在多线程环境中,线程之间通常使用互斥锁实现共享资源的独占访问。在多进程环境,特别是分布式环境,常使用分布式锁来实现共享资源的独占访问。简单来说,分布式锁就是指在分布式环境下,通过加解锁实现多节点对共享资源的互斥访问。
分布式锁的意义
使用分布式锁后,可以在以下两个方面获得提升:
(1) 效率(efficiency)。使用分布式锁可以避免各个节点重复工作,以减少不必要的资源浪费。比如用户付款之后,有可能会发出多条短信。
(2) 正确性(correctness)。在任何情况下都不允许锁失效的发生,因为一旦发生,就可能意味着数据不一致(inconsistency),数据丢失,文件损坏等严重问题。假设存在两个节点在同一条数据上同时执行操作,比如多个节点对同一个订单执行不同的操作,有可能会导致该笔订单最后状态出现错误,从而造成经济损失。
分布式锁基本特点
在使用分布式锁时,首先需了解分布式锁应该有哪些特点。以下是分布式锁必须具备或可以具备的能力:
(1) 互斥性(Mutual xclusivity)。必须具备的能力,保证同一时刻只能有一个节点可以持有锁。
(2) 避免死锁(Dead lock free)。必须具备的能力。如果某个节点获取锁之后长时间不释放锁(花费太长时间执行代码逻辑),或者节点发生了故障,锁无法释放会导致整个处理流程无法进行下去,从而导致死锁。为了避免死锁,最常见的做法是设置一个TTL(Time To Live,存活时间)。
(3) 容错性(Fault tolerance)。必须具备的能力。为避免单点故障,锁服务需要具有一定容错性。大体有两种容错场景:一种是锁服务本身是一个集群,能够自动进行故障切换(如ZooKeeper、etcd);另一种是节点向多个独立的锁服务发起请求,其中某个锁服务故障时仍然可以从其他锁服务读取到锁信息(如Redlock)。该种方式的代价是一个节点要获取多把锁,并且要求每台机器的时钟都是一样的,否则 TTL 会不一致,可能有的机器会提前释放锁,有的机器会太晚释放锁,从而导致业务出现问题。
(4) 可重入性(Reentrant)。可选的能力。同一个节点在获取锁后,如果没有释放该锁,可以再次获取这个锁。
(5) 支持同步加锁和异步加锁。可选的能力。对分布式锁加锁时,可以选择同步加锁和异步加锁。
(6) 支持公平锁和非公平锁。可选的能力。公平锁是指所有的节点都可以按照固定的规则获取锁。如请求顺序。非公平锁则是指所有的节点加锁的顺序是随机的。锁的公平性主要体现在并发请求加锁的场景下,一般都是随机加锁。
分布式锁实现
分布式锁的实现有很多种方式,这种收集了一些常用的分布式锁实现方式,并进行了简单的比较。常见的分布式锁的实现主要有以下几类:
(1) 基于数据库实现分布式锁;(2) 基于缓存组件实现分布式锁;(3) 基于 Zookeeper 组件实现分布式锁;(4) 基于 Chubby 实现分布式锁。
基于数据库
基于数据库实现分布式锁,就是在数据库中创建一个锁表。这个简单描述下如何基于数据库实现分布式锁。
首先定义一个锁表,其中id表示UUID,表示记录唯一;name表示锁记录的名称;lock_until表示锁有效时间。locked_at表示加锁的时间。(lock_until = locked_at + lockTime)。locked_by表示加锁的对象,同一个对象加锁后,可以重复获取锁。
CREATE TABLE tab_lock(id VARCHAR(64),name VARCHAR(64),lock_until TIMESTAMP(3) NULL,locked_at TIMESTAMP(3) NULL,locked_by VARCHAR(255),PRIMARY KEY (id)UNIQUE KEY (name)
)
定义锁表后,就可实现加锁逻辑。通过插入同一个 name(unique key)来创建锁,或者更新同一个 name 来抢占锁,对应的 intsert、update 的 SQL 为:
INSERT INTO tab_lock
(id, name, lock_until, locked_at, locked_by)
VALUES
(UUID, 锁名字, 当前时间+最多锁多久, 当前时间, 主机名)UPDATE tab_lock
SET lock_until = 当前时间+最多锁多久,
locked_at = 当前时间,
locked_by = 主机名 WHERE name = 锁名字 AND lock_until <= 当前时间
最后就是释放锁。通过设置 lock_until 来实现释放,再次抢锁的时候,需要通过 lock_util 来判断锁是否失效。对应的 SQL 为:
UPDATE tab_lock
SET lock_until = lockTime WHERE name = 锁名字
注意,这里只是基于数据库实现分布式锁的一种表结构定义,不同的表结构定义,其处理逻辑不同。比如这篇博文的实现。
基于数据库实现的分布式锁,依赖数据库保证互斥性、容错性,对于避免死锁,需要开发人员保证。基于数据库实现的分布式锁,强依赖数据库,对于依赖数据库的应用来说,不需要使用额外的组件。但是,基于数据库实现分布式锁,需要开发者自行维护锁处理逻辑(其实就是操作表),当然这部分工作量可以通过提供二方件或三方件来减少。
更大的问题是,使用数据库实现分布式锁,除了考虑数据库的单点问题,还需考虑主从数据库的同步问题。这无疑会带来性能上的问题。另一方面,对一个高并发应用来说,数据库常常是其性能瓶颈,使用数据库作为分布式锁的实现,并不是很合适。
在日常的工作中,基于数据库实现的分布式锁也有应用。如数据库表结构改变的管理工具liquibase通过维护数据库databasechangeloglock表实现了分布式锁。
基于缓存组件
基于缓存组件实现分布式锁,就是使用缓存组件支持的数据结构实现类似数据库表的功能。对于缓存组件,Redis已成为缓存组件的主流选择,这里也以Redis为例,介绍下如何基于Redis实现分布式锁。
Redis提供setNx(set if not exist)方法,其语义表示为"不存在则更新",可以很好的用来实现分布式锁。对某个资源加锁只需要执行setNx resourceName requestValue即可。但是这种方式有个问题,加锁了之后如果加锁的业务服务宕机,那么这个锁就不会得到释放,所以需要加入过期时间。Redis2.8之后,支持nx和ex操作是同一原子操作。对应命令是set resourceName requestValue ex expire_time nx。
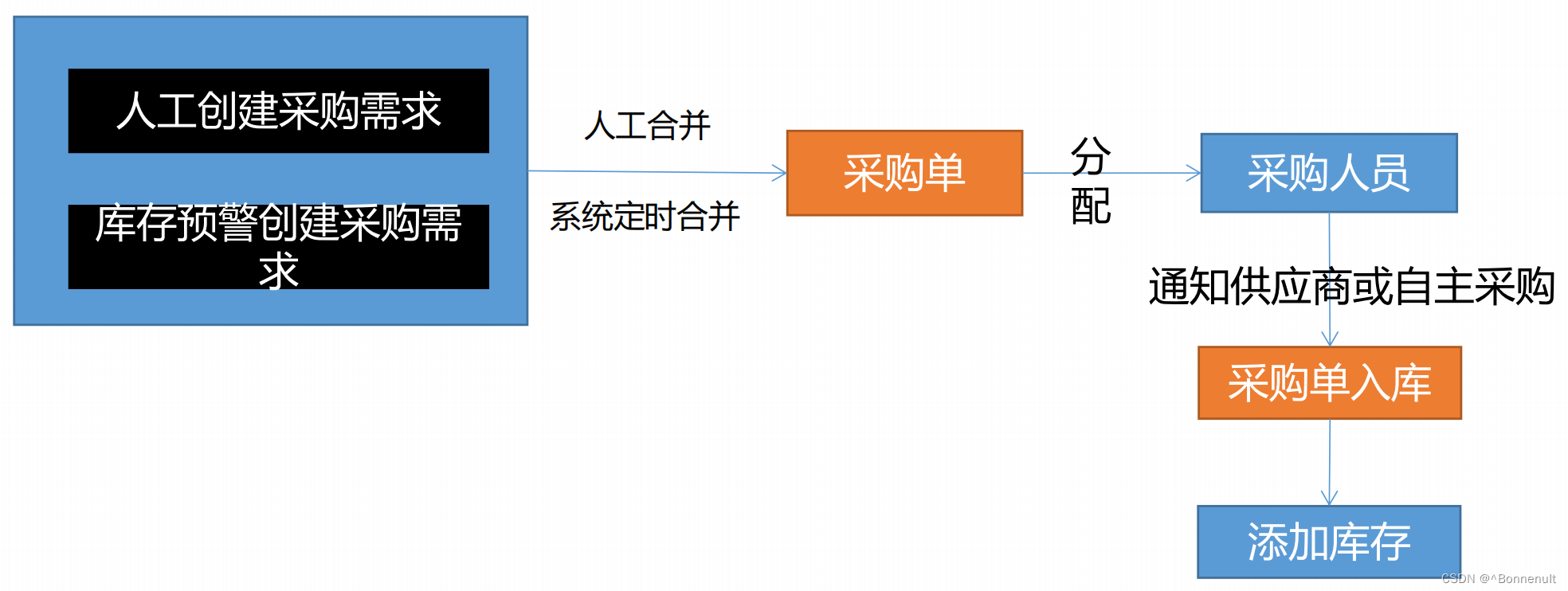
除了考虑过期时间,还可能存在释放别人的锁的问题。示例如下:
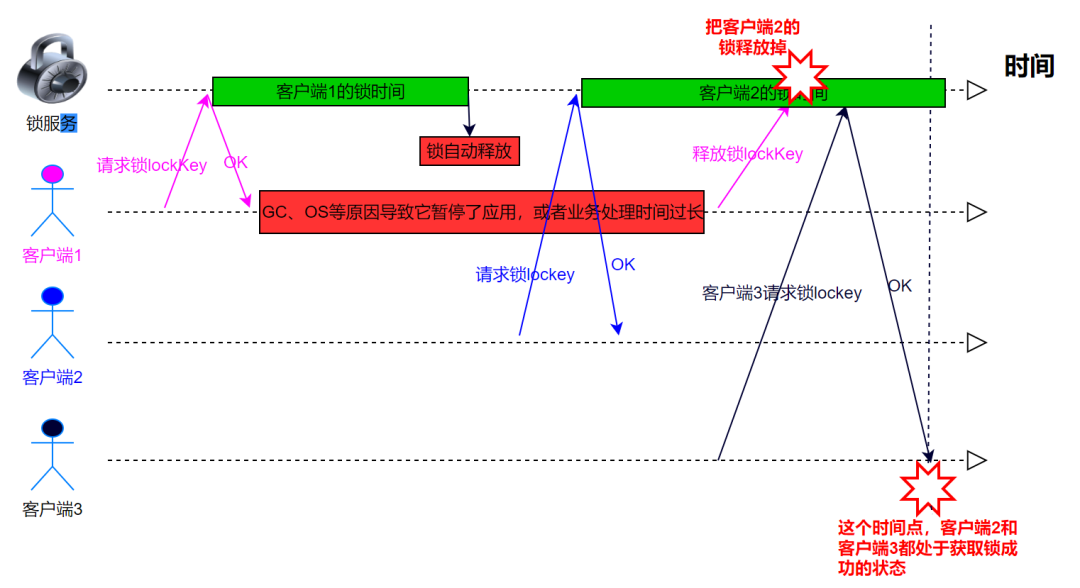 在上图中,按照以下步骤执行会导致释放别人的锁。
在上图中,按照以下步骤执行会导致释放别人的锁。
(1) 客户端 1 获取锁成功。
(2) 客户端 1 在某个操作上阻塞了很长时间。
(3) 过期时间到了,锁自动释放了。
(4) 客户端 2 获取到了对应同一个资源的锁。
(5) 客户端 1 从阻塞中恢复过来,释放掉了客户端 2 持有的锁。
(6) 另外线程客户端 3 此时可以成功请求到锁。
所以,为避免释放他人的锁,在释放锁之前,还需判断是否是自己加的锁。示例代码如下:
if (get(resourceName).equals(requestValue)) {delete(resourceName);return true;
}
return false;
这里的requestValue是一个随机字符串,以保证每个客户端释放的锁是自己持有的那个锁。
以上代码还是有问题,get操作和delete操作分两步执行,所以无法保证都执行成功。Redis支持的事务不能保证原子性,但可以借助LUA脚本实现原子性。示例代码如下:
if redis.call("get",KEYS[1]) == ARGV[1] thenreturn redis.call("del",KEYS[1])
elsereturn 0
end
在软件开发过程中,要避免重复造轮子,Redis的客户端 Redisson 已经实现了相关的分布式锁接口。这也是Redis官方推荐的分布式锁实现方式。(深入Redisson源码可以发现,Redisson并没有基于setNx命令实现分布式锁,而是基于hash实现分布式锁)
此外,对于使用主从模式的Redis来说,在主从切换时,如果锁没有从主节点同步到从节点,就会出现锁丢失的情况。一种解决方案是使用基于 RedLock 实现分布式锁。(基于 RedLock 实现分布式锁存在争议,这里不详细展开。有兴趣的同学,可以自行学习)
相比基于数据库实现的分布式锁,基于Redis实现的分布式锁具有更好的性能表现,且可借助Redis实现锁过期,简化分布式锁实现代码。
基于Zookeeper
ZooKeeper 是以 Paxos 算法为基础的分布式应用协调服务。 ZooKeeper 的数据节点和文件目录类似,所以可以用此特性实现分布式锁。这里以某个资源为目录,然后这个目录下面的节点就是需要获取锁的客户端,未获取到锁的客户端需要注册Watcher到上一个客户端,可以用下图表示。
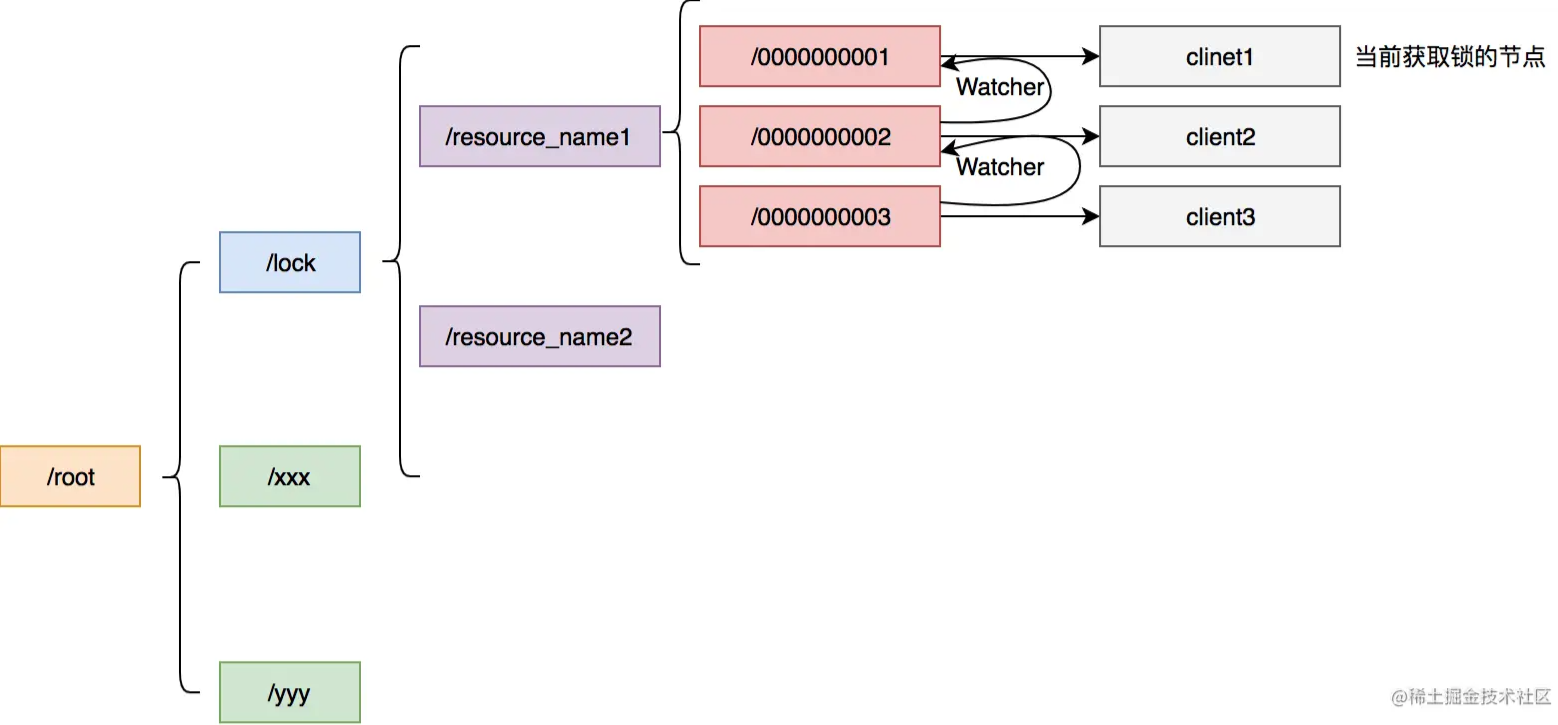 上图中/lock是用于加锁的目录,/resource_name是锁定的资源,/resource_name下面的节点按照加锁的顺序排列。
上图中/lock是用于加锁的目录,/resource_name是锁定的资源,/resource_name下面的节点按照加锁的顺序排列。
基于 Zookeeper 实现分布式锁无需配置锁超时。这是因为设置节点是临时节点,ZooKeeper 可以通过机器请求的session来判断客户端是否宕机。如果客户端宕机,那么这个临时节点对应的就会被删除。
基于 Zookeeper 实现的分布式锁无需关心锁超时时间,实现起来相对比较方便,并且支持读写锁,公平锁等能力。但是 ZooKeeper 作为独立的服务需要额外维护,且其性能和Mysql数据库相差不大,无法应用在高并发场景下。
基于Chubby
Chubby 是 Google 内部使用的分布式锁服务。Zookeeper 是 Chubby 的开源实现。Chubby内部工作原理和Zookeeper类似,但是 Chubby 的定位是分布式锁,而Zookeeper的定位是分布式协调服务。Chubby 主要源于【The Chubby lock service for loosely-coupled distributed systems](https://www.usenix.org/legacy/event/osdi06/tech/full_papers/burrows/burrows.pdf)这篇论文。
Chubby 引入了资源方和锁服务的验证,来避免了锁服务本身孤立地做预防死锁机制而导致的破坏锁安全性的风险。同时依靠 Session 来维持锁的持有状态,在正常情况下,客户端可以持有锁任意长的时间,这可以确保它做完所有需要的资源访问操作之后再释放锁。这避免了基于 Redis 的锁对于有效时间(lock validity time)到底设置多长的两难问题。
分布式锁选型
上述几种分布式锁实现在实际业务中都有应用。对一致性较高的场景,推荐基于数据库实现或基于 Zookeeper 组件实现或基于 Chubby 实现。其中Chubby因是闭源的服务,所以只能通过购买服务的方式实现,一般很难被外部使用。而 Zookeeper,多数业务服务并不直接依赖,为使用分布式锁能力而引入Zookeeper,代价过大。对性能要求较高的场景,推荐基于缓存组件实现分布式锁。由于大部分的业务服务都依赖缓存组件,所以基于缓存组件实现的分布式锁称为大多数业务的选择。
总结
在多进程环境,特别是分布式环境,常使用分布式锁来实现共享资源的独占访问。通过使用分布式锁,业务系统可以在以下两个方面获得提升:(1) 效率(efficiency)。使用分布式锁可以避免各个节点重复工作,以减少不必要的资源浪费。(2) 正确性(correctness)。在任何情况下都不允许锁失效的发生,因为一旦发生,就可能意味着数据不一致(inconsistency),数据丢失,文件损坏等严重问题。
对于分布式锁,可以借助多种中间件实现。如数据库、缓存组件、Zookeeper 组件、Chubby组件等。在对分布式锁实现进行技术选型时,要根据业务的需要进行选型。对一致性要求高的场景,推荐基于数据库实现或基于 Zookeeper 组件实现。Chubby因是闭源的服务,一般很难被外部使用。对性能要求较高的场景,推荐基于缓存组件实现分布式锁。
软件开发没有银弹。分布式锁在保证进程间共享资源的独占访问的同时,也引入了一些新的问题。如引入第三方组件,增大了系统的复杂度。根据分布式锁实现组件的不同,分布式锁也会引入安全问题。
参考
https://juejin.cn/post/6844903688088059912 分布式锁介绍
https://blog.csdn.net/J080624/article/details/86670643 学习分布式锁
https://tech.meituan.com/2016/09/29/distributed-system-mutually-exclusive-idempotence-cerberus-gtis.html 分布式系统互斥性与幂等性问题的分析与解决
https://cloud.tencent.com/developer/article/1932377 聊聊分布式锁
https://tech.youzan.com/bond/ 有赞 Bond 分布式锁
https://xie.infoq.cn/article/11e306846b9664d672689f08f 分布式锁
https://dreamgoing.github.io/分布式锁.html 分布式锁
https://blog.csdn.net/dingjianmin/article/details/82763871 浅谈分布式锁–基于数据库实现篇
https://blog.51cto.com/u_15067225/2604064 liquibase和flyway中分布式锁实现区别









![代理ARP (路由式代理ARP+vlan内代理ARP+vlan间代理ARP) [理论+实验验证]](https://img-blog.csdnimg.cn/c8a5d0f433524325b6c034f228d039ab.png)