter_reference_t<I>>; // 3.7};
RandomAccessIterator 要求:
- I 是一个 BidirectionalIterator
- 对于 I 类型的对象进行比较,其结果符合 严格全序要求
- 对于 I 类型的对象 i 与 I 类型的关联差类型 n:
- i 以 O(1)\mathcal{O}(1)O(1) 时间复杂度向前步进 n 并返回对其自身的引用
- i 以 O(1)\mathcal{O}(1)O(1) 时间复杂度向后步进 n 并返回对其自身的引用
- i 的副本以 O(1)\mathcal{O}(1)O(1) 时间复杂度向前步进 n 并返回
- 同 3
- i 的副本以 O(1)\mathcal{O}(1)O(1) 时间复杂度向后步进 n 并返回
- i1i_{1}i1 与 i2i_{2}i2 的关联差,即计算 ii−i2i_{i} - i_{2}ii−i2
- 随机对 i 进行访问并返回元素的引用,即 ∗(i+n)*(i + n)∗(i+n)
5. ContiguousIterator
template <class I>
concept contiguous_iterator = std::random_access_iterator<I> &&requires(const I& i) {{ std::to_address(i) } ->std::same_as<std::add_pointer_t<std::iter_reference_t<I>>>;};
ContiguousIterator 要求:设 a 与 b 为 I 类型的可解引用迭代器,c 为 I 类型的不可解引用迭代器,使得 b 从 a 可抵达而 c 从 b 可抵达。类型 I 实现 contiguous_iterator 仅若其所蕴含的所有概念均被实现,且:

容器
template <class T>
concept container = requires(T a, const T b) {requires regular<T>; // 1requires swappable<T>; // 2requires erasable<typename T::value_type>; // 3requires same<typename T::reference, typename T::value_type&>; // 4requires same<typename T::const_reference, const typename T::value_type&>; // 4requires forward_iterator<typename T::iterator>; // 5requires forward_iterator<typename T::const_iterator>; // 5requires unsigned<typename T::size_type>; // 6requires signed<typename T::difference_type>; // 7requires same<typename T::difference_type,typename std::iterator_traits<typename T::iterator>::difference_type>; // 8requires same<typename T::difference_type,typename std::iterator_traits<typename T::const_iterator>::difference_type>; // 8{ a.begin() } -> typename T::iterator;{ a.end() } -> typename T::iterator;{ b.begin() } -> typename T::const_iterator;{ b.end() } -> typename T::const_iterator;{ a.cbegin() } -> typename T::const_iterator;{ a.cend() } -> typename T::const_iterator;{ a.size() } -> typename T::size_type;{ a.max_size() } -> typename T::size_type;{ a.empty() } -> boolean;a.clear();a.swap(a);
};
对于容器类型 T,其中包含的元素类型 value_type ,迭代器类型 iterator 与 const_iterator ,元素的引用类型 reference 与 const_reference ,关联差类型 difference_type ,大小相关类型 size_type
- T 是 正则的 ,即它可复制、可默认构造且可比较相等
- T 可交换
value_type是可擦除的value_type的引用类型与 reference 相同- iterator 满足 forward_iterator 要求
size_type是无符号类型difference_type是有符号的difference_type与 iterator 的关联差类型相同- container 拥有以下函数

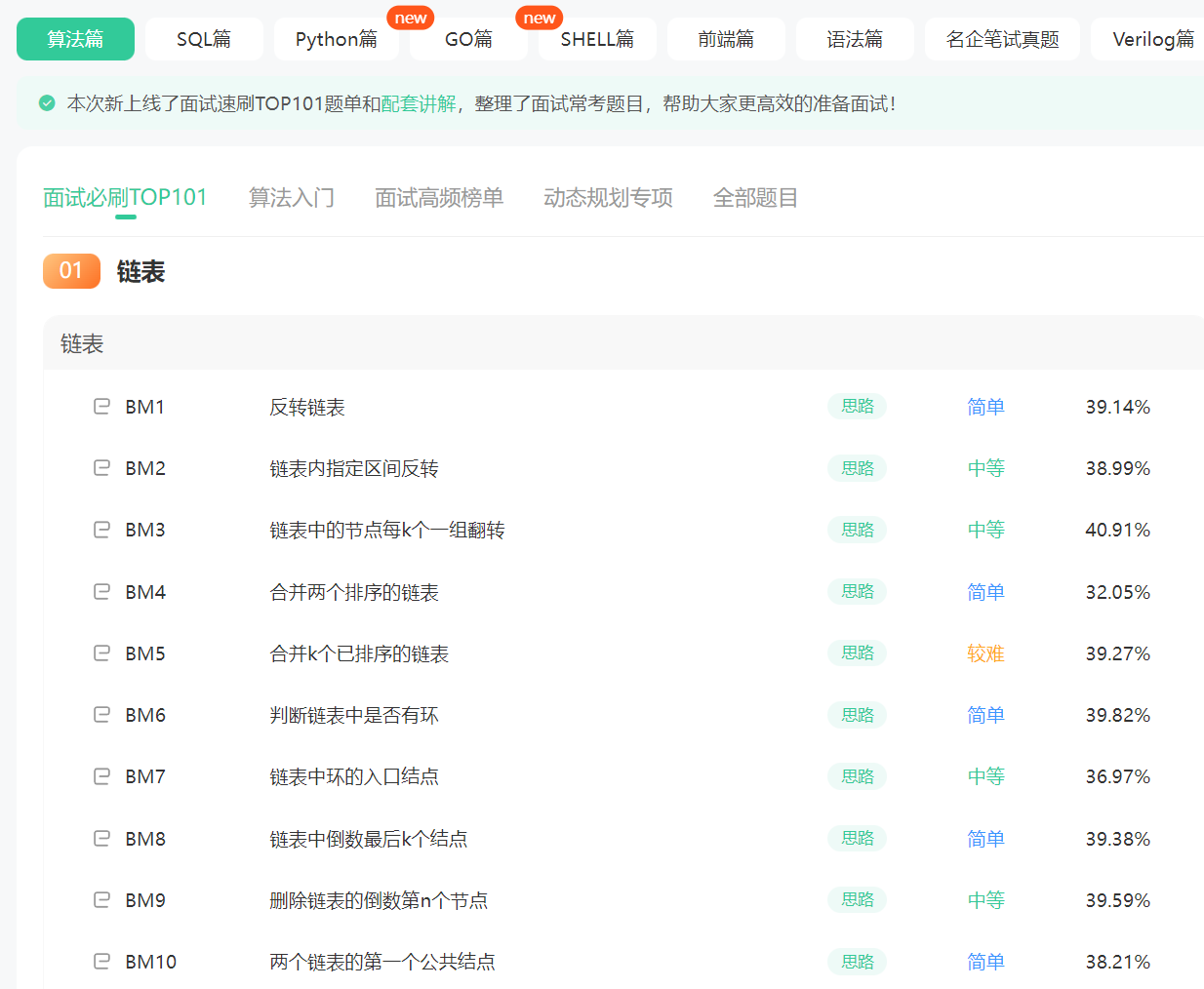
刷题对程序员来说及其重要,语言和开发平台不断变化,但是万变不离其宗的是那些算法和理论,刷题最最最直白的原因就是找一个好的工作,所以刷题一定是必不可少的现关于刷题平台还是蛮多的,给大家介绍一个我认为与大厂关联最深的平台——牛客网